
リカレントニューラルネットワーク
リカレントニューラルネットワークは、テキスト、ゲノム、手書き、話し言葉、またはセンサー、株式市場、政府機関からの数値シーケンスなど、データシーケンスのパターンを認識するように設計された一種の人工ニューラルネットワークです。 リカレントニューラルネットワーク(以降RNN)と他のアーキテクチャの主な違いは、いわゆるメモリの可用性です。 RNNはその状態で以前の値を保持します。 RNNは動的モデルを構築していると言えます。 提供された例のコンテキストに応じて、十分な精度を達成できるように時間とともに変化するモデル。
これらのアーキテクチャに関する優れたチュートリアル。
また、RNNの信じられないほどの効果について、世界有数のディープラーニング研究者の1人であるAndrei Karpatnyによる素晴らしい投稿をお勧めします。
リカレントニューラルネットワークの不合理な有効性
モデルとトレーニング
モデルを作成するには、トランプのスピーチの本文を見つける必要がありました。 短い検索の後、私はトランプが議論で話していることに気づき、さらにさまざまなトピックに関するいくつかのインタビューと声明を見つけました。 日付、ホールの動作の特徴(笑い声など)からファイルを削除し、小文字に変換して、すべてを
speeches.txt
という1つのファイルに結合しました
2番目の重要なポイントは、モデルを構築するためのフレームワークの選択です。 必要に応じて、たとえばPythonの場合、グラフィックカードで行列計算を実行するためのCudaMatライブラリがあります。 一般に、ニューラルネットワークパッセージはアクティベーション関数を使用した一連の行列乗算であるため、CudaMatに基づいてさまざまなアーキテクチャをすばやく実装できます。 しかし、私は車輪を再発明せず、例として、ディープラーニングシステム用の2つのフレームワークを取り上げます。
まず、これはおそらくLuaに基づく最も一般的で便利なTorchフレームワークです。 Luaはおそらく、グラフィックアクセラレータの強力なネイティブバックエンドと最新のJITコンパイラを備えた、最速のインタープリタ言語です。 Why-is-Lua-so-fast Luaは、Deep Mindで積極的に使用されています。GitHubにアクセスしてください 。
2つ目はDeepLearning4jです。これは、SkyMindによって積極的にサポートされている、ニューラルネットワークを構築し、JVMの世界のための分散学習を行うためのオープンフレームワークです。 フレームワークの利点には、視覚化の接続の容易さ、分散トレーニング(data-paralell)の存在、Java開発者にとっての安心感があります。 実際、私の目標は、2つのフレームワークの学習速度とアプローチを比較することでした。
また、NVIDIA GPUが搭載されていないラップトップMacBook Pro(2015)で次のすべてが実行された瞬間に注意したいので、すべてがCPUで実行されたため、モデルのサイズとプレゼンテーションの準備に費やす時間が制限されました。 CPUとGPUの違いは肉眼で見ることができます。
GPU
CPU
トーチ-rnn
最も単純で最速のものから始めましょう。 ここからシステムをインストールできますgithub.com/jcjohnson/torch-rnnただし、このシステムをそのままマシンにインストールすると、Mac所有者はtorch-hd5fの新しいバージョンと他の依存関係との非互換性の問題に直面します(DeepMindはこの問題を認識しています)。 この問題は克服されつつあり、このために私はあなたをここに送ります。 しかし、最良かつ最も簡単な方法は、ここから完成したDockerイメージを取得して、コンテナーを開始することです。
スピーチのケースを、speeches.txtという名前のトーチ/ torch-rnn / data /フォルダーにドロップします( ここにあります )。
次のコマンドでコンテナを起動します
docker run -v /Users/<YOUR_USER_NAME>/torch/torch-rnn/data:/data --rm -ti crisbal/torch-rnn:base bash
-vフラグとその後のパスは、ローカルファイルシステムからDockerコンテナー(ルートシステム/データ/)へのパスをマップすることを意味します。トレーニング中にモデルが中間結果を書き込むため、コンテナーが破棄された後にそれらを失いたくないためです。 そして、その後の打ち上げでは、トレーニングの継続と生成の両方に既製のモデルを使用できます。
残りのコマンドは、コンテナの起動とネイティブシステムでの起動の両方で同じです。
まず、データの前処理を行う必要があります。 スピーチケースのあるファイルをhd5f形式に変換します。 ファイルパスはコンテナバージョン用に記述されているため、ディレクトリに変更します。
