
自己組織化カードについて
まず、自己組織化マップとは何か、または単にSOMを理解しましょう。 SOMは、教師なしの学習に基づいた人工ニューラルネットワークです。 自己組織化マップでは、部屋のニューロンは、通常1次元または2次元の格子サイトに配置されます。 このラティスのすべてのニューロンは、入力層のすべてのノードに接続されています。

SOMは連続的なソース空間を変換します 離散出力空間 。
SOM学習アルゴリズム
ネットワークトレーニングは、 競争 、 協力、 適応の3つの主要なプロセスで構成されています。 SOM学習アルゴリズムのすべてのステップを以下に説明します。
ステップ1:初期化。 すべてのシナプス重みベクトルについて、
どこで -ニューロンの総数、 -入力空間の次元、-1〜1のランダムな値が選択されます。
ステップ2:サブサンプリング。 ベクトルを選択してください 入力スペースから。
ステップ3:勝者のニューロンまたは競合プロセスを検索します。 最適なニューロンを見つけます(勝者のニューロン) ステップで 最小ユークリッド距離の基準を使用する(これはスカラー積の最大値に等しい ):
ユークリッド距離。
ユークリッド距離( )は次のように定義されます:
ステップ4:協力のプロセス。 勝者ニューロンは、「協調」ニューロンのトポロジカルな近傍の中心にあります。 重要な質問: 勝者ニューロンのいわゆるトポロジカルな近傍を決定する方法は? 便宜上、次の記号で示します。 勝者のニューロンに集中 。 トポロジカルな近傍は、次のように決定された最大点に関して対称である必要があります。 、 勝者間の横方向の距離です および隣接ニューロン 。
上記の条件を満たす典型的な例 ガウス関数です:
どこで -有効幅。 横方向の距離は次のように定義されます: 一次元で、そして: 二次元の場合。 どこで 興奮したニューロンの位置を決定し、 -勝者のニューロンの位置(2次元格子の場合 どこで そして 格子内のニューロンの座標)。
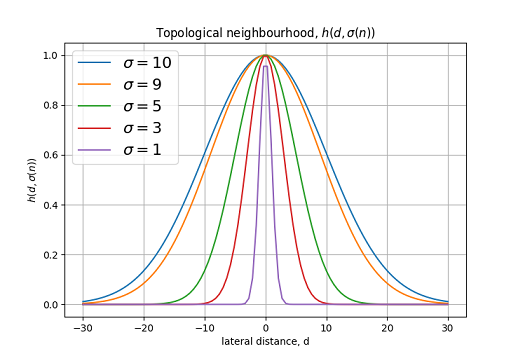
さまざまなトポロジー近傍関数のグラフ 。
SOMの特徴は、学習プロセスにおけるトポロジカルな近傍の減少です。 変更するにはこれを達成できます 式によって:
どこで 一定ですか -学習ステップ、 -初期値 。

グラフ変更 学習プロセスで。
機能 トレーニングフェーズの終わりに、最も近い隣人だけをカバーする必要があります。 以下の図は、2次元格子のトポロジカルな近傍関数のグラフを示しています。
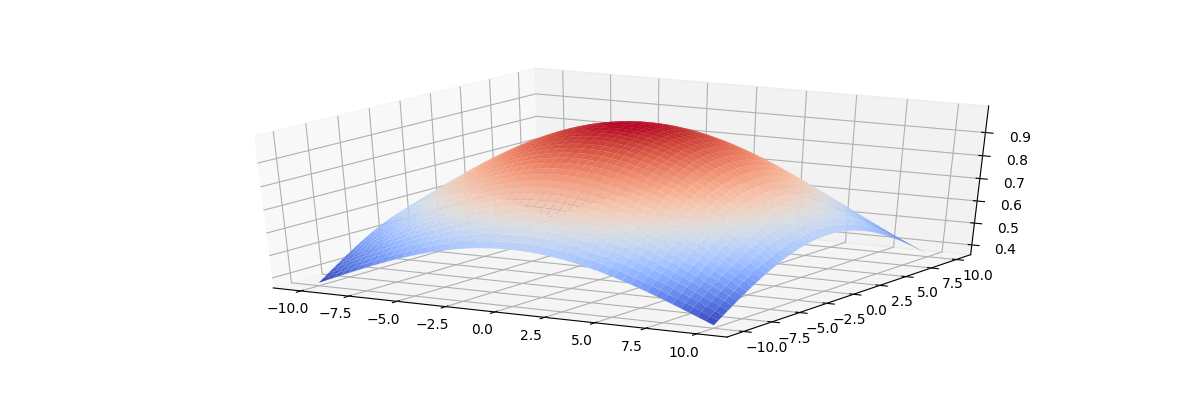
この図は、トレーニングの開始時に、トポロジカルな近傍が格子全体をほぼカバーしていることを示しています。

