 Habréでは、データマイニングのためのいわゆる「盗賊」の適用の主題がすでに繰り返し触れられています。 認識問題でよく使用される前例のマシンのすでによく知られているトレーニングとは対照的に、マルチアームバンディットは、ある意味で「推奨」システムを構築するために使用されます。 Habréでは、多腕バンディットのアイデアと、インターネットコンテンツを推奨するタスクへの適用性は、すでに非常に詳細でアクセスしやすいものになっています。 次の投稿では、先例による学習と、ビデオストリームの認識の問題における強化を伴う学習の共生についてお伝えしたかったのです。
Habréでは、データマイニングのためのいわゆる「盗賊」の適用の主題がすでに繰り返し触れられています。 認識問題でよく使用される前例のマシンのすでによく知られているトレーニングとは対照的に、マルチアームバンディットは、ある意味で「推奨」システムを構築するために使用されます。 Habréでは、多腕バンディットのアイデアと、インターネットコンテンツを推奨するタスクへの適用性は、すでに非常に詳細でアクセスしやすいものになっています。 次の投稿では、先例による学習と、ビデオストリームの認識の問題における強化を伴う学習の共生についてお伝えしたかったのです。
ビデオストリーム内の幾何学的に硬いオブジェクトを検出する問題を考えます。 2001年の遠い最初の年に、ポールヴィオラとマイケルジョーンズは検出アルゴリズムを提案しました(以降、これをヴィオラとジョーンズの方法[1]と呼びます)。 このアルゴリズムはもともと顔の検索の問題を解決するために開発されましたが、今日ではリアルタイム検出が必要なマシンビジョンのさまざまな分野で使用されています。
しかし、ビデオストリーム内の異なるタイプの複数のオブジェクトを検索する必要がある場合はどうすればよいでしょうか? このような場合、通常、複数の異なるViolaおよびJones検出器がトレーニングされ、ビデオストリームのフレームに個別に適用されるため、オブジェクトの数に比例して検索手順が遅くなります。 幸いなことに、実際には、受け入れ可能なオブジェクトが多数あるにもかかわらず、各瞬間にフレームに必要なオブジェクトが1つしか存在しない状況が頻繁に発生します。 例として、 Smart IDReaderの骨の折れる作成の過程で獲得した、私たちの実践からの本当の問題を引用しましょう。 ウェブカメラを使用して、銀行の従業員は顧客に発行された銀行カードを登録します。カードの種類を判別し、適用されたロゴによって番号を認識する必要があります。 現在、10を超える異なるタイプの支払いシステム(したがって、10を超える異なるロゴ)が存在するという事実にもかかわらず、オペレーターは毎回1枚のカードしか見せません。
多腕バンディット問題
nハンドバンディット問題の初期形式は、次のように定式化されます。 n個の異なる選択肢(オプション)のいずれかを繰り返し選択する必要があるとします。 各選択には、選択したアクションに応じて、特定の報酬が伴います。 アクションを選択した場合の平均報酬は、アクションの価値と呼ばれます。 一連のアクションの目的は、一定期間の予想される総報酬を最大化することです。 多くの場合、そのような試みはゲームと呼ばれます。
アクションの値の正確な値は不明ですが、それらの推定値は新しいゲームごとに取得できます。 次に、各時点で、そのような推定値が最大になるアクションが少なくとも1つあります(そのようなアクションは貪欲と呼ばれます)。 アプリケーションとは、次のゲームで貪欲なアクションを選択することです。 学習とは、このゲームで貪欲でないアクションの値をより正確に評価することを目的とした、貪欲でないアクションの1つを選択することです。
V t (a)が、t番目のゲームのアクションaの値の推定値を示すものとします。 t番目のゲームの開始時刻tまでにアクションaがk回選択された場合、報酬r 1 、 r 2 、...、 r kaを順次受け取ることになり、すべてのk a > 0のアクションの値は次の式で推定されます。
