私は最も重要なことを言うのを忘れていました。これはここで書く私の試みであると言えます。 それでは行きましょう。
永遠の質問について:なぜですか?
Androidのプログラミングを専門とする書籍や記事では、データベースアーキテクチャを設計するためのツールや、データベースの作成段階でデータベースを操作するためのパターンが記載されていないのは、正直なところわかりません。 数ページだけを本に追加したり、別の記事を書いたりするのは簡単なように思えます(今のように)。 この記事では、作業で使用するツールについて簡単に説明し、データベースの初期作成を担当するコードについて詳しく説明します。これは、私の観点からは読みやすく便利です。
アプリケーションに5つ以上のテーブルがある場合、データベースアーキテクチャの視覚的な設計に何らかのツールを使用することは悪くありません。 これは私にとって趣味なので、Oracle SQL Developer Data Modelerと呼ばれる完全に無料のツールを使用します( こちらからダウンロードできます)。

このプログラムを使用すると、テーブルを視覚的に描画し、テーブルとの関係を構築できます。 この設計アプローチを使用すると、多くのデータベースアーキテクチャ設計エラーを回避できます(これは、プロのデータベースプログラマとして既にお伝えしています)。 次のようになります。
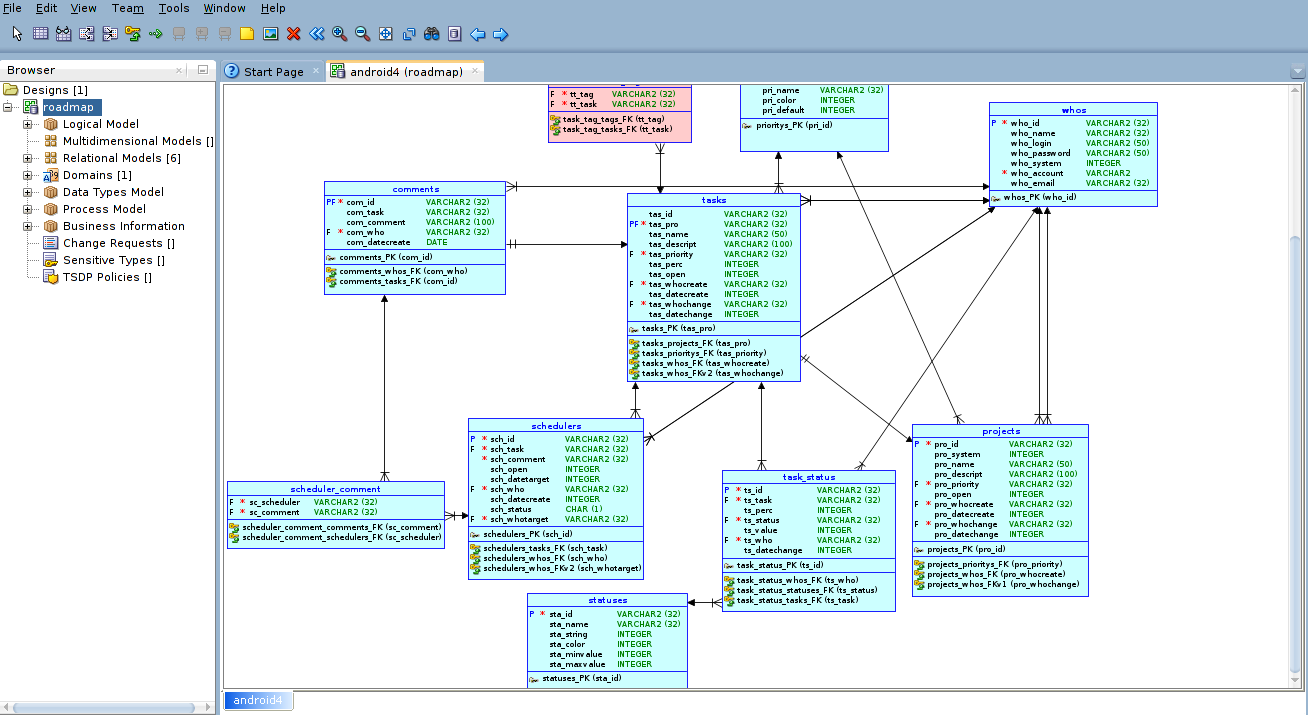
アーキテクチャ自体を設計したら、テーブルを作成するためのsqlコードを作成するという面倒な部分に進みます。 この問題を解決するために、私は既にSQLiteStudioというツールを使用しています(このツールはこちらからダウンロードできます )。
このツールは、SQL Naviagator、Toadなどのよく知られた製品に類似しています。 しかし、その名前が示すように、SQLiteを操作するために投獄されます。 データベースを視覚的に作成し、作成されたテーブルのDDLコードを取得できます。 ところで、必要に応じてアプリケーションで使用できるビューを作成することもできます。 Androidプログラムでビューを使用するための正しいアプローチがどのようになっているのかはわかりませんが、アプリケーションの1つで使用しました。

実際、サードパーティ製のツールはもう使用していません。そしてAndroid Studioから魔法が始まります。 上記で書いたように、JavaコードにSQLコードを埋め込み始めると、出力は読みにくくなり、そのためコードの拡張性が低下します。 したがって、すべてのSQLステートメントを、 assetsディレクトリにある外部ファイルに配置しました。 Android Studioでは、次のようになります。

dbおよびデータディレクトリについて
アセットディレクトリ内に、 db_01とdata_01の 2つのディレクトリを作成しました 。 ディレクトリ名の番号は、使用しているデータベースのバージョン番号に対応しています。 dbディレクトリに、テーブル自体を作成するためのSQLスクリプトを保存します。 また、 データディレクトリには、テーブルの初期入力に必要なデータが保存されます。
次に、プロジェクトで使用するDBHelper内のコードを見てみましょう。 まず、クラス変数とコンストラクター(ここでは、驚くことはありません):
private static final String TAG = "RoadMap4.DBHelper"; String mDb = "db_"; String mData = "data_"; Context mContext; int mVersion; public DBHelper(Context context, String name, int version) { super(context, name, null, version); mContext = context; mVersion = version; }
これでonCreateメソッドが表示され 、ここでさらに興味深いものになります。
@Override public void onCreate(SQLiteDatabase db) { ArrayList<String> tables = getSQLTables(); for (String table: tables){ db.execSQL(table); } ArrayList<HashMap<String, ContentValues>> dataSQL = getSQLDatas(); for (HashMap<String, ContentValues> hm: dataSQL){ for (String table: hm.keySet()){ Log.d(TAG, "insert into " + table + " " + hm.get(table)); long rowId = db.insert(table, null, hm.get(table)); } } }
論理的には、2つのサイクルに分割されます。最初のサイクルではSQLのリストを取得します。データベースを作成して実行するための命令、2番目のサイクルでは以前に作成したテーブルに初期データを既に入力します。 そして、ステップ1:
