こんにちは、Habr! すでにTheanoとTensorflowについて(および他に何についても)話しましたが、今日はKerasについて話します。
KerasはもともとTheanoの便利なアドオンとして成長しました。 したがって、彼のギリシャ語の名前はκέραςであり、ギリシャ語で「ホーン」を意味します。これは、ホーマーのオデッセイへの言及です。 しかし、それ以来多くの水が流れ、ケラスはテンソルフローをサポートし始め、その後完全にその一部になりました。 ただし、私たちのストーリーは、このフレームワークの難しい運命ではなく、その機能に専念します。 興味があれば、猫にようこそ。

ストーブ、つまり目次から始めてください。
- [インストール]
- [バックエンド]
- [実用例]
- [データ]
- [モデル]
- [シーケンシャルAPI]
- [機能API]
- [作業用モデルの準備]
- [カスタム損失]
- [トレーニングとテスト]
- [コールバック]
- [テンソルボード]
- [高度なカウント]
- [結論]
設置
Kerasのインストールは非常に簡単です 通常のpythonパッケージです:
pip install keras
これで分析を開始できますが、最初にバックエンドについて話しましょう。
注意: Kerasを使用するには、少なくとも1つのフレームワーク(TheanoまたはTensorflow)がインストールされている必要があります。
バックエンド
バックエンドは、Kerasを有名にし、人気のあるものにしました(他の利点の中でも、以下で説明します)。 Kerasでは、他のさまざまなフレームワークをバックエンドとして使用できます。 この場合、使用したバックエンドに関係なく、作成したコードが実行されます。 既に述べたように、Theanoで開発が始まりましたが、時間の経過とともにTensorflowが追加されました。 現在、Kerasはデフォルトでそれで動作しますが、Theanoを使用したい場合、これを行う方法には2つのオプションがあります:
- パス
$HOME/.keras/keras.json
(またはWindowsオペレーティングシステムの場合は%USERPROFILE%\.keras\keras.json
)にあるkeras.json構成ファイルを編集します。backend
フィールドが必要です。
{ "image_data_format": "channels_last", "epsilon": 1e-07, "floatx": "float32", "backend": "theano" }
- 2番目の方法は、
KERAS_BACKEND
環境KERAS_BACKEND
を次のように設定することKERAS_BACKEND
。
KERAS_BACKEND=theano python -c "from keras import backend" Using Theano backend.
現在、MicrosoftからCNTKのバインダーを作成する作業が行われていることは注目に値するため、しばらくすると別のバックエンドが利用可能になります。 こちらをご覧ください 。
MXNet Kerasバックエンドもありますが、これにはまだすべての機能がありませんが、MXNetを使用している場合は、この可能性に注意を払うことができます。
また、GPUを搭載したマシンでブラウザからトレーニング済みのKerasモデルを実行できる興味深いKeras.jsプロジェクトもあります。
したがって、Kerasバックエンドは拡大し、時間をかけて世界を引き継ぎます! (しかし、これは不正確です。)
実用例
以前の記事では、記述されたフレームワークでの機械学習の古典的なモデルの作業の説明に多くの注意が払われました。 今では、[そうではない]ディープニューラルネットワークを例に取ることができるようです。
データ

機械学習のモデルの学習は、データから始まります。 Kerasには内部にいくつかのトレーニングデータセットが含まれていますが、それらはすでに仕事に便利な形になっているため、Kerasの全力を発揮することはできません。 したがって、より生のデータセットを使用します。 これは20のニュースグループのデータセットになります-Usenetグループからの2万のニュースメッセージ(これは1990年代のメール交換システムであり、FIDOに似ています。おそらく読者には少し馴染みがあります)は、20のカテゴリにほぼ均等に分散されます。 これらのニュースグループ間でメッセージを正しく配信するようネットワークに教えます。
from sklearn.datasets import fetch_20newsgroups newsgroups_train = fetch_20newsgroups(subset='train') newsgroups_test = fetch_20newsgroups(subset='test')
トレーニングセットのドキュメントの内容の例を次に示します。
From:lerxst@wam.umd.edu(私のことはどこですか)
件名:これは何の車ですか!?