python scripts/preprocess.py --input_txt /data/speeches.txt --output_h5 /data/speeches.h5 --output_json /data/speeches.json
トレーニングを開始
th train.lua -batch_size 3 -seq_length 50 -gpu -1 -input_h5 /data/speeches.h5 -input_json /data/speeches.json
GPUを搭載したシステムで実行する場合、デフォルトで-gpu -0フラグがオンになります。 アクセラレーターがないため、シーケンスサイズの制限を50文字に指定しました。 設定の数は非常に多いです。 RNNレイヤーサイズ128、2レイヤーを選択しました。そうしないと、トレーニングが非常に長い間引きずられる可能性があるためです。 特定の開始点が必要なため、デフォルトで元号とその他のパラメーターの数を残しました。
トレーニングのプロセスでは、モデルが時々ディスクにドロップされ、将来、これらのチェックポイントでトレーニングを続けることができます。 ドキュメントではこれについて詳しく説明しています。 また、必要に応じて、トレーニングプロセス中にモデルのサンプルを出力することもできます。つまり、ドナルド言語の構造を学習する際にモデルがどれだけ前進しているかを確認できます。 DeepLearning4jの例でモデルがどのようにトレーニングされるかを示します。
数時間後、トレーニングは終了し、新しいcvディレクトリがデータディレクトリに表示されます。モデルはトレーニングのさまざまな段階にあります。

モデルからシーケンスをサンプリングするために、導入します
th sample.lua -gpu -1 -sample 1 -verbose 1 -temperature 0.9 -checkpoint /data/cv/checkpoint_74900.t7 -length 2000
チェックポイントフラグは、モデルを取得する場所を示し、最後のレコードを設定します。 温度はSoftMax関数の非常に重要なパラメーターであり、シーケンスがどのように決定論的であるかを示します。 値が大きいほどノイズが多く確率的な出力になり、値が小さいと小さな変更で入力を繰り返すことができます。 有効な値は0〜1です。ただし、これはすべてこちらにも記載されています 。
モデルの結果を以下に示します。
DeepLearning4j
DeepLearning4jフレームワークは 、トーチほど人気がなく有名ですが、同時にいくつかの利点もあります。 ND4Jアレイに基づいているか、NumPy for Javaと呼ばれています。 これらはヒープ上にない配列であり、それらを使用してネイティブコールを実行します。 DeepLearning4jには優れた型システムもあり、直感的には、すべての基本アーキテクチャを実装できます。これは、理論を知ることから逃れることのできない唯一のことです。
ここにコードを投稿しました 。 コードはGravesLSTM Characterモデルに基づいており、私はAlex Blackの開発を使用しました。 モデルのトレーニングプロセスを表示するために、データの視覚化を接続しました。 トーチモデルに似たモデルパラメーターを選択しようとしました。 しかし、違いがあり、以下でプロセスで何が起こるかを見ていきます。
アンドレイ・カルパトニーによると、ニューラルネットワークの学習は科学というより芸術です。 トレーニングオプションは例外的な役割を果たします。 普遍的なルールはありませんが、推奨事項と直感だけがあります。 各パラメーターは、特定の問題セットに一致する必要があります。 スケールの初期初期化でさえ、モデルが収束するかどうかに影響します。 例として、Andrei は20層モデルをツイートしています。 weight init N(0,0.02):完全にスタックしています。 重み初期化N(0、0.05)を試してください:すぐに最適化します。 初期化が重要:\
異なる学習率パラメーターでトレーニングを開始しました。 そしてそれが起こったのです。
学習率0.1およびXAVIER初期化で最初に実行

ステップ3000のどこかでモデルがスタックし、損失関数が同じ値を中心に振動し始めたことがわかります。 考えられる理由の1つは、大きな学習パラメーターを使用すると、パラメーターが最適な値をスキップし、結果が振動になり、勾配がジャンプすることです。 原則として、これは驚くことではありません。学習パラメータ0.1は十分に大きいため、0.1から0.001の範囲、またはそれ以下でテストすることをお勧めします。 もっと始めました。
パラメーター0.01でシステムを開始しましたが、これが結果です。
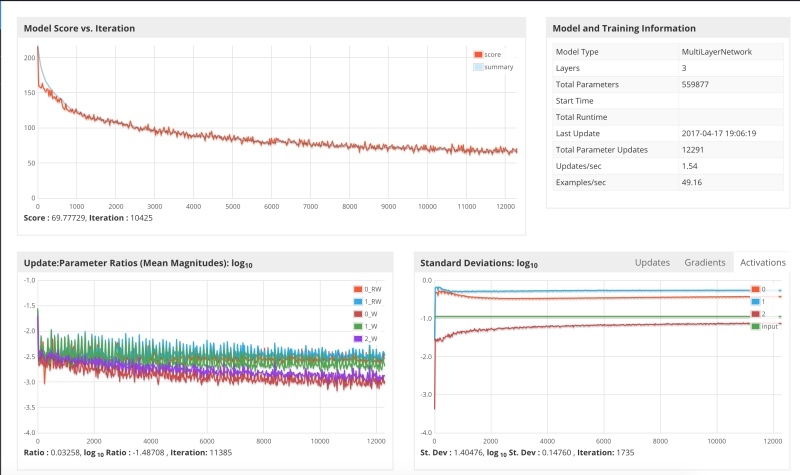
勾配降下は大幅に遅くなり、勾配は着実に減少していますが、多くのステップが必要であり、ラップトップのパワーを使い果たしていたため、トレーニングを停止しました。
