レナ-スタッフのサポートのメンバー。 職務の一つ-専門家の間で電子メールへの着信呼の分布。 それは魅力を分析し、特性の数を決定します。 たとえば、「アクセスタイプ」:システムエラー、単に利用者に相談する必要があるユーザーは、いくつかの新しい機能を望んでいます。 定義「システムの機能モジュール」:会計モジュール、機器の認証など これらの特性のすべてを確認するには、適切な治療にリダイレクトします。
- 私はそれを自動的に行いますプログラムを書くよ、さあ! - 私は答えました。
技術的な部分へのこの魅惑的な小説、フィニッシュムーブで。
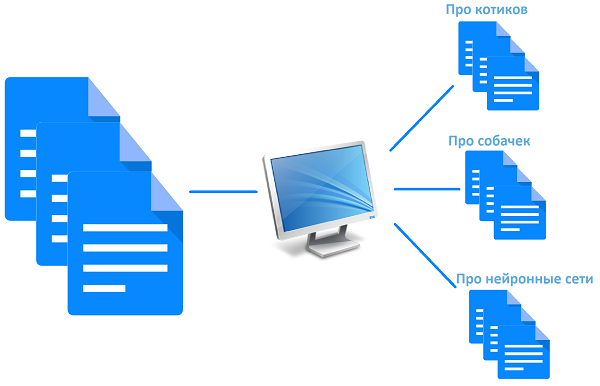
タスクを形式
- 入力は、任意の長さとコンテンツのテキストです。
- それは誤植、略語が含まれており、一般的にあいまいかもしれので、人によって書かれたテキスト。
- このテキストは、何らかの形で分析する必要があり、それにはいくつかの無関係な特性で分類します。 新機能、または必要性の助言を要求だけでなく、機能モジュールを決定するために、エラーメッセージ:私たちの場合、魅力の本質を定義する必要があった。、倉庫管理などを占め、Sの計算を/ N。
- なお、各特性のためにのみ1つの値に割り当てることができます。
- 事前に知られている各特性の可能な値のセット。
- すでに分類されたアプリケーションの数千があります。
私たちの特定のニーズに合わせてタスクと開発の開始を定式化、私はすぐに厳密にいくつかの特定の特性及びこれらの特性の数に縛られる汎用性の高いツールを開発した方がよいことに気づきました。 結果は、任意の特性のテキストを分類することができツールでした。
それを自分で行うには、時間と関心だったので、準備完了ソリューションは、求めていなかった、パラレルはニューラルネットワークの研究に浸漬しました。
楽器の選択
私は、Javaで開発することを決めました。
使用してデータベースとしてSQLiteのとH2を 。 それはまたに便利です休止状態 。
したがって、それは、ニューラルネットワーク(Encog機械学習フレームワーク)の準備ができて実装しました。 私は、分類器、ニューラルネットワークではなく、例えば、としてそれを使用することを決めた単純ベイズ分類器まず、理論的には、ニューラルネットワークが正確でなければなら、ので、。 第二に、私は、ニューラルネットワークをいじってみたかったです。
いくつかのライブラリ訓練するために必要なデータのExcelファイル読み込みするにはApache POIを 。
ああ、そして伝統的に使用テストのためのJUnit 4 + Mockito 。
少し理論
(それは十分なので、私は、詳細にニューラルネットワークの理論を説明していないだろう、ここでは良い入門資料)。 簡単に言うと、単純な方法で:ネットワークは、入力層、中間層および出力層を有しています。 それぞれの層のニューロンの数は、予め開発者によって決定され、追加した場合の学習ネットワークを変更することはできません/後、再び再訓練するネットワークの必要性が単一ニューロンを低下させました。 入力層の各ニューロンに対する正規化数は、(ほとんどの場合、0から1まで)が適用されます。 入力層における整数の集合に応じて、各出力ニューロン上のいくつかの計算後も0から1までの数を得ています。
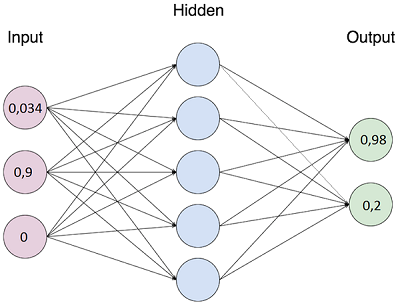
学習ネットワークの本質は、ネットワークが、計算に関与するリンクの重みを調整することであるので、入力層における一定の予め設定された数値が出力層に予め数字の既知のセットを受信するとき。 バランスの調整 - それは反復の一定数に達するまで、ネットワークのいずれか訓練セット上の所定の精度に達するまで反復プロセスが発生します。 訓練の後、入力がトレーニングセットにしたものと類似の数の集合を、提出された場合、ネットワークは、出力層の数字の標準セットに近いを発行することが期待されます。
私たちは練習に向けます
最初のタスクは、ニューラルネットワークの入力に渡すことができる形式にテキストを変換する方法を見つけ出すことでした。 しかし、最初に、事前に設定する必要があるように、ネットワークの入力層のサイズを決定する必要がありました。 入力層は、この層であったことができます任意のテキストにサイズ決めなければならないことは明白である「フィット。」 心に来る最初の事- 入力層の大きさは、コンテキストその言葉/フレーズを含む辞書のサイズと同じでなければなりません 。
語彙を構築するための多くの方法。 例えば、我々は愚かなロシア語のすべての単語を取り、それが私たちの語彙になります。 入力層の大きさは、ニューラルネットワークが十分なリソースを持っていないシンプルなワークステーションを作成することをとても巨大になりますので、しかし、このアプローチは、適切ではありません。 たとえば、私たちは辞書は100個の000の単語を持っていることを想像し、その後、我々は、入力層100,000ニューロンを持っています。 例えば、隠れ層(中間層の寸法を決定するための以下に記載される方法)、出力25で80000。 次いでだけ接続の重みを格納するためのRAM〜60ギガバイト((100 * 000 80 000)+(000 * 80 25))* 64ビット(JAVAでdouble型)を必要とするであろう。 特定の用語がテキストではなく、辞書に使用することができるので、第二に、このアプローチは、適切ではありません。
したがって、辞書は唯一の私たちの分析されたテキストを構成するそれらの単語/フレーズを構築すべきとの結論。 トレーニングデータの十分に大きい量であるべきである。この場合には辞書を構築することを理解することが重要です 。
テキストの言葉/フレーズを「引き出す」の一つの方法(もっと正確には、フラグメントが)の建設と呼ばNグラム 。 最も人気のあるunigrammyとバイグラムです。 文字Nグラムもあります - テキストは、特定の長さのセグメントに個々の単語や文字の上にないときに押し潰されます。 それはあなたが実験する必要があるので、特定のタスクに有効になりますNグラムのどの言うのは難しいです。
| テキスト | Unigramma | バイグラム | 3文字Nグラム |
|---|---|---|---|
| このテキストは部分に分割する必要があります | [ "この"、 "テキスト"、 "である" "べきである"、 "に"、 "壊れた"、 "部"] | [「に分割」「この文章」、「テキストがなければならない」、「破壊する」「べき」、「離れて」] | [ "この"、 "TT"、 "CEN"、 "等"、 "olzh"、 "EN"、 "生命"、 "S P"、 "AZB"、 "UM"、 "上"、「H "" 分「] |
私は単純なものから複雑なものまで移動することを決めたとユニグラムクラスを開始するように設計されています。
クラスユニグラム
class Unigram implements NGramStrategy { @Override public Set<String> getNGram(String text) { if (text == null) { text = ""; } // get all words and digits String[] words = text.toLowerCase().split("[ \\pP\n\t\r$+<>№=]"); Set<String> uniqueValues = new LinkedHashSet<>(Arrays.asList(words)); uniqueValues.removeIf(s -> s.equals("")); return uniqueValues; } }
その結果、〜万のテキストを処理した後、私は〜32,000要素の辞書サイズを得ました。 その結果、対角辞書を分析した後、私はを取り除くために持っているだろうかと、非常に多くの繰り返しがあることに気づきました。 これを行うには:
- すべての彼らは通常運ばないという意味ので、すべての英数字以外の文字(など数字、句読点、算術演算を、)を取り外します。
- 私は、手続きの言葉を通じて運転ステミング (使用ポーターステマーロシア語のため)。 ちなみに、この手順の便利な副作用は、「完了」された「uniseksatsiya」という言葉、および「完了」「sdela」に変換されますです。
- 最初は私は正しいタイプミスや文法の誤りとを検出したかったです。 オリバーアルゴリズム(関数についてNachitalsja similar_text PHPで)とレーベンシュタイン距離 。 しかし、問題はしかしエラーで、より簡単に解決された:私は、要素Nグラムは、トレーニングセットから4つの未満のテキストを発生した場合、我々は辞書で、この要素は将来の役に立たないとして含まれていないことを決めました。 私はタイプミスのほとんどを処分したので、文法的なエラーが発生した言葉、「sleplennyhSlov」とだけ非常にいくつかの単語。 しかし、我々は将来のテキストにしばしば誤植や文法の誤りが含まれている場合は、そのようなテキストの分類の精度が低くなることを理解して、まだタイプミスや文法の誤りを訂正するためのメカニズムを実装している必要があります。 重要:単語を削除することにより、めったに遭遇しないこの「トリック」と言ったときに学習し、語彙を構築するための大量のデータ。
