
画像: www.nonotak.com
ディスクアレイ
多くの産業用ソフトウェアおよびハードウェアシステム(エンタープライズリソース管理システム、運用データ分析、デジタルコンテンツ管理など)では、コンピューターと外部データストレージデバイス間のアクティブなデータ交換が必要です。 このようなドライブ(ハードドライブ)の速度は、コンピューターのRAMの速度よりもはるかに低速です(通常、システム全体のパフォーマンスは、その "最も遅い"コンポーネントに依存します)。 この点で、外部デバイスに保存されているデータへのアクセス速度が向上するという問題が発生します。 したがって、データストレージサブシステム(SHD)は実際には広く使用されており、複数の独立したディスクを単一の論理デバイスに組み合わせています。
生産性を向上させるために、情報を並行して読み書きできる複数のディスクドライブがストレージシステムに含まれています。 現在、RAIDという一般名のテクノロジーファミリが積極的に使用されています。独立/安価なディスクの冗長アレイ-独立/安価なハードドライブの過剰なアレイです(Chen、Lee、Gibson、Katz、Patterson、1993)。
これらのテクノロジーは、ストレージシステムのパフォーマンスを向上させるタスクだけでなく、付随するタスク-データストレージの信頼性を向上させるタスクも解決します。結局のところ、システムの実行中に個々のディスクが故障する可能性があります。 情報の冗長性によって信頼性が確保されます。システムは特別に計算されたチェックサムが書き込まれる追加のディスクを使用し、1つ以上のストレージディスクに障害が発生した場合に情報を復元できます。
冗長ディスクを導入すると、信頼性の問題を解決できますが、ディスクからのデータの読み取り/書き込みごとにチェックサムの計算に関連する追加のアクションを実行する必要があります。 これらの計算のパフォーマンスは、一般的にストレージのパフォーマンスに大きな影響を及ぼします。 RAIDコンピューティングのパフォーマンスを向上させるために、実際に最も一般的なのはRAID-6テクノロジーです。これにより、 故障した2 台のドライブを復元できます 。
この記事では、RAIDテクノロジーファミリーの概要を提供し、Intel 64プラットフォームでのRAID-6アルゴリズムの実装の詳細について説明します。この情報は、オープンソース(Anvin、2009)、(Intel、2012)で入手できますが、圧縮された読み取り可能な形式で提供されます。 さらに、RAIDIXエラー修正コーディングライブラリと、類似の機能を実装する一般的なライブラリであるISA-l(Intel)、Jerasure(J. Plank)との比較結果を示します。
RAIDレベル
RAIDアレイの構築に使用される計算アルゴリズムは徐々に登場し、1993年に1993年にChen、Lee、Gibson、Katz、Pattersonによって最初に分類されました。
この分類によれば、RAID-0アレイは独立したディスクのアレイであり、情報を損失から保護するための対策は講じられていません。 単一のディスクと比較した場合のこのようなアレイの利点は、並列データ交換の編成により容量とパフォーマンスが大幅に向上する可能性があることです。
RAID-1テクノロジーには、システム内の各ディスクの複製が含まれます。 したがって、RAID-1アレイにはRAID-0に比べて2倍のディスク数がありますが、アレイ内の各ディスクにコピーがあるため、システムの1つのディスクに障害が発生してもデータの損失はありません。