Nntp投稿ホスト:rac3.wam.umd.edu
組織:メリーランド大学カレッジパーク
行:15
私が見たこの車で私を啓発できる人はいないかと思っていました
先日。 60年代後半のように見えた2ドアスポーツカーでした/
70年代前半。 それはブリクリンと呼ばれていました。 ドアは本当に小さかった。 さらに、
フロントバンパーは他の部分から分離されていました。 これは
私が知っているすべて。 誰かがモデル名、エンジンの仕様、年を教えてくれれば
生産、この車が作られた場所、歴史、またはあなたがどんな情報でも
このファンキーな車に乗って、メールしてください。
おかげで、
- IL
-あなたの近所のLerxstから持ってきた----
前処理
Kerasには、テキスト、写真、時系列、つまり最も一般的なデータ型の便利な前処理のためのツールが含まれています。 今日、私たちはテキストで作業しているので、それらをトークンに分割し、マトリックス形式にする必要があります。
tokenizer = Tokenizer(num_words=max_words) tokenizer.fit_on_texts(newsgroups_train["data"]) # x_train = tokenizer.texts_to_matrix(newsgroups_train["data"], mode='binary') x_test = tokenizer.texts_to_matrix(newsgroups_test["data"], mode='binary')
出力では、次のサイズのバイナリ行列が得られました。
x_train shape: (11314, 1000) x_test shape: (7532, 1000)
最初の数字はサンプル内のドキュメントの数であり、2番目は辞書のサイズ(この例では1,000)です。
また、クロスエントロピーを使用して学習するために、クラスラベルを行列形式に変換する必要があります。 これを行うために、クラス番号をいわゆるワンホットベクトルに変換します。 ゼロと1単位で構成されるベクトル:
y_train = keras.utils.to_categorical(newsgroups_train["target"], num_classes) y_test = keras.utils.to_categorical(newsgroups_test["target"], num_classes)
出力では、これらのサイズのバイナリ行列も取得します。
y_train shape: (11314, 20) y_test shape: (7532, 20)
ご覧のとおり、これらの行列のサイズはデータ行列(最初の座標では、トレーニングサンプルとテストサンプルのドキュメント数)と部分的に一致し、部分的には一致しません。 2番目の座標には、クラスの数があります(データセットの名前が示すとおり、20)。
これで、ネットワークを教えてニュースを分類する準備ができました!
モデル
Kerasのモデルは、主に2つの方法で説明できます。
シーケンシャルAPI
1つ目は、たとえば次のようなモデルの連続的な説明です。
model = Sequential() model.add(Dense(512, input_shape=(max_words,))) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(num_classes)) model.add(Activation('softmax'))
またはこのように:
model = Sequential([ Dense(512, input_shape=(max_words,)), Activation('relu'), Dropout(0.5), Dense(num_classes), Activation('softmax') ])
機能的なAPI
少し前に、機能的なAPIを使用してモデルを作成することが可能になりました-2番目の方法:
a = Input(shape=(max_words,)) b = Dense(512)(a) b = Activation('relu')(b) b = Dropout(0.5)(b) b = Dense(num_classes)(b) b = Activation('softmax')(b) model = Model(inputs=a, outputs=b)
方法の間に根本的な違いはありません;好みの方法を選択してください。
Model
