幻想を少し払拭するために、キングストンがリリースしたUSBフラッシュ8Gbの最終製品の例を使用して、SKYMEDI SK6211が製造したNANDコントローラーの動作アルゴリズムをリバースエンジニアリング手法で分析してみます。

図 1
完全な分析のために、最初に大量のファイルを記録することによってドライブの使用の模倣を作成し、続いて部分的にランダムな削除と再記録を行います。 次に、LBA範囲の半分をゼロで書き込みますが、各「セクター」のゼロに加えて、オフセット0x0 DWORDにその番号を付けます。 論理範囲の後半を0x77パターンで記述します(このパターンは、ノイズの多いデータアルゴリズムの分析に比較的便利です)。
両方のNANDフラッシュメモリチップをはんだ付けします。 この例では、サムスン製で、 TSOP -48で実行されるK9HBG08U1Mをマークしています。 動作特性:ページサイズ-2112バイト、ブロックサイズ-128ページ、プレーンのブロック数-2048、バンクのプレーン数-4、物理バンクの数-2. 2つのマイクロサーキットの合計容量2112 * 128 * 2048 * 4 * 2 * 2 = 8 858 370 048バイト。

図 2
図 図2は、ブロックの番号付けの原理を示しています(ブロックは128ページで構成されています)。 このチップは、同時に2つのプレーンでプログラミング/消去操作を同時に実行できることに注意してください(0.1と2.3のバリエーション)。 超小型回路の機能とそれらの操作の微妙な違いをさらに詳しく知りたい場合は、現在一般公開されているK9HBG08U1M.pdfで利用可能な技術文書(データシート)を探すことができます。
超小型回路を読み取るには、Flash Extractorコンプレックスの一部であるNANDリーダーを使用します。 当時、SK6211コントローラーが普及したとき、データ復旧用に設計されたこの複合体は、販売されているほとんど唯一の分析ツールでした。

図 3
SK6211コントローラーによるデータ配信アルゴリズムの分析に着手すると、広告ソースからの超小型回路との並列動作の可能性と、わずかに異なる2種類のエラー修正コード(ECC)について学習します。 この出版物では、トピックが広大であるため、エラー修正コードの機能、およびそれらに関連する数学コンポーネント全体の説明を省略します。
データ分析の最初のタスクは、ノイズの多いデータがメモリに書き込まれる兆候を確認することです。 これを行うには、記録した0x77パターンを検索し、完全に埋められた多くのページを見つけようとします。 しかし、検索結果は成功につながらないため、データが変更された形式で記録されていると結論付けることができます。 ダンプをスクロールすると、最後の64バイトを除く値0x88で埋められた多数のページ、および各512バイトブロックの先頭の4バイトと最後の64バイト(ページ2112バイトの範囲内)を除く0xFFで完全に埋められた多数のページが見つかります。 USBフラッシュに記録したパターンに基づいて、データの反転があると想定します。 データの反転を実行する前に、NANDページのコンテンツを分析して、サービスデータの場所を確立します。 パターンを埋める場所では、反転した均一値をサービスデータから区別するのは非常に簡単です。サービスデータは、完全に同一のバイトシーケンスで構成されていません。

図4
使用済みページのSK6211は、2048バイトのデータ( DA )を割り当て、サービスデータ( SA )を格納するために64バイトを割り当てます。 16バイトの4つのデータグループがよくトレースされます。これは、ページに含まれる512の4つのブロックへの適用性を示唆しています。
数千ページの最初の16バイトグループの内容をリストします。

図 5
図 図5は、最初の4バイトが順序付けられたままであり、カオスコンテンツが残りの12にあることを示しています。これに基づいて、各行の最後の12バイトにエラー訂正コードが含まれると仮定できます。 NANDチップが動作するブロックが128ページであることを知って、ブロックサイズ2112 * 128 = 270 336(0x42000)バイトを計算します。 0x00108000から、1ブロック前方、つまり0x0014a000のページに進みます。

