今日、世界中で必要な経済計算のほとんどは、世界のデータセンターで行われており、毎年ますます変化しています。 少し前まで、彼らはウェブページを配信し、広告やビデオコンテンツを配信し、今では音声を認識し、ビデオストリーム内の画像を識別し、必要なときに必要な情報を正確に提供しています。

ますます、これらの機能は、いわゆる人工知能の形式の1つを使用してアクティブになります。 「深い学習。」 これは、大量のデータから学習して、異なる言語からの翻訳、がんの診断、無人車両のトレーニングなどの問題を解決するシステムを作成するアルゴリズムです。 人工知能が私たちの生活にもたらした変化は、業界の前例のないペースによって加速されています。
ディープラーニングの研究者の1人であるジェフリーヒントンは最近、The New Yorkerのインタビューで次のように語っています。「多くのデータがあり、ディープラーニングによって解決される古い分類の問題を取ります。」 「ディープラーニング」に基づいて、数千の異なるアプリケーションにアプローチしています。
前例のない効率
Googleをご覧ください。 深層学習における革新的な研究の実行は、全世界の注目を集めています。GoogleNowサービスの驚くべき正確さ。 外出中の世界最大のプレイヤーに対する重要な勝利。 100の異なる言語で動作するGoogle翻訳の能力...
ディープラーニングは、これまでにない効果的な結果を達成しました。 しかし、このアプローチでは、コンピューターがムーアの法則がスローダウンするまさにその瞬間に膨大な量のデータを処理する必要があります。 ディープラーニングは、新しい計算アーキテクチャの発明を必要とする新しい計算モデルです。
このニッチは、しばらくの間NVIDIAによって占有されてきました。 2010年、スイスのAI研究所のJürgenSchmidhuber教授にちなんで名付けられた研究者であるDan Ciresanは、NVIDIA GPUを使用して、CPUの最大50倍の加速でニューラルネットワークを深くトレーニングできることを発見しました。 1年後、Schmidhuberの研究室はGPUを使用して、手書き認識とコンピュータービジョンの国際競争で優勝した最初の「ディープラーニング」ニューラルネットワークを開発しました。
その後、2012年、当時トロント大学の学生だったアレックスクリジェフスキーは、一対のGPUを使用して、今では有名なImageNet年次パターン認識コンテストで優勝しました。 (Schmidhuberは、最新のコンピュータービジョンでGPUを使用した「ディープラーニング」の影響の包括的な履歴を取得しました)。
「ディープラーニング」の最適化
世界中のAI研究者は、もともとグラフィックアクセラレーターとスーパーコンピューター向けに設計されたNVIDIAコンピューティングモデルがディープラーニングに最適であることを発見しました。 これは、3Dグラフィックス、医学、分子動力学、量子化学、天気シミュレーションの画像の処理とグラフィックモデリングのように、テンソルまたは多次元ベクトルの並列計算を大規模に使用する線形代数アルゴリズムです。 2009年に開発されたNVIDIA Kepler GPUは、ディープラーニングタスクのコンピューティングにグラフィックアクセラレーターを使用する可能性を世界に広げましたが、このタスク用に特に最適化されたことはありません。