private ArrayList<String> getSQLTables() { ArrayList<String> tables = new ArrayList<>(); ArrayList<String> files = new ArrayList<>(); AssetManager assetManager = mContext.getAssets(); String dir = mDb + mVersion; try { String[] listFiles = assetManager.list(dir); for (String file: listFiles){ files.add(file); } Collections.sort(files, new QueryFilesComparator()); BufferedReader bufferedReader; String query; String line; for (String file: files){ Log.d(TAG, "file db is " + file); bufferedReader = new BufferedReader(new InputStreamReader(assetManager.open(dir + "/" + file))); query = ""; while ((line = bufferedReader.readLine()) != null){ query = query + line; } bufferedReader.close(); tables.add(query); } } catch (IOException e) { e.printStackTrace(); } return tables; }
ここではすべてが非常に単純です。ファイルのコンテンツを読み取り、各ファイルのコンテンツを配列要素に連結します。 テーブルは外部キーを持つことができるため、ファイルのリストをソートしていることに注意してください。つまり、テーブルは特定の順序で作成する必要があります。 ファイルの名前に番号を使用し、それを使って並べ替えます。
private class QueryFilesComparator implements Comparator<String>{ @Override public int compare(String file1, String file2) { Integer f2 = Integer.parseInt(file1.substring(0, 2)); Integer f1 = Integer.parseInt(file2.substring(0, 2)); return f2.compareTo(f1); } }
テーブルに記入するのはもっと楽しいです。 私のテーブルには、ハードセットされた値だけでなく、リソースとUUIDキーからの値も入力されます(ユーザーが共有データを操作できるように、いつかプログラムのネットワークバージョンにアクセスしたいです)。 初期データを含むファイルの構造は次のようになります。

私のファイルはsql拡張子を持っているという事実にもかかわらず、内部はsqlコードではなく、そのようなものです:
prioritys
pri_id:UUID:UUID
pri_object:string:object_task
pri_name:string:normal
pri_color:color:colorGreen
pri_default:int:1
prioritys
pri_id:UUID:UUID
pri_object:string:object_task
pri_name:string:hold
pri_color:color:colorBlue
pri_default:int:0
prioritys
pri_id:UUID:UUID
pri_object:string:object_task
pri_name:string:important
pri_color:color:colorRed
pri_default:int:0
prioritys
pri_id:UUID:UUID
pri_object:string:object_project
pri_name:string:normal
pri_color:color:colorGreen
pri_default:int:1
prioritys
pri_id:UUID:UUID
pri_object:string:object_project
pri_name:string:hold
pri_color:color:colorBlue
pri_default:int:0
prioritys
pri_id:UUID:UUID
pri_object:string:object_project
pri_name:string:important
pri_color:color:colorRed
pri_default:int:0
ファイル構造は次のとおりです。行に関してsplit( ":")関数を呼び出し、そのサイズが1である場合、これはデータが書き込まれるテーブルの名前です。 それ以外の場合は、データ自体です。 最初のフィールドは、テーブル内のフィールドの名前です。 2番目のフィールドは、このフィールドに書き込む必要があるものを決定するタイプです。 これがUUIDの場合、一意のUUID値を生成する必要があることを意味します。 文字列がリソースから文字列値を取得する必要があることを意味する場合。 色の場合は、リソースから色コードを取得する必要があります。 intまたはtextの場合、この値をジェスチャーなしでintまたはStringに変換します。 コード自体は次のようになります。
