オープンデータサイエンスコミュニティがコース参加者を歓迎します!
コースの一環として、すでにいくつかの重要な機械学習アルゴリズムに精通しています。 ただし、より洗練されたアルゴリズムとアプローチに進む前に、一歩踏み込んで、モデルトレーニング用のデータの準備について話したいと思います。 ガベージイン-ガベージアウトのよく知られている原則は、すべての機械学習タスクに100%適用可能です。 経験豊富なアナリストであれば、定性的に準備されたデータでトレーニングされた単純なモデルが、不十分なクリーンデータで構築されたunningなアンサンブルよりも優れていることが判明した場合の実践例を思い出すことができます。
UPD:現在、コースは英語で、 mlcourse.aiというブランド名で、Medium に関する記事 、Kaggle( Dataset )およびGitHubに関する資料があります 。

今日の記事のフレームワークでは、3つの類似しているが異なるタスクを確認します。
- 特徴抽出と特徴エンジニアリング-ドメイン固有のデータをモデルに適したベクトルに変換します。
- 特徴変換-アルゴリズムの精度を高めるためのデータ変換。
- 機能選択-不要な機能を切り取ります。
これとは別に、この記事では数式はほとんどないことに注意してください。ただし、比較的多くのコードがあります。
いくつかの例では、 Two Sigma Connectで使用されるRenthop データセットを使用します:Kaggleでの競合物件の照会。 この問題では、不動産賃貸広告の人気を予測する必要があります。 分類問題を3つのクラス['low', 'medium', 'high']
ます。 ソリューションを評価するには、ログ損失メトリックが使用されます(小さいほど良い)。 Kaggleのアカウントをまだお持ちでない方は登録する必要があります。 また、データをダウンロードするには、競争ルールに同意する必要があります。
# train.json.zip Kaggle import json import pandas as pd # Renthop with open('train.json', 'r') as raw_data: data = json.load(raw_data) df = pd.DataFrame(data)

特徴抽出
人生では、データが既製のマトリックスの形で提供されることはめったにないため、すべてのタスクは属性の抽出から始まります。 もちろん、csvファイルを読み取ってnumpy.array
に変換するだけで十分な場合もありますが、これらは幸せな例外です。 特性を抽出する一般的なデータ型を見てみましょう。
テキスト
テキストは、自由形式のデータの最も明白な例です。 テキストを扱う方法は十分であるため、1つの記事には収まりません。 それにもかかわらず、最も人気のあるものを見ていきます。
テキストを操作する前に、トークン化する必要があります。 トークン化では、テキストをトークンに分割します。最も単純な場合、これらは単なる単語です。 しかし、定期的なスケジュール(「額」)を単純にしすぎると、「ニジニノヴゴロド」は2つのトークンではなく、1つの意味を失う可能性があります。 しかし、呼び出しは「スチールキル!」です。 無駄に2つのトークンに分割できます。 言語の特性を考慮に入れた既製のトークナイザーがありますが、特に特定のテキスト(専門用語、専門用語、タイプミス)で作業している場合、間違っている可能性があります。
ほとんどの場合、トークン化の後、通常の形式に戻すことを検討する必要があります。 私たちは語幹処理および/または補題について話している-これらは単語形式を処理するために使用される同様のプロセスです。 それらの違いについてはこちらをご覧ください 。
したがって、ドキュメントを一連の単語に変換し、それらをベクトルに変換し始めることができます。 最も単純なアプローチはBag of Wordsと呼ばれます。辞書長のベクトルを作成し、各単語に対してテキスト内のエントリの数をカウントし、この数をベクトル内の対応する位置に置き換えます。 コードでは、これは言葉よりも簡単に見えます。
from functools import reduce import numpy as np texts = [['i', 'have', 'a', 'cat'], ['he', 'have', 'a', 'dog'], ['he', 'and', 'i', 'have', 'a', 'cat', 'and', 'a', 'dog']] dictionary = list(enumerate(set(reduce(lambda x, y: x + y, texts)))) def vectorize(text): vector = np.zeros(len(dictionary)) for i, word in dictionary: num = 0 for w in text: if w == word: num += 1 if num: vector[i] = num return vector for t in texts: print(vectorize(t))
また、このアイデアは写真でよく示されています。

これは非常に単純な実装です。 実際には、ストップワード、辞書の最大サイズ、有効なデータ構造(通常、テキストデータはスパースベクトルに変換されます)に注意する必要があります...