各ゲームで最大の期待値を持つアクションを選択するのが最も簡単であるという事実にもかかわらず、このアプローチは研究手順がないために成功につながりません。 この問題を取り除くには多くの方法があります。 それらのいくつかは非常にシンプルで、すぐにすべての数学者を思い浮かべます。 それらの一部は、すでにここでHabréで概説されています。 いずれにせよ、数学的に美しい理論をHabrの規模と形式に圧縮するのではなく、尊敬される読者に利用可能な文献へのリンクを提供する方が正しいと考えています[2]。
認識検出器を選択するタスク
それでは、ビデオストリーム内のオブジェクトを見つけるというタスクに戻ります。 Tフレームを含むビデオフラグメントがあるとします。 ビデオシーケンスの各フレームには、検出する必要があるオブジェクトを1つだけ含めることができます。 合計N個の異なるタイプのオブジェクトで、各タイプにはViolaとJonesの独自のカスケードがあります。 ビデオシーケンス内のオブジェクトは自然な方法で表示および表示されますが、オブジェクトの即時の出現または消失はありません(たとえば、はじめに説明したウェブカメラを使用して銀行カードを登録するタスクでは、自然はフレーム内のカードのスムーズな連続的な出現および消失になります)。 ビデオフラグメントの各フレームに対して検出器を選択するためのアルゴリズムを構築する必要があります(文字aで示します)。これにより、オブジェクトの最も正確な検出が保証されます。
さまざまな検出器選択アルゴリズムを比較できるようにするには、品質機能Q(a)を決定する必要があります。 アルゴリズムが次のフレームの認識検出器を「選択」するほど、関数の値は高くなります。 次に、数学を省略します(記事のフルバージョン[3]で常に見つけることができます)、関数をビデオシーケンスの正しく認識されたフレームの数として計算します。
検出器欲張りアルゴリズム
アルゴリズムの説明に直接進みます。これは、強化された機械学習ツールで動作することを思い出してください。
多腕バンディット問題で報酬が自然に発生する場合、オブジェクト検索問題では「報酬」の概念に別の定義が必要です。 オブジェクトが正しく検出された場合はアクション(認識カスケード)を選択した場合の報酬は正でなければならず、そうでない場合はゼロでなければならないことは直感的に明らかです。 ただし、ゲームの時点では、フレームで使用可能なオブジェクトに関する信頼できる情報はありません。そうしないと、画像内でオブジェクトを見つけるタスクが意味をなさないためです。 次に、ターゲットオブジェクト検出器の精度と完全性が良好であると仮定して、画像内で見つかったオブジェクトに対してのみ適切な検出器の選択を推奨します(つまり、次のゲームの報酬は、オブジェクトがフレーム上にある場合は1、そうでない場合は0です)。
次に、アクションの値を計算する方法を検討します。 多腕バンディットの説明に示されている式は、静止したタスク(システムが時間とともに変化しない場合)にのみ適しています。 非定常タスクでは、後の報酬が前の報酬よりも優先されます。 これを達成する最も一般的な方法は、指数平均を使用することです。 次に、次の報酬r k + 1を受け取ったときのアクションaの値は、次の再帰式によって決定されます。
ここで、αはステップサイズです(αの値が大きいほど、アクションの値の重みが大きくなり、新しい報酬が得られます)。 物理的な観点から、パラメーターαは現在のアクションが貪欲になる速度を制御します。
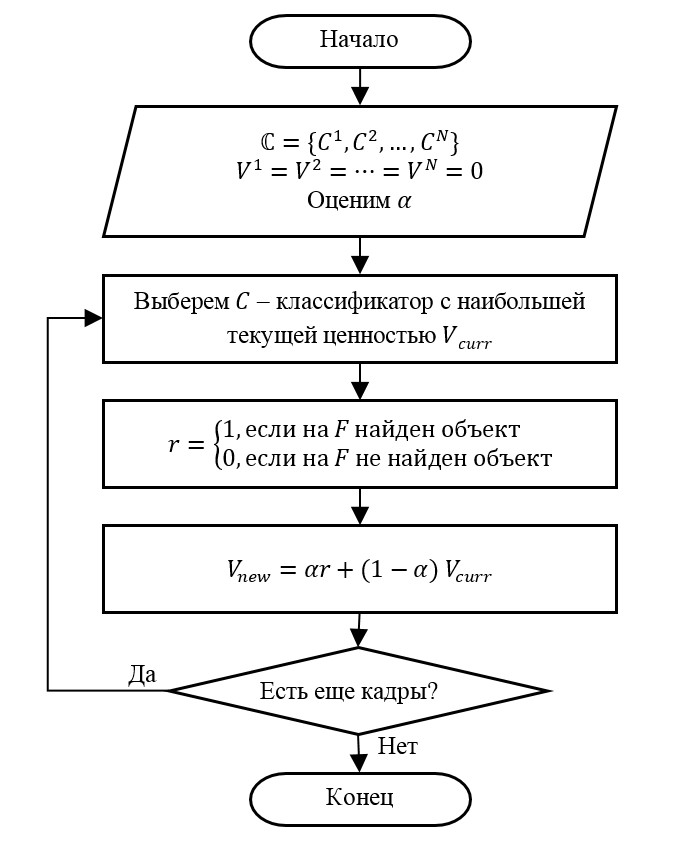
上記に基づいて、適応検出器選択アルゴリズムは、以下の一連のステップとして表すことができます。
ステップ1(初期化)。 N個の検出器があるとします。 検出器の値の初期値V 1 = V 2 =⋯= V N = 0を設定します。パラメーターαの値を選択します。
ステップ2.値V currの最大電流値を持つ検出器Cを選択します 。 そのような検出器が複数ある場合、それらの1つをランダムに選択します。
ステップ3.選択した検出器Cを次のフレームFに適用します。 導入された規則に従って検出器rのゲインを決定します(つまり、 Fにオブジェクトがある場合はr = 1)。
ステップ4.上記の再帰式に従って、検出器Cの値V newの値を更新します。
