
SDAccelは、Xilinx FPGA用のOpenCLプログラミングシステムです。 現在、VHDL / Verilogなどの従来のハードウェア記述言語でFPGAのプロジェクトを開発する問題は、ますます深刻になっています。 問題を解決する方法の1つは、C ++言語を使用することです。 OpenCLは、C ++言語を使用してFPGAファームウェアを開発するためのオプションの1つです。
相転移に関する小さな紹介
2000年にFPGAプログラミングをしなければなりませんでした。 当時、コンピューターはそれほど強力ではなく、FPGAは非常に小さかった。 アルテラのMAX7000 FPGAを使用しました。 ファームウェアの開発には、すばらしいMaxPlus IIシステムが使用されました。 主なツールはグラフィカルエディターでした。 VHDLとVerilogのサポートは既にありましたが、非常に脆弱でした。 VHDLの合成サブセットであるVerilogのみがサポートされていました。 しかし、時間遅延のsdfファイルを使用して、完成したFPGAのVHDLモデルを取得することはできました。 また、コンピュータの電力とFPGAの容量の比率により、FPGAプロジェクト全体を時間遅延でシミュレートできました。 今、私たちはそれについてのみ夢を見ることができます。 この頃、FPGAプロジェクトの開発でフェーズ移行が始まりました。 これは、回路入力からVHDL / Verilogを使用して個々のノードとプロジェクト全体をモデル化する移行でした。 弊社では、アルテラおよびMaxPlus IIからザイリンクスおよびISEへの移行と同時に発生しました。 2004年にこの移行を完了しました。
現時点では、第2段階の移行があります。 FPGAプロジェクト開発のVHDL / VerilogからC ++言語への移行に関連しています。 実際、コンピューターの電力とFPGAの容量の最新の比率では、VHDL / VerilogでFPGAプロジェクトのシミュレーションセッションを実行することはほとんど不可能です。 シミュレーションセッションは、数時間から数日間続くことがあります。 そのような時間は、プロジェクトの最終検証には許可されますが、開発には許可されません。
OpenCLとは何ですか?
OpenCLシステムは、2008年にAppleによって提案されました。 将来、Khronos Group協会が組織されました。これには、INTEL、NVIDIA、AMD、ARM、GOOGLE、SONY、SAMSUNGなどの主要企業が含まれます。 OpenCLに加えて、他のシステム、たとえばOpenXR(仮想現実システム)が開発されています。
OpenCLは、次のような異種システム向けのC ++ベースの設計システムです。
- 従来のプロセッサ
- マルチプロセッサクラスタ
- グラフィックスプロセッサ
- FPGA
OpenCLは、システムモデル、C ++言語拡張、ホストコンピューターの機能のライブラリを定義します。
長いシミュレーション時間は、クロックレベルでのシミュレーションに関連しています。 C言語を使用すると、プロジェクトの説明からクロック信号が削除されます。 データ操作のみがプロジェクトに残ります。 これにより、モデリングと開発の速度を数桁向上させることができます。
最初の注目すべきCプログラミングシステムの1つは、Mentor Graphics Catapultシステムです。 このシステムは2004年に登場し、アルテラFPGAを使用してBing検索サーバーを実装するために、とりわけMicrosoftによって使用されています。
2013年頃、ザイリンクスはVivado HLSをリリースしました。これにより、C ++で個々のコンポーネントを開発し、その後それらをメインプロジェクトに含めることができます。 Vivado HLSに基づいて、さらにいくつかの製品が作成されました。
