私たちは伝統を変えず、ポスグレに捧げる豊かで興味深いプログラムを準備します。 それにもかかわらず、同僚とのコミュニケーションと参加者からのフィードバックにより、膨大な数の専門家が、データを保存するためのいくつかのシステムの操作に、強制的または独自の決定によって関与していることが明らかになります。 私たちは、同僚と互いにコミュニケーションを取り、経験を交換し、問題を解決する方法を見つける機会を奪いたくありません。 そのため、2017年、 PG Dayは、 PostgreSQL 、 MySQL 、 Oracle 、 MS SQL Server 、 NoSQLソリューション、その他の無料および商用DBMSの5つの並列スレッドに分割されています 。
GHGデイの構造の抜本的な変更は今年だけで始まったという事実にもかかわらず、ワークショップの同僚からのイベントへの関心がずっと早く現れ始めました。 過去のPG Dayの1つで、 Andrei RynkevichはOracleからPostgreSQLへの興味深いレポートを発表しました-Phormでの移行の経験に基づいた4年の旅で、Habr読者に喜んで提示しました。
「オラクルからPostgreSQLへの4年の旅」レポートは、「生産」でPostgreSQLを完全に搭載した製品のインストールで来月中に終了する予定である、私たちのプロジェクトの最大の課題に関するものです。

最初は、Oracleがあり、ユーザーアクティビティはほとんどありませんでした。 そのような状況では、どのテクノロジーを使用するかは重要ではありません。 質問をどれだけ上手く書いても構いません-すべてが完璧に機能します。 しかし、アナリストはあなたの助けになります。
そのため、特別な種類の統計が表示されました。これは、軽い負荷でもディスクが眼球に完全に詰まったキーです。 約5 TBでした。 もちろん、統計をオフにしましたが、初めて拡張用の追加データベースについて考え始めました。 負荷は増大していましたが、最適化の機会はOracleライセンスによって制限されていました。 現在のライセンスでは4コアしか使用できませんが、この制限により、リクエストにスタンバイを使用することさえできず、パーティション化も行われません。このような機関車では遠くに行けません。 そのため、拡張のオプションを検討し始めました。

初めに、Oracleの機能に注目しました。 現在のライセンスには年間15,000ポンドがかかります(サポートと新しいバージョンのアップグレード)。 プロセッサのライセンス制限およびパーティション分割のためのドキュメントの削除は、この量に非常に大きな貢献を追加しました。したがって、あまりお金がなかったので、私たちはこのようには行きませんでした。
最初に検討したソリューションはMySQLでした。 当時、MySQLはすでにプロジェクトで使用されていましたが、人々と話し合った結果、かなり問題が多く機能が制限されていることがわかりました。 そのため、NoSQLソリューションをかなり検討しました。 当時、NoSQLの開発者はいませんでしたが、これは非常に劇的な変化であるように思われたので、脇に置きました。
私たちにとって最も適切なソリューションはGreenplumでした。これはPostgreSQLに基づいて構築されたMPPデータベースです。 もちろん、唯一のマイナスはそれも支払われたということですが、金額はOracleの金額と同じではないため、Greenplumへのさらなる移行を目標にPostgreSQLで停止することにしました。 計画によると、このような移行はそれほど難しくないはずです。

