
パベル・フィロノフ( カスペルスキー )
今日は時系列の保存についてお話します。 主観をできるだけ捨てて、より客観的なものに置き換え、最後のどこかに主観的な見た目を残すために使用したアプローチを説明します。

ほとんどの場合、最近の私の実践では、標準的な問題を解決するために新しいものを発明する必要はほとんどないことに気付きます。 ほとんどの場合、選択する必要があります-店でヨーグルトを選択する方法。 あなたが来て、棚があり、これらの列はすべて構成されています。あなたはどちらを選択するかを決める必要があります:習慣、新しいもの、最もおいしい、または最も便利なものを試してください。 そして、それらはすべて広告付きで明るく、美しいです。 互いにすべてが優れています。
偉大な人たちは長い間、これは大きな問題だと言ってきました。 これらの明るいカーテンが私たちの選択をわずかに覆い隠してしまう可能性があるという事実。
どうやってやってみるの? とにかく、正直に、客観的に、それは完全にうまくいきません。 選択には常に主観がありますが、そうでない場合はありません。 しかし、この主観性をどういうわけかレベル化することは可能でしょうか? ある種の制御されたフレームワークをクランプして、その結果が出たのかもしれません。
今日は、主観をできるだけ捨てて、より客観的なものに置き換えて、最後のどこかに主観的な見た目を残すために使用したアプローチを説明します。
ただし、この前に、まず立っていたタスクについて少しお話ししたいと思います。 私の意見では、何らかの意味で感じることができる本当の問題の理解-それは常に状況を明確にします。 これにより、これらの決定や行われたその他の決定をよりよく理解できます。 したがって、私はジョン・マクレーンから始めます。

これがジョン-私のヒーローです。 彼がテロリストを打ち負かしたのを見た子供の頃、誰がジョン・マクレーンのようになりたかったのですか? すべてではない、はい、わかります。 だから本当にしたかった!
私は彼が第1部、第2部、第3部でテロリストを打つのを見ました。 そして、最近では、私は彼のように見えました。 似ているのはわかりにくいとわかります。 おそらく外部ではなく、少し-私たちは彼で何を始めますか。 特に、彼の冒険の第4部では、彼はテロリストと戦っているだけでなく、ガソリンスタンドに侵入しようとしている、電力線を破壊しようとしている、再建しようとしている誰かを捕まえて恐怖にさらすだけでなく、非常に有害なサイバーテロリストと戦っていました大都市の交通信号。 モスクワで交通信号を無秩序に再構築するとどうなるか想像できますか? おそらく何も変わらないでしょうが、これはすぐに行われるべきではないという疑いがあります。
この映画は2007年に公開された、道化師的でユーモラスでした。 どんな種類のサイバーテロリストがいますか、どんな種類の発電所制御、どんな種類の破壊?
問題は、映画のリリース後、2010年頃に発生し、多くの人が映画を視聴したようです。 一部の人もそれに夢中になりました。 残念ながら、染み込んでいる人のすべてが良い人であるというわけではありません。 特に、真ん中に聞こえる名前はかなり人気のあるマルウェアの1つで、約6年前に発見され、多くのスキル、多くの目的を持っていました。

彼の最も不愉快な任務の1つは、自動プロセス制御システム(APCS)をハッキングし、情報を盗んだり、何かを消去したりするだけでなく、商業的損害を引き起こすだけでなく、物理的損害を引き起こす技術プロセスを再プログラミングすることでした。 特に、彼の行動により、ウラン濃縮プログラムは、私の意見では、イランでは数年前に捨てられました。 彼は単に濃縮プラントのいくつかを無効にしました。 残念ながら、状況は繰り返されました。 いくつかのケースが公式に報告されています。 これらのプラントが単独で失敗したのではなく、いくつかの攻撃のテスト、制御システムに対する標的型攻撃の直接的な失敗を確認するレポートが作成されました。
このタスクは、ソリューションの検索につながり始めました。 これは問題であり、多くの人はこれが問題だと考えています。 プロセス制御システムでは、すべてがセキュリティに優れているわけではありません。 そこで新しいセキュリティ要素を導入し、これらのオブジェクトを保護する必要があります。 どのようなオブジェクトですか? ここで、いくつかの画像が私の目の前にあるように、私はちょうどいくつかの写真を撮りました:

ある種の工場、最も可能性が高い製油所は、非常に重要で有用なことを行います。 そして、サイバーの側面から見ることができる脅威から彼を保護することを試みる必要があります。 これは難しい作業であり、非常に多層化されています。
この工場はさまざまな角度から見ることができます。 たとえば、ネットワーク動作の観点から見ることができます。ネットワークトポロジを描き、誰が誰とやり取りするか、誰が誰とやり取りするか、誰ができないかを確認します。 これは1層ソリューションです。
以下に進み、端末がどのように動作するか、端末で実行されるプログラムを監視できます。これらは許可プログラムまたは禁止プログラムです。 このレイヤーをたどることができます。
私はまだ別の層にある部門で働いており、プロセス自体の動作、リレーのオン、コンベアの動作、タンクの加熱、パイプラインを介した流体の追跡を監視しています。 そして、例えば、このオブジェクトを次のように見ます。

実際、技術的なプロセスは、時間とともに変化する動的なシステムです。 多次元であり、多くの特徴があります。 ここでは5行を描画しましたが、平均的なオブジェクトの場合は数千、場合によっては数万になります。 これは、データが目でどのように見えるかを想像するための人工的な例にすぎません。
もちろん、主なタスクはスレッドでの処理です。 ハッキングに関する履歴データは興味深いが、それほど多くはないからです。 しかし、それを実装するには、このデータを処理する必要があるだけでなく、どこかに保存することも望ましいです。 歴史的調査のため、法医学のため。 たとえば、オンライン処理システムをトレーニングするために、大量の履歴データを保存することが非常に重要です。
ここから、具体的な技術的問題が生じ始めます。 そのようなデータがあり(モデルについて少し説明します)、これらのデータがシステムに入る特性がある場合、どのようにして利用可能なストレージサブシステムを最も合理的かつ合理的に整理できますか?履歴分析を行うため、または特定の研究を要求するために? だから私たちは問題に来ます。
ただし、問題はデータスキームに関するものであるため、何が危機にconcreteしているのかについて少し具体的なアイデアを得ることができます。 すでにそのようなわずかに特定の言語で。

ここで、1行の1つのポイントは通常、3つの数値で特徴付けられます。これは、その識別子(チャネル番号)、42-温度、14-圧力、13-リレーのオン/オフ(可能)です。 この動的システムで何かが変更された瞬間、および変更された値。 値は実数値でも整数でも論理値でもかまいません。 実数値はそれらすべてを説明します。
特徴について少し説明します。おそらく、これは会議の主題に関係していると思われます。 ボリュームではそれほど単純ではありません。
残念ながら、平均的なオブジェクトの場合、そのような行の数は合計で数万になりますが、例外的な場合には1桁大きくなる可能性があります。 強烈に、神に感謝します。 通常、センサー値は平均して1秒に1回収集されます。 多分もう少し頻繁に、多分少し遅くなりますが、実際のオブジェクトの特性はほぼ同じです。
そして、私たちが働かなければならない量を想像するために、少し試してみています。 これは非常に重要なポイントです。実際、これらの数値から、たとえば機能的要件なしで非常に不快に感じる何かを推測し始めることができるからです。
ときどき彼らは言う:「それを速くて良いものにする」、しかし私はそのような言葉を理解していません。 私は人を拷問し始めます:「そして、「速い」とは何ですか? そして、「良い」とは何ですか? あなたのデータは何ですか? ボリュームはいくつありますか? そして、あなたの強度は何ですか?」 このチェックリストが完成し、主要なポイントがわかった後にのみ、少なくとも解決策を想像することができます。