- SDSoc-個々の機能の加速。 システムはZynqのみを対象としています(これは、FPGAとAWPプロセッサが1つのケースにあるマイクロ回路です)。 システムはすでに利用可能です。
- SDAccelはOpenCLプログラミングシステムです。 システムは利用可能ですが、全員が利用できるわけではありません。
- SDNetは、ネットワークアプリケーション設計システムです。 それはまだ利用可能ではなく、それについて話すには時期尚早です。
SDSocとSDAccelの特徴は、FPGAプロジェクトがすでにバックグラウンドにフェードインしていることです。 フォアグラウンドのアルゴリズム。 どちらのシステムでも、C / C ++で記述された元のアルゴリズムのレベルでモデリングを実行し、それをFPGAに転送できます。 これにより、アルゴリズムの複雑さを劇的に高めることができます。 そして、これら両方のシステムが画像処理に導入されているのは偶然ではありません。
VHDL / VerilogとC / C ++のFPGAのプログラミングを比較すると、C / C ++とアセンブラーの従来のプロセッサのプログラミングの類似性が示唆されます。 はい、アセンブラーでは、よりコンパクトで高速なコードを作成できます。 しかし、C / C ++では、より複雑なプログラムを作成できます。
電卓モデル
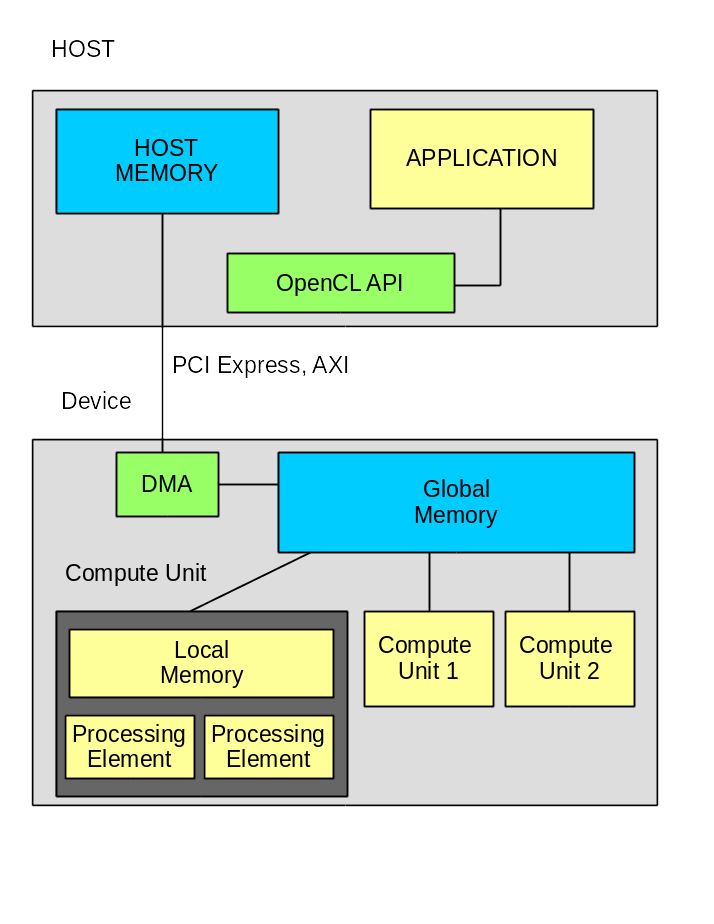
このシステムは、ホストコンピューターとコンピューターで構成され、バスを介して相互接続されています。 ほとんどの場合、PCI Expressバスです。 ただし、アルテラは、統合されたAWPプロセッサを備えたFPGA向けのソリューションをすでに提供しています。 この場合、AXIバスが使用されます。 噂によると、Intel(アルテラを買収した)は、FPGAを統合したXeonプロセッサを開発しています。 そこにある主な設計システムはOpenCLであり、QPIはプロセッサとFPGA間の相互作用に使用されます。
計算機の内部には、1つ以上の「計算ユニット」ユニットがあり、各ユニットは1つ以上の「処理要素」で構成されています。 このレベルでは、GPUとFPGAの間に根本的な違いがあります。 GPUで「処理要素」の数が決定される場合(モデルによって異なりますが)、FPGAではこれはタスクによって異なります。
標準では、いくつかのメモリクラスが定義されています。
- ホストメモリ-ホストコンピューター上のアプリケーションで利用可能なメモリ。 これは通常、コンピューターのランダムアクセスメモリです。
- グローバルメモリ-ホストおよび計算機で使用可能なメモリ。 通常、これはFPGAまたはGPUに接続された動的メモリです。
- グローバルコンスタントメモリ-HOSTの読み取り/書き込みメモリおよび計算機の読み取り専用メモリ。
- ローカルメモリ-1つのコンピューティングユニット内でのみ使用可能なメモリ
- プライベートメモリ-1つの処理要素内でのみ使用可能なメモリ
さらに、ザイリンクスは、すべての「コンピューティングユニット」で使用可能なメモリである「グローバルオンチップメモリ」を導入しています。
簡略化された作業アルゴリズム:
- HOSTはデバイスを初期化します
- HOSTはプログラムを計算機にロードします
- ホストはホストメモリにデータを準備します
- HOSTは、ホストメモリからグローバルメモリにデータを転送するためのDMAチャネルを起動し、DMAの完了を待ちます
- HOSTは計算機を起動し、計算が完了するのを待ちます。
- HOSTは、DMAチャネルを起動して、結果をグローバルメモリからホストメモリに転送し、DMAが完了するのを待ちます。
- HOSTは計算の結果を使用します。