RAID-2およびRAID-3テクノロジーは実際には広く使用されていないため、それらの説明は省略します。
RAID-4テクノロジーは、残りのデータストレージディスクの合計(XOR)が書き込まれる1つの追加ディスクの使用を意味します。
P= sumN−1i=0Di beginaligned qquadwhere\:N\:−\:number\:ドライブ\:with\:data、\:Di :−\:コンテンツ\:i\!−\!Go\:ドライブ endaligned qquad(1)
チェックサム(またはシンドローム )は、 データがストレージドライブに書き込まれるたびに更新されます 。 このため、(1)を再度計算する必要はありませんが、シンドロームに変数ディスクの古い値と新しい値の差を追加するだけで十分です。 ディスクの1つに障害が発生した場合、方程式(1)は、表示される未知の要素、つまり 失われたディスクのデータが復元されます。
明らかに、シンドロームの読み取りと書き込みの操作は、他のデータディスクの操作よりも頻繁に発生します。 このディスクは、アレイの最も忙しい要素になります。 パフォーマンスの面での弱点。 さらに、摩耗が早くなります。 この問題を解決するために、さまざまなシステムディスクの一部を使用してシンドロームを格納するRAID-5テクノロジーが提案されました(図1)。 したがって、読み取りおよび書き込み操作によるディスクのロードは調整されます。
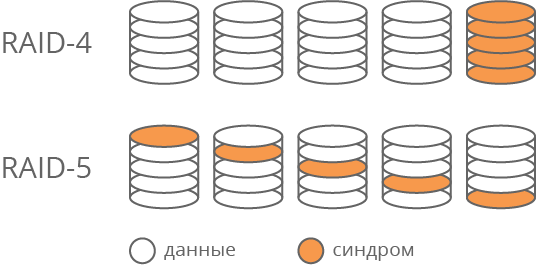
図 1. RAID-4とRAID-5の違い
RAID-1-RAID-5テクノロジーを使用すると、ドライブの1つに障害が発生した場合にデータを回復できますが、2台のドライブが失われた場合、これらのテクノロジーは無力です。 もちろん、2つのドライブが同時に故障する可能性は1つよりはるかに低くなります。 ただし、実際には、故障したディスクの交換には一定の時間が必要であり、その間データは「無防備」のままです。 システム管理者が1つのシフトで作業している場合、またはシステムがアクセスできない場所にある場合、この間隔は非常に長くなる可能性があります。
一方、人為的エラー(故障したディスクではなく正常なディスクを交換する)の可能性は、機械的なディスクの交換中に除外することはできません。これは2つのディスクを回復する問題に再び直面します。 これらの問題を解決するために、2つのディスクのリカバリに焦点を当てたRAID-6テクノロジーが提案されました。 このアルゴリズムをさらに詳しく検討してください。
RAID-6テクノロジー
RAID-6仕様に従ってストレージシステムを構築する際に使用される計算アルゴリズムは、(Anvin、2009)に記載されています。 ここでは、この調査の枠組みで使用するのに便利な形式でそれらを提示します。
システムのパフォーマンスを向上させるために、記録用に受信したデータは通常、データストレージシステムの内部キャッシュに蓄積され、内部キャッシュ戦略に従ってディスクに書き込まれます。これはシステム全体のパフォーマンスに大きく影響します。 この場合、書き込み操作は大きなデータブロックによって実行されます。これは将来ストライプと呼ばれます。
書き込みと同様に、ディスクからの物理的な読み取りを要求すると、要求されたデータだけでなく、このデータが置かれているストリップ全体(または複数のストライプ)も読み取られます。 その後、ストライプはシステムキャッシュに残り、それに関連する読み取り要求を待機します。