確かに、そこにはそれほど単純ではありません。多くの解決策がありますが、そこにはまったくありません。 これで、5人のお気に入りのDBMSをこのリストに安全に追加できるようになりました。 もちろん、ここの誰もが単に適合しません。 彼らは違います。 あるケースではうまく機能するものもあれば、別のケースでうまく機能するものもあれば、おそらく私が説明したタスクでうまく機能するものもあります。
しかし、どれですか? 理解する方法は? 選択方法 これは大きな問題です。 私は頻繁にそして絶えず彼女に出会います。 新しいものを考え出すことはすでに非常にまれであり、ほとんどの場合、このセットから何らかの形でインテリジェントに選択する必要があります。
この選択にはいくつかのアプローチがあります。 最初の-私はそれを「非エンジニアリング」アプローチと呼びました。

残念ながら、たぶん私は知らないかもしれませんが、幸いなことに、時々宣伝されます。 非エンジニアリングアプローチの例は何ですか?
- たとえば、このように-それらはすべてXに格納されているので、ここでも使用します。 タスクが異なっていても、サブジェクトエリアが異なっていても構いません-Xの仕組みを知っています。
- または、「ここで使用しましたが、これを行わないでください。いずれにしても、お願いします。」 私はそのように会った。
- 3番目は私のお気に入りです。 はい、多くの人が私と連帯しています。 しかし、危険な、少し危険ですが、愛されています。
- 私たちはあなたとの会議に参加しています。彼らはここでデータベースについて話します。 おそらくここよりもデータベースについて話し合う会議を覚えていないでしょう。 そしてもちろん、最初のことは、人々が翌日以降に仕事に来るということです。「彼らは私たちにそのようなことを教えてくれました、試してみましょう!」
- 私もこれをとても気に入っています-記事はどこかで出てきました、すべてが素晴らしいです:グラフは指数関数的に上昇し、ドルは一番上に描かれ、誰もが幸せです。 これを選択しましょう。
もちろん、スライドはユーモラスですが、正直に言ってみましょう-誰が今勇敢に立ち上がって自己紹介し、「本当に、私はそうです、そして私は未設計のアプローチを使用しました」と言いますか?
アシスタントに聞いてもいいですか? マイクしてください。
自己紹介して言ってください。 あえて!
聴衆からのコメント:私はウラジミール・ミャスニコフです。 「Xを使ってみましょう。すでにそれを理解します。」というアプローチを使用しました。
ウラジミール、どうもありがとう! 拍手しましょう!
ところで、高負荷システムHighLoad ++の開発者の会議の過去5年間の公開ビデオを公開しました。 YouTubeチャンネルを視聴、学習、共有、購読します 。
これは、治療のそのような部分です。 はい知っていますか? 問題に対処するには、まず問題を認識し、自分自身を認めなければなりません。 ウラジミールは明らかに勇敢な人であり、ここの多くは勇敢であり、彼らはこれが悪いアプローチであることを認める準備ができています。 他にもあるのでしょうか?

それをエンジニアリングと呼びましょう。 彼はおそらくもう少し複雑です。 何らかの形で構造化され、分解されることさえあります。 私は私の分解を試みました、それは一般的であると主張しません。 ポイントごとに説明しますが、実際には、同時にレポートのさらなる部分の内容にもなります。
- 最初はすべて同じように読んでうれしいです。 近年登場したものは何ですか? なぜなら、「今週学ばなければならない10の新しいデータベース」という記事がフィドリーに届いたとき、私は恐れて待っているからです。 遅かれ早かれこれが起こると思う。 そこにすべてが現れるので、それを追跡することは困難であり、常に文学に精通する必要があります。 カンファレンスで聞いたことを通して、誰が何を試したのか、誰が何かに満足しているのか、誰が何かに不満を抱いているのかなど。 そして、私たちは経験を他の人々に広めました。
- 一般的に言えば、価格、速度、拡張性などの基準を選択した場合、それを理解するのは良いことでしょうか? あなたはそれらを決める必要があります。 すべての基準で選択することは不可能です。 ほとんどの場合、非機能要件により、このタスクのどの基準を使用できるかがわかります。このタスクでのみ、最初に検討し、2番目の基準を検討する必要があります。
- これは最も興味深い、待望のポイントです。比較する相手を選択する必要があります。 出場者が必要です。 残念ながら、全員を比較することは困難です。 予備的な選択が必要です。 特定の数字に到達する前であっても、これは解決策のように思えますが、不可能です。 または、すべてを測定するのに十分な力がないことを理解しただけで、今までで最も適切と思われるものを選択する必要があります。 しかし、もちろん、このリストは1つのアイテムで構成されることはほとんどなく、2つのアイテムでさえありません。
- おそらく4番目のポイントについてお話します。 測定対象を選択し、さらには誰を測定するかを選択する場合、非常に繊細で非常に興味深い質問です。「これをどのように行うのですか?」 なぜなら、あなたが2人を連れて、同じことと同じことを測定することを選んだとしても、彼らはそれを完全に異なって行うことができ、数は非常に異なる可能性があるからです。 したがって、どこかで、不必要なニュアンスに進むかもしれませんが、私の意見では、これは最も興味深い部分です。それを測定する方法、何らかの方法でそれを再現する方法です。 ここでは、これに多くの時間を費やします。
- 実装する必要があるため、これはかなり難しい部分です。 彼女自身はとても長いので、いくらかの労力、仕事が必要です。 これについて詳しく説明します。 一般に、このテストを実施するには、各参加者がどの番号がそれに対応するかを理解します。 あなたは手でこれを行う必要があり、コードを書くことさえできます。 私の良さ
- ところで、結果が十分でない場合があります。 「自分のもの」という数字の美しいプレートを持ってきて、「結果がここにあります」と言ったら。 彼らは言うでしょう:「まあ、いい。 だから何?」分析が必要です。 数では十分ではありません。 数字の後には常に、それらを説明する通常の単語が続き、それらを明らかにし、それでもこの結果の意味を伝えようとします。
- そして、最終的には、特定の推奨事項が必要になります。 さらに、「これだけが機能し、それだけです」という非常に厳密なことはほとんどできません。 実際、もちろん、いくつかの解決策があります。 おそらく、この決定またはその決定がどの程度の確実性をもっているのかを言わなければならない。 たとえば、レポートおよび特定の推奨事項の形式で。
- 洗練されたアプローチ。 私がそれを書き留めたとき、3つ以上のポイント-これは一般に難しいですが、ここでは最大8つになりました。 このアプローチ、私はそれを見ますが、非常にまれであり、私はその理由を理解しています。 労働集約的です。 確かに、時間と工数を費やす必要がありますが、努力する必要がありますが、「Xを使用してみましょう。ただし、後で確認します」と思われます。
しかし、ここで、時間を費やすなら、何かのためにそれをします。 どこかに保存したい。 たとえば、テストで「バグ」の解析にかかる時間を大幅に節約できることに気付きました。 おそらくここで時間を節約できますか? 可能です。
データベースをリリースから実稼働環境のリリースに変更しなければならない状況に直面したのは誰ですか? はい、出会った人はほとんどいません。 そして、誰がそれを好きでしたか? 手がまったくありません。 これは非常に危険です。
選択が不合理で盲目にされた場合、必要な非機能要件に陥らないリスクがあります。 特に、変化し始めた場合。 彼らは一度に誰を変えましたか? はい、これも可能です。 したがって、これらの人件費はもちろん将来的に回収することができます。 つまり、彼らがどれだけあなたに返済するかを予測することは困難ですが、私を信じて、時にはそれだけの価値があります。
これが私たちの計画です。 それを見てみましょう。 文献の批評から始めましょう。