このすべては、教室やFilteredUnigram VocabularyBuilderに実装されています。
クラスFilteredUnigram
public class FilteredUnigram implements NGramStrategy { @Override public Set<String> getNGram(String text) { // get all significant words String[] words = clean(text).split("[ \n\t\r$+<>№=]"); // remove endings of words for (int i = 0; i < words.length; i++) { words[i] = PorterStemmer.doStem(words[i]); } Set<String> uniqueValues = new LinkedHashSet<>(Arrays.asList(words)); uniqueValues.removeIf(s -> s.equals("")); return uniqueValues; } private String clean(String text) { // remove all digits and punctuation marks if (text != null) { return text.toLowerCase().replaceAll("[\\pP\\d]", " "); } else { return ""; } } }
テキスト){ public class FilteredUnigram implements NGramStrategy { @Override public Set<String> getNGram(String text) { // get all significant words String[] words = clean(text).split("[ \n\t\r$+<>№=]"); // remove endings of words for (int i = 0; i < words.length; i++) { words[i] = PorterStemmer.doStem(words[i]); } Set<String> uniqueValues = new LinkedHashSet<>(Arrays.asList(words)); uniqueValues.removeIf(s -> s.equals("")); return uniqueValues; } private String clean(String text) { // remove all digits and punctuation marks if (text != null) { return text.toLowerCase().replaceAll("[\\pP\\d]", " "); } else { return ""; } } }
).split( "[\ N \トン\ R $ + <>№=]"); public class FilteredUnigram implements NGramStrategy { @Override public Set<String> getNGram(String text) { // get all significant words String[] words = clean(text).split("[ \n\t\r$+<>№=]"); // remove endings of words for (int i = 0; i < words.length; i++) { words[i] = PorterStemmer.doStem(words[i]); } Set<String> uniqueValues = new LinkedHashSet<>(Arrays.asList(words)); uniqueValues.removeIf(s -> s.equals("")); return uniqueValues; } private String clean(String text) { // remove all digits and punctuation marks if (text != null) { return text.toLowerCase().replaceAll("[\\pP\\d]", " "); } else { return ""; } } }
{ public class FilteredUnigram implements NGramStrategy { @Override public Set<String> getNGram(String text) { // get all significant words String[] words = clean(text).split("[ \n\t\r$+<>№=]"); // remove endings of words for (int i = 0; i < words.length; i++) { words[i] = PorterStemmer.doStem(words[i]); } Set<String> uniqueValues = new LinkedHashSet<>(Arrays.asList(words)); uniqueValues.removeIf(s -> s.equals("")); return uniqueValues; } private String clean(String text) { // remove all digits and punctuation marks if (text != null) { return text.toLowerCase().replaceAll("[\\pP\\d]", " "); } else { return ""; } } }
[I])。 public class FilteredUnigram implements NGramStrategy { @Override public Set<String> getNGram(String text) { // get all significant words String[] words = clean(text).split("[ \n\t\r$+<>№=]"); // remove endings of words for (int i = 0; i < words.length; i++) { words[i] = PorterStemmer.doStem(words[i]); } Set<String> uniqueValues = new LinkedHashSet<>(Arrays.asList(words)); uniqueValues.removeIf(s -> s.equals("")); return uniqueValues; } private String clean(String text) { // remove all digits and punctuation marks if (text != null) { return text.toLowerCase().replaceAll("[\\pP\\d]", " "); } else { return ""; } } }
<>(は、Arrays.asList(ワード)); public class FilteredUnigram implements NGramStrategy { @Override public Set<String> getNGram(String text) { // get all significant words String[] words = clean(text).split("[ \n\t\r$+<>№=]"); // remove endings of words for (int i = 0; i < words.length; i++) { words[i] = PorterStemmer.doStem(words[i]); } Set<String> uniqueValues = new LinkedHashSet<>(Arrays.asList(words)); uniqueValues.removeIf(s -> s.equals("")); return uniqueValues; } private String clean(String text) { // remove all digits and punctuation marks if (text != null) { return text.toLowerCase().replaceAll("[\\pP\\d]", " "); } else { return ""; } } }
