
過去10年間で、テクノロジーは大きく進歩しました。 モノのインターネット、クラウドシステム、人工知能の形態、ニューラルネットワーク、認知技術。 これはすべて比較的最近になって登場しましたが、これは私たちの生活を積極的に変えています。 IBMは、変更を前向きにするために多大な努力をしてきました。 これはすべて、喜びのためではなく、完全に実用的な目的のために行われます。 実際、現代の科学とビジネスのニーズは非常に大きいということです。 そして、これらのニーズを満たすために、新しいツールが必要です。 その1つはIBM Watsonです。IBMWatsonは、学習し、最大のデータ配列の個々の要素間の関係を識別し、ユーザーを含むその環境と対話することができる認知プラットフォームです。
HabrahabrとGeektimesで、当社はIBM Watsonがどのように役立つかについて繰り返し話してきました。 しかし、システムはどのように機能しますか? 一般に、その機能は環境およびさまざまな要因の分析に基づいています。 これにより、プラットフォームは特定の決定を下し、質問に答えることができます。 以下は、認知システムのいくつかのコンポーネントの動作原理の比較的簡単な要約です。 このトレーニング、言語処理、および質問への回答。
Watsonの学習方法
認知システムの重要な要素は、意思決定と質問への回答に関与する人の思考の機能の一部をエミュレートすることです。
ワトソンのトレーニングはいくつかの段階で実施されます。 最初は情報のロードです。 このシステムの開発者は、科学、技術、その他あらゆる分野での使用に適したものにしようとしています。
すべては、特定のトピックに関する関連情報をWatsonデータベースにロードすることから始まります。 ここで、シャーロックホームズと、演ductive法の有効性と関連知識の重要性に関する彼の説明を思い出すことができます。 特定の問題を研究しているホームズは、この問題に直接関連する情報のみをメモリに「ロード」しました。 Watsonについても同様です。開発者がシステムを新しいサブジェクトでトレーニングすることを決定すると、トレーニングのトピックに関連する関連情報のみをメモリにロードします。 古くて関連性の低いデータは検証され、削除されます。 これは継続的なプロセスです。
次にIBM Watsonラインが登場します。データの前処理は、インデックスおよびその他のメタデータの構築から始まり、将来のより効率的な作業を可能にします。 「知識グラフ」が作成され、マスタリングされるマテリアルの重要な概念を表します。
データの前処理が終了すると、人々は再びWatsonがデータを解釈できるように働き始めます。 これは、専門家が質疑応答の形でシステムを使い始めたときに、機械学習の助けを借りて行われます。 この方法は、研究対象のトピックに関連する言語パターンを作成するのに役立ちます。
データを処理および同化するもう1つの方法は、Watsonのユーザーとの継続的なやり取りです。 専門家はこの活動を定期的に評価し、Watsonの能力の向上、ますます複雑になる質問への回答、以前に受け取った情報の更新を支援します。 つまり、人間の意思決定をエミュレートすることです。 これは、科学、医学、ビジネスの両方で必要です。
実際、ワトソンがよりスマートになり、ユーザーや開発者からフィードバックを受け取り、自分の過ちから学ぶのは「動的学習」です。
Watsonは自然言語とどのように連携しますか?