クラス(およびそのクラスから継承されたSequential
)には、model- model.layers
、inputs- model.inputs
、outputs- model.outputs
含まれるレイヤーを確認できる便利なインターフェイスがあります。
また、モデルを表示および保存するための非常に便利な方法はmodel.to_yaml
です。
backend: tensorflow class_name: Model config: input_layers: - [input_4, 0, 0] layers: - class_name: InputLayer config: batch_input_shape: !!python/tuple [null, 1000] dtype: float32 name: input_4 sparse: false inbound_nodes: [] name: input_4 - class_name: Dense config: activation: linear activity_regularizer: null bias_constraint: null bias_initializer: class_name: Zeros config: {} bias_regularizer: null kernel_constraint: null kernel_initializer: class_name: VarianceScaling config: {distribution: uniform, mode: fan_avg, scale: 1.0, seed: null} kernel_regularizer: null name: dense_10 trainable: true units: 512 use_bias: true inbound_nodes: - - - input_4 - 0 - 0 - {} name: dense_10 - class_name: Activation config: {activation: relu, name: activation_9, trainable: true} inbound_nodes: - - - dense_10 - 0 - 0 - {} name: activation_9 - class_name: Dropout config: {name: dropout_5, rate: 0.5, trainable: true} inbound_nodes: - - - activation_9 - 0 - 0 - {} name: dropout_5 - class_name: Dense config: activation: linear activity_regularizer: null bias_constraint: null bias_initializer: class_name: Zeros config: {} bias_regularizer: null kernel_constraint: null kernel_initializer: class_name: VarianceScaling config: {distribution: uniform, mode: fan_avg, scale: 1.0, seed: null} kernel_regularizer: null name: dense_11 trainable: true units: !!python/object/apply:numpy.core.multiarray.scalar - !!python/object/apply:numpy.dtype args: [i8, 0, 1] state: !!python/tuple [3, <, null, null, null, -1, -1, 0] - !!binary | FAAAAAAAAAA= use_bias: true inbound_nodes: - - - dropout_5 - 0 - 0 - {} name: dense_11 - class_name: Activation config: {activation: softmax, name: activation_10, trainable: true} inbound_nodes: - - - dense_11 - 0 - 0 - {} name: activation_10 name: model_1 output_layers: - [activation_10, 0, 0] keras_version: 2.0.2