Bag of Wordsのようなアルゴリズムを使用すると、テキスト内の語順が失われます。つまり、「i、cow are no」と「no、i have cows」というテキストは、ベクトル化後は意味的に反対ですが、同じになります。 この問題を回避するには、一歩下がってトークン化のアプローチを変更します。たとえば、N-gram(N個の連続した用語の組み合わせ)を使用します。
In : from sklearn.feature_extraction.text import CountVectorizer In : vect = CountVectorizer(ngram_range=(1,1)) In : vect.fit_transform(['no i have cows', 'i have no cows']).toarray() Out: array([[1, 1, 1], [1, 1, 1]], dtype=int64) In : vect.vocabulary_ Out: {'cows': 0, 'have': 1, 'no': 2} In : vect = CountVectorizer(ngram_range=(1,2)) In : vect.fit_transform(['no i have cows', 'i have no cows']).toarray() Out: array([[1, 1, 1, 0, 1, 0, 1], [1, 1, 0, 1, 1, 1, 0]], dtype=int64) In : vect.vocabulary_ Out: {'cows': 0, 'have': 1, 'have cows': 2, 'have no': 3, 'no': 4, 'no cows': 5, 'no have': 6}
また、単語を操作する必要がないことにも注意してください。場合によっては、文字からN-gramを生成できます(たとえば、このようなアルゴリズムでは、関連する単語やタイプミスの類似性が考慮されます)。
In : from scipy.spatial.distance import euclidean In : vect = CountVectorizer(ngram_range=(3,3), analyzer='char_wb') In : n1, n2, n3, n4 = vect.fit_transform(['', '', '', '']).toarray() In : euclidean(n1, n2) Out: 3.1622776601683795 In : euclidean(n2, n3) Out: 2.8284271247461903 In : euclidean(n3, n4) Out: 3.4641016151377544
Bag of Wordsの概念の開発:コーパス(検討中のこのデータセット内のすべてのドキュメント)にはめったに見られないが、この特定のドキュメントに存在する単語は、より重要かもしれません。 次に、一般的な主題の単語と区別するために、より狭義の主題の単語の重みを増やすことは理にかなっています。 このアプローチはTF-IDFと呼ばれ、10行で記述することはできません。したがって、希望する人はwikiなどの外部ソースの詳細に慣れることができます 。 デフォルトのオプションは次のようになります。
Bag of Wordsの類似物は、テキストタスク以外でも見つけることができます。たとえば、私たちが開催しているコンテストの Bag of Sites-Catch Me If You Canなどです。 他の例(アプリの バッグ、イベントのバッグ)を検索できます 。

このようなアルゴリズムを使用すると、簡単な問題に対する完全に機能するソリューション、つまりベースラインを取得できます。 ただし、クラシックの愛好家には、新しいアプローチがあります。 新しいウェーブの最も一般的な方法はWord2Vecですが、代替手段(グローブ、ファストテキストなど)もあります。
Word2Vecは、Word埋め込みアルゴリズムの特殊なケースです。 Word2Vecおよび同様のモデルを使用して、単語を大規模な空間(通常は数百)にベクトル化するだけでなく、それらのセマンティックな近接性を比較することもできます。 ベクトル化されたビューの操作の古典的な例:キング-男性+女性=クイーン。

もちろん、このモデルは単語を理解していないことを理解する価値がありますが、一般的なコンテキストで使用される単語が互いに近くに配置されるようにベクトルを配置しようとします。 これが考慮されていない場合、多くの面白いことが発明されます。例えば、対応するベクトルに-1を掛けることでヒトラーの反対を見つけます。
このようなモデルは、ベクトルの座標が実際に単語のセマンティクスを反映するように、非常に大きなデータセットでトレーニングする必要があります。 あなたの問題を解決するために、例えばここから事前に訓練されたモデルをダウンロードできます。
ちなみに、他の分野(バイオインフォマティクスなど)でも同様の方法が使用されています。 最も予期せぬ使用法-food2vec 。