「)); public class FilteredUnigram implements NGramStrategy { @Override public Set<String> getNGram(String text) { // get all significant words String[] words = clean(text).split("[ \n\t\r$+<>№=]"); // remove endings of words for (int i = 0; i < words.length; i++) { words[i] = PorterStemmer.doStem(words[i]); } Set<String> uniqueValues = new LinkedHashSet<>(Arrays.asList(words)); uniqueValues.removeIf(s -> s.equals("")); return uniqueValues; } private String clean(String text) { // remove all digits and punctuation marks if (text != null) { return text.toLowerCase().replaceAll("[\\pP\\d]", " "); } else { return ""; } } }
[\\にpP \\ D]を"、 ""); public class FilteredUnigram implements NGramStrategy { @Override public Set<String> getNGram(String text) { // get all significant words String[] words = clean(text).split("[ \n\t\r$+<>№=]"); // remove endings of words for (int i = 0; i < words.length; i++) { words[i] = PorterStemmer.doStem(words[i]); } Set<String> uniqueValues = new LinkedHashSet<>(Arrays.asList(words)); uniqueValues.removeIf(s -> s.equals("")); return uniqueValues; } private String clean(String text) { // remove all digits and punctuation marks if (text != null) { return text.toLowerCase().replaceAll("[\\pP\\d]", " "); } else { return ""; } } }
クラスVocabularyBuilder
class VocabularyBuilder { private final NGramStrategy nGramStrategy; VocabularyBuilder(NGramStrategy nGramStrategy) { if (nGramStrategy == null) { throw new IllegalArgumentException(); } this.nGramStrategy = nGramStrategy; } List<VocabularyWord> getVocabulary(List<ClassifiableText> classifiableTexts) { if (classifiableTexts == null || classifiableTexts.size() == 0) { throw new IllegalArgumentException(); } Map<String, Integer> uniqueValues = new HashMap<>(); List<VocabularyWord> vocabulary = new ArrayList<>(); // count frequency of use each word (converted to n-gram) from all Classifiable Texts // for (ClassifiableText classifiableText : classifiableTexts) { for (String word : nGramStrategy.getNGram(classifiableText.getText())) { if (uniqueValues.containsKey(word)) { // increase counter uniqueValues.put(word, uniqueValues.get(word) + 1); } else { // add new word uniqueValues.put(word, 1); } } } // convert uniqueValues to Vocabulary, excluding infrequent // for (Map.Entry<String, Integer> entry : uniqueValues.entrySet()) { if (entry.getValue() > 3) { vocabulary.add(new VocabularyWord(entry.getKey())); } } return vocabulary; } }
ClassifiableText> classifiableTexts){ class VocabularyBuilder { private final NGramStrategy nGramStrategy; VocabularyBuilder(NGramStrategy nGramStrategy) { if (nGramStrategy == null) { throw new IllegalArgumentException(); } this.nGramStrategy = nGramStrategy; } List<VocabularyWord> getVocabulary(List<ClassifiableText> classifiableTexts) { if (classifiableTexts == null || classifiableTexts.size() == 0) { throw new IllegalArgumentException(); } Map<String, Integer> uniqueValues = new HashMap<>(); List<VocabularyWord> vocabulary = new ArrayList<>(); // count frequency of use each word (converted to n-gram) from all Classifiable Texts // for (ClassifiableText classifiableText : classifiableTexts) { for (String word : nGramStrategy.getNGram(classifiableText.getText())) { if (uniqueValues.containsKey(word)) { // increase counter uniqueValues.put(word, uniqueValues.get(word) + 1); } else { // add new word uniqueValues.put(word, 1); } } } // convert uniqueValues to Vocabulary, excluding infrequent // for (Map.Entry<String, Integer> entry : uniqueValues.entrySet()) { if (entry.getValue() > 3) { vocabulary.add(new VocabularyWord(entry.getKey())); } } return vocabulary; } }