これにより、モデルを人間が読める形式で保存し、この説明からモデルをインスタンス化できます。
from keras.models import model_from_yaml yaml_string = model.to_yaml() model = model_from_yaml(yaml_string)
テキスト形式で保存されたモデル(ちなみに、JSONで保存することもできます)には重みが含まれていないことに注意することが重要です。 ウェイトを保存およびロードするにはload_weights
それぞれsave_weights
およびload_weights
使用します。
モデルの可視化
視覚化を無視することはできません。 Kerasには、モデルのビルトインビジュアライゼーションがあります。
from keras.utils import plot_model plot_model(model, to_file='model.png', show_shapes=True)
このコードは、次の画像をmodel.png
として保存します。
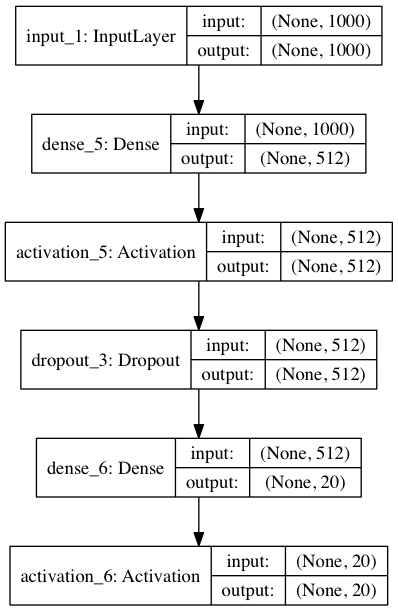
ここでは、レイヤーの入力と出力のサイズも追加で表示しました。 None
、サイズのタプルで最初に行く-これはバッチの次元です。 なぜなら None
価値がある場合、バッチは任意です。
jupyter
ラップトップで表示する場合は、少し異なるコードが必要です。
from IPython.display import SVG from keras.utils.vis_utils import model_to_dot SVG(model_to_dot(model, show_shapes=True).create(prog='dot', format='svg'))
視覚化には、graphpyzパッケージとpython pydotパッケージが必要であることに注意することが重要です。 ビジュアライゼーションが正しくpydot
するためには、リポジトリからpydot
パッケージが機能しないため、 pydot-ng
更新バージョンを取得する必要があるという微妙な点があります。
pip install pydot-ng
Ubuntuのgraphviz
パッケージは、次のように配置されます(他のLinuxディストリビューションでも同様)。
apt install graphviz
MacOS(HomeBrewパッケージシステムを使用):
brew install graphviz
Windowsのインストール手順については、 こちらをご覧ください 。
作業のためのモデルの準備
そのため、モデルを作成しました。 今、あなたは仕事のためにそれを準備する必要があります:
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
compile
関数のパラメーターはどういう意味ですか? loss
は誤差の関数であり、私たちの場合、それはクロスエントロピーです。マトリックスの形でラベルを準備したのは彼女のためでした。 optimizer
-使用されるoptimizer
通常の確率的勾配降下がありますが、Adamはこのタスクで最高の収束を示します。 metrics
-モデルの品質が考慮されるmetrics
この場合、精度、つまり正しく推測された回答の割合です。
カスタム損失
Kerasには一般的なエラー機能のほとんどが含まれていますが、タスクには独自のものが必要になる場合があります。 あなた自身のloss
を作るために、あなたは少し必要です:正解と予測された答えのベクトルを取り、出力ごとに単一の数を生成する関数を定義するだけです。 トレーニングのために、クロスエントロピーを計算する関数を作成します。 何らかの方法でそれを変えるために、いわゆるクリッピングを導入します-ベクトルの値を上下にトリミングします。 はい、別の重要なポイント:非標準のloss
は、基礎となるフレームワークの観点から説明するために必要な場合がありますが、Kerasで対処できます。
from keras import backend as K epsilon = 1.0e-9 def custom_objective(y_true, y_pred): '''Yet another cross-entropy''' y_pred = K.clip(y_pred, epsilon, 1.0 - epsilon) y_pred /= K.sum(y_pred, axis=-1, keepdims=True) cce = categorical_crossentropy(y_pred, y_true) return cce