手順5.オブジェクトを検索するためのフレームがまだある場合は、手順2に進みます。 それ以外の場合、処理を終了します。
実験結果
冒頭で述べたように、このアルゴリズムを使用して、ビデオストリーム内の銀行カードの種類を判別する問題を解決しました。 オペレーターは銀行カードをウェブカメラに提示し、認識システムは既存のロゴによってカードの種類を判断する必要があります。

提案されたアルゴリズムの品質を評価するために、VISA、MasterCard、American Express、Discover、UnionPayの5つのタイプの銀行カードの29の表現を含むテストビデオフラグメントを準備しました。 ビデオフラグメントのフレームの総数は1116でした。テストビデオフラグメントのフレーム構成を表に示します。 私たちは、Viola and Jones方式(もちろん、まったく異なる画像で)を使用して、支払いシステムのロゴ検出器を事前にトレーニングしました。
| オブジェクトタイプ | カードの数 | フレームの総数 |
|---|---|---|
| ビザ | 16 | 302 |
| マスターカード | 8 | 139 |
| アメリカンエクスプレス | 2 | 37 |
| 銀Union | 1 | 17 |
| 発見 | 2 | 34 |
| カードのないフレーム | - | 587 |
| 合計 | 29日 | 1116 |
提案されている検出器選択アルゴリズム(AED)の有効性は、シーケンシャルアルゴリズムと比較して評価されました(トレーニングされたロゴ検出器が順番にフレームに適用されます)。 このようなシーケンシャルアルゴリズムは非常に意味があり、間引きによって検出を加速するという考えを実装しています。 この表は、品質汎関数Qの値と、個々の間隔ポイントの処理済みフレームの総数Q rに対する品質汎関数の比率を示しています。
| 方法 | 300 | 600 | 900 | 1116 |
|---|---|---|---|---|
| 代替 | 191(0.64) | 379(0.63) | 547(0.61) | 676(0.61) |
| AVD | 216(0.72) | 446(0.74) | 682(0.76) | 852(0.76) |
表示される表形式データのグラフィカルな表現を次の図に示します。

記載されている検出器選択アルゴリズムは、代替方法と比較してより良い検出品質を提供するという事実にもかかわらず、理想的な品質はまだ達成されていません。 これは、使用されるViolaとJonesのカスケードの独自の品質パラメーター(精度と完全性によって決定される)に一部起因します。 これを確認するために、フレームごとにすべてのロゴ検出器を同時に使用する実験を行いました(もちろん、この場合は時間に注意を払っていません)。 この実験の結果、品質関数Q * = 1030( Q r * = 0.92)の最大可能値が得られました。これは、より正確な新しい検出器をトレーニングする必要があることを示しています:-)
おわりに
ビデオストリーム内のオブジェクトを検索するタスクでは、1つのフレームの処理速度が重要です。 Viola and Jonesメソッドなどの高速アルゴリズムを適用しても、必要な速度が得られない問題があります。 そのような場合、さまざまな機械学習手法(ユースケーストレーニングや強化学習など)の組み合わせにより、アルゴリズムの過剰最適化や鉄の予定外のアップグレードに頼ることなく、問題をエレガントに解決できる場合があります。
参照リスト
- Viola P.、Jones M. Robust Real-time Object Detection // International Journal of Computer Vision。 2002年。
- サットンR.S.、バルトE.G. 強化されたトレーニング。 M。:BINOM。 知識の研究室、2012.399 p。
- ウシリンS.A. Viola-Jonesカスケードによるビデオストリーム内のオブジェクトのマルチクラス検出アルゴリズムのパフォーマンスを向上させる追跡方法の使用//ロシア科学アカデミーのシステム分析研究所(ISA RAS)のトランザクション。 2017. No. 1(67)。 C. 75〜82。