背景
今回はすべてが非常に簡単でした。 ビッグデータスペシャリストプログラムの卒業生は、おそらく次のことを求めています。
Kafka、Elasticsearch、およびHadoopエコシステムのさまざまなツールを使用してデータパイプラインを収集する方法を学習できる別のプログラムを作成します。
その後、雇用主側では、リクエストが「飛び込む」ようになりました。これは、まとめて次のように説明できます。
データエンジニアは非常に熱い仕事です!
現実には、私たちは半年間それらを閉じることができませんでした。
この特定の専門分野に注意を払ったことは素晴らしいことです。 現在、市場はデータサイエンティストに大きく偏っており、プロジェクト作業の半分以上がエンジニアリングです。
この瞬間から、需要があり、問題が存在することが明らかになりました。 プログラムの開発に急ぐ必要があります!
教育プログラムの開発における興味深い点は、直接の潜在的なクライアントでそれを検証しないことです。 想像してみてください。私たちは私たちと一緒に勉強したい人に近づいてきて、「これはあなたに必要ですか?」と尋ねます。
したがって、このことを理解している人、つまり実際のデータエンジニアのために、まずプログラムを検証する必要があります。 第二に、雇用主と一緒に-結局、彼らは最終的に私たちの製品の消費者です。
チームの従業員の雇用に関与している6人のデータエンジニアと話をしたところ、そのような人の仕事の本質は何か、その人はどのようなタスクを解決できるかがすぐに明らかになりました。
プログラム
エンジニアの日付の本質は、データからパイプラインを作成し、それらを監視およびトラブルシューティングし、データをアップロードおよび変換するための一時的なアドホックタスクを解決できることです。
指定すると、彼は次のことができるはずであることが判明しました。
- 生データを収集する
- キューを操作して構成する
- スケジュールに従ってデータ処理ジョブ(MLを含む)を実行する
- BIを構成する
- リレーショナルデータベースを操作する
- noSQLを使用する
- リアルタイム処理用のツールを使用する
- コマンドラインツールを使用する
- 環境と適切に連携する
これらの各ポイントで、さまざまな楽器を録音できます。 このテーマについても素晴らしい視覚化があります。 プログラムですべてをカバーすることは不可能であるか、必要でさえなかったため、1つのバッチと1つのリアルタイムパイプラインを作成する経験を積むのに十分であると判断しました。 残りは、必要に応じて、将来独立して習得します。
しかし、このプロセスに白い斑点が1つも存在しないように、彼は「始点から終点まで」パイピングを行うことを学ぶことが重要です。 そして、主催者としての問題が発生しました。
クリックジェネレーター
私たちは、参加者がクリックストリームを分析するという事実に落ち着きました。 そして、それをどのように彼らのサイトに直接生成するのかを理解する必要があります。 このソリューションの前提条件は次のとおりです。
- パイプラインの1つはリアルタイムである必要があるため、静的なデータセットは私たちには適さないため、何らかの方法でリアルタイムでデータを生成する必要があります。
- 参加者は「from and to」パイプラインを構築することを決定したため、これは実際の場合と同様に、サイトから直接データを収集する必要があることを意味します。
まあ、それはどのように思い付くか残っています。 エンジニアの日付の一部は、 Seleniumなど、サイトをテストするためのツールに目を向けることができると提案しました。 この部分は、「ヘッドレス」であるため、 PhantomJSを内部で使用する方がよいことを明確にしました。つまり、より高速になります。
彼らのアドバイスを受けて、メンバーのサイト用にユーザーエミュレータを作成しました。 コード自体はそれほどホットではありません(重要:すべての人に同じサイトを提供するため、このサイトの構造を知って、コードで特定の検索パラメーターを使用できます)。
from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.desired_capabilities import DesiredCapabilities from numpy.random import choice import time import numpy as np dcap = dict(DesiredCapabilities.PHANTOMJS) dcap["phantomjs.page.settings.userAgent"] = ("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 YaBrowser/17.6.1.745 Yowser/2.5 Safari/537.36") driver = webdriver.PhantomJS(desired_capabilities=dcap) driver.set_window_size(1024, 768) hosts = ["35.190.