ここで、 y_true
およびy_pred
はy_pred
テンソルであるため、Tensorflow関数を使用してそれらを処理します。
別の損失関数を使用するには、 compile
関数のloss
パラメーターの値を変更し、そこに損失関数のオブジェクトを渡します(関数のpythonにはオブジェクトもありますが、これはまったく別の話ですが):
model.compile(loss=custom_objective, optimizer='adam', metrics=['accuracy'])
トレーニングとテスト
最後に、モデルをトレーニングします。
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_split=0.1)
fit
メソッドはまさにそれを行います。 ラベルx_train
およびy_train
、バッチbatch_size
、バッチbatch_size
、一度に送信されるサンプルの数、エポックを学習するためのエポックの数(1つの時代はモデルによって1回完全に渡されるトレーニングサンプル)を制限するラベルとともに、トレーニングサンプルを入力として受け入れます検証に与えるトレーニングサンプルの割合はvalidation_split
です。
このメソッドはhistory
返します-これは、トレーニングの各ステップでのエラーの履歴です。
そして最後に、テスト。 evaluate
メソッドは、テスト選択とそのラベルを入力として受け取ります。 メトリックは作業の準備で設定されたため、他に何も必要ありません。 (ただし、バッチのサイズを指定します)。
score = model.evaluate(x_test, y_test, batch_size=batch_size)
コールバック
また、Kerasのコールバックなどの重要な機能についても少し説明する必要があります。 それらを通して多くの便利な機能が実装されています。 たとえば、非常に長い時間ネットワークをトレーニングしている場合、データセットのエラーが減少しなくなった場合、いつ停止するかを理解する必要があります。 英語では、説明されている機能は「早期停止」と呼ばれます。 ネットワークをトレーニングするときに、どのように適用できるか見てみましょう。
from keras.callbacks import EarlyStopping early_stopping=EarlyStopping(monitor='value_loss') history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_split=0.1, callbacks=[early_stopping])
実験を行い、この例で早期停止がどのように機能するかを確認してください。
テンソルボード
Tensorboardに便利な形式のログ保存をコールバックとして使用することもできます(簡単に言えば、Tensorflowに関する記事で説明しました-これはTensorflowログからの情報を処理および視覚化するための特別なユーティリティです)。
from keras.callbacks import TensorBoard tensorboard=TensorBoard(log_dir='./logs', write_graph=True) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_split=0.1, callbacks=[tensorboard])
トレーニングが終了しTensorboard
(またはその過程で!)、 Tensorboard
を起動して、ログを含むディレクトリへの絶対パスを指定できます。
tensorboard --logdir=/path/to/logs
たとえば、検証サンプルのターゲットメトリックがどのように変更されたかを確認できます。

(ところで、ここでは、ネットワークが再トレーニングされていることがわかります。)
高度なグラフ
次に、少し複雑な計算グラフを作成することを検討してください。 ニューラルネットワークには多くの入力と出力があり、入力データはさまざまなマッピングによって変換できます。 複雑なグラフの一部を再利用するために(特に、 transfer learning
