1年以上前、Mail.Ru Groupでスパマー対策担当者として働いていたとき、それは私を襲い、mallocの実験について書きました。 そのとき、私は喜んでモスクワ物理学技術研究所で AKOSに関するセミナーを開催するのを手伝い、メモリ割り当てに関するトピックがありました。 トピックは大きく、非常に興味深いものですが、コアの低レベルと非常にアルゴリズム的に集中した構造の両方をカバーしています。 すべての教科書では、動的メモリ割り当ての主な問題の1つはその予測不能性であると書かれています。 sayingにもあるように、私は身代金を知っているだろう-私はソチに住んでいるだろう。 オラクルがメモリの割り当てと解放に応じて計画全体を事前に伝えた場合、ヒープの断片化、ピークメモリ消費などを最小限に抑える最適な戦略を立てることができます。 ここから、手動アロケーターに大騒ぎしました。 思考の過程で、ロギングツールmalloc()
およびfree()
欠如に出会いました。 私はそれらを書かなければなりませんでした! それについてちょうど記事がありました(私はmacOSも勉強しました)。 2つの部分が計画されましたが、人生は突然変わり、 malloc()
にはmalloc()
ませんでした。 だから、正義を取り戻し、約束を実現する時が来ました 。 たくさんの仕事を予測する深い訓練を受けてください。
中:
-
libtracemalloc
、malloc()
インターセプターの改善。 - KerasでのLSTMの構築-ディープリカレントネットワーク。
- 実際のアプリケーションの例を使用してモデルをトレーニングします( vcmi / vcmi-そして、あなたは、ヒーローズIIIはどこから来たのだと思いましたか?)。
- 予想外に良い結果に驚いています。
- 技術の実用化について空想しています。
- ソース
面白い? 猫へようこそ。
libtracemalloc
最初の記事では、 malloc()
のみをmalloc()
。 その実装にはいくつかの欠点がありました。
- 呼び出しのシリアル化中にマルチスレッドが無視されました。 つまり、メモリが割り当てられたスレッドから情報を失いました。
- ファイルへの書き込み時にマルチスレッドが無視されました。
write()
呼び出しは、ミューテックスなしで、競争的に行われました。 POSIXにはアトミックな性質が必要であるという事実にもかかわらず、 バージョン3.14より前のLinuxでは、位置付けに関する不快なバグがありました 。 -
free()
でログインしていません。
次のコード修正(1)および(2):
int fd = 0; void* (*__malloc)(size_t) = NULL; pthread_mutex_t write_sync = PTHREAD_MUTEX_INITIALIZER; inline void get_time(long* sec, long* mcsec) { /* ... */ } void* malloc(size_t size) { if (!__malloc) { __malloc = (void*(*)(size_t)) dlsym(RTLD_NEXT, "malloc"); } if (!fd) { fd = open(LOG, O_WRONLY | O_CREAT | O_EXCL, 0666); if (fd < 0) { return __malloc(size); } } long sec, mcsec; get_time(&sec, &mcsec); void* ptr = __malloc(size); char record[64]; pthread_mutex_lock(&write_sync); write(fd, record, sprintf(record, "%ld.%06ld\t%ld\t%zu\t%p\n", sec, mcsec, pthread_self(), size, ptr)); pthread_mutex_unlock(&write_sync); return ptr; }
したがって、 pthread_self()
を使用し、mutexの下でwrite()
を実行しwrite()
。 よく見ると、 open()
フラグでO_EXCL
を見ることができます。 初期のfork()
動作を修正するために追加しました。 たくさんの仕事を始める前に。 2つの分岐したプロセスが同時にファイルを開き、互いに上書きしました。
修正する必要があります(3):
void (*__free)(void*) = NULL; void free (void *ptr) { if (!__free) { __free = (void(*)(void*)) dlsym(RTLD_NEXT, "free"); } if (!fd) { __free(ptr); return; } long sec, mcsec; get_time(&sec, &mcsec); char record[64]; pthread_mutex_lock(&write_sync); write(fd, record, sprintf(record, "%ld.%06ld\t%ld\t-1\t%p\n", sec, mcsec, pthread_self(), ptr)); pthread_mutex_unlock(&write_sync); __free(ptr); }
ロギングは、 malloc()
と同様に完全に行われます。
その結果、次のような結果が得られます。
0.000000 140132355127680 552 0x2874040 0.000047 140132355127680 120 0x2874270 0.000052 140132355127680 1024 0x28742f0 0.000079 140132355127680 -1 0x2874270 0.000089 140132355127680 -1 0x28742f0 0.000092 140132355127680 -1 0x2874040 0.000093 140132355127680 -1 (nil) 0.000101 140132355127680 37 0x2874040 0.000133 140132355127680 32816 0x2874070 0.000157 140132355127680 -1 0x2874070 0.000162 140132355127680 8 0x2874070