private ArrayList<HashMap<String, ContentValues>> getSQLDatas() { ArrayList<HashMap<String, ContentValues>> data = new ArrayList<>(); ArrayList<String> files = new ArrayList<>(); AssetManager assetManager = mContext.getAssets(); String dir = mData + mVersion; try { String[] listFiles = assetManager.list(dir); for (String file: listFiles){ files.add(file); } Collections.sort(files, new QueryFilesComparator()); BufferedReader bufferedReader; String line; int separator = 0; ContentValues cv = null; String[] fields; String nameTable = null; String packageName = mContext.getPackageName(); boolean flag = false; HashMap<String, ContentValues> hm; for (String file: files){ Log.d(TAG, "file db is " + file); bufferedReader = new BufferedReader(new InputStreamReader(assetManager.open(dir + "/" + file))); while ((line = bufferedReader.readLine()) != null){ fields = line.trim().split(":"); if (fields.length == 1){ if (flag == true){ hm = new HashMap<>(); hm.put(nameTable, cv); data.add(hm); } // nameTable = line.trim(); cv = new ContentValues(); continue; } else { if (fields[1].equals("UUID")){ cv.put(fields[0], UUID.randomUUID().toString()); } else if (fields[1].equals("color") || fields[1].equals("string")){ int resId = mContext.getResources().getIdentifier(fields[2], fields[1], packageName); Log.d(TAG, fields[1] + " " + resId); switch (fields[1]){ case "color": cv.put(fields[0], resId); break; case "string": cv.put(fields[0], mContext.getString(resId)); break; default: break; } } else if (fields[1].equals("text")){ cv.put(fields[0], fields[2]); } else if (fields[1].equals("int")){ cv.put(fields[0], Integer.parseInt(fields[2])); } } flag = true; } bufferedReader.close(); } } catch (IOException e) { e.printStackTrace(); } return data; }
突然の
この記事に既にコードを挿入したので、2つの問題に気付きました。 まず、ファイルの最後に空の行がない場合、ContentValuesを配列に追加しません。 第二に、外部キーがあるテーブルにデータを挿入する必要がある場合の問題について考えました。 私はその場で何も思いつきませんでした。私は余暇にそれを実装するのが最善であると思います。
あとがきとして、私はAndroid向けプログラミングのアマチュアだと言って繰り返しますが、これは問題の半分です。 2番目の問題は、私の環境にはAndroidプログラマーがいないことであり、実際、相談する人もいないし、より良い方法をブレインストーミングする人もいないということです。 科学的な突進の方法に従い、途中で熊手を踏まなければなりません。 痛いこともありますが、全体的にクールです。 私が取り組んでいるプロジェクトは、すでに4つの転生を経験しています。 したがって、ピアニストを撃たないでください、できる限り演奏します。 もっとうまくやる方法を書いてくれたら、感謝して嬉しいです。