新しいHashMapの<>(); class VocabularyBuilder { private final NGramStrategy nGramStrategy; VocabularyBuilder(NGramStrategy nGramStrategy) { if (nGramStrategy == null) { throw new IllegalArgumentException(); } this.nGramStrategy = nGramStrategy; } List<VocabularyWord> getVocabulary(List<ClassifiableText> classifiableTexts) { if (classifiableTexts == null || classifiableTexts.size() == 0) { throw new IllegalArgumentException(); } Map<String, Integer> uniqueValues = new HashMap<>(); List<VocabularyWord> vocabulary = new ArrayList<>(); // count frequency of use each word (converted to n-gram) from all Classifiable Texts // for (ClassifiableText classifiableText : classifiableTexts) { for (String word : nGramStrategy.getNGram(classifiableText.getText())) { if (uniqueValues.containsKey(word)) { // increase counter uniqueValues.put(word, uniqueValues.get(word) + 1); } else { // add new word uniqueValues.put(word, 1); } } } // convert uniqueValues to Vocabulary, excluding infrequent // for (Map.Entry<String, Integer> entry : uniqueValues.entrySet()) { if (entry.getValue() > 3) { vocabulary.add(new VocabularyWord(entry.getKey())); } } return vocabulary; } }
<>(); class VocabularyBuilder { private final NGramStrategy nGramStrategy; VocabularyBuilder(NGramStrategy nGramStrategy) { if (nGramStrategy == null) { throw new IllegalArgumentException(); } this.nGramStrategy = nGramStrategy; } List<VocabularyWord> getVocabulary(List<ClassifiableText> classifiableTexts) { if (classifiableTexts == null || classifiableTexts.size() == 0) { throw new IllegalArgumentException(); } Map<String, Integer> uniqueValues = new HashMap<>(); List<VocabularyWord> vocabulary = new ArrayList<>(); // count frequency of use each word (converted to n-gram) from all Classifiable Texts // for (ClassifiableText classifiableText : classifiableTexts) { for (String word : nGramStrategy.getNGram(classifiableText.getText())) { if (uniqueValues.containsKey(word)) { // increase counter uniqueValues.put(word, uniqueValues.get(word) + 1); } else { // add new word uniqueValues.put(word, 1); } } } // convert uniqueValues to Vocabulary, excluding infrequent // for (Map.Entry<String, Integer> entry : uniqueValues.entrySet()) { if (entry.getValue() > 3) { vocabulary.add(new VocabularyWord(entry.getKey())); } } return vocabulary; } }
全て分類さテキストからnグラムに変換) class VocabularyBuilder { private final NGramStrategy nGramStrategy; VocabularyBuilder(NGramStrategy nGramStrategy) { if (nGramStrategy == null) { throw new IllegalArgumentException(); } this.nGramStrategy = nGramStrategy; } List<VocabularyWord> getVocabulary(List<ClassifiableText> classifiableTexts) { if (classifiableTexts == null || classifiableTexts.size() == 0) { throw new IllegalArgumentException(); } Map<String, Integer> uniqueValues = new HashMap<>(); List<VocabularyWord> vocabulary = new ArrayList<>(); // count frequency of use each word (converted to n-gram) from all Classifiable Texts // for (ClassifiableText classifiableText : classifiableTexts) { for (String word : nGramStrategy.getNGram(classifiableText.getText())) { if (uniqueValues.containsKey(word)) { // increase counter uniqueValues.put(word, uniqueValues.get(word) + 1); } else { // add new word uniqueValues.put(word, 1); } } } // convert uniqueValues to Vocabulary, excluding infrequent // for (Map.Entry<String, Integer> entry : uniqueValues.entrySet()) { if (entry.getValue() > 3) { vocabulary.add(new VocabularyWord(entry.getKey())); } } return vocabulary; } }
())){ class VocabularyBuilder { private final NGramStrategy nGramStrategy; VocabularyBuilder(NGramStrategy nGramStrategy) { if (nGramStrategy == null) { throw new IllegalArgumentException(); } this.nGramStrategy = nGramStrategy; } List<VocabularyWord> getVocabulary(List<ClassifiableText> classifiableTexts) { if (classifiableTexts == null || classifiableTexts.size() == 0) { throw new IllegalArgumentException(); } Map<String, Integer> uniqueValues = new HashMap<>(); List<VocabularyWord> vocabulary = new ArrayList<>(); // count frequency of use each word (converted to n-gram) from all Classifiable Texts // for (ClassifiableText classifiableText : classifiableTexts) { for (String word : nGramStrategy.getNGram(classifiableText.getText())) { if (uniqueValues.containsKey(word)) { // increase counter uniqueValues.put(word, uniqueValues.get(word) + 1); } else { // add new word uniqueValues.put(word, 1); } } } // convert uniqueValues to Vocabulary, excluding infrequent // for (Map.Entry<String, Integer> entry : uniqueValues.entrySet()) { if (entry.getValue() > 3) { vocabulary.add(new VocabularyWord(entry.getKey())); } } return vocabulary; } }