画像
画像の操作では、すべてが同時によりシンプルで複雑になります。 より簡単です。多くの場合、よく考えられた事前トレーニング済みネットワークの1つをまったく考えて使用できないためです。 さらに複雑なのは、まだ詳細に理解する必要がある場合は、このウサギの穴が非常に深くなるからです。 ただし、最初にまず最初に。
GPUが弱く、「ニューラルネットワークのルネッサンス」がまだ発生していなかった当時、画像から機能を生成することは別の複雑な分野でした。 写真を使用するには、角度、領域の境界などを定義する低レベルで作業する必要がありました。 コンピュータービジョンの経験豊富な専門家は、古いアプローチとニューラルネットワークヒップスターの間に多くの類似点を描くことができます。特に、現代のネットワークの畳み込み層は、 Haarカスケードに非常に似ています。 この問題を経験することなく、私は公的な情報源から知識を移そうとはしません。skimageとSimpleCVライブラリへのリンクをいくつか残して、私たちの時代に直行します。
多くの場合、写真に関連するタスクには、ある種の畳み込みネットワークが使用されます。 アーキテクチャを思いついたり、ネットワークをゼロからトレーニングしたりすることはできませんが、事前にトレーニングされた最先端のネットワークを利用できます。その重みはオープンソースからダウンロードできます。 それを彼らの仕事に適応させるために、科学者たちはいわゆる 微調整:ネットワークの最後の完全に接続された層が「オフ」になり、それらの代わりに新しい層が追加され、特定のタスク用に選択され、ネットワークは新しいデータでトレーニングされます。 ただし、何らかの目的で画像を単純にベクトル化する場合(たとえば、ある種の非ネットワーク分類子を使用する場合)-最後のレイヤーを切り取り、前のレイヤーの出力を使用するだけです:
from keras.applications.resnet50 import ResNet50 from keras.preprocessing import image from scipy.misc import face import numpy as np resnet_settings = {'include_top': False, 'weights': 'imagenet'} resnet = ResNet50(**resnet_settings) img = image.array_to_img(face()) # ! img = img.resize((224, 224)) # x = image.img_to_array(img) x = np.expand_dims(x, axis=0) # , .. features = resnet.predict(x)

あるデータセットで訓練され、最後のレイヤーを「ティアリング」して代わりに新しいレイヤーを追加することにより、別のデータセットに適応した分類子
ただし、ニューラルネットワークの方法にこだわらないでください。 手で生成される兆候のいくつかは最近便利になります。たとえば、アパート賃貸広告の人気を予測する場合、明るいアパートがより注目を集め、「平均ピクセル値」の兆候を作ると想定できます。 それぞれのライブラリのドキュメントの例に触発されます 。
画像にテキストが必要な場合は、たとえばpytesseractを使用して、複雑なニューラルネットワークを自分の手で展開することなく読むこともできます。
In : import pytesseract In : from PIL import Image In : import requests In : from io import BytesIO In : img = 'http://ohscurrent.org/wp-content/uploads/2015/09/domus-01-google.jpg' # In : img = requests.get(img) ...: img = Image.open(BytesIO(img.content)) ...: text = pytesseract.image_to_string(img) ...: In : text Out: 'Google'
pytesseractは万能薬とはほど遠いことを理解する必要があります。
# Renthop In : img = requests.get('https://photos.renthop.com/2/8393298_6acaf11f030217d05f3a5604b9a2f70f.jpg') ...: img = Image.open(BytesIO(img.content)) ...: pytesseract.image_to_string(img) ...: Out: 'Cunveztible to 4}»'
ニューラルネットワークが役に立たない別のケースは、メタ情報からの兆候の抽出です。 ただし、EXIFには、カメラのメーカーとモデル、解像度、フラッシュの使用、撮影の地理座標、ソフトウェアの処理に使用されるものなど、多くの有用なものを保存できます。