最初に、マスター+スタンバイ(24コア、128 GBのRAM)、3テラバイト(3 TB)のRAID10を構築した2台のホストを購入しました-SSDは非常に高価なため、SSDディスクではありません。 そして、次に何をすべきかを考えました。
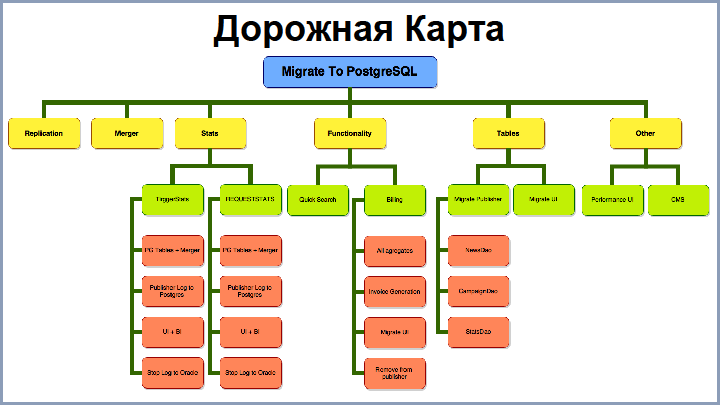
最初の段階では、移行のすべてのステップを明確かつ詳細に理解していませんでした。 ある時点で、ロードマップを描画する必要がありました。 画面には、このロードマップの大幅に切り捨てられたバージョンが表示されます。 ステージのうち、次のものを区別できます。
- OracleデータベースからPostgreSQLデータベースへのデータ複製。
- 合併-「生」ブロックをデータベース自体に埋める方法として。
- OracleからPostgresへの統計転送。
- 機能の移転。
- テーブルと関連プロジェクトを転送します。
さらに-各ステージについて順次。
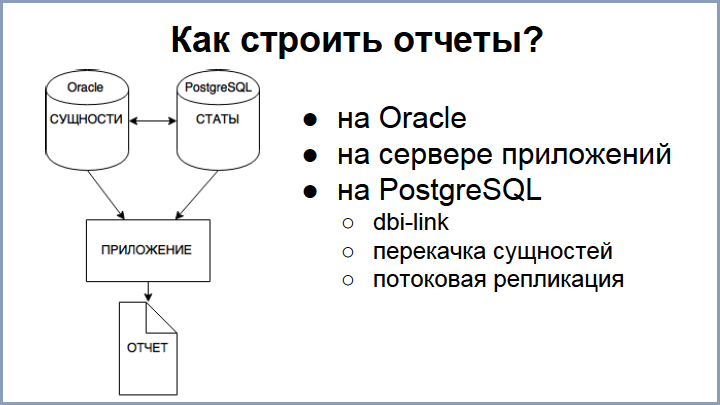
当初、私たちは一度に移行する機会がないことをすでに理解していたため、統計から始めることにしました。 そして、一部の統計が部分的にPostgreSQLにあり、残りがOracle(主にエンティティ)にあるような瞬間が形成されました。 問題は、レポートに両方が必要なことです。 質問:どのようにレポートを作成しますか?
まだ機会が限られているため、Oracleのオプションをすぐに却下しました。 アプリケーションサービスを構成し、Oracleからエンティティを抽出し、PostgreSQLから統計情報を取得して、何らかの方法で接続とフィルタリングを行うことができます。 このようなアプリケーションは、データベースに対して作業を行います。 このアプローチは非常に複雑に思えたので、さまざまな程度で使用する3つのアプローチをさらに実装しました。
最初のオプション :PostgreSQLでレポートをリクエストする際にDBIリンクを使用して必要なエンティティをOracleからポンプアウトする-このアプローチは機能しており、多数のエンティティで大きなデータをポンプする必要がある場合、すべてが遅くなり、そのような最適化が行われるため、小さなサンプルに適していますクエリは非常に複雑です。 このアプローチは、エンティティの関連性が必要な場合に関連します。「編集」ページに移動し、新しい要素を追加し、保存したらすぐに新しい統計で表示する必要があります。
次のオプションは、すべてのエンティティをOracleからPostgreSQLに転送し、すべてのエンティティを定期的に転送することです。 このアプローチも使用しますが、実際には、エンティティの数に約100 GBがかかるため、postgresでのエンティティの関連性は遅れています。 ただし、このオプションは、データの関連性を必要としない大きなレポートを処理する必要がある場合に有効です。 しかし、何らかの統計が遅れ始めるとすぐに30分で私たちに頼る私たちの演算子を知って、私たちはストリーミングレプリケーションを実装することに決めました:Oracleに更新すると、エンティティはほぼすぐにPostgresに入ります。
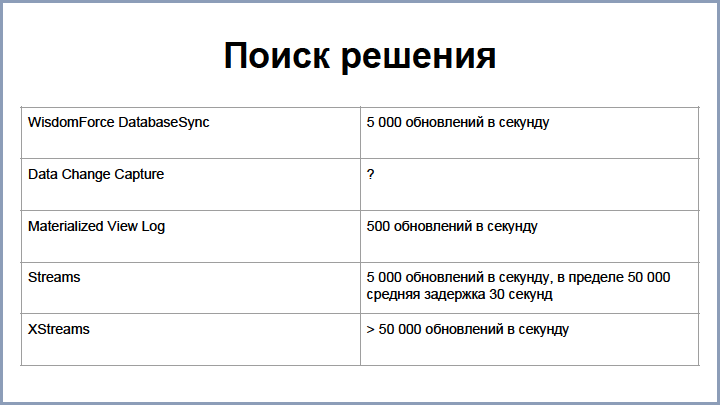
この問題に対処するために、次のオプションが検討されました。
WisdomForce Database Syncは、当時存在していた商用製品です。 それは私たちによく合い、速度は毎秒約5,000の更新を提供しましたが、使用することに決めた瞬間に別の会社がそれを購入し、プロジェクトが市場から消えたので、私たちはそれを把握して自分でソリューションを構築する必要がありました。
検討された最初のオプションは、 Oracle DataChange Captureです。 これらは、Oracleデータベースで実行されるJavaプロセスです。 彼らはプレートの変化をキャッチし、それらをキューに詰める方法を知っています。 残念ながら、この決定のスピードは歴史上失われましたが、それほど速くはありませんでした。
レプリケーションの最初のバージョンは、 マテリアライズド・ビュー・ログに基づいて構築されました-これらは、マスター・プレートに対するすべての変更を保存し、マテリアライズド・ビューで迅速に再カウントするために使用されるOracle特殊プレートです。
このソリューションは実装が非常に簡単で、1秒あたり約500の更新速度が得られましたが、製品が成長し、これでは不十分であることが判明しました。 次に、Oracleから他のソースにデータを複製する特別なOracleテクノロジーStreamに切り替えました。 また、現在の速度では、1秒間に5000回の更新でエンティティをポンプおよび更新することができます(制限では最大50 000にすることができました)が、平均遅延には最大30秒かかります。 そして、興味深いことに、Oracleで1つのレコードを更新しても、すぐにはStreamに到達しませんが、これらすべてのプロセスに遅延があるため、多少の遅延が発生します。
また、Oracleにはストリームテクノロジーの継続性があります。XStreamsを使用すると、より良い結果を得ることができますが、有料ソリューションがあるため、テストしましたが、使用しませんでした。

