信頼性の低い(不安定な)、つまり、非決定的テストの動作は異なります。 同じコードで肯定的な結果と否定的な結果の両方を表示できます。 言い換えると、テストの失敗は、新しい問題を示している場合と示していない場合があります。 また、同じバージョンのコードでテストを再開してエラーを再現しようとすると、テストが成功する場合と失敗しない場合があります。 このようなテストは信頼性が低く、最終的には価値が失われます。 最初の問題が作業コードの非決定性である場合、テストを無視することは、本番環境のバグを無視することを意味します。
Googleでの信頼できないテスト
Googleの継続的インテグレーションシステムは、約420万のテストを実行します。 これらのうち、約63,000が1週間以内に予測できない結果を示しています。 それらはすべてのテストの2%未満を表していますが、それでもエンジニアに深刻な負担をかけています。
信頼できないテストを修正したい(そして新しいテストを書くのを避けたい)場合、まずそれらを理解する必要があります。 Googleでは、テストに関する多くのデータを収集します。実行時間、テストの種類、実行のフラグ、消費されたリソースです。 このデータの一部がテストの信頼性とどのように相関するかを調査しました。 この研究は、テスト方法を改善し、テスト方法をより安定させるのに役立つと思います。 ほとんどの場合、テストの規模が大きいほど(バイナリのサイズ、RAMの使用、またはライブラリの数に応じて)、信頼性は低くなります。 記事の残りの部分では、発見されたパターンのいくつかについて説明します。
信頼できないテストの以前の議論については、John Mikkoの2016年5月の記事を参照してください 。
テストサイズ-大規模なテストは信頼性が低い
テストは、サイズ別に3つのグループ(小、中、大)に分けました。 各テストにはサイズがありますが、ラベルの選択は主観的です。 エンジニアは最初にテストを作成するときにサイズを決定しますが、テストが変更されるとサイズが常に更新されるとは限りません。 一部のテストでは、このラベルは現実に対応していません。 ただし、ある程度の予測値があります。 週の間に、私たちの小さなテストの0.5%が非決定性を示し、1.6%が中程度のテストを、14%が大きなテストを示しました[1] 。 小規模なテストから中規模および中規模から大規模への信頼性の明らかな低下があります。 しかし、まだ多くの疑問が未解決のままです。 サイズのみを考えると、ほとんど理解できません。
テストが大きいほど、信頼性は低くなります
いくつかの客観的な推定値を収集します:テストのバイナリサイズとテスト中に使用されるRAMの量[2] 。 これら2つのメトリックについて、テストを同じサイズの2つのグループにグループ化し[3] 、各グループの信頼性の低いテストの割合を計算しました。 以下の数値は、最良の線形客観的予測[4]のr2値です。
| メトリックとテストの信頼性の予測との相関 | |
| メートル法 | r2 |
| バイナリサイズ | 0.82 |
| 使用RAM | 0.76 |
ここで説明するテストは、ほとんど成功/失敗のシグナルを出す密閉テストです。 バイナリサイズとRAM使用量は、テストのサンプル全体でよく相関しており、それらの間に大きな違いはありません。 そのため、大規模なテストは信頼性が低い可能性が高いだけでなく、テストの増加に伴って信頼性が徐々に低下しています。
以下に、テストスイート全体のこれら2つのメトリックを使用してグラフをコンパイルしました。 バイナリサイズが大きくなると信頼性が低下します[5]が、線形客観的予測の差[6]も増加します。
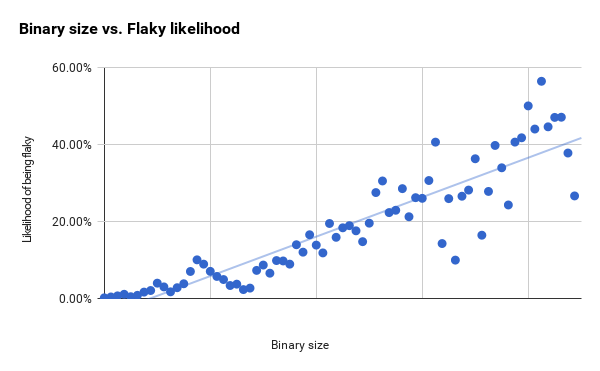
以下のRAM使用率チャートはより明確に動いており、最初と2番目の縦線の間でのみ大きな違いを示し始めています。
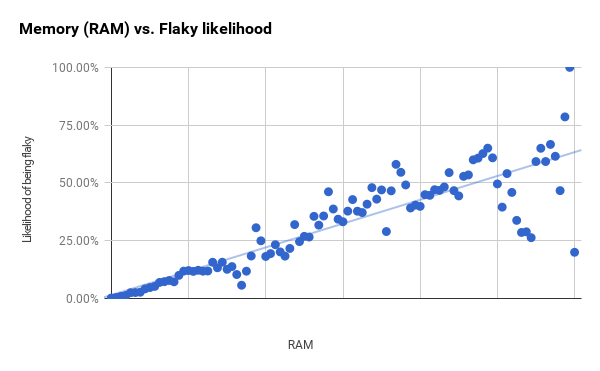
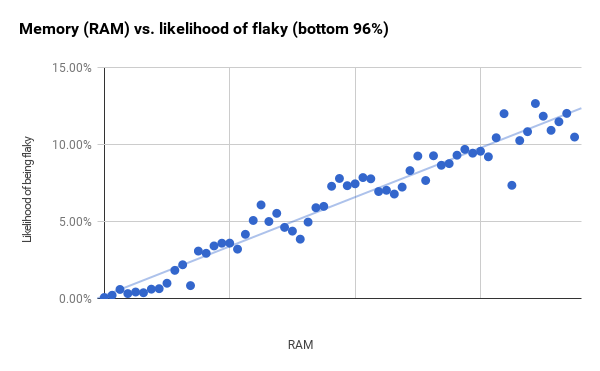