+ class VocabularyBuilder { private final NGramStrategy nGramStrategy; VocabularyBuilder(NGramStrategy nGramStrategy) { if (nGramStrategy == null) { throw new IllegalArgumentException(); } this.nGramStrategy = nGramStrategy; } List<VocabularyWord> getVocabulary(List<ClassifiableText> classifiableTexts) { if (classifiableTexts == null || classifiableTexts.size() == 0) { throw new IllegalArgumentException(); } Map<String, Integer> uniqueValues = new HashMap<>(); List<VocabularyWord> vocabulary = new ArrayList<>(); // count frequency of use each word (converted to n-gram) from all Classifiable Texts // for (ClassifiableText classifiableText : classifiableTexts) { for (String word : nGramStrategy.getNGram(classifiableText.getText())) { if (uniqueValues.containsKey(word)) { // increase counter uniqueValues.put(word, uniqueValues.get(word) + 1); } else { // add new word uniqueValues.put(word, 1); } } } // convert uniqueValues to Vocabulary, excluding infrequent // for (Map.Entry<String, Integer> entry : uniqueValues.entrySet()) { if (entry.getValue() > 3) { vocabulary.add(new VocabularyWord(entry.getKey())); } } return vocabulary; } }
{:uniqueValues.entrySet()エントリ) class VocabularyBuilder { private final NGramStrategy nGramStrategy; VocabularyBuilder(NGramStrategy nGramStrategy) { if (nGramStrategy == null) { throw new IllegalArgumentException(); } this.nGramStrategy = nGramStrategy; } List<VocabularyWord> getVocabulary(List<ClassifiableText> classifiableTexts) { if (classifiableTexts == null || classifiableTexts.size() == 0) { throw new IllegalArgumentException(); } Map<String, Integer> uniqueValues = new HashMap<>(); List<VocabularyWord> vocabulary = new ArrayList<>(); // count frequency of use each word (converted to n-gram) from all Classifiable Texts // for (ClassifiableText classifiableText : classifiableTexts) { for (String word : nGramStrategy.getNGram(classifiableText.getText())) { if (uniqueValues.containsKey(word)) { // increase counter uniqueValues.put(word, uniqueValues.get(word) + 1); } else { // add new word uniqueValues.put(word, 1); } } } // convert uniqueValues to Vocabulary, excluding infrequent // for (Map.Entry<String, Integer> entry : uniqueValues.entrySet()) { if (entry.getValue() > 3) { vocabulary.add(new VocabularyWord(entry.getKey())); } } return vocabulary; } }
辞書の例:
| テキスト | フィルタunigramma | 辞書
|
|---|---|---|
| 12のタスクのシーケンスを見つける必要があります | ニーズ、騎士、結果的に、問題 | ニーズ、騎士、結果的に、任意のためのタスク、ADD、転位 |
| 任意のための問題 | 任意のためのタスク | |
| 任意の転置を追加します。 | 、任意のトランスポーズを追加 |
バイグラムを構築するためにも、一度最後に、実験後の辞書サイズと分類精度の比から最高の結果を生成し、代替に選挙を停止し、クラスを書きました。
クラスバイグラム
class Bigram implements NGramStrategy { private NGramStrategy nGramStrategy; Bigram(NGramStrategy nGramStrategy) { if (nGramStrategy == null) { throw new IllegalArgumentException(); } this.nGramStrategy = nGramStrategy; } @Override public Set<String> getNGram(String text) { List<String> unigram = new ArrayList<>(nGramStrategy.getNGram(text)); // concatenate words to bigrams // example: "How are you doing?" => {"how are", "are you", "you doing"} Set<String> uniqueValues = new LinkedHashSet<>(); for (int i = 0; i < unigram.size() - 1; i++) { uniqueValues.add(unigram.get(i) + " " + unigram.get(i + 1)); } return uniqueValues; } }
テキスト){ class Bigram implements NGramStrategy { private NGramStrategy nGramStrategy; Bigram(NGramStrategy nGramStrategy) { if (nGramStrategy == null) { throw new IllegalArgumentException(); } this.nGramStrategy = nGramStrategy; } @Override public Set<String> getNGram(String text) { List<String> unigram = new ArrayList<>(nGramStrategy.getNGram(text)); // concatenate words to bigrams // example: "How are you doing?" => {"how are", "are you", "you doing"} Set<String> uniqueValues = new LinkedHashSet<>(); for (int i = 0; i < unigram.size() - 1; i++) { uniqueValues.add(unigram.get(i) + " " + unigram.get(i + 1)); } return uniqueValues; } }