複製スキームは非常に単純です。 オラクルは、REDOログを読み取るプロセスを作成しています。これは、PostgreSQLのWALファイルに類似しています。 複製する必要のあるすべてのラベルは、別のラベル「複製データ」に記録されます。 ミドルウェアの助けを借りて、REDOログハンドラープロセスが各プレートでハングします。 その結果、出力でデータが取得され、「レプリケーションデータ」プレートも追加されます。
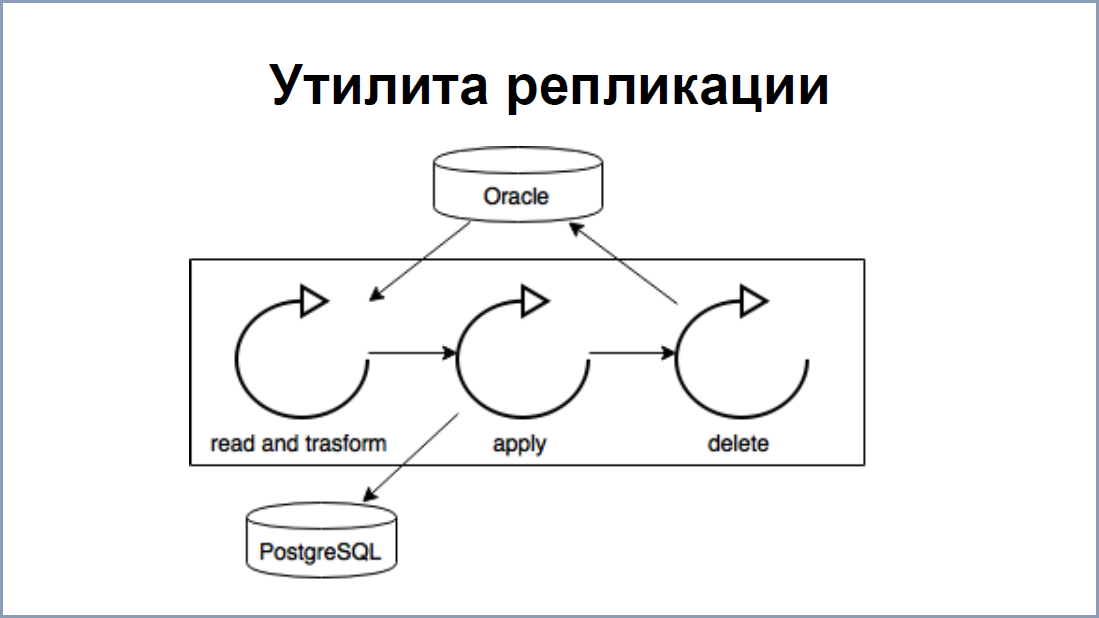
PostgreSQLの側で、 Javaレプリケーションアプリケーション/ユーティリティを構築しました-このデータをレプリケーションデータから読み取り、PostgreSQLに書き込みます。 その利点は、データをトランスアクティブに読み書きできる場合、整合性の違反がないことです。
1秒あたり5000の速度については、基本的に、レプリケーションユーティリティはこの場所の狭いリンクです。 先ほど述べたように、ストリームプロセスでは、最大50,000件のソート/更新を保持できます。 ユーティリティを高速化するために、 3つのスレッドに分割しました。
- 最初のストリームは、レプリケーションデータからデータを読み取り、PostgreSQLに既に適用できるクエリに変換しました。
- 2番目はこれらの変更を適用しました。
- 3番目は、複製データプレートから処理済みデータを消去しました。