ストレージのパフォーマンスを向上させるために、ストライプはすべてのシステムディスクで並行して記録および読み取りされます。 これを行うために、同じサイズのブロックに分割されます。 D0、D1、...、DN−1 。 Nブロックの数は、アレイ内のデータディスクの数と同じです。 フォールトトレランスを確保するために、ディスクアレイに2つの追加のディスクが導入されます。PとQを指定します。ストリップには、アレイに対応するブロックを含めます D0、D1、...、DN−1 、ディスクPおよびQ(図2)。1つまたは2つのストレージディスクに障害が発生した場合、対応するブロックのデータはシンドロームを使用して復元されます。

図 2.ストライプ構造
RAID-6では、RAID-5テクノロジーのようにディスクの均一な負荷を維持するために、異なるストリップのシンドロームが異なる物理ディスクに配置されることに注意してください。 しかし、私たちの研究では、この事実は関係ありません。 将来的には、デフォルトで、すべてのシンドロームはストリップの最後のブロックに格納されると考えています。
シンドロームを計算するために、ブロックを個別の単語に分割し、同じ数字を持つすべての単語に対してチェックサム計算を繰り返します 。 各単語について、次の規則に従ってシンドロームを計算します。
\左\ {\ begin {aligned} P&= \ sum_ {i = 0} ^ {N-1} D_i \\ Q&= \ sum_ {i = 0} ^ {N-1} q_iD_i \ end {aligned } \右。 \ begin {aligned} \ qquadここで\:N \:-\:番号\:ドライブ\:\:システム、\\ D_i \:-\:ブロック\:データ、\:\:iボリュームに対応\:ディスク、\\ P、Q \:-\:シンドローム、\:q_i \:-\:いくつかの\:係数\ end {aligned} \ qquad(2)
次に、数値αおよびβのディスクが失われた場合、次の方程式系を構成できます。
$$表示$$ \左\ {\ begin {aligned}D_α+D_β&= P-\ sum {} D_i \\q_αD_α+q_βD_β&= Q-\ sum {} q_iD_i \ end {aligned} \右。 i≠α、β; α≠β$$表示$$
システムが任意のαとβに対して一意に解ける場合、ストリップで、失われた2つのブロックを復元できます。 次の表記法を紹介します。
$$表示$$ P_ {α、β} = \ sum_ {i = 0 \\ i≠α\\α≠β} ^ {N-1} D_i; \ bar {P} _ {α、β} = P-P_ {α、β} $$表示$$
$$表示$$ Q_ {α、β} = \ sum_ {i = 0 \\ i≠α\\α≠β} ^ {N-1} q_iD_i; \ bar {Q} _ {α、β} = Q-Q_ {α、β} $$表示$$
次に、次のものがあります。
$$表示$$ \左\ {\ begin {aligned}D_α+D_β&= \ bar {P} _ {α、β} \\q_αD_α+q_βD_β&= \ bar {Q} _ {α、β} \ end {aligned} \右。 \左右矢印\左\ {\ begin {aligned}D_α&= \ bar {P} _ {α、β}-D_β\\D_β&= \ frac {q_α\ bar {P} _ {α、β}-\ bar {Q} _ {α、β}} {q_α-q_β} \ end {aligned}、α≠β\右。 \ qquad(3)$$表示$$