ために)、モデルの一部を新しい入力データに簡単に抽出、保存、適用できるモジュラースタイルでモデルを記述することは理にかなっています。
前述のFunctional API
とSequential API
両方の方法を組み合わせてモデルを記述するのが最も便利です。
例としてシャムネットワークモデルを使用したこのアプローチを検討してください。 有用なプロパティを持つベクトル表現を取得するために、同様のモデルが実際に積極的に使用されています。 たとえば、同様のモデルを使用して、顔の写真をベクトルで表示して、類似した顔のベクトルが互いに近くなるようにする方法を学習できます。 特に、FindFaceなどの画像検索アプリケーションはこれを利用します。
モデルの図は図で見ることができます:

ここで、関数G
は入力画像をベクトルに変換し、その後、画像のペアのベクトル間の距離が計算されます。 写真が同じクラスからのものである場合、距離を最小化する必要があり、異なるクラスからのものである場合、最大化する必要があります。
このようなニューラルネットワークをトレーニングした後、ベクトルG(x)
の形式で任意の画像を提示し、この表現を使用して最も近い画像を検索するか、他の機械学習アルゴリズムの特徴ベクトルとして使用できます。
それに応じてコードでモデルを記述し、ニューラルネットワークの一部を抽出して再利用することを可能な限り簡単にします。
まず、入力ベクトルをマップする関数をKerasで定義します。
def create_base_network(input_dim): seq = Sequential() seq.add(Dense(128, input_shape=(input_dim,), activation='relu')) seq.add(Dropout(0.1)) seq.add(Dense(128, activation='relu')) seq.add(Dropout(0.1)) seq.add(Dense(128, activation='relu')) return seq
注: Sequential API
を使用してモデルを説明しましたが、その作成を関数でラップしました。 この関数を呼び出すことでこのようなモデルを作成し、 Functional API
をFunctional API
して入力データに適用することができます。
base_network = create_base_network(input_dim) input_a = Input(shape=(input_dim,)) input_b = Input(shape=(input_dim,)) processed_a = base_network(input_a) processed_b = base_network(input_b)
これで、変数processed_a
およびprocessed_b
は、以前に定義したネットワークを入力データに適用することによって取得されたベクトル表現が含まれます。
それらの間の距離を計算する必要があります。 これを行うために、Kerasは任意の式をレイヤー( Layer
)として表すLambda
ラッパー関数を提供します。 データをバッチで処理することを忘れないでください。これにより、すべてのテンソルには常に追加の次元があり、これがバッチのサイズを決定します。
from keras import backend as K def euclidean_distance(vects): x, y = vects return K.sqrt(K.sum(K.square(x - y), axis=1, keepdims=True)) distance = Lambda(euclidean_distance)([processed_a, processed_b])
さて、内部表現間の距離を取得しましたが、入力と距離を1つのモデルに収集することが残っています。
model = Model([input_a, input_b], distance)
モジュラー構造のおかげで、 base_network
個別に使用できます。これは、モデルのトレーニング後に特に役立ちます。 これをどのように行うことができますか? モデルのレイヤーを見てみましょう。