ストリームプロセスでは、データレプリケーションだけでなく、DDLも許可されます。 最初は、この問題を解決するために急いで行きました。 幸いなことに、システムは複雑であり、すべての手動による単収縮を最小限に抑えたかったのですが、DDL言語自体が多様であるため、簡単ではありませんでした。 さらに、DDLをOracleからPostgreSQLに翻訳することにはあいまいな点があります。 そのため、このDDLの亜種については、実稼働環境でアカウントが作成されないことがよくありました。 その結果、postgresでそれらを再作成し、データをリロードする方が簡単だと判断しました。 その結果、サポートする命令を1つ残しました-これはTRUNCATEです。

ほとんどの場合、1秒間に5000回の更新が許容されますが、まだ不足している瞬間があります。 これはまさに、Oracleの大量データのパッチです。 そのため、更新プログラムが数十ギガバイトに影響を与えることがありました。 ストリームプロセスは十分に重いため、これらのボリュームをすべて実行することはサーバーにとって非常に高価です。 そのため、このようなスキームを思いつきました。
データベース設計者は、自分のパッチが多数の変更に影響を与えることを理解している場合、レプリケーションを停止する必要があるという特定のフラグをパッチシステムに設定します。 このパッチを適用すると、パッチシステムはストリームプロセスを停止し、タブレットで独自の処理を行い、最後にレプリケーションプレートにマーカーが書き留められ、パッチが終了したこととタブレットを初期化する必要があることを示しました。 次に、パッチシステムはpostgresに進みました。 彼女は、すでにPostgresにあるOracleで書かれたこの最後のトークンを待っていました。 彼はいつも最後に来ました。 システムはフラグを確認し、プレートを再作成する必要がある場合、DBIリンクを使用してそれらを再作成し、Oracleからすべてのエンティティを抽出しました。 そして、彼女はシステム自体のパッチを適用しました。 それがすべてレプリケーションです。