(3)のユニークな可解性のために、すべてが qα そして qβ は異なるため、計算が行われる代数構造においてそれらの違いは可逆的でした。 そのような構造として有限体を選択した場合 Gf(2n) (ガロアフィールド)、フィールドのプリミティブ要素が正しく選択されている場合、これらの条件は両方とも一致します。
2つの故障したディスクの1つに1つのデータが含まれ、もう1つのディスクにシンドロームが含まれている場合、生き残ったシンドロームを使用して両方のディスクを復元できます。 このケースを詳細に検討することはしません-数学的根拠はここでも同様です。
実際には、アレイ内のディスクの数はそれほど多くないため(100を超えることはほとんどありません)、パフォーマンスを改善するために、あらゆる種類の必要な定数を事前に計算できます。 $インライン$(q_α-q_β)^ {-1}、q_α、$インライン$ 、後で計算で使用します。
このタスクの計算速度は、2つのディスクに障害が発生した場合だけでなく、すべてのディスクが動作している「通常」モードでもストレージの全体的なパフォーマンスを維持するために重要です。 これは、ストライプが物理的に異なるディスクにあるブロックに分割されているという事実によるものです。 ストライプを読み取るために、システムのすべてのディスクからのブロックの並列読み取りの操作全体が開始されます。 すべてのブロックが読み取られると、それらからストライプが収集され、ストライプの読み取り操作は完了したと見なされます。 この場合、ストリップの読み取り時間は、最後のブロックの読み取り時間によって決まります。
したがって、1つのディスクのパフォーマンスが低下すると、システム全体のパフォーマンスが低下します。 さらに、1つのディスクからの読み取り速度の低下は、ヘッド位置の不良、ディスク負荷の偶発的な増加、電子機器によって修正された内部ディスクエラーなどの要因によって引き起こされる可能性があります。 この問題を解決するために、システムの最も遅いディスクからの読み取り操作が完了するのを待たずに、式(3)を使用してそれらの値を計算することができます。 ただし、このような計算は、十分に迅速に実行できる場合にのみ、検討中の状況で役立ちます。
上記の説明では、故障したディスクの番号がわかっていることが重要です。 実際的な観点からは、これは、ハードウェア制御システムによってドライブが故障したという事実が検出されることを意味し、その数を設定する必要はありません。 「隠された」データ損失を検出するタスク、すなわち システムが実行可能と見なすディスク上のデータの歪み。この資料では考慮していません。
上記で使用された「乗算」という用語では、学校で慣れ親しんでいた数字の乗算とは異なる特別な意味を付けていることに注意してください。 古典的な理解はここでは適用されません、なぜなら 結果として次元nビットの2つの数値を乗算すると、次元2が得られます n ビット。 したがって、後続の乗算ごとに、チェックサム値のサイズが増加し、すべてのストライプブロックのサイズが同じである必要があります。
次に、実際の計算で使用される操作、その複雑さ、および最適化の方法を検討します。
有限体での算術演算
RAID-6テクノロジの複雑さを詳細に評価し、計算の複雑さを軽減するには、最終フィールドでの計算をより詳細に検討する必要があります。
視野に焦点を当てます Gf(2n) からなる 2n 要素。 (Lidl&Niederreiter、1988)に続いて、フィールドの要素を表します Gf(2n) 次数が2次係数以下の多項式として n−1 。 このような多項式をマシンワードビットの形式で記述すると便利です。 n 。 16進数システムでそれらを記述します。例:
$$表示$$ x ^ 7 + x ^ 5 + x ^ 2 + 1→10100101→A5 \\ x ^ 5 + x ^ 3 + 1→101001→29 $$表示$$
任意のnフィールドに対して Gf(2n) 次数の既約多項式を法とするGF(2)上の多項式環を因数分解することにより得られる n 。 このような多項式を生成と呼びます。 したがって、フィールドでの追加 Gf(2n) 多項式を追加する操作として実行でき、乗算は生成多項式を法とする多項式を乗算する操作として実行できます。 つまり 2つの多項式を乗算した結果は、生成多項式とこの除算の剰余で除算され、フィールドの2つの要素を乗算した最終結果になります Gf(2n) 。
既約多項式の広範なリストは(Seroussi、1998)にあります。 たとえば、体の生成多項式として Gf(28) 多項式171を選択できます。 (x8+x6+x5+x4+1) 。
加算操作 Gf(28) は、同じであり、生成多項式の選択に依存しません。これは、合計の次数が項の最大次数を超えることができないためです。 例:
A5+29=8C

生成多項式の次数が機械語の長さを超えない場合、ビット単位の排他的「or」の1つの機械コマンドに対してフィールド要素を追加する操作が実行されます。
乗算の演算は2段階で実行されます。フィールドの要素が多項式として乗算され、この積を生成多項式で除算した余りが求められます。 例:
A5×29=6A(mod171)

さらに、基本的な機械操作に関しては、因子の値に応じて、最大2(n-1)回の加算が必要です。 この「依存性」の中に、計算の生産性を高める実質的な準備があります。 たとえば、選択した場合
qi=xN−i−1 、次にフォームの合計の計算 sumqiDi Hornerのスキームに従って生成できます。
sumN−1i=0xN−i−1Di=(((D0x+D1)x+D2)x+...+DN−1)
すなわち、シンドロームPおよびQを計算するときの乗算の操作の要因として、多項式を修正できます x 。 多項式乗算 x シフト中に転送があった場合、1ビットを左にシフトし、結果をモジュールに追加する操作になります。 例:
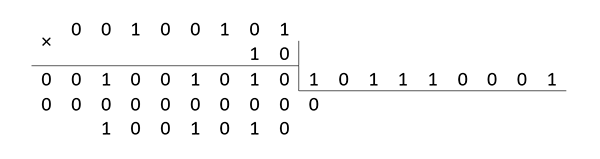
A5×2=3B(mod171)
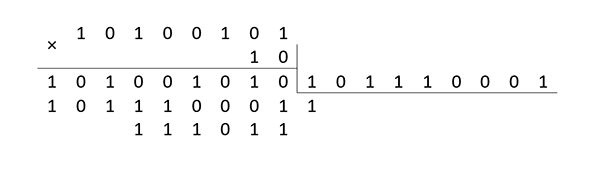
25×2=4A(mod171)
選択の対象 qi=xN−i−1 式(2)、(3)は、次の形式で書き換えることができます。
症候群の計算
\左\ {\ begin {aligned} P&= \ sum {} D_i = D_0 + D_1 + ... + D_ {N-1} \\ Q&= \ sum {} x ^ {Ni-1} D_i =(((D_0x + D_1)x + D_2)x + ... + D_ {N-1})\ end {aligned} \右。 \ qquad(2 ')
2つの失われたデータディスクの回復
$$表示$$ \左\ {\ begin {aligned}D_α&= \ bar {P} _ {α、β}-D_β\\D_β&= \ frac {\ bar {P} _ {α、β}- \ bar {Q} _ {α、β} x ^ {α-N+ 1}} {1-x ^ {α-β}} \ end {aligned}、α≠β\右。 \ qquad(3 ')$$表示$$
チェックサムを計算するときは、 x および追加。 また、データを回復するときに、これらの操作は、フィールドの要素である定数による乗算のいくつかの結果も追加しました。 次数の少ない多項式である2つの任意のフィールド要素を乗算する操作 n 、次のように書き換えることができます。