主に、読み始めたときに気に入らなかった点についてお話しします。 特定のポイント。 たとえば、特定のタスクについて多くのデータベース比較が実行されます-あなたは誰だと思いますか? -これらのデータベースの開発者自身。
100パーセントの相関に気付きました。実際には100パーセントです。 私が発明したBingo-Bongoベースの開発者が比較を行うと、そこで彼が勝ちます-誰が正しい答えを知っていますか? -Bingo-BongoDBがそこに勝ちます。 はい、常に。 すごい どんな比較でも関係ありません。 私はこの結果に混乱しています。 私はすぐにそのように彼を信頼する準備ができていません。 一般的に、私は人生で非常にだまされやすい人ですが、エンジニアの帽子をかぶると、すぐに多くの点で非常に疑い始めます。 たとえば、このようなレビューで。
私を笑わせたもう一つの興味深い点が、私はしばしば彼を見ました。 異なるDBMSを互いに正しく比較するために何をする必要がありますか? もちろん、異なるデータを取得します。 面白いのは、ある記事が別の記事を参照しているとき、次のように言うことです。 そこにはデータしかありませんでした-異なるデータがあります。 彼らには1つのサーバーがあります-他のサーバーがあります。」 一般的に、あなたは何を比較していますか? また、あまり良くありません。
また、より良いソースもあります。スライドの最後には、私が好きなものへのリンクがあります。
そして、ほとんどの著者は、あなたが本当に賢明に選択したいなら、あなたの問題を解決し、彼らが持っているデータと彼らが持っている負荷プロファイルを見てはいけないと言います。 負荷プロファイルを取り、データを取り、それらについてのみ測定します。 100%の確実性ではなく、これらの数値のみが、これが今後どのように機能するかを長い間考えてくれます。 なぜ100%ではないのですか? おそらく、システムが2年間機能する場合、最初に2年間テストすることはまずありません。 テスト時間はさらに制限されます。 したがって、まだ危険がありますが、もちろん大幅に削減されます。
基準について話しましょう。 何を比較しますか?

私の仕事にとって最も重要なものを選択しました。 比較できる基準のすべてがここにあるわけではありません。 どちらを落としたかは言いません。 では、これを追加の質問に任せましょう。「この基準で比較してみませんか?」 私が比較していることについてお話します。
- たとえば、書き込み帯域幅。 これは私にとって重要です。 私はそれを保持し、ディスクに落ち、登録した負荷に耐える時間が必要です。 しかし、質問は非常に難しく、信じられないほど難しいことが判明しました。 「帯域幅が非常に大きい」という記事をどこかで見たとき、私は疑い始めます-どのような条件でテストされましたか? 私の経験では、常に中毒があるからです。 たとえば、「バッチ」のサイズ(一度に何個のデータパケットを書き込むか)によって変化します。 データベースに書き込むクライアントの数によって異なります。 長時間データベースに書き込む場合でも少し異なります。たとえば、5分間を書くと1つの数字があり、12時間とすると、通常「ピークパフォーマンス」と呼ばれるものと必ずしも同じではない他の数字が表示されることがあります。そして、この基準自体はもはやささいなことではないようです。すでにさまざまな角度から見ることができます。これらは、このレポートでこの帯域幅を検討する3つの側面(上のスライド)です。
- , . , , . - . , . — , . , , . ? , : , , , . , . , . , , ? , « ».
- — . , , . , . , , , . , . , , — , — , - . , . - , , . .
ここに私たちの基準があります、ここで最初にそれらについて話しましょう。 帯域幅から始めますが、HighLoadが残っています。 これは最も興味深い特性の1つですが、実は些細なことではありません。
その前に、私たちの「出場者」。 これら4つを比較します。

ここで、私はすぐに、おそらくあなたの多くがポップアップする興味深い点を説明したいと思います。 なぜ特殊なソリューション(OpenTSDBとInfluxDBであり、「私たちは時系列に過ぎず、これが私たちの財産であり、他には何も保存できない」)を汎用DBMSと比較するのはなぜですか? 結局のところ、多くの点で専門化の方が優れているという答えが明らかになると思われます。
実際のところ、ここでの答えは、すぐに教えます。一方で、はい、特殊なソリューションは良いのですが、すべてのソリューションが非機能要件に適合する場合はどうでしょうか。 異なるシステムの動物園を作るべきですか? 結局のところ、ほとんどの場合、時系列を保存するだけでなく、おそらく、モデルに応じて他のメタデータとより豊富なデータを持っているでしょう。 ほとんどの場合、それらはどこかに追加する必要があります。 特殊なソリューションの動物園を作成せず、1つのソリューションが一方と他方の両方に対応していることを示したらどうでしょうか。 したがって、原則として既に使用されているソリューションを採用することは私にとって興味深いことでした。 彼らがこの状況にどれだけうまく対処しているかを見るために。 極端な場合、動物園を作らないため。
プロジェクトに複数のデータベースがあるのは誰ですか? 誰が2つ持っていましたか? 誰が3つ持っていますか? 誰が4つ持っていますか? 誰が5人いますか? 数人が残っています...これもあまり良くありません。 はい、同僚は私に同意します。 ありがとう 適切な要件に適合しますが、管理にはあまり便利ではありません。
これらは私たちが話し合う4つです。
少しtsiferok、数字なしで。 比較対象。 ここでも、このスライドは非常に重要です。なぜなら、私はそのような免責事項を挿入し、あなたがそれを理解したいからです。

ここでは、DBMSではなく測定します。 それらをまとめて測定します。つまり、クライアントのように自動的に測定します。 私はDBMSの仕組みにあまり興味を持っていないため、販売していません。 私の仕事、インフラ、クライアント、現実に近いもので、彼らがどのように正確に機能するのだろうか。
したがって、これが非常に重要なポイントであることに留意してください。これから説明する数値は純粋なDBMSではなく、ここで説明するすべてのものを引き付けます。 Dockerがあるという事実(今ではそれがなくても非常に便利で、気に入っています)。 特定のクライアントには非常に興味深い機能が1つあります。ストレージ用に最適化されたドライバーがまだないため、場所によってはドライバーに問題がある可能性があります。 そして、これらは私たちの世界の現実です。すべてのプログラミング言語で、必要なすべてのDBMSに理想的なドライバーがあるわけではありません。 時々これらのドライバーで-ああ私の良さ! -バグがあります。パフォーマンスのバグである場合があり、これに対処してこれを理解する必要があります。
そして今、最も興味深い。