<>(nGramStrategy.getNGram(テキスト)); class Bigram implements NGramStrategy { private NGramStrategy nGramStrategy; Bigram(NGramStrategy nGramStrategy) { if (nGramStrategy == null) { throw new IllegalArgumentException(); } this.nGramStrategy = nGramStrategy; } @Override public Set<String> getNGram(String text) { List<String> unigram = new ArrayList<>(nGramStrategy.getNGram(text)); // concatenate words to bigrams // example: "How are you doing?" => {"how are", "are you", "you doing"} Set<String> uniqueValues = new LinkedHashSet<>(); for (int i = 0; i < unigram.size() - 1; i++) { uniqueValues.add(unigram.get(i) + " " + unigram.get(i + 1)); } return uniqueValues; } }
?」 class Bigram implements NGramStrategy { private NGramStrategy nGramStrategy; Bigram(NGramStrategy nGramStrategy) { if (nGramStrategy == null) { throw new IllegalArgumentException(); } this.nGramStrategy = nGramStrategy; } @Override public Set<String> getNGram(String text) { List<String> unigram = new ArrayList<>(nGramStrategy.getNGram(text)); // concatenate words to bigrams // example: "How are you doing?" => {"how are", "are you", "you doing"} Set<String> uniqueValues = new LinkedHashSet<>(); for (int i = 0; i < unigram.size() - 1; i++) { uniqueValues.add(unigram.get(i) + " " + unigram.get(i + 1)); } return uniqueValues; } }
「あなたがやって」、「あなたは」} class Bigram implements NGramStrategy { private NGramStrategy nGramStrategy; Bigram(NGramStrategy nGramStrategy) { if (nGramStrategy == null) { throw new IllegalArgumentException(); } this.nGramStrategy = nGramStrategy; } @Override public Set<String> getNGram(String text) { List<String> unigram = new ArrayList<>(nGramStrategy.getNGram(text)); // concatenate words to bigrams // example: "How are you doing?" => {"how are", "are you", "you doing"} Set<String> uniqueValues = new LinkedHashSet<>(); for (int i = 0; i < unigram.size() - 1; i++) { uniqueValues.add(unigram.get(i) + " " + unigram.get(i + 1)); } return uniqueValues; } }
<>(); class Bigram implements NGramStrategy { private NGramStrategy nGramStrategy; Bigram(NGramStrategy nGramStrategy) { if (nGramStrategy == null) { throw new IllegalArgumentException(); } this.nGramStrategy = nGramStrategy; } @Override public Set<String> getNGram(String text) { List<String> unigram = new ArrayList<>(nGramStrategy.getNGram(text)); // concatenate words to bigrams // example: "How are you doing?" => {"how are", "are you", "you doing"} Set<String> uniqueValues = new LinkedHashSet<>(); for (int i = 0; i < unigram.size() - 1; i++) { uniqueValues.add(unigram.get(i) + " " + unigram.get(i + 1)); } return uniqueValues; } }
" + unigram.get(I + class Bigram implements NGramStrategy { private NGramStrategy nGramStrategy; Bigram(NGramStrategy nGramStrategy) { if (nGramStrategy == null) { throw new IllegalArgumentException(); } this.nGramStrategy = nGramStrategy; } @Override public Set<String> getNGram(String text) { List<String> unigram = new ArrayList<>(nGramStrategy.getNGram(text)); // concatenate words to bigrams // example: "How are you doing?" => {"how are", "are you", "you doing"} Set<String> uniqueValues = new LinkedHashSet<>(); for (int i = 0; i < unigram.size() - 1; i++) { uniqueValues.add(unigram.get(i) + " " + unigram.get(i + 1)); } return uniqueValues; } }
これで私は停止することを決めたが、それは辞書の編纂のための言葉の可能性と、さらに処理されるまで。 たとえば、シノニムを定義することができ、共通の心にそれらをもたらすこと、などを思い付くために、あなたは自分自身の何かを行うことができます単語の類似性を分析することができます しかし、原則として、分類の精度の有意な増加が与えていません。
さて、先に行きます。 辞書内の要素の数に等しくなるニューラルネットワークの入力層のサイズは、我々は、計算しました。
私たちのタスクの出力層の大きさが特徴の可能な値の数と同じにすることです。 ユーザー、新しい機能を助けるために、システムのエラー:たとえば、私たちは、「アクセスタイプ」の特性のための3つの可能な値を持っています。 次に、出力層のニューロンの数は3に等しいです。 我々は出力層で受け取ることを期待予め数値の参照一意のセットを決定するのに必要な特性の各値に対してネットワークを学習した場合: - 第二のために、0 0 1 - 最初の値1 0 0 1 0 0第三のための...