a(x)b(x)=(an−1xn−1+an−2xn−2+...+a1x+a0)(bn−1xn−1+bn−2xn−2+...+b1x+b0)=((((bn−1a(x)x+bn−1a(x))x+bn−3a(x))x+...+b1a(x))+b0a(x)
結果として、データを復元するときに、足し算と掛け算をすることができます。 x 。 これらの操作は最大速度で実行する必要があります。
コンピューティングのベクトル化
すべてのデータブロックとこれらのブロックのコードワードに対して同じアクションを実行するという事実により、SSE、AVX、AVX2、AVX512などのIntelプロセッサ拡張機能を使用したベクトル化計算に異なるアルゴリズムを使用できます。 このアプローチの本質は、プロセッサの特別なベクトルレジスタに複数のコードワードを一度にロードすることです。 たとえば、128ビットのベクトルレジスタサイズでSSEを使用する場合、16個のフィールド要素を1つのレジスタに配置できます。 Gf(28) 。 プロセッサがAVX512をサポートする場合、64要素。
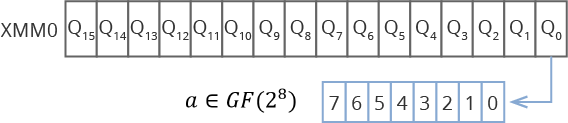
図 3.ベクトルレジスタ内のデータの場所
計算におけるベクトルレジスタ内のデータの場所に関するこの考え方は、ISA-L(Intel)およびJerasure(James Plank)ライブラリで使用されます。 これらのエラー防止コーディングライブラリは、幅広い機能と深刻な最適化により非常に人気があります。 これらのライブラリのフィールド要素の乗算では、SHUFFLEステートメントと事前に計算された補助的な「乗算テーブル」を使用します。 ライブラリのより詳細な説明は、 IntelおよびJerasureにあります。
ベクトル化の計算に関しては、開発者の主な「技術」はデータをレジスタに配置することです。 今のところ、コンパイラーに勝っているのはここです。
RAIDIXの主な利点の1つは、元のアプローチです。これにより、既にオーバークロックされている他のライブラリと比較して、データのエンコードおよびデコード速度を2倍以上向上させることができます。 このアプローチは、レイディックスでは「ビット単位の同時実行」と呼ばれます。 ちなみに、同社はアルゴリズムを計算して実装するための適切な方法の特許を持っています。
RAIDIXは、ベクトル化に対して異なるアプローチを採用しています。 このアプローチの本質は次のとおりです。ベクトルレジスタを精神的に垂直に配置します。 データブロックから、レジスタのサイズに等しい8つの値をカウントします。 SSEを使用すると、8 * 16バイト、AVX-8 * 32バイトが得られます。
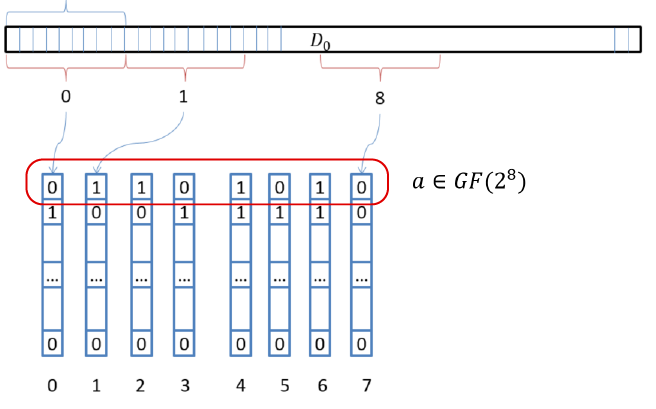
図 4.レジスタの垂直配置
この概念のフレームワークでは、1つのベクトルレジスタ内のビットと同じ数のフィールド要素をレジスタに配置しました。 乗算 x これらの8つのレジスタの3つのXOR演算と置換(再指定)により、すべての要素がすぐに実行されます。 つまり、わずか数個の単純な命令を使用して、128または256のフィールド要素にxをすぐに掛けることができます。
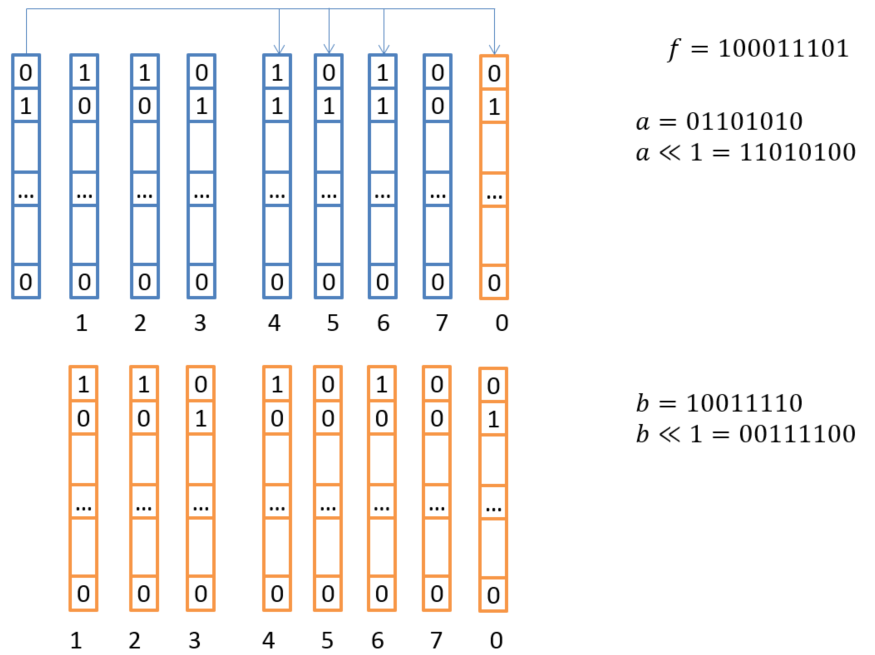
図 5. Xによるベクトル乗算のスキーム
この手順は、乗算ごとに繰り返されます。 x 定数で乗算するときに使用されます。 このアプローチにより、エンコードとデコードを最高速度で実行できます。