3番目のシステムは、学習パラメーター0.05で開始します。
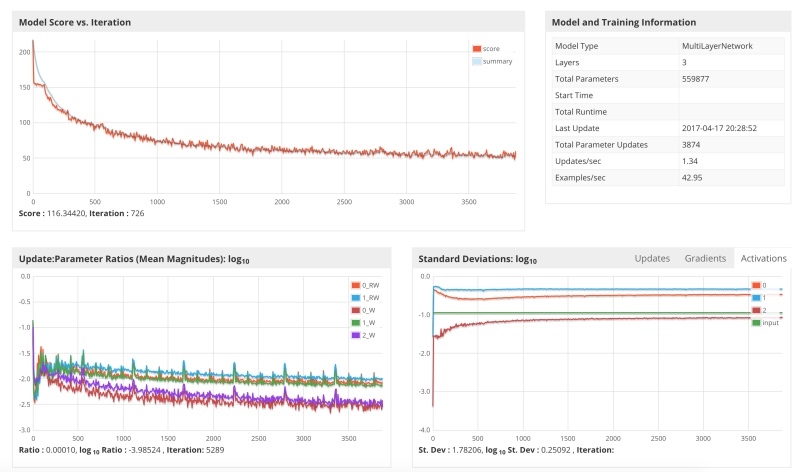
結果は、勾配はより速く下降したが、再び最後にはまり込んで振動し始めたことを示しています。これは、0.05の値が0.1を大きく下回っていないため、驚くことではありません。
最適なオプションは、プロセスでより低い学習パラメーターを設定することです。 これの鮮明な例は、LeNetアーキテクチャです。 原則は、大きなパラメーターから開始し、下降するにつれて減少することです。 ここにそのようなスケジュールでの打ち上げがあります。
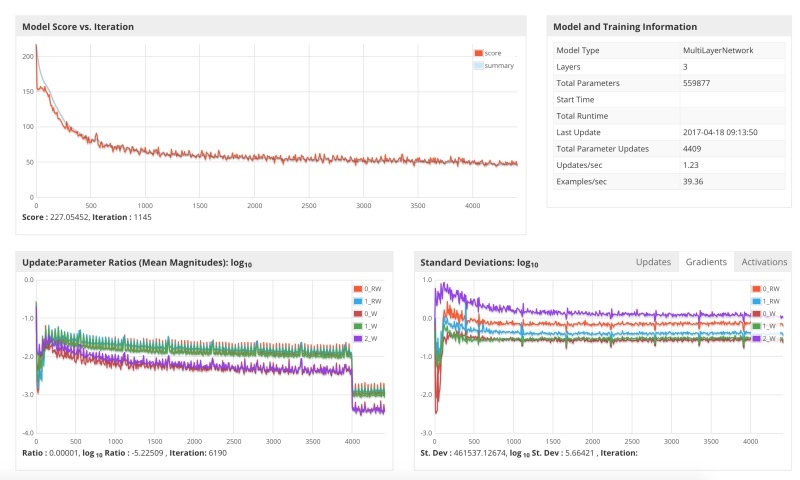
下のグラフは、ステップ4000で更新サイズがどのように減少し、同時に損失関数が障壁を突破し、さらに降下が始まるかを示しています。 仕事にはラップトップが必要だったので、トレーニングを終了しませんでした。この分析は、空き時間に数日で行いました。 さらに、正則化、モーメントなど、多くのトレーニングパラメーターがあります。 重大な作業の場合、これらのパラメーターを慎重に選択する必要があります。小さな変更は、モデルが収束するか、ローカルミニマムでスタックするかどうかに決定的な影響を与える可能性があるためです。
結果
そして今、最も面白くて最も面白い。 彼女がどのように勉強し、モデルが私たちに与えたもの。 DeepLearning4jログの例。
当初、再帰型ニューラルネットワークは言語やデータ構造について何も知らないため、スピーチのコーパスをフィードし始めます。 いくつかのミニバッチの後の結論です(ランダム播種によりモデルをサンプリングします)。
----- Sample 1 ----- Lfs mint alo she g tor, torink.han, aulb bollg rurr Atans ir'd ciI anlot, ade dos rhant eot taoscare werang he ca m hltayeu.,hare they Woy theaplir horet iul pe neaf it Yf therg. hhat anoy souk, thau do y RO Bury f if. haveyhaled Dhorlsy Ato thinanse rank fourile DaniOn Ttovele yhinl ans anu he B
モデルは、単語がスペースで区切られていることをすでに理解していることがわかります。 彼のような代名詞が現れます。
----- Sample 2 ----- aly Eo, He, to bakk st I stire I'micgobbsh brond thet we sthe mikadionee bans. Whether job lyok,. Whon not I ouuk. Wewer they sas I dait ond we polntryoiggsiof, waoe have ithale. I bale bockuyte seemer I dant you I Fout whey We kuow Soush Wharay nestibigiof, You knik is you know, boxw staretho bad
私たちのシャリコフはすでに彼の最初のアビバルグを言っていることがわかります。 モデルは、私、彼、私たち、あなたの代名詞を正しく把握し始めます。 いくつかの簡単な単語も存在します。
どうぞ
----- Sample 3 ----- cy doing to whit stoll. Ho just to deed to was very minioned, now, Fome is a soild say and is is soudd and If no want nonkouahvion. if you beeming thet take is our tough us iss could feor youlk to at Lend and we do toted to start to pasted to doind the we do it. I jind and I spongly stection Caread.
すでに英語のように見えます。
合計後
サイズ32x1000文字の340のミニバッチを完了した
----- Sample 4 ----- Second. They left you asses, believe me, but I will have great people.I solling us some -- and you see something youve seen deterner to Mexico, we are building interest. 100,000. Im not going to be so bad. It was so proud of me. Incredible and or their cities which I kept the same wealthy. They dont want them, were the world companies. Yes, they get the fraud, except people deals 100. Its like never respaved us. Thats what were going to do an orfone thats seen this.