グラフは消えました。 帯域幅については非常に複雑です。 長い間、私はそれが何であるか、どのような量であるかを理解しようとしていましたか? それは数字ですか? これは中毒ですか? これは、神が禁じている、不可欠なものですか? 神に感謝、それは判明した、それはないようです。
最初は、何を測定し、どのように測定するかを理解しようとしました。 青いグラフとは何か、どのように構築されるかを明確にしよう。 これはメソッドのテストに関するものです。
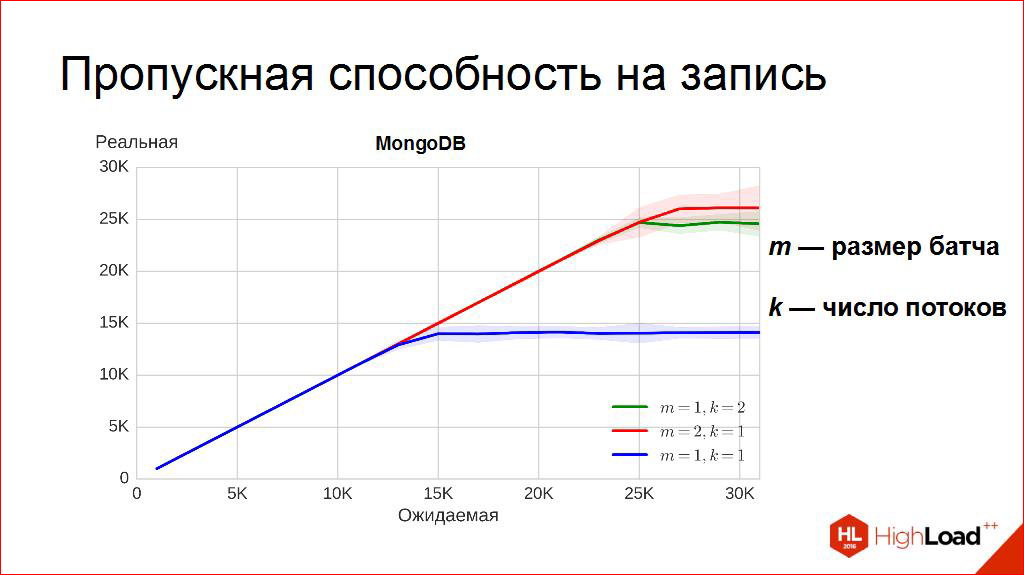
「ボリュームノブ」は非常にシンプルで、どれだけ録音しようとしますか。 実際には2つの「ペン」があります。システムにあるセンサーの数と、値を記録する頻度です。 たとえば、センサーの数を「ツイスト」して、各センサーがその値を1秒に1回記録することを記録できます。 そして、横軸に沿って「ツイストツイスト」を開始します。予想されるスループット、つまり2万個は2万個のセンサーで、それぞれが1秒に1回値を記録します。
縦軸は何ですか。実際、青いグラフはどこにあり、プロットされていますか? これは、「電圧計」をきちんと取り、測定を開始します。DBMSに実際にどれだけ記録したのでしょうか。 そして、それもさまざまな方法で、そして巧妙に行われます。 たとえば、ここでは、各ポイント(もちろん、近似値で)は次の方法で取得されます:このような負荷で5分間開始し、毎秒この秒を記録した量を記録し、これらのポイントの分布のヒストグラムを作成して中央値を選択します。 非常にクールな値、私はそれが好きです、それは私たちが測定したこれらのポイントのちょうど半分がその左にあるような帯域幅です。 つまり、少なくとも半分の時間が、このような速度で書かれていることを保証します。
平均値を選択できる場合もありますが、ここでは小さい数字が表示されます。 なんで? 平均、ただ平均、それは外れ値に敏感です。 しばらくの間、誤ってハードドライブがビジー状態になった場合、または他の誰かがシステムに接続して、数秒間そこに何かを行った場合はどうなりますか? その後、数秒間、かなりひどいディップができます。 中-これらの障害に非常に敏感です。 私はここでそれを描き始めませんでしたが、平均は常に少なく、この場合、私の意見では、物事のほぼ実際の状態を示していません。 中央値が良くなっています。 意味がわかります。 少なくとも半分の時間で「それほど遅くない」と書きます。
おそらくおもしろいことに気付くでしょう。 この平らな線がレベルです。 つまり、「ボリュームノブ」を回しますが、「音量」は得られません。 たぶんそう思われます。 ここにあります-帯域幅。 このDBMSにこれ以上書き込むことは不可能です。最初はそうでしたが、少し方法を変えたらどうやって書くのでしょうか。 一度に1ポイントではなく、一度に2ポイントの書き込みを開始するとどうなりますか? それでは何が起こるでしょうか? そして、別のグラフ、赤を取得します。

各挿入時に、一括挿入を行います。 1点ではなく2点を挿入し、同じ「ペン」を「ねじり」ます。 このしきい値が上昇していることがわかります。 では、帯域幅とは何ですか? 少し青か赤? そして、一般的に、なぜそうですか?
ここで愚かな例が私の頭に浮かぶ、あなたは私を許しますが、それはどういうわけか私に近いです。 DBMSに関連するものはほとんどありません。 夕方、会社が休息を取り、楽しみを持ち、誰かに牛乳瓶を送ることにしたとしましょう。 ここでは牛乳が最も適しているように思えます。 人は何をしますか? 彼は服を着、靴を履き、鍵を取り、外に出て、エレベーターを下り、店に行き、棚を探し、牛乳を取り、レジカウンターに行き、「急いで!」 「ミルクが消えるまで1ボトル」のスループットのシステムを作成しました。
ここで、「2瓶の牛乳を飲むように頼めばどうなるでしょうか」と考えます。 この時間差はどうなりますか? チェックアウト時に「ピーク!」ではなく、「ピーク-ピーク!」であり、残りの時間はすべて同じであるという事実。 そして、ほぼ2倍の帯域幅を持つシステムが得られます。
DBMSの世界に戻ると、このシーンはどのように見えるでしょうか? これはおそらく、リクエストの準備、ソケットのオープン、ネットワーク接続の確立、リクエストの送信、サーバー側のリクエストの解析、準備、実行、おそらくハードディスクからの解除、応答の準備、応答のシリアル化、パッキング、ソケットへの送信、クライアント側の展開ですそして読書。 おそらく、ここで、1つではなく2つのポイントを書き留めてほしい場合、ここに共通の部分があります。これにより、少し節約できるようになります。
別の興味深いアプローチがあります。 「ツイスト」できる別の軸-しかし、牛乳1本を2人送ったらどうなるでしょうか。 2つのスレッドで記述するとどうなりますか? 興味深い効果もあります。 一度に一点よりも実際に高速に処理します。 Zelenenkayaは2つのストリームですが、一度に1つのポイントです。 ちなみに、それらが重複しなかったことは興味深いです。 緑のものは少し小さいです。 確かに、変動の範囲内ですが、それでも特徴的な中央値は赤い中央値よりも小さくなっています。
つまり、2つの軸があり、さらに2つの「ハンドル」をねじることができます。 一度に書き込む量を「ねじる」ことができ、このシステムで書き込むクライアントの数を「ねじる」ことができます。
それらをひねりましょう、それは面白いです。 これらの「ペン」、「ツイスト」、何が起こるかを見ることができます。 たとえば、バッチを「ねじり」ます。 これは私のお気に入りの「ペン」の1つで、実装が非常に簡単なので、「ねじる」のが大好きです。
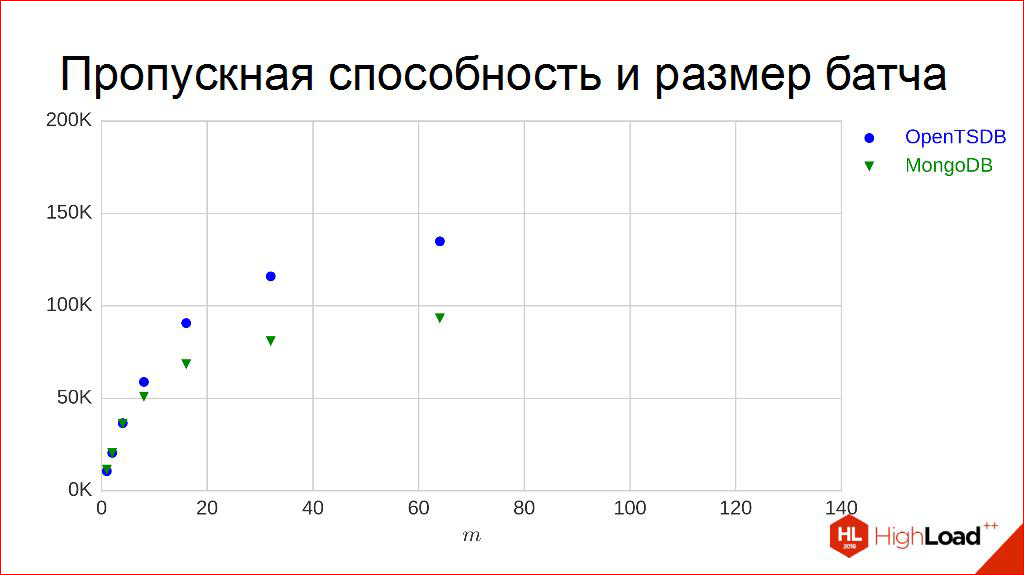
他のチャートに行きましょう。 さまざまなバッチを使用してemkiを実行し、ポイントを作成しましょう。 度2の場合、それらが取られることがわかります。 ポイントはまったく同じ方法で構成されます。実験は5分間続き、中央値は受信した1秒あたりのすべての帯域幅から計算されます。 2人の出場者用。 興味深いパターンが見られます。はい、それは成長しますが、ところで、どういうわけか、少し曲がり始めます。つまり、明らかに無限に成長せず、おそらく非常に線形ではありません。 別の興味深い点は、いくつかの点で非常に類似しており、ほぼ同じ動作をする場合、他の点ではわずかに異なり始め、異なる動作をすることです。
帯域幅は本当にこの曲線ですか? ある種の中毒? おそらく。 しかし、曲線と依存関係を扱うのは非常に不便です。 彼らはテーブルに入るのに不便です。 数字を使用すると便利です。 それらをそれぞれ数字に変換し、測定に便利な数字に変換するために、多かれ少なかれ何を考えますか。 このチャートの全員が配置するのが不便であるため、交差し始める可能性があります。 あいまいさ。 これがどのように行われるかについて考えてみましょう。
最初に、これを見たとき、私の手はペンを取り、次のようにそれをするように頼みます-ある種の曲線を描きます:

ある種の法律、おそらく依存関係。 その後、真実の瞬間が生じます。 非常に緊張し、どんな種類の曲線を描くことができるかを推測する必要があります。 次のようなものを拾う必要があります。 多くの選択方法があります。 私が最も簡単で最も愛され、使用されているものの1つは、軸で少し遊ぶことです。 水平軸に沿ってバッチを延期するのではなく(今は少し緊張する必要があります)、バッチからの対数を延期し始めたらどうでしょうか? 対数軸。 まれに、誰かがそれが使用される理由を知っているかもしれませんが、この図は少し単純に見えるため、このような状況では非常に便利です:

直線で作業する方が便利です。 ちなみに、その前のグラフは本当に対数であったことがわかります。 直接的なものは明らかです。 おそらく、これらの角度もカウントできます。 ここで、スライドのタイトルは、これがどのように行われるかを示しています。 これらの角度、またはむしろこれらのキャッチの接線を与える非常に複雑な線形回帰法はありません。
さらに微妙な点があります。 それは非常に議論の余地があり、誰かが後でどこから入手したか教えてくれることを本当に望んでいます。 いつかどこかで説明され、よく考えられたと思います。 しかし、アイデアはこれです。これらのグラフを取得する代わりに、これらの角度、またはむしろこれらの角度の接線を取得しましょう。 角度が大きいほど、見た目が良いほど、数値は良くなります。 角度が小さければ小さいほど、接線は小さくなります。 つまり、ここでこの順序の関係をより厳密に紹介しようとすることができます。
たとえば、競合他社(これらは角度ではなく、ここで記録した角度の接線です)の場合、バッチのサイズに対する帯域幅の測定された依存性はほぼ同じになります。 この場合、2つです。
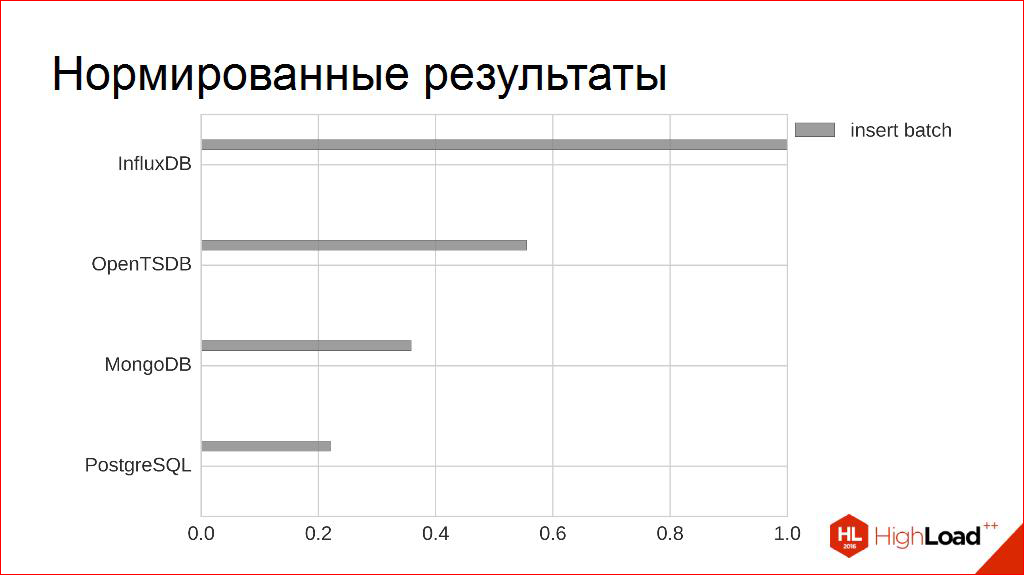
残りを要約します。 そして、もう1つのトリックを行います。
絶対数-2万、10万、20万-それらは小冊子の広告には豪華ですが、私は本当にそれらを必要としません。 ちなみに、最低限必要なのは知っているだけです。 例えば、私は、ピークパフォーマンスの点で各競合他社が私の非機能要件に適合していることを知っています。
後で他の基準と比較するために、単純な手法を使用します。 単純に最大値に正規化し、ゼロから1のような相対値を取得します-誰がより多く、誰がより少ないのです。 比Fig的には、この基準により-誰がより良く、誰がより悪い。
このプレートには、他の基準に従って他の列が表示される余地があることがはっきりとわかります。 それらの構築を終了してみましょう。