質問が口頭または書面のどちらで行われようと、システムは複雑なセマンティック構成を分析し、セマンティックだけでなくテキストの感情的な負荷も理解できなければなりません。 Watsonがテキストの意味を正しく判別するために、開発者はシステムにコンテンツ分析の質問応答システム(Deep Question * Answering、DeepQA)を統合しました。 これは基本の基礎であり、認知プラットフォームの作業はこのシステム上に構築されます。
彼女のおかげで、ワトソンは彼らの言うことを理解し、適切で適切な答えを出すことができます。 しかし、機械が人の言語を理解することは非常に困難です。 単語と用語の多くの定義は非論理的です。 「恥をかいて燃やす」という同じ表現を取るために-人は彼を完全に理解しています(もちろん、彼はそれを前に聞いていません)。 車の場合、その車がワトソンでない場合、この表現はナンセンスです。 前述のように、システム開発者は徐々にイディオムを理解し、語彙の接続を確立してパターンを構築するようワトソンに教えています。
とりわけ、システムはテキストの感情的な内容を認識することができます。 これを行うために、2016年にToneAnalyzer 、 EmotionAnalysis、およびVisualRecognitionの 3つのAPIが一度に追加され ました 。 TexttoSpeech (TTS)サービスは更新され 、感情の新たな機会が生まれました。また、 Expressive TTS音声モジュールAPIへのアクセスが公開されました(作業は12年間継続されています)。 一般に、システムが自然言語で動作するのを支援するモジュールおよびサービスは、常に開発および追加されています。 これは、前述のように、動的学習のコンポーネントの1つです。 絶え間ない進歩、開発はプロジェクトのタスクの1つであり、成功裏に実装されています。
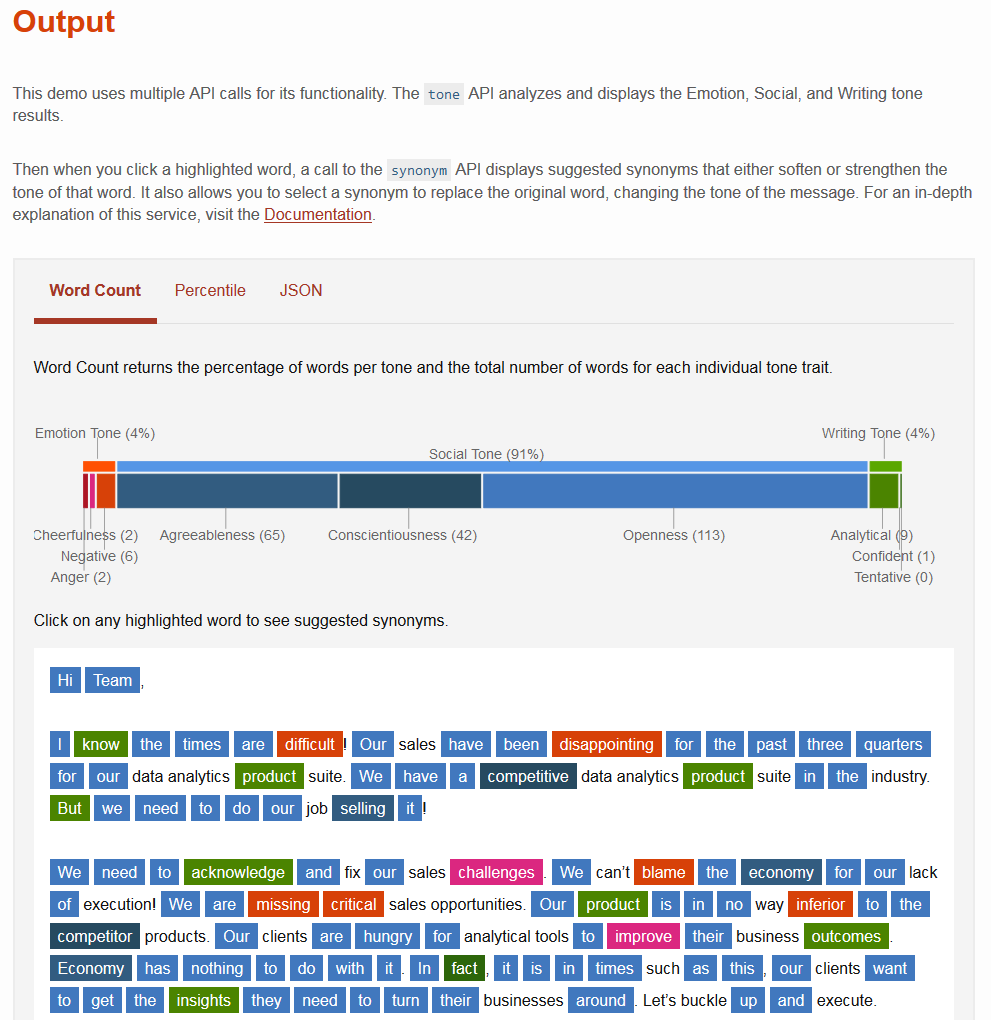
IBM Watsonシステムを使用したレターのセマンティックおよび感情的な充填の分析の一例
Watsonは、テキスト内のプレゼンテーションのスタイルを決定し、ポジティブとネガティブを含む感情を識別し、画像を認識して分類できるようになりました。
Watsonは質問にどのように答えますか?