RAIDIXアルゴリズムを最も一般的なエラー修正コーディングライブラリISA-lおよびJerasureと比較しました。 比較は、ディスクからのデータの受信を考慮せずに、エンコードまたはデコードアルゴリズムの速度のみに関係していました。 次の構成のシステムで比較が行われました。
- OC:Debian 8
- CPU:Intel Core i7-2600 3.40GHz
- RAM:8GB
- GCC 4.8コンパイラー
図 図6は、プロセッサコアごとのRAID-6のデータのエンコードとデコードの速度の比較を示しています。 RAIDIXアルゴリズムは「rdx」として指定されています。 3つのチェックサム(RAID-7.3)を持つRAIDアルゴリズムについても同様の比較が行われます。
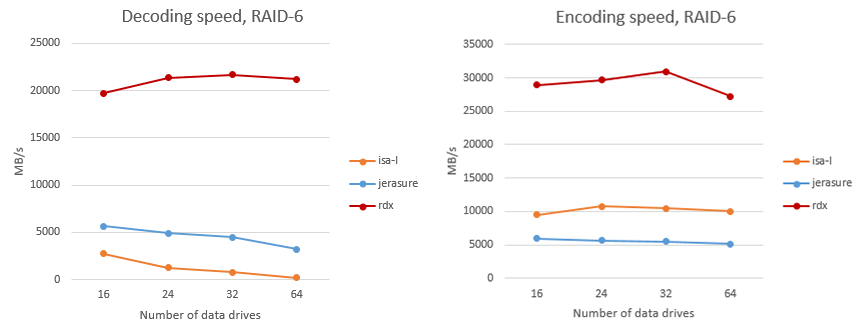
図 6. RAID 6でのコーディングとデコードの速度の比較

図 7. RAID 7.3でのコーディングとデコードの速度の比較
一部がAssemblerに実装されているISA-LやJerasureとは異なり、RAIDIXライブラリは完全にCで記述されているため、「Reyds」コードを新しいまたは「エキゾチック」なタイプのアーキテクチャに簡単に転送できます。
繰り返しますが、達成された数値は1つのコアに関連していることに注意してください。 ライブラリは完全に並列化されており、マルチコアおよびマルチソケットシステムでは速度がほぼ直線的に向上します。
このエンコードおよびデコード操作の実装により、RAIDシステムは、障害モードで1秒あたり数十ギガバイトのレベルで再構築および書き込み/読み取りパフォーマンスを提供できます。
したがって、ベクトル化中の基本データ型として、原則として__m128i(SSE)または__m256i(AVX)が使用されます。 アルゴリズムは単純なXOR操作のみを使用し、ベースタイプを__m512i(AVX512)に置き換えたため、Radixのエンジニアは、最新のIntel Xeon Phiマルチコアプロセッサでアルゴリズムを迅速に再構築、実行、およびテストできました。 一方、long long(64ビット、標準タイプC)を基本タイプとして使用する場合、ロシアのElbrusプロセッサーでReydsアルゴリズムが正常に実行されます。
文学
- アンビン、HP(2009年5月21日)。 RAID-6の数学。 2009年11月18日、Linuxカーネルアーカイブから取得: ftp.kernel.org/pub/linux/kernel/people/hpa/raid6.pdf
- チェン、PM、リー、EK、ギブソン、ジョージア、カッツ、RH、およびパターソン、DA(1993)。 RAID:高性能で信頼性の高いセカンダリストレージ。 テクニカルレポート番号 UCB / CSD-93-778。 バークレー:カリフォルニア大学EECS部門。
- Intel (1996-1999)。 Iometerユーザーガイド、バージョン2003.12.16。 Iometerプロジェクトから2012年に取得: iometer.svn.sourceforge.net/viewvc/iometer/trunk/IOmeter/Docs/Iometer.pdf?revision=HEAD
- Intel (2012)。 Intel 64およびIA-32アーキテクチャソフトウェア開発者マニュアル。 Vol 1、2a、2b、2c、3a、3b、3c。
- Seroussi、G.(1998)。 低重量のバイナリ既約多項式の表。 Hewlett Packardコンピューターシステム研究所、HPL-98-135。