ジオデータ
地理データはタスクにはあまり見られませんが、特にこの領域には十分な既製のソリューションがあるため、それらを操作するための基本的なテクニックを学ぶことも役立ちます。
ジオデータは、ほとんどの場合、住所または「緯度+経度」のペアの形式で表示されます。 ポイント。 タスクによっては、ジオコーディング(住所からポイントを復元)とリバースジオコーディング(逆)の2つの操作が必要になる場合があります。 どちらも、GoogleマップやOpenStreetMapなどの外部APIを使用して実行できます。 さまざまなジオコーダーには独自の特性があり、品質は地域によって異なります。 幸いなことに、多くの外部サービスのラッパーとして機能するgeopyのようなユニバーサルライブラリがあります。
大量のデータがある場合、外部APIの制限に簡単に遭遇します。 また、HTTP経由で情報を受信することは、常に最適な速度のソリューションではありません。 したがって、OpenStreetMapのローカルバージョンを使用する可能性を念頭に置く価値があります。
データが多くなく、十分な時間があり、洗練された標識を取得する必要がない場合、OpenStreetMapを使用してreverse_geocoderを使用することはできません。
In : import reverse_geocoder as revgc In : revgc.search((df.latitude, df.longitude)) Loading formatted geocoded file... Out: [OrderedDict([('lat', '40.74482'), ('lon', '-73.94875'), ('name', 'Long Island City'), ('admin1', 'New York'), ('admin2', 'Queens County'), ('cc', 'US')])]
ジオコーディングを使用する場合、住所に入力ミスが含まれている可能性があることを忘れないでください。そのため、時間をかけて整理する価値があります。 通常、座標のタイプミスは少なくなりますが、すべてがうまくいくわけではありません。GPSは、データの性質によって、また一部の場所(トンネル、高層ビルの4分の1 ...)で「ノイズ」を発生させることがあります。 データソースがモバイルデバイスである場合、ジオロケーションはGPSではなく、地区内のWiFiネットワークによって決定される場合があり、スペースやテレポーテーションにつながることを考慮する価値があります。 。
WiFiロケーショントラッキングは、SSIDとMACアドレスの組み合わせに基づいており、完全に異なるポイントで一致する場合があります(たとえば、連邦プロバイダーはMACアドレスの精度でルーターのファームウェアを標準化し、異なる都市に配置します)。 ルーターを使用して会社を別のオフィスに移動するなど、より一般的な理由があります。
ポイントは通常、きれいな分野ではなく、インフラストラクチャの中にあります-ここでは、想像力を自由に操り、兆候を思いつき、人生経験とドメイン領域の知識を適用することができます。 ポイントの地下鉄への近さ、建物の階数、最寄りの店舗までの距離、半径内のATMの数-1つのタスクの枠組みで、数十の標識を見つけてさまざまな外部ソースから取得できます。 都市インフラ外のタスクでは、高度などのより具体的な情報源からの標識が役立つ場合があります。
2つ以上のポイントが相互接続されている場合、それらの間のルートからフィーチャを抽出する価値があります。 ここでは、距離が便利です(大圏距離と、道路グラフに従って計算された「正直な」距離を見る価値があります)、左折と右折の比率に沿ったターン数、信号機、インターチェンジ、橋の数。 たとえば、私のタスクの1つで、「道路の複雑さ」と呼ばれる兆候がよくわかりました-グラフに従って計算され、GCDで除算された距離。
日時
関連する機能が普及しているため、日付と時刻の処理は標準化する必要がありますが、落とし穴は残っています。
曜日から始めましょう-ワンホットコーディングを使用して、簡単に7つのダミー変数に変換できます。 さらに、週末の別の特性を強調表示すると便利です。
df['dow'] = df['created'].apply(lambda x: x.date().weekday()) df['is_weekend'] = df['created'].apply(lambda x: 1 if x.date().weekday() in (5, 6) else 0)
一部のタスクでは、追加のカレンダー機能が必要になる場合があります。たとえば、現金の引き出しは給料日に結び付けられ、旅行カードの購入は月の初めに結び付けられます。 また、一時的なデータを処理する場合、祝日、異常気象、その他の重要なイベントを含むカレンダーを手元に用意する必要があります。
- 中国の旧正月、ニューヨークマラソン、ゲイプライドパレード、トランプの就任の共通点は何ですか?