次のステップは、データをデータベース自体にロードすることです。 実際、私たちのプロジェクトはいくつかに分かれています。実際には、データベース自体です。 UI。エンティティのベースに流れ込み、レポートを発行します。 ストアドプロシージャを通じて毎日150 GBをポンピングするログサーバー。
データベース開発者は実際にはlog-server-databaseバンドルを制御しないため、多くの問題が発生します。 たとえば、統計はさまざまな国から、さまざまな時間にさまざまな量で取得され、定期的に負荷が急増します。 これがすべてのユーザーに影響することは明らかです。 次の問題は、予期しないこともあります。ログサーバーが生成するデータのパケットが大きすぎます。 繰り返しますが、このようなバンドルを処理すると、サーバー上の多くのリソースが消費され、他のすべてのプロセスに影響します。 さらに、統計のために失敗したパッチを処理することは依然として困難です。
何かが「フロッピー」である場合、これらの統計はログサーバーに残ります。 データベース開発者は、どういうわけかそこにたどり着き(これが常に可能であるとは限りません)、ストアドプロシージャを変換する必要があります(呼び出し、修正、再入力)。 これはかなり複雑な決定です。 したがって、postgresの側では、少し異なる方法でファイルをアップロードしました。 ログサーバーはストアドプロシージャを呼び出さなくなりましたが、csvファイルを発行します。

特定のルールに従って、各タイプの統計をデータベースにアップロードするマージプログラムがあります。 すべての「偽の」ファイルは同じホスト上にあり、これにより以前の問題がすべて解決されました。 ロードジャンプは、ディスク上の未処理ファイルの数にのみ影響しました。 いつでも「ファイル」ファイルを見つけて、手で修正し、元に戻してロードできます。 また、合併により大きなバンドルが分割されたため、非常に長いトランザクションはありませんでした。

合併も長い道のりを歩んできました。
最初のオプションは膝の上で行われ、この線は緑色のように見えます。 これが彼の決定です。 つまり、統計のタイプごとに「ステージング」ラベルが作成され、これらのラベルをデータベースに配置するプロシージャが作成されました。 しかし、このオプションはすべてのソリューションに適しているわけではないため、よりシンプルでより普遍的なものにしたかったのです。 そこで、2番目のオプションがありました。
画面には、統計を処理するための最初で最も簡単なルールが表示されます。 プログラムは、ファイルの名前によって、どのルールを取るかを理解し、データベース内のラベルは同じルールに対応していました。 主キーはこのプレートから選択され、すでに各行のこれらの主キーによって、INSERTまたはUPDATEを実行する必要があるかどうかをすでに理解できました。
これらのルールはほとんどのタイプの統計を記述しますが、まだ多くのオプションがあります。 そのため、Merger構文は成長し続けています。 そのため、INSERTまたはUPDATEのルールがあり、これまたはそのパーティションを実行する必要がある場合に条件を設定し、他のあらゆる変な方法を埋めます。 しかし、おそらく次のことが区別できます。 統計は、PostgreSQLのエンティティよりも早く来ることがあります。 これは、たとえば、レプリケーション自体が「落ちた」か、しばらく動作しなかった場合に発生します。

この問題を解決するために、トリッキーな小さなスキームも作成しました。 OracleにはHEART_BEATと呼ばれるプレートと、30秒ごとにタイムスタンプを挿入するジョブがあります。 このプレートはPostgreSQLデータベースに複製され、Mergerはすでに何が必要かを理解できます。 到着した最後のハートビートを調べ、そのハートビートよりも新しいファイルのみを処理します。そうしないと、一部のデータが失われる可能性があります。 エンティティが存在しないが、すでに統計に含まれている場合は、マージすると消えることは明らかです。

レプリケーションと合併により、統計に進むことができました。 スライドには、このプロセスのわずかに変更されたバージョンが表示されています。 ステージのうち、次のものを区別できます。
- 合併のラベルとルールの作成。
- csvファイルを介してOracleとPostgreSQLの両方にログインするためのログサーバーの翻訳。
何らかの理由で、他のすべてを一度に転送することを恐れていました。 したがって、各段階で、何らかの問題が発生した場合に戻る機会を何とかして保持しようとしました。 本番環境で二重ロギングがしばらく保持されていた場合、UIとレポートの両方の変換を開始しました。
ここで、移行への恐怖も認識しました。したがって、 2つの同一のレポートが同時にシステムに存在し、1つはOracleで機能し、もう1つはPostgreSQLで機能しました。 これは、開発者とテスターの両方にとって非常に便利であることが判明しました。常に同じクエリを実行し、結果を確認してグラフィカルに比較し、見つかった問題を解決できます。