以下に注意することが重要です-ホストと計算機間のすべての通信はグローバルメモリを経由します。 より複雑なアルゴリズムでは、計算と並行して次のサイクルのデータを転送できます。
カーネルとは何ですか?
カーネルはOpenCLの基本概念です。 実際、これは単一の「Processing Element」で実行される関数です。 1つのCompute Unit内で複数のカーネルを実行できます。 これは、GPUの並列動作を保証する主な方法です。
関数定義の例:
__kernel void krnl_vadd( __global int* a, __global int* b, __global int* c, const int length);
通常の説明とは異なり、新しいキーワードがここに表示され、それらはOpenCL標準で定義されたものです。
- __kernel-電卓で実行される関数を定義します。
- __global-データがグローバルメモリにあることを決定します。
SDAccelは、カーネルを実装する3つの方法を提供します。
- OpenCL標準
- C ++-これはVivado HLSのすべての機能を使用します
- VHDL / Verilog-すべてのFPGA機能が使用されます
GPUとFPGAの実装の主な違い
2つのベクトルの単純な加算関数を例として使用すると、GPUとFPGAのコードの効果的な実装の主な違いを追跡するのに非常に便利です。
GPUの追加機能は次のようになります。
__kernel void krnl_vadd( __global int* a, __global int* b, __global int* c, const int length) { int idx = get_global_id(0); c[idx] = a[idx] + b[idx]; return; }
そして、このようなFPGAの場合:
__kernel void __attribute__ ((reqd_work_group_size(1, 1, 1))) krnl_vadd( __global int* a, __global int* b, __global int* c, const int length) { for(int i = 0; i < length; i++){ c[i] = a[i] + b[i]; } return; }
GPUのバージョンは長さパラメーターを使用しないことに注意してください。 ベクトルの各要素に対して、カーネルの独自のインスタンスが実行されると想定されています。 各インスタンスはidx番号を受け取り、追加を実行します。 同時に起動されるインスタンスの数は、このGPUの機能によって決まります。 ベクトルが大きすぎる場合、いくつかの開始点があります。 FPGAの場合、これも実行できますが、あまり効果的ではありません。 最良の結果は、1つの計算ユニットと1つの処理エレネットのみが使用されるオプションによって提供されます。 注意してください-関数宣言の前に、reqd_work_group_size(1、1、1)属性が追加され、関数自体の中にループがあります。 属性値1,1,1は、1つのカーネルのみが使用されることを意味します。 そして、この知識はコンピューティング構造を最適化するために使用されます。 サイクル自体は、追加の属性を使用して、並列コンピューティング構造に拡張できます。 長さが一定の場合、最良の結果が得られます。
SDAccel