KerasのLSTM
そもそも、正確に予測したいものを決定します。 malloc()
およびfree()
の呼び出しの以前の履歴から、さらにサイズのある将来の呼び出しのシーケンスをすぐに予測したいと思います。 注意を向けて、メモリのどのセクションが解放されるかすぐに示すのは非常にクールですが、好奇心reader盛な読者がこれを行うことをお勧めします-優秀な卒業論文が出てきます。 ここでは、より簡単に、解放されるメモリ量を予測します。
次のポイントは、RMSEで正確なサイズを予測することは、腐敗した有害な作業であることです。 私が試したのは、ネットワークがデータセット全体の平均値に不法に収束することです。 したがって、有名なバディアロケーターのように、サイズクラスを2の累乗で導入します 。 つまり、予測問題は分類問題として提起されます。 例:
| サイズ | クラス |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 2 |
| 4 | 3 |
| 5 | 3 |
| 6 | 3 |
合計で32のクラスがあり、 malloc(uint32_t size)
精神的な(誤った)制限をmalloc(uint32_t size)
。 実際には、64ビットのsize_t
があり、4GiB以上を割り当てることができます。
クラスをfree()
から対応するmalloc()
への呼び出しから取得します。 解放されたメモリへのポインタを知っています。 malloc()
クラスとfree()
クラスを何らかの形で区別するために、後者に32を追加し、合計で64のクラスがあります。 率直に言って、これはかなりの量です。 データにパターンがある場合、最も愚かなネットワークでさえ、そこから何かを学ぶ必要があります。 次のコードは、 libtracemalloc
から受け取ったログを解析します。
threads = defaultdict(list) ptrs = {} with gzip.open(args.input) as fin: for line in fin: parts = line[:-1].split(b"\t") thread = int(parts[1]) size = int(parts[2]) ptr = parts[3] if size > -1: threads[thread].append(size.bit_length()) ptrs[ptr] = size else: size = ptrs.get(ptr, 0) if size > 0: del ptrs[ptr] threads[thread].append(32 + size.bit_length())
ご覧のとおり、新しいポインターを保存し、古いポインターを削除します。まるで束をエミュレートするかのようです。 次に、 threads
辞書を消化可能なx
とy
変換する必要があります。
train_size = sum(max(0, len(v) - maxlen) for v in threads.values()) try: x = numpy.zeros((train_size, maxlen), dtype=numpy.int8) except MemoryError as e: log.error("failed to allocate %d bytes", train_size * maxlen) raise e from None y = numpy.zeros((train_size, 64), dtype=numpy.int8) offset = 0 for _, allocs in sorted(threads.items()): for i in range(maxlen, len(allocs)): x[offset] = allocs[i - maxlen:i] y[offset, allocs[i].bit_length()] = 1 offset += 1
ここで、 maxlen
は、予測するコンテキストの長さです。 デフォルトでは、100に設定します。モデル自体を作成するために残ります。 この場合、2つのLSTMレイヤーとフルトップリンクが標準です。
from keras import models, layers, regularizers, optimizers model = models.Sequential() embedding = numpy.zeros((64, 64), dtype=numpy.float32) numpy.fill_diagonal(embedding, 1) model.add(layers.embeddings.Embedding( 64, 64, input_length=x[0].shape[-1], weights=[embedding], trainable=False)) model.add(getattr(layers, layer_type)( neurons, dropout=dropout, recurrent_dropout=recurrent_dropout, return_sequences=True)) model.add(getattr(layers, layer_type)( neurons // 2, dropout=dropout, recurrent_dropout=recurrent_dropout)) model.add(layers.Dense(y[0].shape[-1], activation="softmax")) optimizer = getattr(optimizers, optimizer)(lr=learning_rate, clipnorm=1.) model.compile(loss="categorical_crossentropy", optimizer=optimizer, metrics=["accuracy", "top_k_categorical_accuracy"])

メモリを慎重に処理するために、トレーニングされていない埋め込みを使用し、事前に1つのホットエンコーディングを実行しません。 T.O. x
とy
8ビット(64 <256)で、ミニバッチは32ビットです。 非常に短時間で実行されるプログラムは数千万のサンプルを生成するため、これは重要です。 neurons
デフォルトは128で、ドロップアウトはありません。 トレーニングを始めましょう!