>>> model.layers [<keras.engine.topology.InputLayer object at 0x7f238fdacb38>, <keras.engine.topology.InputLayer object at 0x7f238fdc34a8>, <keras.models.Sequential object at 0x7f239127c3c8>, <keras.layers.core.Lambda object at 0x7f238fddc4a8>]
models.Sequential
タイプのリストに3番目のオブジェクトがあります。 これは、入力画像をベクトルで表示するモデルです。 それを抽出して本格的なモデルとして使用するには(再トレーニング、検証、別のグラフに埋め込むことができます)、レイヤーのリストからそれを引き出します。
>>> embedding_model = model.layers[2] >>> embedding_model.layers [<keras.layers.core.Dense object at 0x7f23c4e557f0>, <keras.layers.core.Dropout object at 0x7f238fe97908>, <keras.layers.core.Dense object at 0x7f238fe44898>, <keras.layers.core.Dropout object at 0x7f238fe449e8>, <keras.layers.core.Dense object at 0x7f238fe01f60>]
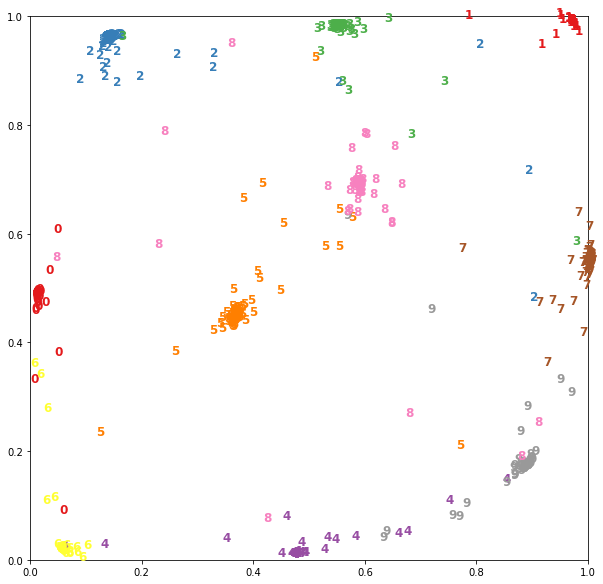
たとえば、 base_model
出力base_model
が2のMNISTデータで既にトレーニングされたシャムネットワークの場合、次のようにベクトル表現を視覚化できます。
データをロードし、 28x28
サイズの画像をフラットベクトルに縮小します。
(x_train, y_train), (x_test, y_test) = mnist.load_data() x_test = x_test.reshape(10000, 784)
以前に抽出したモデルを使用して写真を表示します。
embeddings = embedding_model.predict(x_test)
現在、 embeddings
は2次元のベクトルであり、平面上に描画できます。
おわりに
それだけです、Kerasで最初のモデルを作りました! 彼が提供する機会があなたに興味を持ち、あなたがあなたの仕事でそれを使うことを願っています。
ケラスの長所と短所について議論する時が来ました。 明らかな利点には、モデル作成の単純さが含まれ、これが高速のプロトタイプ作成につながります。 たとえば、 衛星に関する最近の記事の著者はKerasを使用しました。 一般的に、このフレームワークはますます人気が高まっています。
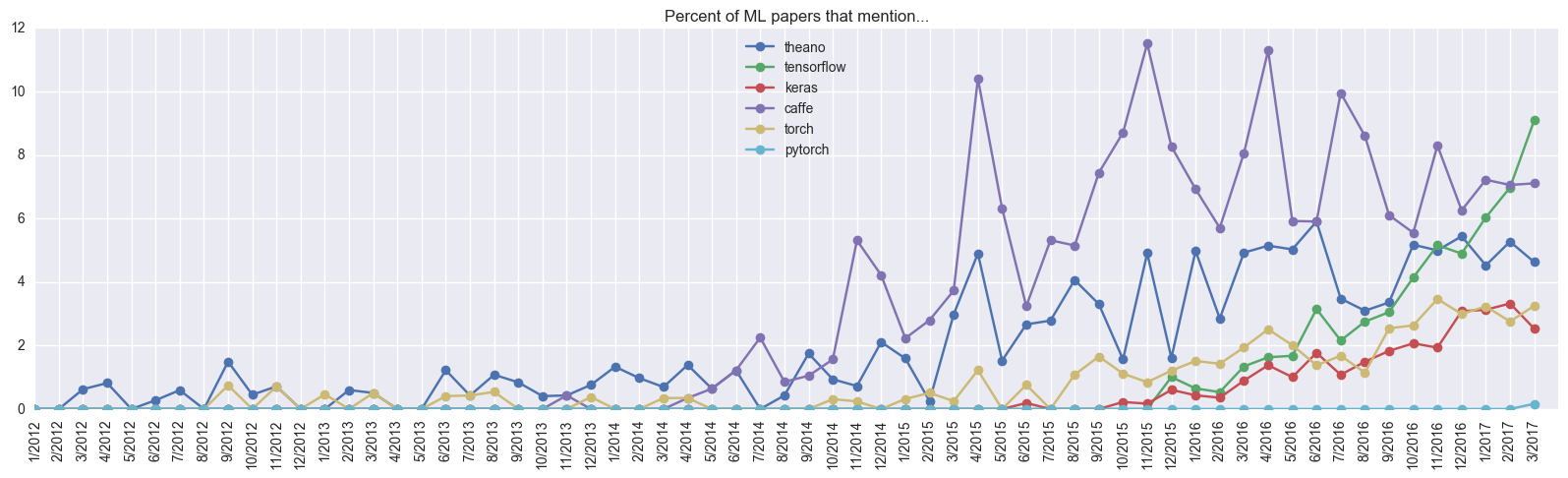
科学記事への言及から判断すると、Kerasは1年でTorchを抜いており、5年間開発中です。 彼の目標-使いやすさ-FrançoisChollet(FrançoisChollet、著者Keras)が達成したようです。 さらに、彼のイニシアチブは見過ごされませんでした:ほんの数か月後、GoogleはTensorflowを開発しているチームでこれを行うように彼を招待しました。 また、Tensorflow 1.2では、KerasはTF(tf.keras)に含まれます。
また、短所についていくつかの言葉を言わなければなりません。 残念ながら、コードの普遍性に関するKerasのアイデアは常に満たされているわけではありません。Keras2.0は最初のバージョンとの互換性を壊しました。 違いは、Kerasの場合、2番目のバージョンのみが開発用に選択されたことです。 また、KerasコードはTheanoよりもはるかに遅いTensorflowで実行されます(ただし、フレームワークは少なくともネイティブコードに匹敵します)。
一般に、特定の問題を解決するためにネットワークを迅速に構築およびテストする必要がある場合、使用するKerasを推奨できます。 ただし、非標準レイヤーや複数のGPUへのコードの並列化など、複雑なものが必要な場合は、基盤となるフレームワークを使用することをお勧めします(場合によっては避けられないこともあります)。
この記事のほとんどすべてのコードは、 ここでは単一のラップトップの形をしています 。 また、 Kerasのドキュメント: keras.io 、およびこの記事の主な根拠となっている公式の例を強くお勧めします。
この投稿は、 Wordbearerと共同で作成されました。