トレーニングの終わりに 最近傍に狭まります。
ステップ5:適応プロセス。 適応プロセスには、ネットワークのシナプスの重みの変更が含まれます。 ニューロンの重みのベクトルの変更 格子内の次のように表現することができます:
-学習速度のパラメーター。
その結果、更新された時刻の重みベクトルの式が得られます :
SOM学習アルゴリズムでは、学習速度パラメーターを変更することもお勧めします ステップに応じて。
どこで SOMアルゴリズムの別の定数です。

グラフ変更 学習プロセスで。
重みを更新した後、手順2に戻ります。
SOM学習アルゴリズムのヒューリスティック
学習ネットワークは2つの段階で構成されます。
自己組織化の段階 -最大1000回以上の反復が必要になる場合があります。
収束の段階 -機能マップの微調整に必要です。 原則として、収束段階に十分な反復回数は、ネットワーク内のネオロンの数を500倍超えることがあります。
ヒューリスティック1.学習速度パラメーターの初期値は、値に近い値を選択することをお勧めします。 、 。 さらに、0.01を下回ってはなりません。
ヒューリスティック2.初期値 格子の半径にほぼ等しく設定し、定数 次のように定義します:
収束段階で、変更を停止します 。
PythonとTensorFlowを使用したSOMの実装
ここで、PythonとTensorFlowを使用して、理論から自己組織化マップ(SOM)の実用的な実装に移りましょう。
まず、SOMNetworkクラスを作成し、すべての定数を初期化するTensorFlow操作を作成します。
import numpy as np import tensorflow as tf class SOMNetwork(): def __init__(self, input_dim, dim=10, sigma=None, learning_rate=0.1, tay2=1000, dtype=tf.float32): # if not sigma: sigma = dim / 2 self.dtype = dtype # self.dim = tf.constant(dim, dtype=tf.int64) self.learning_rate = tf.constant(learning_rate, dtype=dtype, name='learning_rate') self.sigma = tf.constant(sigma, dtype=dtype, name='sigma') # 1 ( 6) self.tay1 = tf.constant(1000/np.log(sigma), dtype=dtype, name='tay1') # 1000 ( 3) self.minsigma = tf.constant(sigma * np.exp(-1000/(1000/np.log(sigma))), dtype=dtype, name='min_sigma') self.tay2 = tf.constant(tay2, dtype=dtype, name='tay2') #input vector self.x = tf.placeholder(shape=[input_dim], dtype=dtype, name='input') #iteration number self.n = tf.placeholder(dtype=dtype, name='iteration') # self.w = tf.Variable(tf.random_uniform([dim*dim, input_dim], minval=-1, maxval=1, dtype=dtype), dtype=dtype, name='weights') # , self.positions = tf.where(tf.fill([dim, dim], True))
次に、競争プロセスのオペレーションを作成する関数を作成します。
def __competition(self, info=''): with tf.name_scope(info+'competition') as scope: # distance = tf.sqrt(tf.reduce_sum(tf.square(self.x - self.w), axis=1)) # ( 1) return tf.argmin(distance, axis=0)
協力と適応のプロセスのための主要なトレーニング業務を作成することは私たちに残っています。