model.fit(x, y, batch_size=batch_size, epochs=epochs, validation_split=validation)
export TF_CPP_MIN_LOG_LEVEL=1
をexport TF_CPP_MIN_LOG_LEVEL=1
ことを強制されました。それ以外の場合、TensorflowはPoolAllocatorsをスパムしました。
結果
実験として、 vcmi / vcmiを取り上げます。これは、私が密輸に使用していた3番目のヒーローエンジンのGPL実装です。 ちなみに非常に完全で優れた実装ですが、緊急には自動テストが必要です。 そして、私たちはそれについて話しているので、Python APIをエンジンに固定し、ニューラルネットワークAIの実装を試みたいと思います。 時々、人々は反対し、ヒーローには多くの自由度があると言います。 私は、誰もAlphaGoをすぐに強制することはありません。あなたは小さな戦いから始められます。
クローンを作成し、vcmiコードを収集し、元のリソースを取得し、ゲームを実行して、ヒープコールログを収集します。
# ... easy ... LD_PRELOAD=/path/to/libtracemalloc.so /path/to/vcmiclient
私はrog慢を開始し、数週間さまよい、リソースを収集しました。 速度は大幅に低下しますが、それはあなたにとって無意味ではありません。 結果のログはGoogleドライブ -94MiBにアップロードされました 。 最初の32クラスの分布:
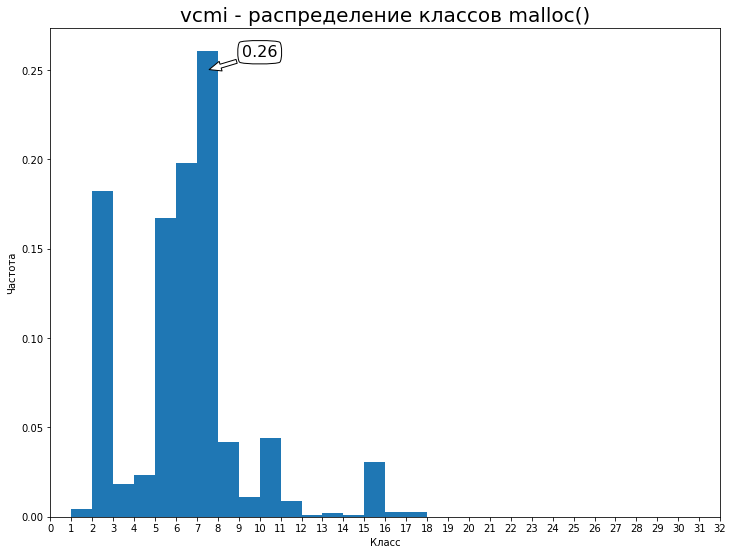
T.O. ベースラインは0.26の精度です。 それを改善してみましょう。 モデルのトレーニングには、パスカルタイタンの時代ごとに10.5時間かかりました(2時代、21時間、 validation_split
= 15%)。 一般に、2番目の時代は結果を大きく変えることはなく、1つだけで十分です。 次の指標が判明しました。
loss: 0.0512 val_loss: 0.1160 acc: 0.9837 val_acc: 0.9711 top_k_categorical_accuracy: 1.0000 val_top_k_categorical_accuracy: 0.9978
私の意見では、非常にクールでした。 検証で97%の精度を達成しました。これは、50%を超える精度で約20の正しい予測を意味します。 LSTMをGRUに置き換えると、時代の時間を8時間に短縮でき、わずかに優れたメトリックが達成されます。
私はモデルの開発ベクトルを見る:
- 「額」にあるニューロンの数を増やすと、メトリックが改善される可能性があります。
- アーキテクチャ、メタパラメータの実験。 少なくとも、コンテキストの長さとレイヤー数への依存を調査する必要があります。
- 呼び出しスタックを展開してdebuginfoを適用することにより、予測コンテキストを充実させます。 一連の関数から完全なソースコードまで。
訓練されたモデルのサイズは1メガバイトで、これは完全な履歴(gzipで98 MB)よりもはるかに小さいです。 ネットワークを適切に調整すれば、品質を犠牲にすることなくネットワークを削減できると確信しています。
未来
「待ってください」と読者は言います。「mallocを呼び出すたびに、正しい考えを持つ人は誰もネットワークを前進させません。」 もちろん、すべてのサイクルがカウントされるとき、行列128に100を64で掛けることはばかげているように見えます。 しかし、私は異議を唱えています:
- 20コールごと、またはそれ以下でネットワークを開始する必要があります。 テクノロジーが改善されると、この数は増加します。
- マルチコアプロセッサは長い間一般的になり、100%をはるかに超えて使用されています。 プログラムのダウンタイムの間、ある種の
read()
ブロックには、具体的なタイムスライスと推論のためのリソースがあります。 - ニューロアクセラレータはすぐ近くにあります。 TPUはすでにGoogle 、 IBM 、 Samsungによって製造されています 。 それらを使用して、ダイナミクスでの動作を分析し、それらにランタイムを動的に適合させることにより、既存の「単純な」プログラムを高速化してみませんか
TL; DR
Heroes IIIの動的割り当てとメモリ解放を予測するRNNモデルは、97%の精度でトレーニングすることができました。これは非常に予想外でクールです。 新世代のメモリアロケータを作成するためのアイデアを実践する可能性があります。
 ソースコードの機械学習は、新しい刺激的なトピックです。 6月3日に開催されるカンファレンスソース{d}のテクニカルトークをご覧ください。 全記事の半分を執筆したChals Suttonと、 マイニングソフトウェアリポジトリのスターでGHTorrentの創設者であるGeorgios Giusiusが講演します。 参加は無料で、場所の数は限られています。
ソースコードの機械学習は、新しい刺激的なトピックです。 6月3日に開催されるカンファレンスソース{d}のテクニカルトークをご覧ください。 全記事の半分を執筆したChals Suttonと、 マイニングソフトウェアリポジトリのスターでGHTorrentの創設者であるGeorgios Giusiusが講演します。 参加は無料で、場所の数は限られています。