最初の記事ではPostgreSQLのインデックス作成メカニズム 、2番目の記事ではアクセスメソッドインターフェイスについて説明しましたが、特定の種類のインデックスについて説明する準備ができました。 ハッシュインデックスから始めましょう。
ハッシュ
装置
一般理論
多くの最新のプログラミング言語には、基礎となるデータ型としてハッシュテーブルが含まれています。 外見は、整数ではなく通常の配列のように見えますが、任意のデータ型(たとえば、文字列)がインデックスとして使用されます。 PostgreSQLハッシュインデックスの構造は似ています。 どのように機能しますか?
通常、データ型には有効な値の非常に広い範囲があります。理論的には、テキスト型の列にいくつの異なる行を表示できますか? 同時に、テーブルのテキスト列に実際に保存される値の数はいくつですか? 通常はそれほどではありません。
ハッシュの考え方は、任意のデータ型の値を小さな数値(0〜N -1、合計N値)と一致させることです。 このマッピングはハッシュ関数と呼ばれます。 結果の数値は、テーブルの行(TID)にリンクを追加できる通常の配列のインデックスとして使用できます。 このような配列の要素はハッシュテーブルバスケットと呼ばれます -同じインデックス値が異なる行で発生する場合、複数のTIDが同じバスケットに存在する可能性があります。
ハッシュ関数の方が優れているほど、バスケット間で初期値がより均等に分散されます。 しかし、優れた関数であっても、異なる入力値に対して同じ結果が得られる場合があります-これは衝突と呼ばれます。 そのため、1つのバスケットには、異なるキーに対応するTIDが存在する可能性があるため、インデックスから取得したTIDを再確認する必要があります。
例として:文字列に対してどのハッシュ関数を考えることができますか? バスケットの数を256にします。次に、バスケット番号として、最初の文字のコードを取得できます(たとえば、1バイトのエンコードがあります)。 これは良いハッシュ関数ですか? 明らかにそうではありません:すべての行が同じ文字で始まる場合、それらはすべて1つのバスケットに分類されます。 均一性の問題はありません。すべての値を再確認する必要があり、ハッシュの意味全体が失われます。 256を法とするすべての文字のコードを合計するとどうなりますか? 理想からは程遠いものの、はるかに優れています。 PostgreSQLでこのようなハッシュ関数が実際にどのように機能するのか疑問に思っている場合は、 hashfunc.cの hash_any()の定義を参照してください。
インデックスデバイス
ハッシュインデックスに戻ります。 私たちのタスクは、あるデータ型(インデックスキー)の値から対応するTIDをすばやく見つけることです。
インデックスに挿入するとき、キーのハッシュ関数を計算します。 PostgreSQLのハッシュ関数は常に2 32≈40億の値の範囲に対応する整数を返します。 バスケットの数は最初は2に等しく、データ量に合わせて動的に増加します。 バスケット番号は、ビット演算を使用したハッシュコードによって計算できます。 このバスケットにTIDを入れます。
しかし、これは十分ではありません。異なるキーに対応するTIDが1つのバスケットに分類される可能性があるためです。 になる方法 元のキー値をTIDとともにバスケットに書き込むことは可能ですが、これによりインデックスのサイズが大幅に増加します。 そのため、バスケットのスペースを節約するために、キー自体ではなく、ハッシュコードが保存されます。
インデックスを検索するとき、キーのハッシュ関数を計算し、バスケット番号を取得します。 バスケットの内容全体をソートし、必要なハッシュコードを持つ適切なTIDのみを返すことは残ります。 ハッシュコードとTIDのペアが整然と格納されているため、これは効率的に行われます。
しかし、2つの異なるキーが同じバスケットに落ちるだけでなく、同じ4バイトのハッシュコードを持つことになります。誰も衝突をキャンセルしませんでした。 したがって、アクセス方法は、一般的なインデックスメカニズムに各TIDを制御するように要求し、テーブル行の条件を再確認します(メカニズムは可視性チェックとともにこれを実行できます)。
ページ構成
リクエストの計画と実行の観点からではなく、バッファキャッシュマネージャの目を通してインデックスを見ると、すべての情報、すべてのインデックスエントリをページにパックする必要があることがわかります。 このようなインデックスページはバッファリングされ、テーブルページと同様にそこからプッシュされます。
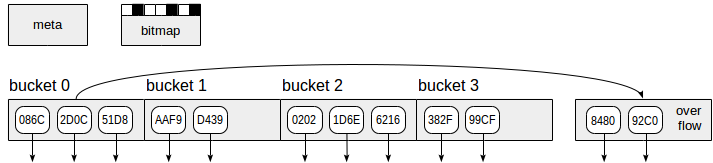
ハッシュインデックスは、図からわかるように、4種類のページ(灰色の四角形)を使用しています。
- メタページ(メタページ)-ゼロページには、インデックスの内容に関する情報が含まれます。
- バスケットのページ(バケットページ)-インデックスのメインページ。「ハッシュコード-TID」のペアの形式でデータを格納します。
- オーバーフローページ-バスケットページと同じ方法で配置され、バスケットの1ページでは不十分な場合に使用されます。
- ビットマップページ-他のバスケットに使用できる無料のオーバーフローページを示します。
インデックスページの要素から来る下矢印は、TID(テーブル行へのリンク)を象徴しています。
インデックスの次の増加に伴い、前回よりも2倍のバスケット(および対応するページ)が即座に作成されます。 このような潜在的に多数のページをすぐに強調表示しないようにするために、バージョン10では、サイズがよりスムーズに増加しました。 オーバーフローページは必要に応じて割り当てられ、ビットマップページで追跡されます。ビットマップページも必要に応じて割り当てられます。
ハッシュインデックスは、サイズを減らす方法を知らないことに注意してください。 インデックス行の一部を削除すると、選択したページがオペレーティングシステムに戻されなくなると、それらはクリーニング後の新しいデータ(VACUUM)にのみ再利用されます。 インデックスの物理サイズを小さくする唯一の方法は、REINDEXまたはVACUUM FULLコマンドを使用してインデックスを最初から再構築することです。
例
ハッシュインデックスを作成する例を次に示します。 テーブルを再発明しないために、以下では航空輸送に関するデモデータベースを使用し、今回はフライトテーブルを使用します。
demo=# create index on flights using hash (flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged
CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
ハッシュインデックスの現在の実装の不快な機能は、それを使用したアクションがプリエンプティブレコードのログに分類されないことです(PostgreSQLがインデックスの作成時に警告します)。 結果として、ハッシュインデックスは障害後に復元できず、レプリケーションに関与しません。 さらに、ハッシュインデックスは、アプリケーションの普遍性においてBツリーよりも著しく劣っており、その有効性も疑問を提起します。 つまり、現在、このようなインデックスを使用することは実用的ではありません。