たとえば、顧客数の帯域幅。 同じこと。 測定します。 今だけ、水平軸上で、書き込むストリーム数を延期し、これらのポイントを取得します。 彼らは少し震え始めていることがわかります。 ここでは、曲線も描画できると推測できます。 それらはロジスティック関数、つまり飽和状態になります。 彼らは本当にそのようなしきい値に行き、それ以上は行きません。
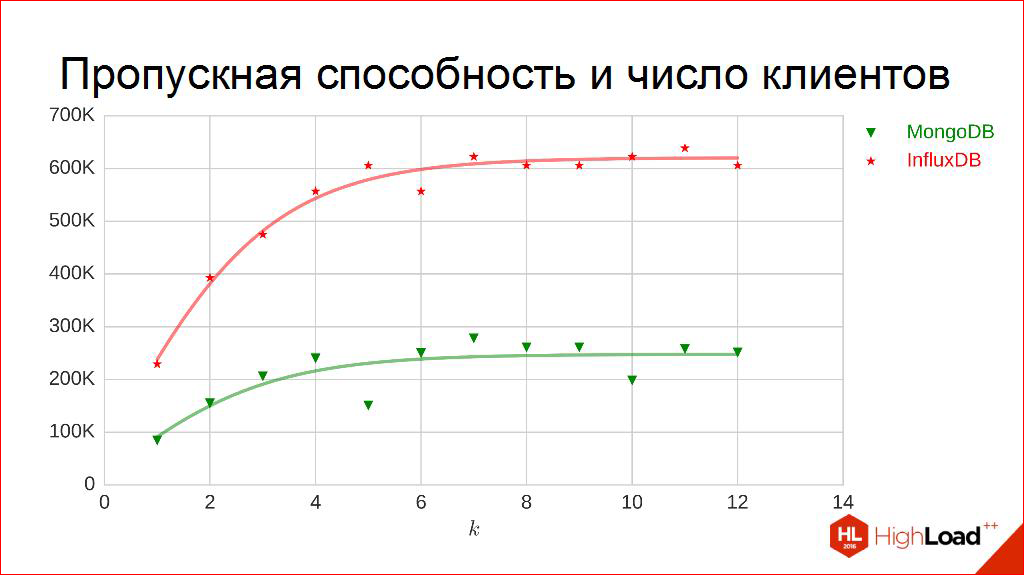
ところで、なぜ、このように見えるのですか? なぜそんなに奇妙なのですか? 実際、私たちの性質は限られており、たとえば、DBMSが消費できるコアの数が環境によって制限されているマシンでは。 そして、このグラフから、コアの数がすぐにわかると思います。
お勧めします。 さて、考え直して、このDBMSに発行されたカーネルの数を一緒に考えてみましょう。 一、二、三? 四? いくつかは、実際には4つと推測しました。
核が終了するとすぐに恐ろしい競争が始まり、この分野で働くことは事実上無意味です。 早めに現場で作業する必要があるため、ここでは別のアプローチを使用します。 これらの曲線を全体として測定するのではなく、この激しい競争がまだ存在しない線形の部分のみを測定したいのです。 このマシンには4つのコアがあり、20コアに移行した場合、そして誰かが非常に幸運だった場合は60コアになります。 おそらく他の曲線があるので、ここでは線形部分のみを測定します。 ここでは、一般に、多少の線形部分にあります。
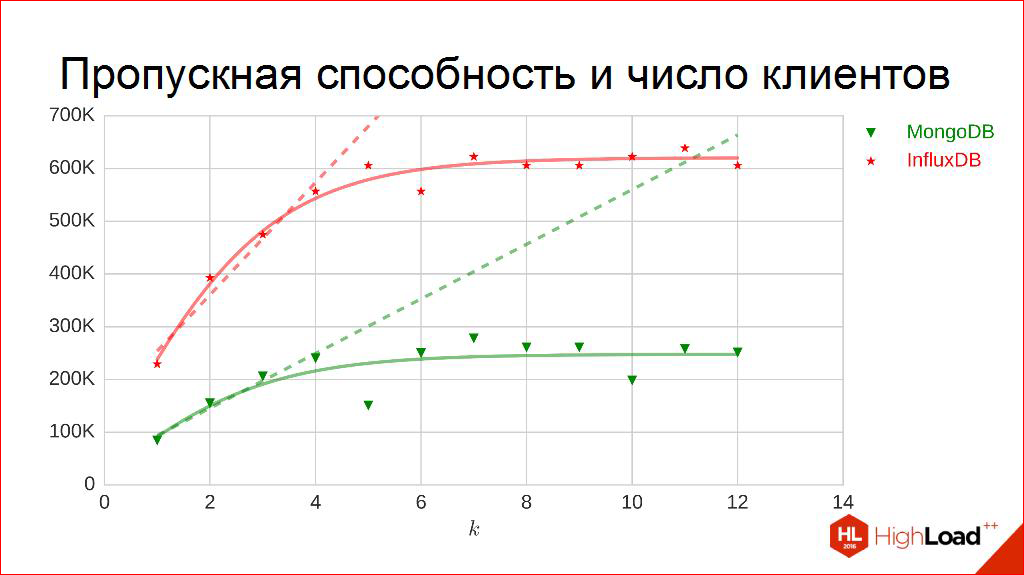
そして、受信は同じです-直接、傾斜角の接線-ここではデジタルです。 このレポートでこれを理解することを提案し、プレートをオレンジ色の長方形で塗りつぶすことを提案するように、比dependence的に、クライアントの数の帯域幅を得ることができます。

この特性から測定値を取得します。 さらに深く進んでください。 たとえば、見るために、そして負荷の下で何が起こりますか? そこでは、一般的に、最も興味深いことが起こります。 これらは、それぞれ10、12時間続くため、最も高価な実験です。 私の意見では、最長の実験は3日間です。 さまざまなDBMSの動作。 いくつかの興味深い一般的なパターンが観察されます。 たとえば、次の例は、60000の負荷がかかっているOpenTSDBです。

原則として、すべてが十分に予測可能であり、すべてが正常です。 時々、DBMSはDBMSの業務のために去り、そこで何かをします。 ログから判断すると、彼女は非常にアクティブにHBaseと通信します。つまり、HBaseは非常にアクティブなことをしてから戻ってきます。 ところで、これは、このために準備する必要があることを意味し、顧客を準備する必要があります。 これは、DBMSが少し「自身に回復する」ことができるため、一般的には良い習慣です。 彼女が永遠に去るなら-私たちはそれを必要としませんが、少し-多分。 しかし、残りの時間は、すべてが正常であり、すべてが安定しており、よくできています!