グループのサイズは一定ですが、各グループのテストの数は異なります。 グラフの右側の大きな差がある点は、左側のグループよりもテストがはるかに少ないグループに対応しています。 テストの96%未満(最初の垂直バーの直後で終了)を取得し、グループのサイズを小さくすると、より強い相関が得られます(r2は0.94)。 これはおそらく、RAMとバイナリサイズが一般的なグラフに示されているよりもはるかに大きな予測能力を持っていることを意味します。
特定のツールは、信頼できないテストの頻度と相関しています。
一部のツールは、信頼できないテストを引き起こしたとして非難されています。 たとえば、 WebDriverテスト(Java、Python、またはJavaScriptで記述されたもの)は、信頼性がないという評判があります[7] 。 通常のテストツールの一部について、このツールで記述された信頼性の低いテストの割合を計算しました。 大規模なテストを作成する場合、これらのツールはすべて頻繁に使用されることに注意してください。 これはテストツールの完全なリストではなく、すべてのテストの約3分の1をカバーしています。 他のテストではあまり知られていないツールを使用するか、そこでツールを定義できません。
| 通常のテストツールを使用する場合のテストの信頼性が低い | ||
| カテゴリー | 信頼できない共有 | すべての信頼できないテストのシェア |
| すべてのテスト | 1.65% | 100% |
| Java Webドライバー | 10.45% | 20.3% |
| Python WebDriver | 18.72% | 4.0% |
| 内部統合ツール | 14.94% | 10.6% |
| Androidエミュレーター | 25.46% | 11.9% |
これらのツールはすべて、平均を上回る割合の不安を示しています。 また、信頼性の低いテストの5つごとがJava WebDriverで記述されていることを考えると、なぜ人々がそれについて文句を言うのかが明らかになります。 しかし、相関関係は因果関係の存在を意味するものではありません。 前のセクションの結果を知ると、単なるツールではなく、他の要因がテストの信頼性を低下させると想定できます。
サイズはツールよりも優れた予測を提供します
機器の選択とテストのサイズを組み合わせて、どちらがより重要かを確認できます。 前述の各ツールについて、このツールを使用するテストを分離し、前と同じ原則に従って、メモリ使用量(RAM)とバイナリサイズのグループに分けました。 次に、最高の客観的予測の行と、それがデータとどの程度相関するかを計算しました(r2)。 次に、彼は、テストが最小グループ[8] (すでにテストの48%をカバー)で信頼できないという確率予測、およびRAM使用率の90パーセンタイルと95パーセンタイルを計算しました。
| RAMおよび機器による信頼性のない予測確率 | ||||
| カテゴリー | r2 | 最小グループ(48パーセンタイル) | 90パーセンタイル | 95パーセンタイル |
| すべてのテスト | 0.76 | 1.5% | 5.3% | 9.2% |
| Java Webドライバー | 0.70 | 2.6% | 6.8% | 11% |
| Python WebDriver | 0.65 | −2.0% | 2.4% | 6.8% |
| 内部統合ツール | 0.80 | −1.9% | 3.1% | 8.1% |
| Androidエミュレーター | 0.45 | 7.1% | 12% | 17% |
この表は、RAMの計算結果を示しています。 相関は、Androidエミュレーターを除くすべてのツールでより強力です。 エミュレータを無視すると、RAMを同様に使用するツール間の相関関係の差は約4〜5%になります。 最小テストと95パーセンタイルの違いは8〜10%です。 これは、私たちの調査で最も有用な結論の1つです。ツールにはある程度の影響がありますが、RAMを使用すると、信頼性が大幅に逸脱します。