PostgreSQLの統計が多ければ多いほど、新しいケースが多くなりました。 そのため、たとえば、PostgreSQLで見つかった統計によると、ある時点で、すでにOracleにあるエンティティを更新する必要がありました。 たとえば、いくつかのしきい値を渡すとき、ステータスを変更する必要がありました。 この場合、postgresの側で、必要な統計を可能な限り集約し、dbiリンク経由でOracleにそれを詰め込む何らかの種類のジョブを開始しました。 そこ-すでにストアドプロシージャを介して、またはOracleの対応するジョブによって処理された別のプレートで。 その後、Oracleでデータ、ステータス、およびエンティティが変更され、レプリケーションを通じてPostgreSQLに移行しました。

何だと思う? これはエンティティのコレクションです 。 私はすべてのエンティティをモデラーに入れ、彼はそれらの間のすべての接続を構築しました。 ご覧のとおり、グリッドは非常に密集しており、すべてが画面に収まるわけではありません。 したがって、統計を使用した同じトリック:すべてを部分的に転送するために、接続が非常にタイトであるため、成功しませんでした。 さらに、ORMシステムはUIで機能し、接続を切断することは非常に困難です。 実際、異なるデータベースに2フェーズコミットを実装する必要があります。 同じORM-kuで2つのオプションを実行することも、モデルにとって問題でした。 そのため、エンティティの移行全体を最後のブレークスルーまで延期すると同時に、必要なポイントをすべて準備することにしました。
タブレットの1つについて、転送、切断を実装する必要がありましたが、かなり時間がかかりました。 その理由は、このプレートが非常に大きく、集中的に変化しているためです。 postgresでの初期初期化(すべてのエンティティをポンピングする必要がある)およびレプリケーションプロセスには不利でした。
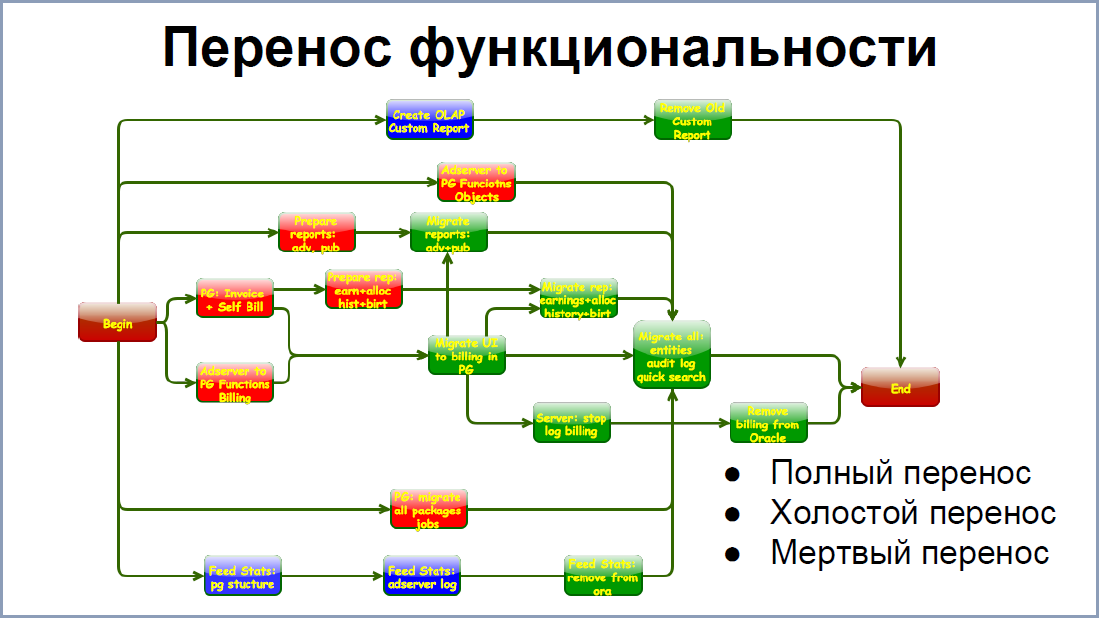
機能の転送により、少し簡単になりました。 画面には、OracleからPostgreSQLへのシステムの一部の移行段階の関係が表示されます。 もちろん、より少ないリンクがありますが、各正方形は正方形で構成されており、独自の接続があります。 したがって、最後のスパートを促進するために、可能な限りすべてを簡素化しました。 3つのオプションがあります 。
Oracleから完全に削除してpostgresで実行したときの機能の完全な移行 。 場合によっては、これが可能でした。
ほとんどの場合、 機能を転送し、アイドル状態で起動しました 。 たとえば、課金システムはこのモードで約1年間機能し、多くのパフォーマンスの問題といくつかの重大なバグを見つけることができました。しかし、そのような請求の結果はもちろんゴミ箱に捨てられました。
デッド転送とは、ストアドプロシージャをOracleからpostgresに書き換えて転送することです。これらの手順は機能しない場合があります。そして、しばしば、彼らは働かず、呼ばれなかった。しかし、これにより、次のステップのために一連の「空白」を作成することができました。