隠された層の数及び寸法に関しては、その後特別な推薦がありません。 ソースは、各特定のタスクのために最適なサイズのみ実験により算出することができることを書くが、先細りの入力層と出力の大きさの範囲内で変化する大きされた1つの隠れ層、始まるネットワークをお勧めします。 まず、私は、入力層の2/3の隠れ層のサイズを作成して、隠された層の数と長さで実験します。 ここでは、ここであなたは、このテーマに関する理論とガイドラインのビットを読み取ることができます。 学習する必要がありますどのくらいのデータについて告げるもあります。
そこで、我々はネットワークを作成しました。 今、あなたは、私たちは、ニューラルネットワークの「送り」に適したテキストを数値に変換する方法を決定する必要があります。 これを行うために、我々は、 ベクトルテキストにテキストを変換する必要があります。 単語のユニークなベクトルを割り当てるために辞書内のすべての単語を予めは、必要、の量は、辞書のサイズに等しくなければなりません。 単語のベクトルを変更するためにネットワークを訓練した後は不可能です。 ここでは、4つの単語の辞書を検索する方法は次のとおりです。
| 辞書で単語 | ベクトルワード |
|---|---|
| こんにちは | 1 0 0 0 |
| どのように | 0 1 0 0 |
| 業務 | 0 0 1 0 |
| あなたに | 0 0 0 1 |
ベクトルテキストでの変換手順のテキストは、単語のテキストに使用されるベクトルの追加を意味します:テキストは、「?こんにちは、あなたの両方に」ベクター「1 1 0 1」に変換されます。 我々はすでに、ニューラルネットワークの入力にもたらすことができ、このベクター:入力層の各個々のニューロンのための各別々の番号(ニューロンの数は、テキストのベクトルの大きさにちょうど等しいです)。
ベクトルテキストを計算する方法
private double[] getTextAsVectorOfWords(ClassifiableText classifiableText) { double[] vector = new double[inputLayerSize]; // convert text to nGram Set<String> uniqueValues = nGramStrategy.getNGram(classifiableText.getText()); // create vector // for (String word : uniqueValues) { VocabularyWord vw = findWordInVocabulary(word); if (vw != null) { // word found in vocabulary vector[vw.getId() - 1] = 1; } } return vector; }
){ private double[] getTextAsVectorOfWords(ClassifiableText classifiableText) { double[] vector = new double[inputLayerSize]; // convert text to nGram Set<String> uniqueValues = nGramStrategy.getNGram(classifiableText.getText()); // create vector // for (String word : uniqueValues) { VocabularyWord vw = findWordInVocabulary(word); if (vw != null) { // word found in vocabulary vector[vw.getId() - 1] = 1; } } return vector; }
inputLayerSize]。 private double[] getTextAsVectorOfWords(ClassifiableText classifiableText) { double[] vector = new double[inputLayerSize]; // convert text to nGram Set<String> uniqueValues = nGramStrategy.getNGram(classifiableText.getText()); // create vector // for (String word : uniqueValues) { VocabularyWord vw = findWordInVocabulary(word); if (vw != null) { // word found in vocabulary vector[vw.getId() - 1] = 1; } } return vector; }
classifiableText.getText())。 private double[] getTextAsVectorOfWords(ClassifiableText classifiableText) { double[] vector = new double[inputLayerSize]; // convert text to nGram Set<String> uniqueValues = nGramStrategy.getNGram(classifiableText.getText()); // create vector // for (String word : uniqueValues) { VocabularyWord vw = findWordInVocabulary(word); if (vw != null) { // word found in vocabulary vector[vw.getId() - 1] = 1; } } return vector; }
//単語が語彙で見つかりました private double[] getTextAsVectorOfWords(ClassifiableText classifiableText) { double[] vector = new double[inputLayerSize]; // convert text to nGram Set<String> uniqueValues = nGramStrategy.getNGram(classifiableText.getText()); // create vector // for (String word : uniqueValues) { VocabularyWord vw = findWordInVocabulary(word); if (vw != null) { // word found in vocabulary vector[vw.getId() - 1] = 1; } } return vector; }