- それらはすべて、潜在的な異常のカレンダーに追加する必要があります。
しかし、時間(分、月の日...)ですべてがそれほどバラ色ではありません。 時間を実際の変数として使用する場合、データの性質と若干矛盾します:0 <23、ただし02.01 0:00:00> 01.01 23:00:00。 一部のタスクでは、これが重要になる場合があります。 それらをカテゴリ変数としてエンコードすると、多数の記号を生成し、近接性に関する情報を失う可能性があります。22と23の差は22と7の差と同じになります。
このようなデータには、より難解なアプローチがあります。 たとえば、円への投影とそれに続く2つの座標の使用。
def make_harmonic_features(value, period=24): value *= 2 * np.pi / period return np.cos(value), np.sin(value)
このような変換は、ポイント間の距離を保持します。これは、いくつかの距離ベースのアルゴリズム(kNN、SVM、k-means ...)にとって重要です。
In : from scipy.spatial import distance In : euclidean(make_harmonic_features(23), make_harmonic_features(1)) Out: 0.5176380902050424 In : euclidean(make_harmonic_features(9), make_harmonic_features(11)) Out: 0.5176380902050414 In : euclidean(make_harmonic_features(9), make_harmonic_features(21)) Out: 2.0
ただし、このようなエンコード方式の違いは、通常、メトリックの小数点以下3桁でのみ検出でき、それ以前では検出できません。
時系列、ウェブなど
私は時系列を扱うのがあまり楽しくなかったので、時系列からサインを自動生成するためのライブラリへのリンクを残し、さらに先に進みます。
Webを使用する場合、通常、ユーザーのユーザーエージェントに関する情報があります。 これは情報の貯蔵庫です。
まず、そこから、まず、オペレーティングシステムを抽出する必要があります。 次に、記号is_mobile
ます。 第三に、ブラウザを見てください。
In : ua = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/56.0.2924.76 Chrome/ ...: 56.0.2924.76 Safari/537.36' In : import user_agents In : ua = user_agents.parse(ua) In : ua.is_bot Out: False In : ua.is_mobile Out: False In : ua.is_pc Out: True In : ua.os.family Out: 'Ubuntu' In : ua.os.version Out: () In : ua.browser.family Out: 'Chromium' In : ua.os.version Out: () In : ua.browser.version Out: (56, 0, 2924)
他のドメインドメインと同様に、データの性質に関する推測に基づいて独自の属性を作成できます。 この記事の執筆時点では、Chromium 56は新しく、しばらくしてから、このバージョンのブラウザは、非常に長い間このブラウザを再起動していない人のみが保存できます。 では、なぜ「最新バージョンのブラウザに遅れをとっている」というサインを導入しないのですか?
OSとブラウザに加えて、リファラー(常に利用可能とは限りません)、 http_accept_language 、およびその他のメタ情報を確認できます。
次に有用な情報は、少なくとも国、できれば都市、プロバイダー、接続タイプ(モバイル/固定電話)を抽出できるIPアドレスです。 さまざまなプロキシと古いデータベースがあるため、記号にノイズが含まれている可能性があることを理解する必要があります。 ネットワーク管理の達人は、はるかに洗練された機能を抽出しようとすることもできます 。たとえば、 VPNの使用について想定することです。 ちなみに、IPアドレスのデータとhttp_accept_languageを組み合わせることをお勧めします。ユーザーがチリのプロキシに座っていて、ブラウザーのロケールがru_RUである場合、テーブルの対応する列( is_traveler_or_proxy_user
)にあるユニットに不適当で価値があるものがあります。
一般的に、特定の領域には非常に多くのドメイン固有のものがあるため、1つの頭に収まらない。 したがって、私は親愛なる読者に彼らの経験を共有して、彼らの仕事でサインの抽出と生成についてコメントで伝えることを勧めます。
フィーチャ変換
正規化と分布の変化
特徴の単調な変換は、一部のアルゴリズムにとって重要であり、他のアルゴリズムには影響しません。 ちなみに、これが決定木とすべての派生アルゴリズム(ランダムフォレスト、勾配ブースティング)の人気の理由の1つです-誰もが変換を台無しにする方法を知っている/したいわけではありませんが、これらのアルゴリズムは異常な分布に耐性があります。
: np.log
, np.float64
. , ; - . , . ( ).
: , – . 5, .
– Standart Scaling ( Z-score normalization).
StandartScaling ...