ただし、PostgreSQLの10番目のバージョンのリリースにより、この秋に状況が変わります。 その中で、最終的にハッシュインデックスにログサポートが追加され、さらにメモリの割り当てと同時操作の効率が最適化されました。
ハッシュセマンティクス
ハッシュインデックスは、PostgreSQLの誕生から現在まで、使用できない状態でほとんど存在していたのはなぜですか? 実際、ハッシュアルゴリズムはDBMSで非常に広く使用されており(特に、ハッシュ結合およびグループ化に)、システムはどのハッシュ関数をどのデータ型に適用するかを知る必要があります。 しかし、この通信は静的ではなく、一度だけ設定することはできません-PostgreSQLでは、新しい型をその場で追加できます。 ここで、ハッシュアクセスメソッドでは、そのような対応が含まれており、補助関数の演算子族へのバインディングの形式で提示されます。
demo=# select opf.opfname as opfamily_name,
amproc.amproc::regproc AS opfamily_procedure
from pg_am am,
pg_opfamily opf,
pg_amproc amproc
where opf.opfmethod = am.oid
and amproc.amprocfamily = opf.oid
and am.amname = 'hash'
order by opfamily_name,
opfamily_procedure;
opfamily_name | opfamily_procedure
--------------------+--------------------
abstime_ops | hashint4
aclitem_ops | hash_aclitem
array_ops | hash_array
bool_ops | hashchar
...
これらの関数は文書化されていませんが、対応する型の値のハッシュコードを計算するために使用できます。 たとえば、text_opsファミリの場合、hashtext関数が使用されます。
demo=# select hashtext('');
hashtext
-----------
127722028
(1 row)
demo=# select hashtext('');
hashtext
-----------
345620034
(1 row)
プロパティ
このアクセス方法がそれ自体についてシステムに報告するハッシュインデックスプロパティを見てみましょう。 前回引用したリクエスト。 次に、結果のみに制限します。
name | pg_indexam_has_property
---------------+-------------------------
can_order | f
can_unique | f
can_multi_col | f
can_exclude | t
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | t
bitmap_scan | t
backward_scan | t
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | f
search_array | f
search_nulls | f
ハッシュ関数は順序関係を保持しません。1つのキーのハッシュ関数の値は他のキーの関数の値より小さいため、キー自体の順序付けについて結論を出すことはできません。 したがって、ハッシュインデックスは、原則として、「等しい」単一の操作をサポートできます。
demo=# select opf.opfname AS opfamily_name,
amop.amopopr::regoperator AS opfamily_operator
from pg_am am,
pg_opfamily opf,
pg_amop amop
where opf.opfmethod = am.oid
and amop.amopfamily = opf.oid
and am.amname = 'hash'
order by opfamily_name,
opfamily_operator;
opfamily_name | opfamily_operator
---------------+----------------------
abstime_ops | =(abstime,abstime)
aclitem_ops | =(aclitem,aclitem)
array_ops | =(anyarray,anyarray)
bool_ops | =(boolean,boolean)
...
したがって、ハッシュインデックスは順序付けられたデータ(can_order、orderable)を生成できません。 同じ理由で、ハッシュインデックスは未定義の値では機能しません。操作「等しい」は、null(search_nulls)には意味がありません。
キー(キーハッシュコードのみ)はハッシュインデックスに格納されないため、排他的インデックスアクセス(リターナブル)に使用することはできません。
このアクセス方法がサポートしない複数列インデックス(can_multi_col)。
内部
バージョン10以降、 pageinspect拡張機能を使用してハッシュインデックスの内部構造を調べることが可能になります。 これがどのように見えるかです:
demo=# create extension pageinspect;
CREATE EXTENSION
Metastage(インデックスの行数と最大のバスケット番号を取得します):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx', 0 ));
hash_page_type
----------------
metapage
(1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx', 0 ));
ntuples | maxbucket
---------+-----------
33121 | 127
(1 row)
カートページ(実際の行数とクリアできる行数を取得します):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx', 1 ));
hash_page_type
----------------
bucket
(1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx', 1 ));
live_items | dead_items
------------+------------
407 | 0
(1 row)
などなど。 ただし、使用可能なすべてのフィールドの意味を理解することは、ソースコードを学習しなければ成功する可能性は低いです。 このような要望がある場合は、 READMEから始めてください。
継続する 。