def training_op(self): # win_index = self.__competition('train_') with tf.name_scope('cooperation') as scope: # d # 1d 2d coop_dist = tf.sqrt(tf.reduce_sum(tf.square(tf.cast(self.positions - [win_index//self.dim, win_index-win_index//self.dim*self.dim], dtype=self.dtype)), axis=1)) # ( 3) sigma = tf.cond(self.n > 1000, lambda: self.minsigma, lambda: self.sigma * tf.exp(-self.n/self.tay1)) # ( 2) tnh = tf.exp(-tf.square(coop_dist) / (2 * tf.square(sigma))) with tf.name_scope('adaptation') as scope: # ( 5) lr = self.learning_rate * tf.exp(-self.n/self.tay2) minlr = tf.constant(0.01, dtype=self.dtype, name='min_learning_rate') lr = tf.cond(lr <= minlr, lambda: minlr, lambda: lr) # ( 4) delta = tf.transpose(lr * tnh * tf.transpose(self.x - self.w)) training_op = tf.assign(self.w, self.w + delta) return training_op
その結果、SOMを実装し、各反復で入力ベクトルとステップ番号をパラメーターとして渡すことでニューラルネットワークをトレーニングできるtraining_op操作を受け取りました。 以下は、Tesnorboardを使用して作成されたTensorFlow操作グラフです。
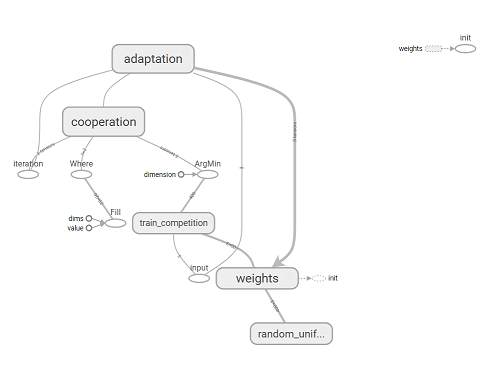
TensorFlow操作グラフ。
プログラムをテストする
プログラムをテストするために、3次元ベクトルを入力します 。 このベクトルは、3つの色として表すことができます コンポーネント。
SOMネットワークのインスタンスとランダムベクトル(色)の配列を作成します。
# 2020 som = SOMNetwork(input_dim=3, dim=20, dtype=tf.float64, sigma=3) test_data = np.random.uniform(0, 1, (250000, 3))
これで、メインのトレーニングサイクルを実装できます。
training_op = som.training_op() init = tf.global_variables_initializer() with tf.Session() as sess: init.run() for i, color_data in enumerate(test_data): if i % 1000 == 0: print('iter:', i) sess.run(training_op, feed_dict={som.x: color_data, som.n:i})
トレーニング後、ネットワークは連続入力色空間を離散勾配マップに変換します.1つの色域が適用されると、指定された色に対応するマップの1つの領域のニューロンが常にアクティブになります(提供されたベクトルに最適な1つのニューロンがアクティブになります)。 デモンストレーションのために、シナプスニューロンの重みのベクトルをカラーグラデーションイメージとして提示できます。
この図は、20x20のニューロンのネットワークの重みのマップを示しています。 反復の学習:

トレーニングの開始時(左)とトレーニングの終了時(右)の重みのマップ。

350k後の100x100ニューロンのネットワークのスケールマップ。 学習の反復。
おわりに
その結果、自己組織化マップが作成され、3つのコンポーネントで構成される入力ベクトルでのトレーニングの例が示されています。 ネットワークをトレーニングするには、任意の次元のベクトルを使用できます。 アルゴリズムをバッチモードで動作するように変換することもできます。 さらに、入力データネットワークの表示順序は、機能マップの最終的な形式に影響を与えず、学習速度のパラメーターを経時的に変更する必要はありません。
PS:完全なプログラムコードはこちらにあります 。