簡略化すると、すべてが次のようになります。
1.システムが質問に回答できるようにするには、メモリに関連データが必要です。 これはすでに上記で言及されています。 専門家がさまざまな情報をシステムにアップロードし、必要に応じて使用できるように、このデータにインデックスが付けられます。
2.さらに質問がテキストまたは音声形式でシステムに送信されます。
3.質問はシステムによって分析され、Watsonは検索クエリを選択し、データベース内の必要な関連情報の検索を開始します。 これは、Googleの仕組みと比較できます。
4.ある程度の確率で、希望する回答が含まれている可能性のあるフレーズを分析することにより、多くの仮説が生成されます。 質問の言語と可能な回答のそれぞれの言語の詳細な比較が実行されます。 検索クエリ結果のデータベースが生成されています。
5.各結果は特定の方法で評価され、ポイントを獲得します。 回答が質問の領域に関連する程度を分析します。
6.いずれかの回答のスコアが高いほど、ランクが高くなります。
7.最終分析の後、Watsonがその回答を関連性があると見なした場合、ユーザーに提供されます。
質問に対する答えを見つける実際のプロセスは、多くの場合並列モードで機能するいくつかのアルゴリズムを使用して各フレーズが作成されるため、はるかに複雑です。 Watson用に何百もの推論アルゴリズムが開発されました。 一致する用語と同義語を検索するものもあれば、時間的および空間的特徴を調べるものもあれば、コンテキスト情報の必要なソースを検索して分析するものもあります。
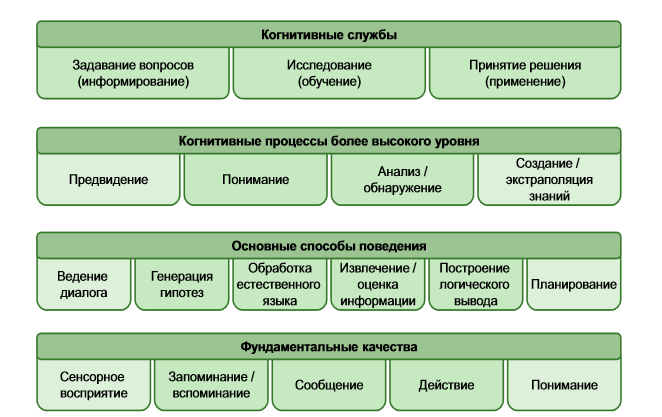
正しい答えを得るために、システムは追加のデータソースを使用します。 たとえば、インターネット上のニュース、技術文献、参考書。 行内のすべての資料はコピーされませんが、無関係な情報を選別して関連性が検証されます。 コグニティブプラットフォームの非常に優れたパフォーマンスにより、このプロセスには数秒しかかかりません。
この資料を締めくくりますが、この記事が読者の関心のあるすべての問題を明らかにするわけではないことに注意してください。 コメントで質問してください。専門家の回答を収集し、コメントに「基づいて」プレハブ資料を公開します。 これはおそらく、本当に興味のある質問に答えるのに最適なオプションの1つです。