実際、最後のジャークに行くためにすべてを準備して、私たちはこの最後のジャークに対処します。実際、アイドル状態で機能し、重荷であった機能を含むすべての統計を転送しました。かなり大量の関連データをダウンロードし、ポイントでいくつかの移行を実行する必要があるため、リリース自体はかなり大きな「ダウンタイム」で行われました。興味深いことに、多くのことを行ったにもかかわらず、特定のモジュールを転送するのを忘れていたことがわかったため、リリースを約1週間延期せざるを得ませんでした。その後も、1〜2週間で移行されなかった別のモジュールが見つかり、活発に終了する必要がありました。

だから4年-これはかなり長い時間です。この値が正当化されるかどうかを理解するために、いくつかのメトリックを書き留めました。その一部はスライドに表示されています。おそらく、あなたやあなたのそれぞれは、この作品またはその作品の量の初期評価に間違えられたでしょう。同じ間違いを犯しました。当初、評価は1年半でした。そして今でも、すべてが終わったときに、2年以上もこの数字を呼ぶ人はほとんどいません。
ご覧のとおり、ベースはそれほど大きくありませんが、それほど小さくはありません。コードを取得した場合、そのような数値を0で書くには、1日あたり約80行を書く必要があります。これはそうではなく、小さなチームにとっても多くのことです。
最大の時間は、さまざまなソリューションの調査と比較に費やされました。技術的ではない他のポイントのうち、いくつかあります。ご覧のとおり、異動には、さまざまなチーム、さまざまな場所で働いていた約30人が関与しました。そして、そのような結合されたチームの調整にはかなり長い時間がかかりました。
ポイントの1つは焦点の喪失でした。。長い間、私は自分の目でこれに出くわすまでそれが何であるかを考えていました。事実、私たちはプロアクティブであり、ほとんどの場合、Oracleでこのような大きな問題は発生していなかったため、すべての移行タスクは少しバックグラウンドで行われました。また、短期的なタスクがかなりあったため、この戦略的方向性はわずかに背景に追いやられました。移行を1、2週間忘れた場合がありました。

PostgreSQLは非常に優れたデータベースであるという事実にもかかわらず、リリースごとにますます気に入っていますが、それでも移行中にいくつかのポイントが不足していました。
ジョブは、Oracleではデータベース自体に存在し、フレームワークを超えてある種のcrontabを実行することは珍しいことでした。さらに、これらすべてを監視し、すべてが正常に起動および実行されることを確認する必要があります。
リソース管理:プロセス間、たとえばユーザークエリと統計間でリソースを共有するとよい場合があります。私が思うに、Oracleが何回も節約したので、Oracleで
最もクールなのはフラッシュバックです。これは、あるバージョンを短期間復元する機会です。私たちは似たようなことを考えていますが、今ではpostgresでそれを実装することを考えています。なぜなら、インシデントのために大きなエンティティを復元する必要があったからです。
また、OEM(Oracle Enterprise Management)-これはそのようなWebアプリケーションです。特定の問題が発生すると、DBAはこのOEMに登り、そこにあるすべてのアクティビティを確認します。ストーリーを調べ、何が起こったのかを確認し、さまざまな側面の相互作用を比較し、あらゆる種類の管理作業を行うことができます。 PostgreSQLでは、もちろん、DBAは指先で精通しているため、このアプリケーションを使用した場合と同じ速度ですべてのクエリを発行できますが、DBA以外の人にとっても苦労します。したがって、独自のOEMバージョンを作成しましたが、テーブルとクエリの流通の全履歴を保存することが重要でした。その結果、そこに行って速度が低下しているものを確認し、あらゆる種類の関係を確認し、コードに変更を加えることができました。