8万。 同じこと。 安定性は十分だと思われますが、さらに詳しく説明します-ここでの安定性は少し正式に理解されています。 中央値(50パーセントクォンタイルと呼ばれることもある)の場合、これは半分が左にあることを意味し、ここで99パーセントクォンタイルを測定しました。 つまり、全体の99%でDBMSのレコードが希望するレベルにあるという事実に興味があります。 8万人に当てはまります。 もちろん、いくつかの時点で脱落することもありますが、1%を超えることはありません。
そのため、「健康な人のOpenTSDB」は依然として次のようになります。
そして、これが「OpenTSDB喫煙者」です。
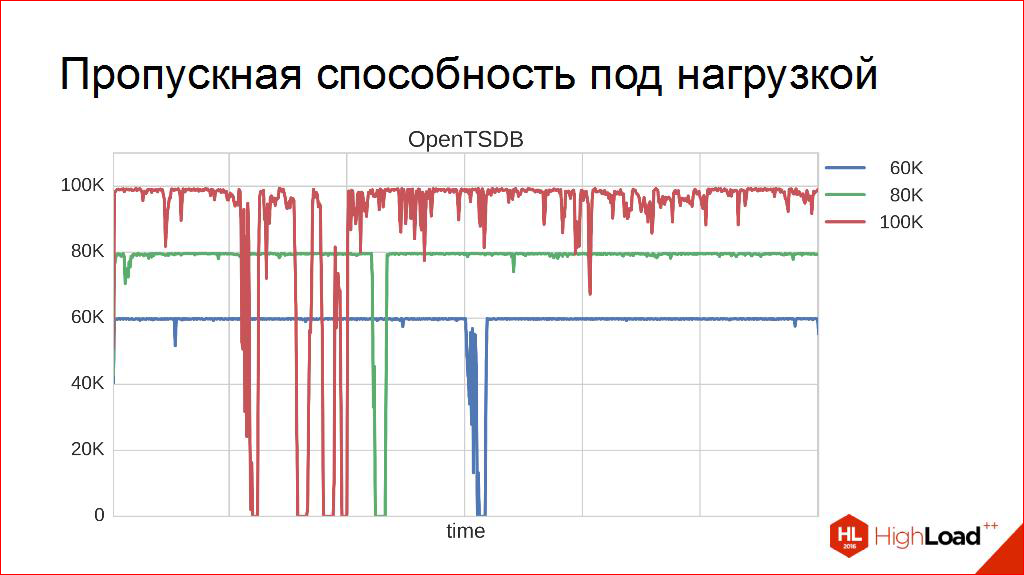
このような負荷でも機能しますが、明らかに99パーセンタイルがあります。これは100ではなく、明らかにずっと少ないでしょう。 より頻繁に「それ自体に入る」-あなたが理解することができる、それはまだそのような負荷に耐えることが必要です。 そして、これは、そのようなスケジュールを見て、私が言うことになることを意味します。したがって、この100未満のものは、このインストールで保持する必要はありません。 80歳未満-ホールド。 長い間百はオンになりません! ピーク負荷時にはさらに耐えることができますが、12時間100を維持することはお勧めしません。
そして、このしきい値が表示されます。 残念ながら、正確に計算できませんでした。 実験は非常に大きな一歩を踏み出しました。 この特性が満たされた最後のステップで停止しました。 そのため、システムは12時間、希望の負荷の下で安定して動作できます。
そして、負荷のかかった作業が多数ありました。 当然、それらはピークのピークよりもはるかに小さくなりますが、この意味では、わずか5分間の動作ではなく、数日間続くことを説明しているため、若干興味深いものです。 そして、ここに青いバーがあります:
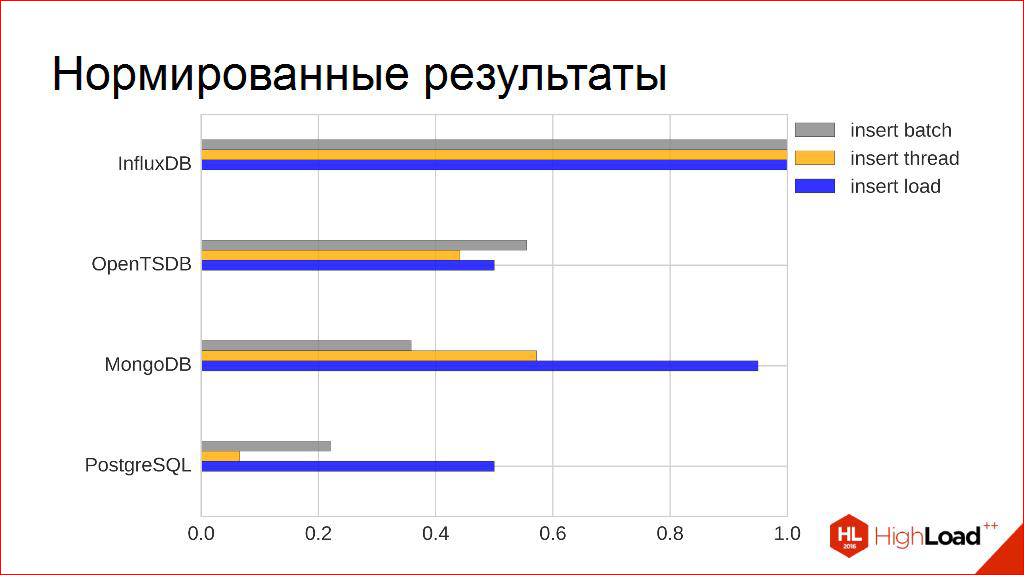
おそらく、「キャプテンシー」の少しは、ここですでにトレースされています。 他の人を見ると、すでに興味深い関係が見られますが、これについては後で説明します。
さらに進みましょう。 クエリ実行時間。
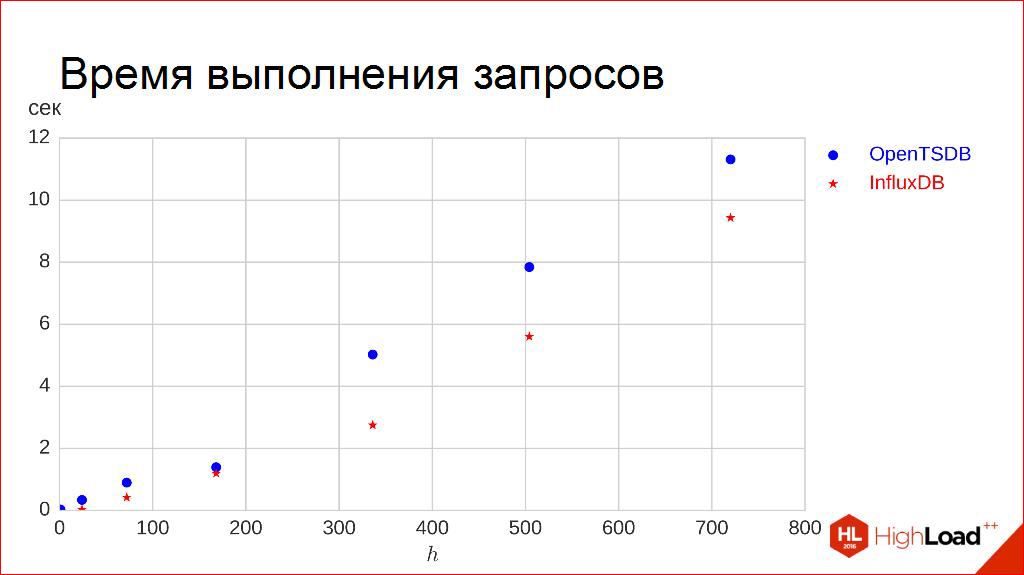
ここで、少し簡単に神に感謝します。 必要に応じて、水平軸に沿って間隔の長さを確保します。 データをリクエストします。1日、3日間、1週間、自分でアップロードします。 100件のリクエストを作成し、ランタイムの95パーセンタイルを測定します。つまり、リクエストの95%がそこに示されている時間よりも短く実行されるようにします。
私にとって、これはより重要なので、これは中央値ではありません。 なんで? これが最も重要だからです-ユーザーがボタンをクリックすると、円が回転します。 , , 5 . 95% , .
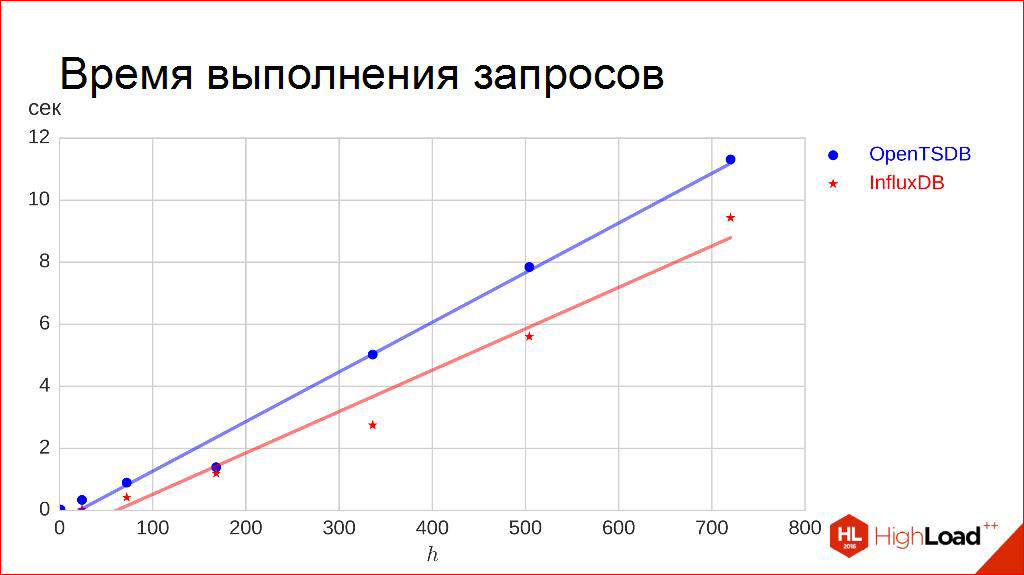
. , , . — . , , . , . , . :
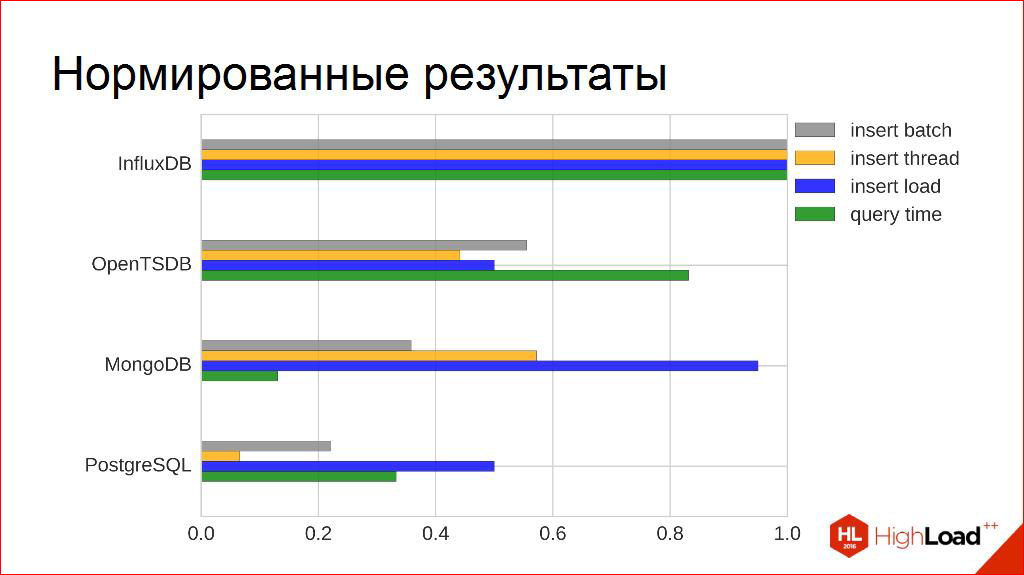
-, , «» . , , , . , . , , . , , .