| バイナリサイズの予測確率とツールの信頼性の欠如 | ||||
| カテゴリー | r2 | 最小グループ(33パーセンタイル) | 90パーセンタイル | 95パーセンタイル |
| すべてのテスト | 0.82 | −4.4% | 4,5% | 9.0% |
| Java Webドライバー | 0.81 | −0.7% | 14% | 21% |
| Python WebDriver | 0.61 | −0.9% | 11% | 17% |
| 内部統合ツール | 0.80 | −1.8% | 10% | 17% |
| Androidエミュレーター | 0.05 | 18% | 23% | 25% |
Androidエミュレーターでのテストでは、バイナリサイズと信頼性の間に実質的な相関関係はありません。 他のツールについては、RAM消費に関する小規模テストと大規模テストの信頼性の予測に大きな違いが見られます。 最大12パーセントポイント。 しかし、同時に、バイナリサイズでテストを比較すると、信頼性の予測の差はさらに大きく、最大22パーセントポイントです。 これは、RAMの使用を分析したときに見たものと似ています。これは、調査のもう1つの重要な結論です。バイナリサイズは、使用するツールよりも信頼性の予測の偏差にとって重要です。
結論
開発者が選択したテストのサイズは信頼性と相関しますが、Googleには、このパラメーターを予測に非常に役立つようにするサイズを選択するための十分なオプションがありません。
バイナリサイズとRAM使用量を客観的に測定した指標は、テストの信頼性と強く相関しています。 これはステップ関数ではなく連続関数です。 後者は予想外の飛躍を示し、これらのポイントであるタイプのテストから別のタイプに移動することを意味します(たとえば、単体テストからシステムテストへ、またはシステムテストから統合テストへ)。
特定のツールで作成されたテストでは、多くの場合、予測できない結果が生じます。 しかし、これは主にこれらのテストのサイズが大きいことで説明できます。 ツール自体は、この信頼性の違いにわずかに貢献します。
大規模なテストを作成する場合は注意が必要です。 テストするコードと、このための最小テストがどのようになるかを考えてください。 そして、大規模なテストを非常に慎重に記述する必要があります。 追加の保護対策なしでは、非決定的な結果でテストを行う可能性が高く、そのようなテストは修正する必要があります。
注釈
- 1週間以内に少なくとも1つの信頼できない結果が示された場合、テストは信頼できないと見なされました。
- また、テスト用に作成されたライブラリの数も考慮しました。 テストの1%のサンプルでは、バイナリサイズ(0.39%)とRAM使用量(0.34%)は、ライブラリの数(0.27)よりも強い相関関係を示しています。 次に、バイナリサイズとRAM使用量のみを調査しました。
- メトリックごとに約100グループ。
- r2は、最適な予測ラインがデータにどれだけ近いかを測定します。 値1は、行がデータと完全に一致することを意味します。
- チャートには、実際のドットが一般的な上昇傾向とは反対の傾向を示す2つの興味深い領域があります。 1つは最初の垂直線のほぼ半分から始まり、2つのデータポイントまで続き、2つ目は最初の垂直線の直前で始まり、その直後に終了します。 ここでは、サンプルサイズが十分に大きいため、単なるランダムノイズになることはほとんどありません。 これらのポイントの周りには、バイナリサイズのみに基づいて予想されるよりも多少信頼性の低いテストのクラスターがあります。 これは将来の研究の見通しです。
- 観測点と客観的予測の線の間の距離。
- 他のWebテストツールも非難されていますが、ほとんどの場合、WebDriverを使用しています。
- 最小グループの不安の予測された割合のいくつかは否定的になりました。 実際にはテストのマイナス部分はありませんが、これはこのタイプの予測を使用した場合に起こりうる結果です。