みどり私たちはまだ危機を買いませんでしたが、量は増え続けているので、PostgreSQLですでにOracleを抱えていたのと同じ問題に直面していますが、それは大規模です。したがって、最初に遭遇した問題はディスクの制限です。ある時点で、いくつかのパーティションで非RAID操作を行う必要さえありました。したがって、RAID-10をRAID-5に変えると思われます。
この操作の主な問題は、これらのパーティションに保存されているデータが失われることです。そのため、すべてをそこに収めるためにディスク上のスポットを再生する必要がありました。リクエストには、問題もあります。処理のいくつかの制限に直面しており、一部の機能をオフにする必要さえあります。さらに、postgres から別の場所まで、多くのスペースと処理を必要とする膨大な統計を取り、特別な方法でこの方向全体を開発しました。
新しいバージョンを見ましたか?私たちは見て見ましたが、主な統計を簡単にHadoopに転送しました。 hdupにImpalaがあります、そのような円柱状の、実際には、データを処理するデータベース。そして、Hadoopクラスター内で、請求や短期ジョブの作業のいずれにも必要とされない膨大な統計をすべて抽出するという戦略的なタスクもあります。
そのため、私たちのオペレーターは時間ごとの統計を見るのが好きです。メインイベントテーブルのキーのボリュームは非常に大きく、これはサーバーにとって高価なため、Hadoopに時間ごとの統計を既に投稿しました。PG Day'17

のテーマ別の拡大は、あるデータウェアハウスから別のデータウェアハウスへの移行のトピックに関するリスナーとスピーカーの関心を高めました。移行の問題は、ほぼすべてのセクションで対処されます。、だから誰も質問しません!特にあなたのために、私たちはいくつかの興味深いレポートを提示する準備をしています。
バジルSozykinのYandexのはお伝えしますPotgreSQLへのOracleからの移行サービスをロードタオ、Yandexの専門家は「ダウンタイム」せずに、本当に巨大なデータベースを移行する方法についての刺激的な話を。アレクサンダーコロトコフ同社からPostgresのプロフェッショナルにその報告書では、「私たちの応答Uber'uは、」MySQLへのPostgreSQLのバックで人気のタクシーサービスを動かす程度センセーショナルな話の解析を行います。DistilleryのKristina Kucherovaが、彼女と彼女の同僚が、システムのOLTP部分のMS SQLからPostgreSQLへの移行、およびそれらの結果。
さて、 Oracleを実行している25のDBMSからのGreenplumでのオンラインデータ複製に関する4番目の興味深いレポートは、 Tinkoff BankのDate Warehouse管理グループの責任者である Dmitry Pavlovによって準備されています。ドミトリーがPG Dayで演じたのはこれが初めてではありません。彼の以前の報告は大成功であり、満員の部屋を集めました。この号を出版に向けて準備し、「発行」ボタンを押す準備ができた最後の瞬間に、研究所「Voskhod」の同僚がレポートを申請しました。ドミトリー・ポギベンコが語る
ダウンタイムを最小限に抑えて、DB2からPostgreSQLへの状態システム「Mir」(10 TBを超えるデータ!)のデータベースの正常な移行。
独自の移行の準備をしていますか?あるストアから別のストアに既に正常に移行し、経験を共有したいと思っていますか?PG Dayに来て、春の価格でチケットを購入し、レポートを申請してください。締め切りはもうすぐです!
夏にサンクトペテルブルクでお会いしましょう!