In : from sklearn.preprocessing import StandardScaler In : from scipy.stats import beta In : from scipy.stats import shapiro In : data = beta(1, 10).rvs(1000).reshape(-1, 1) In : shapiro(data) Out: (0.8783774375915527, 3.0409122263582326e-27) # , p-value In : shapiro(StandardScaler().fit_transform(data)) Out: (0.8783774375915527, 3.0409122263582326e-27) # p-value
… -
In : data = np.array([1, 1, 0, -1, 2, 1, 2, 3, -2, 4, 100]).reshape(-1, 1).astype(np.float64) In : StandardScaler().fit_transform(data) Out: array([[-0.31922662], [-0.31922662], [-0.35434155], [-0.38945648], [-0.28411169], [-0.31922662], [-0.28411169], [-0.24899676], [-0.42457141], [-0.21388184], [ 3.15715128]]) In : (data – data.mean()) / data.std() Out: array([[-0.31922662], [-0.31922662], [-0.35434155], [-0.38945648], [-0.28411169], [-0.31922662], [-0.28411169], [-0.24899676], [-0.42457141], [-0.21388184], [ 3.15715128]])
– MinMax Scaling, ( (0, 1)).
In : from sklearn.preprocessing import MinMaxScaler In : MinMaxScaler().fit_transform(data) Out: array([[ 0.02941176], [ 0.02941176], [ 0.01960784], [ 0.00980392], [ 0.03921569], [ 0.02941176], [ 0.03921569], [ 0.04901961], [ 0. ], [ 0.05882353], [ 1. ]]) In : (data – data.min()) / (data.max() – data.min()) Out: array([[ 0.02941176], [ 0.02941176], [ 0.01960784], [ 0.00980392], [ 0.03921569], [ 0.02941176], [ 0.03921569], [ 0.04901961], [ 0. ], [ 0.05882353], [ 1. ]])
StandartScaling MinMax Scaling - . , , – StandartScaling. MinMax Scaling , (0, 255).
In : from scipy.stats import lognorm In : data = lognorm(s=1).rvs(1000) In : shapiro(data) Out: (0.05714237689971924, 0.0) In : shapiro(np.log(data)) Out: (0.9980740547180176, 0.3150389492511749)
, , , .. , – . , , , . - ( – -) - , ; , – np.log(x + const)
.
-. , – QQ . , .
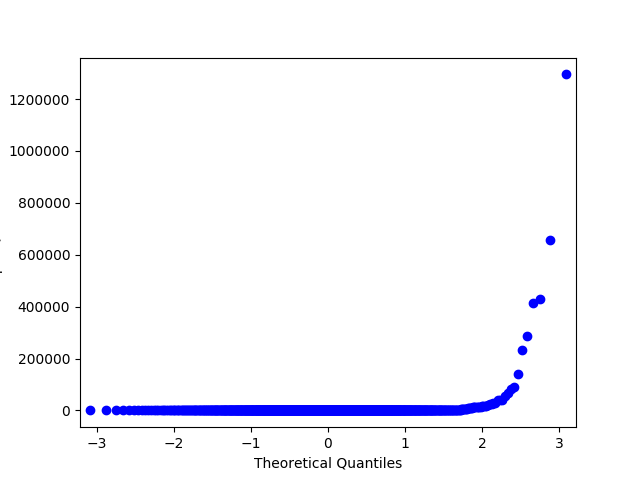

In : import statsmodels.api as sm # price Renthop In : price = df.price[(df.price <= 20000) & (df.price > 500)] In : price_log = np.log(price) In : price_mm = MinMaxScaler().fit_transform(price.values.reshape(-1, 1).astype(np.float64)).flatten() # , sklearn warning- In : price_z = StandardScaler().fit_transform(price.values.reshape(-1, 1).astype(np.float64)).flatten() In : sm.qqplot(price_log, loc=price_log.mean(), scale=price_log.std()).savefig('qq_price_log.png') In : sm.qqplot(price_mm, loc=price_mm.mean(), scale=price_mm.std()).savefig('qq_price_mm.png') In : sm.qqplot(price_z, loc=price_z.mean(), scale=price_z.std()).savefig('qq_price_z.png')


QQ StandartScaler.
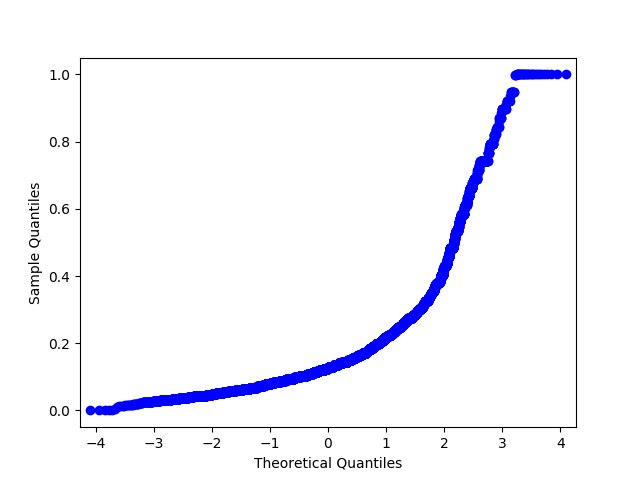
QQ MinMaxScaler.