図 6
図の内容から 5および図 6第3バイトがメモリのNANDブロックのページ番号の役割を果たすことは明らかです。 NANDメモリのすべての空でないブロックを表示するとき、この仮定は反論されません。
図 7
2ページの各ページのサービスデータの0および1バイトで同じ値。 このバイトのペアは、ブロック番号用に予約されていると想定できます。 すべてのブロックのすべての値を導き出し、最初のバイトの下位ニブルでは0x0〜0x3の値が使用され、ゼロバイトでは0x00〜0xFFの値が使用されることがわかります。 最初のバイトの高いニブル値には、より多様な意味があります。 番号付けに10ビットが使用されると仮定します。これは、サービス領域の最初のバイトの最下位2ビットから上位部分として、ゼロバイトから8ビットが下位部分として形成されます。 最初の0x400ブロックの数値を表示することにより、仮定の精度を確認します。 それらを昇順で並べ替えると、0x000から0x3C3までの数字のチェーンが連続して配置されていることがわかります。これにより、仮定が正しいことが確認されます。 0x400ブロックの残りのグループに対して同様のチェックを実行し、誤った解釈の可能性を最終的に排除します。
サービスデータを除き、データの反転を実行し、データの並列化メカニズムを分析します。 各ダンプのブロック内の論理番号を分析して、異なるバンクでの記録の対称性に関する仮定を確認しましょう。 SK6211の場合、対称記録の仮定が確認されます。 論理番号0x000のブロックを探します。512個の各データブロックには、シリアル番号とコンテンツとしてゼロが含まれています。 私たちが記録したデータの実際の場所に基づいて、データの位置のテーブルを作成します。
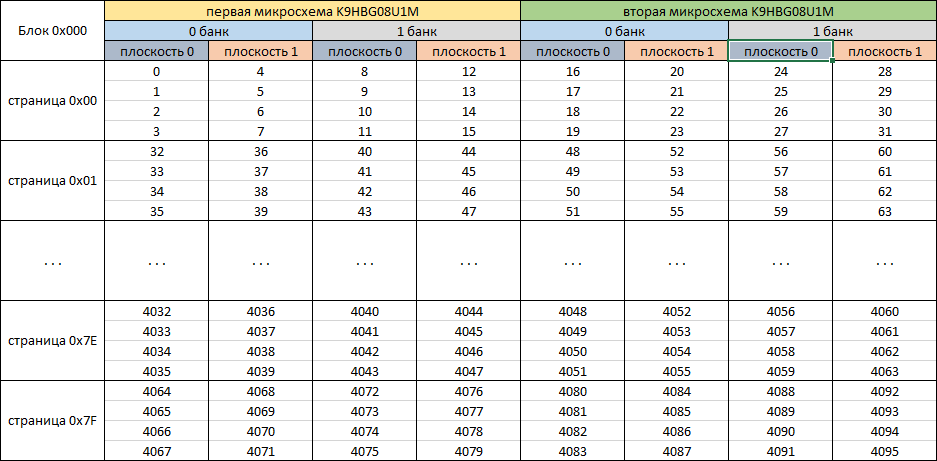
図 8
データの配置に従って、このチップセットのコントローラーが最も効率的な並列化を実装して高性能を実現していることがわかります。 データ並列化メカニズムを考慮して、変換システムがドライブマイクロコード0x42000 * 8 = 0x210000バイトで動作するブロックサイズを計算します。 オーバーヘッドを破棄すると、ブロックサイズは0x40000 * 8 = 0x200000(2 097 152)バイトになります。
さらなる分析のために、データの拡散を排除し、それらを2 MBのソリッドブロックに収集する必要があります。

図 9
最初のステップは、偶数ブロックと奇数ブロックにページ番号を付けることにより、プレーン間の並列化を排除することです。
2番目のステップは、各NANDメモリチップの0と1バンクの2倍のページサイズを結合することです。
3番目のステップは、両方のNANDメモリチップのクアッドページサイズを結合することです。
結果のダンプ内の2MBブロックの内容を分析すると、番号が付けられた「セクター」の単調に増加するシーケンスが観察され、データ並列化アルゴリズムの分析の正確性が確認されます。
次に、プレキャストダンプで、ブロックの配置と論理バンクへの編成を確認します。

図 10
数十個のブロックを検索し、シリアル番号で収集します。 コレクションの結果に基づいて、ブロック内のセクターの番号付けが結合されていることを確認します。 また、最初の2つのオーバーヘッドバイトの10ビットがブロック番号であるという以前の仮定は正しいです。
合計チップサイズは8 858 370 048(0x210000000)バイトで、トランスレーターのブロックサイズは2 162 688(0x210000)です。 合計ブロック0x210000000 / 0x210000 = 0x1000(4096)。 使用される番号の桁数と実際の番号付けに基づいて、ブロック番号が0x400(1024)を超えることはできないため、ブロードキャストには4つの論理バンクがあると結論付けることができます。 結果のダンプを4つの等しい部分(それぞれ0x400ブロック)に条件付きで分割し、各部分のブロック番号を推定し、これに基づいて、各論理バンクのブロードキャストに含まれるブロックの数を想定します。

図 11
各論理バンクのサイズは0x400よりも著しく小さいことに注意してください。 この必要性は、サービス構造に、そして最も重要なことには、ウェアレベリングメカニズムの効果的な動作に、ある量の「余分な」ブロックが必要であるという事実によって決定されます。 メカニズムは、コンテンツが変更された各ブロックがブロードキャストから除外され、バックアップに分類されるという原則に基づいて実装されます。その場所は、変更されたデータを記録する前にブロードキャストに含まれず、バックアップと見なされたブロックによって引き継がれます。 各ブロックの記録のカウンターを考えると、メカニズムは非常に効果的に機能します。 このアルゴリズムのアキレス腱は大量の不変データであり、ローテーションでの記録には比較的少数のブロックが関与します。
この原則は、ダンプ内のブロックの場所によって非常に明確に確認されます。 図によると 10論理空間が実現されるブロックの散布がどのように非線形であるかを見ることができます。 NANDメモリチップをはんだ付けし、USBフラッシュをコンピューターに接続し、最初の4096個の「セクター」で一定数のレコードを実行します。NANDメモリチップをドロップアウトして読み取り、結果のダンプのブロックの順序を収集して評価します。

図 12
ご覧のとおり、残りのブロックは変更せずに、論理番号0x000のブロックが別の場所に「移行」されています。 古いアドレスでは、ユーザーデータ領域とサービス領域の両方にあるブロックのすべてのページが0xFFで完全に埋められています。これは、このブロックがクリアされ、変換から除外されていることを示します。
結果の両方のダンプを比較すると、変更されたデータに加えて、ゼロブロック内のサービスデータに変更があり、トランスレーターの構造がどのように形成されているかを分析できます。
このような分析方法により、USB NANDコントローラーの動作アルゴリズムに関する十分なデータを取得して、それらを使用して調査中のコントローラーに基づいて損傷したドライブから情報を回復できます。また、データの並列化とウェアレベリングのメカニズムを実際に確認できます。 また、翻訳者のデバイスとUSBフラッシュ分析に基づいて(追加分析はFAT32でフォーマットされ、数千のファイルで満たされたドライブで実行されます)、ファイルシステム構造を持つブロックにはブロックの特権割り当てがないことに気付くことができます。
次の投稿:Seagate FreeAgent Go外付けハードドライブからのデータの回復
前の投稿:LinuxベースのNASで破損したRAID 5アレイからデータを回復する