今日、PostgreSQLで最近採用されたいくつかのパッチ(およびpg_filedumpユーティリティ)について再度お話ししたいと思います。 Habréで以前に公開された同様の記事には多くのプラスがあり、それは誰かに興味があると思わせます。 前の記事をスキップした場合、それらは-one 、 two 、 threeです。 レビューしたパッチは私が作成したものですが、テストしてレビューした人々の貢献を忘れないでください。 これらの人々によって行われた仕事は、著者自身の仕事よりもしばしば困難です。 Fedor Sigayev、Robert Haas、Tom Lane、Dmitry Ivanov、Grigory Smolkin、Andres Freund、Anastasia Lubennikova、およびTelsは、調査されたパッチの開発に特に積極的に参加しました。
11. pg_filedump:エラーが発生した場合にゼロ以外のリターンコードを返します
pg_filedumpユーティリティは 、テーブルセグメントをデコードし、ページヘッダーとタプルに関する情報を表示するように設計されていることを思い出させてください。 ページのチェックサムがコンテンツと一致しない場合、pg_filedumpは警告を表示しますが、nullのリターンコードを返すことに注意してください。 特にユーティリティがシェルスクリプトで使用される場合、これは完全に正しいとは限りません。
パッチはこの状況を修正します。 pg_filedumpは、エラーが検出された場合、チェックサムとその他の両方でゼロ以外のコードを返します。
+/* Program exit code */ +static int exitCode = 0; + /*** * Function Prototypes */ @@ -191,6 +194,7 @@ ConsumeOptions(int numOptions, char **options) { rc = OPT_RC_INVALID; printf("Error: Missing range start identifier.\n"); + exitCode = 1; break; } @@ -205,6 +209,7 @@ ConsumeOptions(int numOptions, char **options) rc = OPT_RC_INVALID; printf("Error: Invalid range start identifier <%s>.\n", optionString); + exitCode = 1; break; } (... ...) @@ -1746,5 +1823,5 @@ main(int argv, char **argc) if (buffer) free(buffer); - exit(0); + exit(exitCode); }
パッチ: 1c9dd6b728810ea7d2f196e6e15064017e4b9eef
12.タイムスタンプタイプの内部ドキュメントの改善
タイムスタンプタイプのドキュメントは次のとおりです。
When <type>timestamp</> values are stored as eight-byte integers (currently the default), microsecond precision is available over the full range of values. When <type>timestamp</> values are stored as double precision floating-point numbers instead (a deprecated compile-time option), the effective limit of precision might be less than 6. <type>timestamp</type> values are stored as seconds before or after midnight 2000-01-01. [...]
次のセクションで説明するパッチの作業中に、提供されたテキストが誤った表現を作成することがわかりました。 実際、デフォルトでは、タイムスタンプは時間をマイクロ秒単位で保存します。 ユーザーが浮動小数点数の形式で古い表現を選択した場合、実際には時間は秒単位で保存されます。
ニュースレターでの短い議論の後、誤解を招く文書が書き直されました。
パッチ: 44f7afba79348883da110642d230a13003b75f62
13. pg_filedump:部分的なデータ復旧