バージョン2016.3以降、SDAccelとSDSocはSDxと呼ばれる1つのパッケージにマージされます。 SDSocは、WindowsおよびLinuxで実行されます。 SDAccelは、特定のLinuxバージョン、特にCentOs 6.8でのみ動作します。 そのような制限についての合理的な説明はありません。将来、SDAccelがWindowsでも動作することを願っています。 SDxパッケージはEclipseに基づいています。 プロジェクトタイプ「Xilinx SDx」が追加されます。 プロジェクトを作成するときは、プラットフォームを選択する必要があります。 これまでのところ、選択はわずかです。 図は、プラットフォーム選択ウィンドウのビューを示しています。

プラットフォームがモジュールと基本的なFPGAファームウェアを決定します。 SDAccelはパーシャルリコンフィギュレーションテクノロジーを使用します。 FPGAにロードされる基本ファームウェアと、SDAccelプロジェクトの形成に基づいた基本ファームウェアとの間の対応が必要です。 この対応は、プラットフォームの名前とバージョンによってサポートされています。 一番上の行はFMC126Pモジュールであることに注意してください。 私は彼のためにプラットフォームを作成しようとしていますが、これまでのところ失敗しています。
もう1つの重要なスクリーンショットは、プロジェクトのプロパティです。
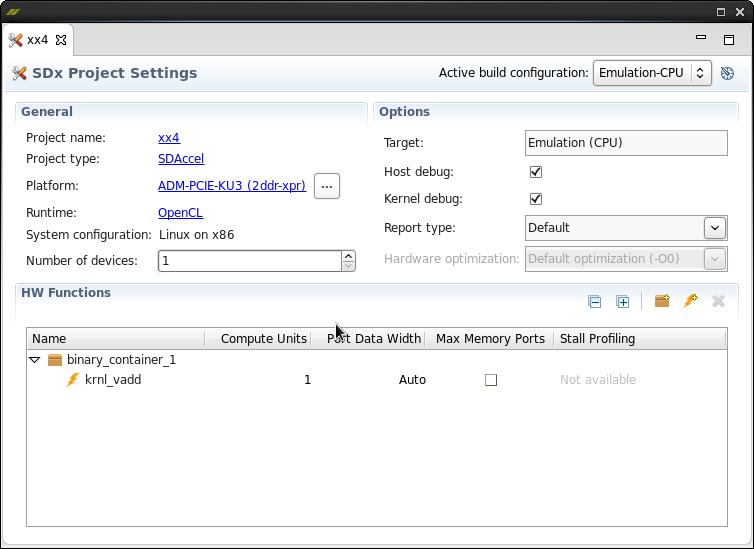
[ハードウェア機能]フィールドに注意してください。
- binary_container_1はFPGAにロードされるものです。
- kernel-vaddは関数の名前です
- Comput Units列は、基本的に並列機能実装の数です
- 列「最大メモリポート」-グローバルメモリにアクセスする際の追加最適化の許可
非常に重要なのは、右上のフィールド「アクティブなビルド構成」です。 実際のところ、このシステムの本質はすべてここにあります。 次の3つのオプションが可能です。
- エミュレーションCPU-プロセッサ上のOpenCL実装
- Emulation-HW-VivadoシミュレーターでのOpenCL実装
- システム-選択したハードウェアプラットフォームでのOpenCL実装
コンパイル結果は、拡張子が.exeの方法で実行可能ファイルになり、拡張子が.xclbinのファイルになります。 これは、カーネル関数が実装されたbinary_containerです。
実行の3つのバリアントでは、異なるOpenCLランタイムが形成されます。 エミュレーションCPUオプションは、実行が最も高速です。 コンパイルと起動は非常に高速です。 このモードでは、アルゴリズムを確認する必要があります。
Emulation-HWオプションは、コンパイルと実行のためにより長くなっています。 このモードでは、Vivado HLSが呼び出され、VHDL / Verilog / SystemCのコードが合成され、カーネルを実行するためにVivadoシミュレーターが起動されます。 コンパイル結果に基づいて、使用されているリソースを判別し、実行の遅延を評価できます。 既にクロック周波数があり、これに関連するすべての問題が発生するため、シミュレーションは長くなる可能性があります。 確かにPCI ExpressとSODIMMは単純化されたモデルを使用しているため、シミュレーションの速度が向上します。
システムオプションは機能しています。 コンパイルにはFPGAトレースが含まれますが、これはかなり長いプロセスです。 ADM-PCIE-KU3の小さなプロジェクトは、約1時間で繁殖します。 開始するには、プラットフォームに付属のデバイスドライバーをインストールする必要があります。 起動すると、partial Reconfigurationテクノロジを使用してbinary_containerがFPGAにロードされます。 ダウンロード自体も高速ではありません。約1分です。 説明できない理由は何ですか。
HOSTのプログラム