QQ . !
In : from demo import get_data In : x_data, y_data = get_data() In : x_data.head(5) Out: bathrooms bedrooms price dishwasher doorman pets \ 10 1.5 3 8.006368 0 0 0 10000 1.0 2 8.606119 0 1 1 100004 1.0 1 7.955074 1 0 1 100007 1.0 1 8.094073 0 0 0 100013 1.0 4 8.116716 0 0 0 air_conditioning parking balcony bike ... stainless \ 10 0 0 0 0 ... 0 10000 0 0 0 0 ... 0 100004 0 0 0 0 ... 0 100007 0 0 0 0 ... 0 100013 0 0 0 0 ... 0 simplex public num_photos num_features listing_age room_dif \ 10 0 0 5 0 278 1.5 10000 0 0 11 57 290 1.0 100004 0 0 8 72 346 0.0 100007 0 0 3 22 345 0.0 100013 0 0 3 7 335 3.0 room_sum price_per_room bedrooms_share 10 4.5 666.666667 0.666667 10000 3.0 1821.666667 0.666667 100004 2.0 1425.000000 0.500000 100007 2.0 1637.500000 0.500000 100013 5.0 670.000000 0.800000 [5 rows x 46 columns] In : x_data = x_data.values In : from sklearn.linear_model import LogisticRegression In : from sklearn.ensemble import RandomForestClassifier In : from sklearn.model_selection import cross_val_score In : from sklearn.feature_selection import SelectFromModel In : cross_val_score(LogisticRegression(), x_data, y_data, scoring='neg_log_loss').mean() /home/arseny/.pyenv/versions/3.6.0/lib/python3.6/site-packages/sklearn/linear_model/base.py:352: RuntimeWarning: overflow encountered in exp np.exp(prob, prob) # , - ! - , Out: -0.68715971821885724 In : from sklearn.preprocessing import StandardScaler In : cross_val_score(LogisticRegression(), StandardScaler().fit_transform(x_data), y_data, scoring='neg_log_loss').mean() /home/arseny/.pyenv/versions/3.6.0/lib/python3.6/site-packages/sklearn/linear_model/base.py:352: RuntimeWarning: overflow encountered in exp np.exp(prob, prob) Out: -0.66985167834479187 # ! ! In : from sklearn.preprocessing import MinMaxScaler In : cross_val_score(LogisticRegression(), MinMaxScaler().fit_transform(x_data), y_data, scoring='neg_log_loss').mean() ...: Out: -0.68522489913898188 # a – :(
(Interactions)
, ; , .
Two Sigma Connect: Rental Listing Inquires. . , , – , .
rooms = df["bedrooms"].apply(lambda x: max(x, .5)) # ; .5 df["price_per_bedroom"] = df["price"] / rooms
. , , , . , - : , ( )[ https://habrahabr.ru/company/ods/blog/322076/ ] (. sklearn.preprocessing.PolynomialFeatures
) .
" ", . , , . python : pandas.DataFrame.fillna
sklearn.preprocessing.Imputer
.
. :
-
"n/a"
( ); - ( , );
- , - ( , , .. );
- (, ) – .

- df = df.fillna(0)
. : , ; .
(Feature selection)
? - , . : , . , – , . – ( ) , .
– , , .. . , , , . , .
In : from sklearn.feature_selection import VarianceThreshold In : from sklearn.datasets import make_classification In : x_data_generated, y_data_generated = make_classification() In : x_data_generated.shape Out: (100, 20) In : VarianceThreshold(.7).fit_transform(x_data_generated).shape Out: (100, 19) In : VarianceThreshold(.8).fit_transform(x_data_generated).shape Out: (100, 18) In : VarianceThreshold(.9).fit_transform(x_data_generated).shape Out: (100, 15)
In : from sklearn.feature_selection import SelectKBest, f_classif In : x_data_kbest = SelectKBest(f_classif, k=5).fit_transform(x_data_generated, y_data_generated) In : x_data_varth = VarianceThreshold(.9).fit_transform(x_data_generated) In : from sklearn.linear_model import LogisticRegression In : from sklearn.model_selection import cross_val_score In : cross_val_score(LogisticRegression(), x_data_generated, y_data_generated, scoring='neg_log_loss').mean() Out: -0.45367136377981693 In : cross_val_score(LogisticRegression(), x_data_kbest, y_data_generated, scoring='neg_log_loss').mean() Out: -0.35775228616521798 In : cross_val_score(LogisticRegression(), x_data_varth, y_data_generated, scoring='neg_log_loss').mean() Out: -0.44033042718359772
, . , , , .