こことここであなたは、さらに分析のためのテキストの準備について読むことができます。
分類精度
辞書を形成するための異なるアルゴリズムを試した後に隠された層と寸法の異なる数で、私は、このバージョンに落ち着い:辞書形成するカットオフFilteredUnigramのredkoispolzuemyh語と共に使用します。 第1の層と第一層の大きさの1/4 - - 第2の層2つの隠された層は、辞書サイズの寸法の1/6行います。
(このサイズのネットワークのための非常に少ないです)〜20の000の文章で訓練した後、我々は持っている2000参照テキストのネットワークを実行します。
| Nグラム | 精度 | 辞書サイズ
(redkoispolzuemyh言葉なし) |
|---|---|---|
| Unigramma | 58% | 〜25000 |
| フィルタunigramma | 73% | 〜1200年 |
| バイグラム | 63% | 〜8000 |
| フィルタバイグラム | 69% | 〜3000 |
一つの特性のため、この精度。 あなたは、パフォーマンスのために、より精度が必要な場合は、次のように、計算式は以下のとおりです。
- 右のすべての特性を推測する確率は、各特性を推測の確率の積に等しいです。
- 少なくとも一つの特性を推測する確率は、一と各特性の不正確な決意の確率の積との差です。
例:
73% - 仮定、オーディオ特性の精度は65%の第2の特徴です。 直ちに 0.65 * 0.73 = 0.4745 = 47.45パーセントであり、 少なくとも1つの特性が、1-(1-0,65)*(1-0,73)で判定精度精度の両方を決定= 0 、9055 = 90.55パーセント。
これは、入力データの前処理マニュアルを必要としないツールのために良い結果です。
そこ1である「しかし」:「ヘルプ」のカテゴリに、より正確な分類からのテキストのカテゴリ「システムエラー」から以下同様のテキスト:精度が異なるカテゴリーに分類されるべきテキストの類似性に大きく依存しています。 そのため、異なるタスクと異なる歌詞で同じネットワーク設定、および語彙の精度に大きな違いが生じる場合がございます。
概要プログラム
私はあなたがテキストを分類したいことにより、特性の数に縛られない普遍的なプログラムを書くことにした、前に言いました。 私は、プログラムの唯一のアルゴリズムを説明、開発のすべての詳細を説明しませんここにいる、とソースを参照するには、記事の最後になります。
プログラムの一般的なアルゴリズム:
- あなたが最初に起動するとプログラムがトレーニングデータとXLSXファイルを要求します。 ファイルは、1枚のまたは2つのシートから構成されてもよいです。 トレーニングのためのデータの最初のページで、第二に - 更なる試験のネットワーク精度についてのデータ。 シートの構造が一致しています。 最初の列は、テキストを分析する必要があります。 後続の列内のテキストの特性の値を含まなければならない(任意の数が存在してもよいです)。 最初の行は、これらの特性の名前が含まれている必要があります。
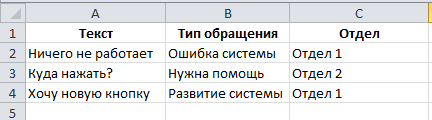
- このファイルに基づき辞書、決定した特性と各特性のために許可されるユニークな値のリストを構築されています。 このすべては、リポジトリに格納されています。
- これは、各特性のための個別のニューラルネットワークを作成します。
- すべての作成されたニューラルネットワークは訓練され、保持されます。
- あなたはすべての訓練されたニューラルネットワークがロードされて保存され、次回。 プログラムは、テキストを解析する準備ができています。
- 得られたテキストは、それぞれ独立して、ニューラルネットワークの処理され、そして全体的な結果は、各特性の値として与えられます。
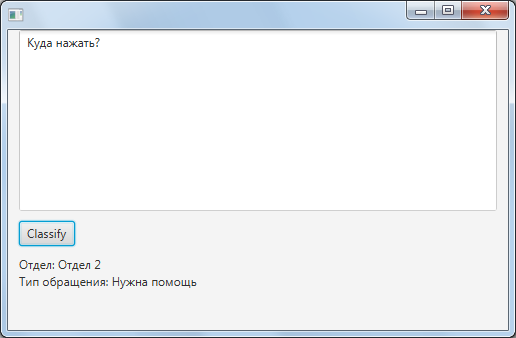
計画:
- 分類器(例えば、他のタイプの追加畳み込みニューラルネットワークと単純ベイズ分類器を )。
- 組み合わせunigrammとバイグラムからなる辞書を使用してみてください。
- タイプミスや文法の誤りを排除する仕組みを追加します。
- 同義語の辞書を追加します。
- 彼らは通常、情報ノイズあるとして、あまりにも頻繁に言葉を避けてください。
- 分析されたテキストにその影響への言葉のために、個々の意味に重みを追加する以上でした。
- あなたが別のライブラリの基本的な機能を作ることができるように、APIを簡素化し、アーキテクチャを変更するために少し。
ソースコードのビット
ソースは、特定の設計パターンの使用例として有用であり得ます。 別の記事でそれを我慢しているので、この記事でも聞かせて、意味がありませんが、また、私は私の経験を共有しているので、それらについて沈黙することも望ましいことではありません。
- パターン「戦略」 。 NGramStrategyインタフェースとそれを実装するクラス。
- パターン「オブザーバー」 。 クラスLogWindowと分類器、オブザーバーと観測インターフェイスを実装します。
- パターン「デコレーター」 。 クラスバイグラム。
- パターン「シンプル工場。」 getNGramStrategy法()NGramStrategyインタフェース。
- パターン「ファクトリメソッド」 。 getNgramStrategyメソッド()NGramStrategyTestクラス。
- パターン「抽象ファクトリー」 。 クラスJDBCDAOFactory。
- パターン(アンチパターン?) "シングル" 。 クラスEMFProvider。
- パターン「テンプレートメソッド」 。 initializeIdeal方法()NGramStrategyTestクラス。 確かに、そのアプリケーションの非常に古典はありません。
- 柄«DAO» 。 インタフェースCharacteristicDAO、ClassifiableTextDAOなど
完全なソースコード: https://github.com/RusZ/TextClassifier
建設的な提案と批判を歓迎します。
PSは:レナの場合は、心配しないでください - それは架空の人物です。