OpenCL標準はAPIを定義しています。 Khronos GroupのWebサイトでは、すべての機能について詳しく説明されています。 しかし、これはすべて悲観的に見えます。 ただし、ここでのザイリンクスは私たちの生活を簡素化しました。 vector_additionの例には、xcl.hおよびxcl.cppファイルが含まれています。これらのファイルには、単一のデバイスを操作するために最も必要な機能が記述されています。 ここにあります:
- xcl_world_single()、xcl_world_release()-デバイスでの作業の初期化と完了
- xcl_malloc()-デバイスのグローバルメモリ内のバッファの割り当て
- xcl_import_binary()-binary_containerのロード
- xcl_set_kernel_arg()-カーネル関数の引数の設定
- xcl_memcpy_to_device()-デバイスへのデータ転送
- xcl_memcpy_from_devce()-デバイスからデータを転送します
- xcl_run_kernel3d()-実行のために関数を開始
もちろん、複数のHOSTプログラムが存在する場合があります。 別のプロジェクトを作成し、Google Testなどの単体テストシステムを接続して、FPGAの機能の実装を確認することは非常に可能です。
FPGAの中身は何ですか?
コンポーネントカタログには、このような素晴らしい要素「SDAccel OpenCL Programmable Region」があります。

ここにbinary_containerがロードされます。 この要素の結合数は非常に少ないことがわかります。 制御用のS_AXIバス、グローバルメモリへのアクセス用のM_AXIバス、クロックおよびリセット信号があります。 FPGAにはDMAノード、ダイナミックメモリコントローラー、中央のaxi_interconnectノードがあると想定されています。
SDAccelブロックは展開でき、内部は次のようになります。

あまりよくありませんが、axi_interconnectブロックが2つあり、それらの間に4つのカーネルブロックがあることがわかります。 このような構造は、各ブロックが独自のAXIバスを必要とするため、大量のカーネルを使用しないことを推奨することを意味します。 16本以上のタイヤを使用することは推奨されません。
潜在的な利点と実際の欠点
このシステムの主な利点は、大きなデータ配列を操作するための複雑なアルゴリズムを実装できることです。 もちろん、「複雑なアルゴリズム」と「大きな配列」の概念は条件付きです。 私の主観的な意見では、システムのアプリケーションは、検証に1 MB以上のテストデータを必要とするアルゴリズムに効果的です。 まず第一に、これらはもちろん画像処理アルゴリズムです。
別の潜在的な利点は、他の機器に切り替える機能です。 たとえば、FPGA XilinxからFPGA Alteraへ。
主な欠点:
- これは新しいシステムであり、説明できないバグがまだ存在することは確かです
- 限られた数のLinuxオプションでのみ動作します。 Windowsの場合-動作しません。
- C ++からVHDL / Verilogへの変換の効率が問題になっています。 VHDL / Verilogにカーネルを実装することは可能ですが。
最初の知り合いがいました
SDAccelをさらに研究して、次のことを計画します。
- 記憶の処理、作業速度の測定の効果的な方法の研究
- FMC126Pモジュール用のプラットフォームの開発
- Alexander Kapitanov( capitanov )によるFPFFTKライブラリに基づく畳み込みノードの実装
PSところで、OpenCLは
<stdio.h>
サポートしていませんが、printfはあります。 特に、printfはFPGAに実装されている場合にも機能します。