: - baseline , . : - "" (, Random Forest) Lasso , . : , .
from sklearn.datasets import make_classification from sklearn.linear_model import LogisticRegression from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import SelectFromModel from sklearn.model_selection import cross_val_score from sklearn.pipeline import make_pipeline x_data_generated, y_data_generated = make_classification() pipe = make_pipeline(SelectFromModel(estimator=RandomForestClassifier()), LogisticRegression()) lr = LogisticRegression() rf = RandomForestClassifier() print(cross_val_score(lr, x_data_generated, y_data_generated, scoring='neg_log_loss').mean()) print(cross_val_score(rf, x_data_generated, y_data_generated, scoring='neg_log_loss').mean()) print(cross_val_score(pipe, x_data_generated, y_data_generated, scoring='neg_log_loss').mean()) -0.184853179322 -0.235652626736 -0.158372952933
, — .
x_data, y_data = get_data() x_data = x_data.values pipe1 = make_pipeline(StandardScaler(), SelectFromModel(estimator=RandomForestClassifier()), LogisticRegression()) pipe2 = make_pipeline(StandardScaler(), LogisticRegression()) rf = RandomForestClassifier() print('LR + selection: ', cross_val_score(pipe1, x_data, y_data, scoring='neg_log_loss').mean()) print('LR: ', cross_val_score(pipe2, x_data, y_data, scoring='neg_log_loss').mean()) print('RF: ', cross_val_score(rf, x_data, y_data, scoring='neg_log_loss').mean()) LR + selection: -0.714208124619 LR: -0.669572736183 # ! RF: -2.13486716798
, , : "", , , . Exhaustive Feature Selection .
– , . N, N , , N+1 , , . , . Sequential Feature Selection .
: , .
In : selector = SequentialFeatureSelector(LogisticRegression(), scoring='neg_log_loss', verbose=2, k_features=3, forward=False, n_jobs=-1) In : selector.fit(x_data_scaled, y_data) In : selector.fit(x_data_scaled, y_data) [2017-03-30 01:42:24] Features: 45/3 -- score: -0.682830838803 [2017-03-30 01:44:40] Features: 44/3 -- score: -0.682779463265 [2017-03-30 01:46:47] Features: 43/3 -- score: -0.682727480522 [2017-03-30 01:48:54] Features: 42/3 -- score: -0.682680521828 [2017-03-30 01:50:52] Features: 41/3 -- score: -0.68264297879 [2017-03-30 01:52:46] Features: 40/3 -- score: -0.682607753617 [2017-03-30 01:54:37] Features: 39/3 -- score: -0.682570678346 [2017-03-30 01:56:21] Features: 38/3 -- score: -0.682536314625 [2017-03-30 01:58:02] Features: 37/3 -- score: -0.682520258804 [2017-03-30 01:59:39] Features: 36/3 -- score: -0.68250862986 [2017-03-30 02:01:17] Features: 35/3 -- score: -0.682498213174 # ". ..." ... [2017-03-30 02:21:09] Features: 10/3 -- score: -0.68657335969 [2017-03-30 02:21:18] Features: 9/3 -- score: -0.688405548594 [2017-03-30 02:21:26] Features: 8/3 -- score: -0.690213724719 [2017-03-30 02:21:32] Features: 7/3 -- score: -0.692383588303 [2017-03-30 02:21:36] Features: 6/3 -- score: -0.695321584506 [2017-03-30 02:21:40] Features: 5/3 -- score: -0.698519960477 [2017-03-30 02:21:42] Features: 4/3 -- score: -0.704095390444 [2017-03-30 02:21:44] Features: 3/3 -- score: -0.713788301404 #
№6
c UCI . Jupyter notebook - , .