***.***"] keywords = {"music": "", "grammar": ""} conformity = 0.9 condition = 1 def user_journey(host, journey_length, keywords, user_type, conformity): driver.get("http://" + host) el = driver.find_element_by_link_text("") # journey el.click() print driver.current_url for i in xrange(journey_length): try: links = [] the_links = [] p = 0 P = [] links = driver.find_elements_by_class_name("b-ff-articles-shortlist__a") # url if len(links) == 0: links = driver.find_elements_by_class_name("b-ff-mobile-shortlist__a") # , if len(links) == 0: links = driver.find_elements_by_class_name("b-ff-articles-tags__a") # , links[0].click driver.current_url the_links = driver.find_elements_by_partial_link_text(keywords.get(user_type)) # url, the_link = choice(the_links, 1)[0] # url links.append(the_link) # p = (1-conformity)/float(len(links)-1) # url, , conformity P = [p]*len(links) # P[-1] = conformity # 'the link' conformity l = choice(links, 1, p=P) # time.sleep(np.random.poisson(5)) # l[0].click() print driver.current_url except: driver.close # , - while condition == 1: for host in hosts: journey_length = np.random.poisson(5) user_type = choice(keywords.keys(), 1)[0] print user_type user_journey(host, journey_length, keywords, user_type, conformity)
私たちは何をしましたか? さまざまなタイプのユーザーを生成します。 ここに2つあります(実際にはもっとあります):音楽愛好家と文法を理解したい人。 タイプの選択はランダムに選択されます。
タイプ内に、ランダム性の要素も導入しました。同じタイプのユーザーは、直接ハードコーディングした同じリンクをたどらず、リンクは「正しい」リンクのサブセットからランダムに選択されます+ユーザーが「間違った「リンク。 これは、将来、参加者がこのデータを分析し、何らかの方法でこれらのユーザーをセグメント化しようとするために行われました。
さらに、実際のユーザーの行動のように直接見えるように、ページにランダムな待機時間を実装しました。 そして、私たちがやめるまでこの銃は撃ちます。
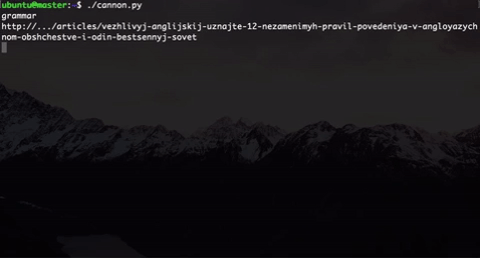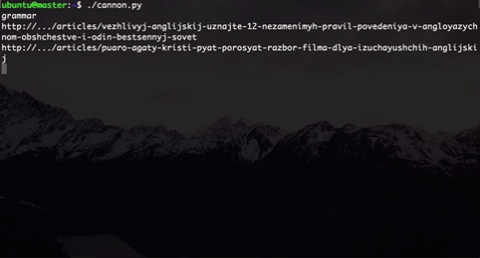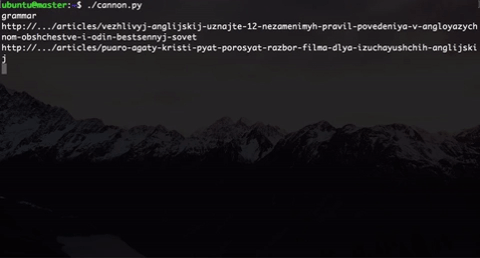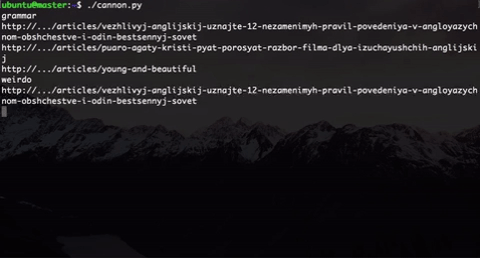
唯一のことは、そのような銃で20〜30人のグループをすばやく処理できないことです。そのため、このスクリプトをgnu parallelで実行することにしました 。 この行により、利用可能なすべてのカーネルでスクリプトを並行して実行できます。
$ parallel -j0 python ::: cannon.py
まとめ
- 各参加者は、nginxを使用して発行したサイトを作成します。
- サーバーのIPアドレスを送信します。
- サイトのすべてのページにJavaScriptを埋め込み、クリックを収集します。
- 銃から彼のサイトに到着するデータを収集します。
- Kafkaに送信します。
- パイプラインに沿ってさらに...
そのため、プロジェクトが開始され、その上で彼はデータエンジニアプログラムで6週間働きます。