「ディープラーニング」向けに最適化された多くの新しいアーキテクチャ開発を含む、最初のMaxwell、次にPascalという新しい世代のGPUアーキテクチャを開発することで、これを修正することにしました。 KIeplerのわずか4年後に導入された、PascalベースのTesla P40推論アクセラレーターであるTesla K80は、ムーアの法則よりもはるかに優れたパフォーマンスを26倍向上させます。
この間、Googleは、最終結果を発行する機能によって強化された、テンソルプロセッサ(TPU)と呼ばれる特別なアクセラレータチップを開発しました。 2015年に委託されたのは彼の会社でした。
少し前、GoogleチームはTPUの利点に関する技術情報を公開しました。 彼らは、とりわけ、TPUがK80よりも13倍優れていると主張していますが、TPUをPascalに基づく現行世代のP40と比較していません。
Google比較アップデート
Googleの比較を更新し、K80からP40へのパフォーマンスのジャンプを定量化し、TPUが現在のNVIDIAテクノロジーとどのように比較されるかを示すために、以下の表を作成しました。
P40は、計算精度と帯域幅、内蔵メモリおよびメモリ帯域幅を組み合わせて、トレーニングとエンドツーエンドの結果の両方で前例のないパフォーマンスを実現します。 トレーニングのために、P40は10倍の帯域幅と12テラフロップスの32ビット浮動小数点パフォーマンスを備えています。 完成した結果を生成するために、P40は8ビット整数と高いメモリ帯域幅での操作に対して高いパフォーマンスを発揮します。
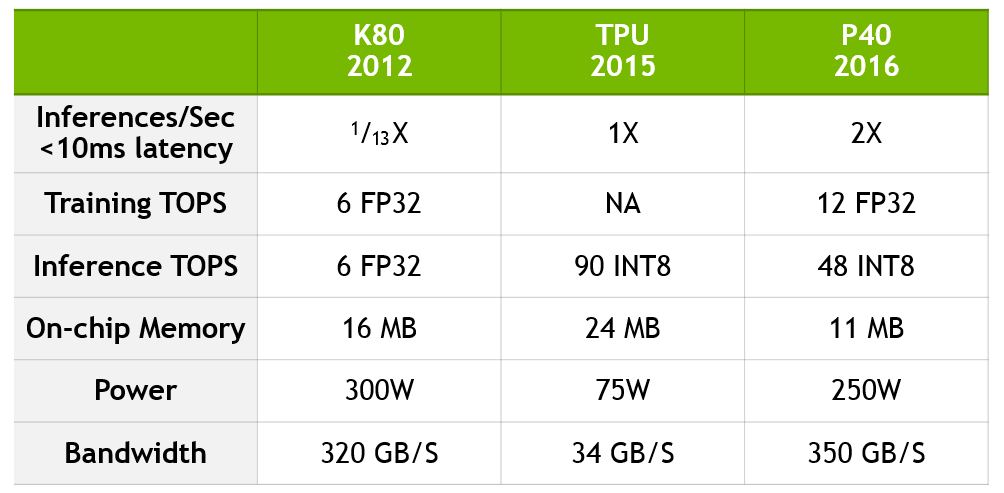
データは、Jouppi et al [Jou17]によるTensor Processing UnitレポートのIn-Datacenter Performance AnalysisおよびNVIDIA独自のデータに基づいています。 K80-TPUのパフォーマンス要因は、パフォーマンスを半完成のK80と比較するGoogleレポートのCNN0およびCNN1の平均加速率に基づいています。 K80-P40のパフォーマンス要因は、同様のパフォーマンス特性を持つパブリックCNNモデルであるGoogLeNetに基づいています。
GoogleとNVIDIAは異なる開発パスを選択していますが、これらのアプローチにはいくつかの共通のテーマがあります。
- AIはより高速な計算を必要とします。 専用のアクセラレータは、ムーアの法則が減速している時代に「深層学習」の高まる需要に対応するために必要なデータ処理の重要な部分を提供します。
- テンソル処理は、深層学習の生産性を提供し、完成した結果を提供するための中核です。
- テンソル処理は、企業が最新のデータセンターを作成するときに考慮する必要がある重要な新しいワークロードです。
- テンソルの処理を高速化すると、最新のデータセンターを作成するコストを大幅に削減できます。
コンピューター技術の世界は、すでにAI革命と呼ばれている歴史的な変革を遂げています。 今日、その影響は、Alibaba、Amazon、Baidu、Facebook、Google、IBM、Microsoft、Tencentなどの大規模なデータセンターで最も顕著です。 専門技術を使用せずに新しいデータセンターの構築と稼働に数十億ドルを費やすことなく、AIのワークロードを増やす必要があります。 高速コンピューティングなしでは、AIシステムの大規模な開発と実装はほとんど不可能です。