. , . . , , , , . -, , - . . — . , . , .
- , , , -, , - , . - , . , , . , , .
. , , , , . , - . -, , , : « , ?». , , ? . - , - . ?

- . . , , , . . — , — , . , , : , ; , .
, , , . , .
. . , , , . . . .

.
, ? , - ?

, ( ). , .
, , . «», , , , , . , , — , - , ?
, -, .

, -, , - , .

, . . , . , , . .
, , , . . , , .
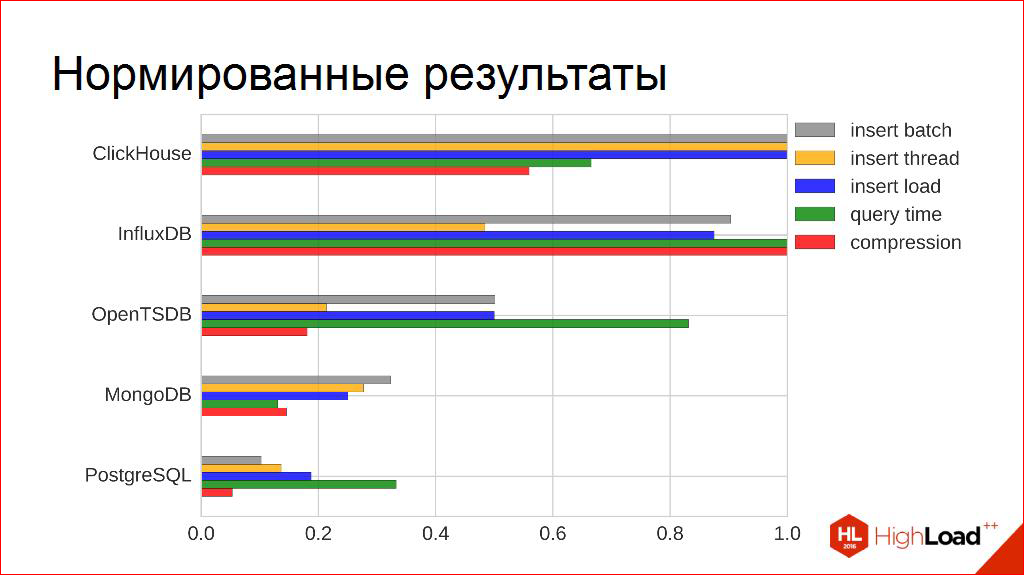
, — .

- , — . . . , -, , - . .

, , , , . , , , .
«», :
- , — ;
- - , , ;
- , , , — . — , .
, .

ご清聴ありがとうございました。
, , .
ソース:
- Y. Bassil . A Comparative Study on the Performance of the Top DBMS Systems – paper
- C. Pungila, O. Aritoni, TF. Fortis . Benchmarking Database Systems for the Requirements of Sensor Readings – paper
- B. Cooper,, A. Silberstein, E.Tam, R. Ramakrishnan, and R. Sears . Benchmarking Cloud Serving Systems with YCSB – paper
- T. Goldschmidt, H. Koziolek, A. Jansen . Scalability and Robustness of Time-Series Databases for Cloud-Native Monitoring of Industrial Processes – paper
- T. Person. InfluxDB Markedly Outperforms Elasticsearch in Time-Series Data & Metrics Benchmark – blogpost
- . -. In-memory NoSQL ? - slides
- B. Schwartz . Time-Series Databases and InfluxDB – blogpost
- K. Eamonn and K. Shruti . On the Need for Time Series Data Mining Benchmarks: A Survey and Empirical Demonstration – paper
- R. Sonnenschein. Why industrial manufactoring data need special considerations – slides
- S.Acreman . Top10 Time Series Databases – blogpost
- J. Guerrero . InfluxDB Tops Cassandra in Time-Series Data & Metrics Benchmark – blogpost
- J.Guerrero. InfluxDB is 27x Faster vs MongoDB for Time-Series Workloads – blogpost
- ClickHouse - blogpost
, .
: . . : , ? , , ? ?
: , , , . , , , , , . . , , . , , . .
: : , ?
: . . . , , , , -, 20 . -. .
, . .
. . — . , , , — . , , . . , .
: , , , , , - , - ? , , , OpenTSDB «». . , - OpenTSDB append , compaction?
: . どうもありがとう。 .
-, , , . , DBA, : « . , ». .
, by default . - -, , , . . , - PostgreSQL , , , , — . , , VACUUM, , .
OpenTSDB. , append/compaction . -, - storage, , , . , , , , , . — , Docker- , , .
, , , : « . , ». , , , . ありがとう
: , , , query (), ? query, , - , ? ?
: .
-, OpenTSDB, InfluxDB — , .
: — , , — . , , , , . , . , , , , . . .
, , , , , , : DROP — , DROP — . , .
, . , , , , , , , .
: , . : , , , , , , ? , , ? , ?
: . , , , , , . , . 20 , , 40 . , , , , , , . 今がその時です。
. — . . , (latency). - , . , latency — , , . , , -, , latency , .
, , -. , OpenTSDB , InfluxDB , . , , : 5 . , , , . , , , , . , , InfluxDB HTTP- .
: , , , . - ?
: . , , , , range , , , , .
: ? - ?
: . , , , HTTP-, , keep alive, . , , .
よろしくお願いします!
→ pavel.filonov@kaspersky.com
→ github
— Highload++ , — « , ».
" highload " Backend Conf .
, , , highload-. Tarantool, ClickHouse CockroachDB, , , , -, MySQL, — MongoDB.