どんな感じ? 私はそれほど悪くなるつもりはない。 私はとても誇りに思いました。 おなじみの自己陶酔的なイントネーション。
これはどうですか? 彼らはあなたのロバを去り、私を信じますが、私は偉大な人々を持っています。
それから、私たちがメキシコで見たものと私たちが建設している、どうやら壁が欲しかったのですが、興味がありました。
わずか340のミニバッチの後、モデルはそのような結果を非常に迅速に生成し始めたことに注意してください。 DeepLearning4jのトレーニングを終了しなかったため、Torch-RNNの例を使用してモデルの結果を見てみましょう。
So we're going to run. But I was going to have all the manufacturing things as you know what we're not going to be very soon to this country starting a president land the country. It's the committed to say the greatest state. You know, I like Iran is so badly. I said, "I'm not as you know what? Why aren't doing my sad by having any of the place so well, you look at 78%, I've done and they're coming in the Hispanics are so many. The different state and then I mean, it's not going to be these people that are politicians that they said, "You know, every poll said "We will bring it. I think we don't want to talk about the stupid new of this country. We love it of money. It's running the cary America great.
ネットワークが幻覚を始める様子を見ることができます。 サンプルのサイズは、さまざまなパラメーターを示すことで変更できますが、温度パラメーターの表示にも違いがあります。 以下は、低温の例です-0.15。
I want to take our country and they can be a great country and they want to do it. They want to take a look at the world is a lot of things are the worst thing that we have to do it. We have to do it. I mean, they want to tell you that we will be the world is a great country and they want to be a great country is going to be a great people. I mean, I want to be saying that we have to do it. They don't know what they don't want to say that we have to do it.
ネットワークが話し始めていることがわかります。 トランプ氏はかなり単純な言語を話すため、ネットワークで最も可能性の高い状態遷移は単純な構造になります。
このモデルの欠点は肉眼で見える。
- モデルのデータサイズは非常に小さいです。 考えられるすべてのスピーチとスピーチをまとめたわけではありませんが、すぐに組み立てるのに便利なものをまとめました。 これらのタイプのモデルでは、ニューラルネットワークは非常にデータを必要とするため、データサイズが最も重要な役割を果たします。
- モデルのサイズは小さく(レイヤーの数)、計算リソースが限られているため、小さなデモを行う必要がありました。 モデルを増やすことで、より興味深い結果を得ることができます。
この例はちょっとしたおもちゃですが、同時に、ニューラルネットワークのトレーニングの主要なポイントを示しています。 質問がある場合、またはこのトピックに興味がある場合は、将来情報を共有できます。 Twitterのコンテンツ- @ATavgen