このパッチについては、新しいメガ機能であるpg_filedumpを使用してPostgreSQLテーブルを復元するノートで説明されているため、ここでは詳しく説明しません。 TL; DRバージョン-pg_filedumpを使用して、PostgreSQLインスタンスが起動しない場合でも、テーブルのデータの少なくとも一部を復元できます。
パッチ: 52fa0201f97808d518c64bcb9696f2a350678aa5
14. pg_filedump:カタログテーブルのデコード
前のパッチと同様に、ホテルの記事全体がこれに専念しましたpg_filedumpのもう1つの新機能:PostgreSQLディレクトリの復元 。 TL;まだ読んでいない人のためのDRバージョン-pg_filedumpがカタログテーブルで使用される一部のタイプをサポートしていなかった前。 このパッチを適用すると、カタログテーブルをデコードできるようになり、データベーススキーマがわからない場合は復元できるようになりました。
パッチ: 5c5ba458fa154183d11d43218adf1504873728fd
15a。 パーティションアクセラレーション:find_tabstat_entry()/ get_tabstat_entry()でのBattleNekの修正
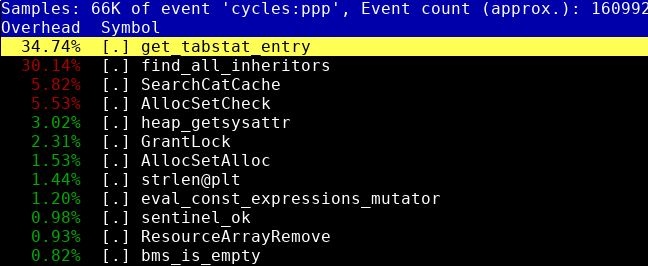
執筆時点でこれらの行が開発されており、機能がフリーズしているPostgreSQL 10では、 宣言的にテーブルをパーティション分割する機能が追加されました。 つまり、ハッシュまたは範囲によってテーブルを複数の物理テーブルに分割できるようになりました。 これは、以前はテーブル継承を使用して可能でしたが、利便性が低く、一般的に汚いハックのように見えました。 宣言的パーティション分割の使用例は、 こことここにあります 。
さて、私は考えましたが、さらに(たとえば10,000個の)パーティションを作成し、どこで速度が低下するかを確認します。 C / C ++コードプロファイリングのトピックは、 DTrace 、 SystemTap 、およびHeapTrackに関する記事を数える場合、以前は記事全体をいくつか取り上げました 。 さらに、このテーマについて、 YouTubeにあるビデオのHighLoad ++ 2016に関するレポートを作成 しました 。 したがって、ここではプロセスの説明については触れません。 パフォーマンストップは、この記事の冒頭のイラストで見ることができる2つの明示的なバトルを示したとしか言えません。
そのため、パッチはこれらの最初の戦艦を修正します。 テーブルの統計では、リスト上に構築された小さなメモリアロケータが使用されることが判明しました。 テーブルに対応するPgStat_TableStatus構造テーブル識別子の検索は、このリストをスキャンすることで実行されましたが、10,000個のテーブルがある場合はうまく機能しません 。
パッチ: 090010f2ec9b1f9ac1124dc628b89586f911b641
15b。 パーティションアクセラレーション:find_all_inheritors()のBattleNekの修正
同様の問題が、特定のテーブルのすべての相続人に対する再帰的検索手順に存在していました。 PostgreSQLが複数のテーブル継承をサポートしていることを知っている人はほとんどいません。 そのため、子テーブルをクロールする場合、以前にアクセスしたテーブルのリストを調べます。 次のテーブルがリストにない場合、追加されます。 既に存在する場合、テーブルは親のカウンターを増やします。 結果として、すべての子テーブルのリストとその親の数がプロシージャから返されます。
ご想像のとおり、リストの検索を高速化するためにハッシュテーブルを追加することにより、戦艦は再び排除されました。 私のベンチマークによると、合計で2つのパッチが宣言型パーティション分割を64%加速しました。 興味深いのは、パッチが多数のパーティションを使用するだけでなく、数個のパーティションを使用する場合にパッチを高速化することです。 もちろん後者の場合、効果はそれほど顕著ではありません。
パッチ: 827d6f977940952ebef4bd21fb0f97be4e20c0c4
おわりに
前述のように、これらすべての記事の目的は、RDBMS、特にPostgreSQLの開発において、プロセスへの関心が非常に高いにもかかわらず、魔法的または直接理解できないほど複雑なものはないことを示すことです。 このシリーズの記事が、趣味として、または専門的にPostgreSQLの開発に参加するように2、3人の人々を動機づけることができることが望まれます。
特に、私が現在働いているPostgres Professionalという会社は 、プログラマーだけでなく、たとえばQAやDBAも永久に雇っています。 すでに述べたように、私たちのビジネスにおける品質テストとコードレビューは、コードを書くよりも重要な場合がよくあります。