さらに、必要な機器が存在するかどうかを事前に知りませんでした。 そのため、構造が大きく異なるFTPストレージを手動で参照する必要がありました。 現代社会の重要な側面の1つであるインターネット検索の出現につながったのは、この問題です。
 / マリアナ・アバソロ CCによる写真
/ マリアナ・アバソロ CCによる写真
創造の歴史
最初の検索エンジンの作成者は Alan Emtageであったと考えられています。 1989年、彼はモントリオールのマギル大学で働き、故郷のバルバドスから引っ越しました。 大学の情報技術学部の管理者としての彼の仕事の1つは、学生と教師向けのプログラムを見つけることでした。 彼の仕事を促進し、時間を節約するために、アランは彼を検索するコードを書きました。
「FTPサイトをさまよいながら時間をかけてサイトの内容を把握しようとする代わりに、スクリプトを作成してくれました」とアランは言います。
Emtage は、リストをFTPサーバーに埋め込むタスクを自動化する簡単なスクリプトを作成し、それをローカルファイルにコピーしました。 これらのファイルは、標準のgrep Unixコマンドを使用して必要な情報をすばやく検索するために使用されました。 したがって、AlanはArchieと呼ばれる世界初の検索エンジンを作成しました。これは、Archive(Archive)という単語の略語です。
Archieは、数分で世界中の1,000以上のサイトで210万のファイルを検索できました。 ユーザーはトピックを入力する必要があり、システムは名前がキーワードと一致したファイルの場所に関するレポートを提供しました。
この決定は非常に成功したことが判明したため、1990年にEmteijと彼のパートナーであるPeter Deutschがより強力なArchieの商用バージョンを発売する目的でBunyipを設立しました。 Bunyipがインターネットサービスを販売して以来、これは史上初のインターネットスタートアップだったと言えます。
「すべては1日30回の訪問で始まり、1時間に30回、1分でリクエストがありました」 とピーターは言います。 「トラフィックは成長し続けたため、スケーリングメカニズムに取り組み始めました。」
チームは、リストをより効果的なプレゼンテーションにすることを決定しました。 データは個別のデータベースに分割されました。1つはテキスト形式のファイル名、もう1つは階層ホストディレクトリへのリンクを持つレコードです。 他の2つを互いに接続する3番目のベースがありました。 この場合、ファイル名ごとに要素ごとに検索が実行されました。
時間が経つにつれて、他の改善が実装されました。 たとえば、データベースは再び変更されました-圧縮されたツリーの理論に基づいたデータベースに置き換えられました。 新しいバージョンは、ファイル名のリストの代わりにテキストデータベースを形成し、以前のものよりもはるかに高速に動作しました。 マイナーな改善により、ArchieはWebページのインデックスを作成できました。
残念ながら、Archieの作業は中止され、検索エンジンの分野での革命は延期されました。 Emteijと彼のパートナーは、将来の投資に反対し、1996年に辞任することを決めました。 その後、Bunyipクライアントはさらに1年間働き、その後ニューヨークのWebデザイン会社であるMediapolisの一部になりました。 同時に、取得したすべての技術の特許は取得されませんでした。
「しかし、素晴らしい経験を得ました。世界を旅し、会議に参加し、現代のインターネットの外観を形作った人々に会いました」とアランは回想します。 インターネット協会のメンバーとして、彼はティム・バーナーズ・リー、ウィントン・サーフ、ジョン・ポステルのような人々と仕事をすることができました。
マークを残しました
それでも、ArchieはWWWの開発に影響を与えることができました。 特に、ロボットの標準的な例外の出現。 このツールは、サーバーのどの部分にアクセスできないかをロボットに通知するために使用されました。 これを行うために、HTTP経由でアクセスできるrobots.txtファイルを使用しました。
次の形式の情報を含む1つ以上の行が含まれていました 。
<>:< ><>< >
レコード<field>は、User-agentまたはDisallowの2つの値を取ることができます。 ユーザーエージェントは、ポリシーが記述されたロボットの名前を指定し、Disallowは、アクセスが閉じられたセクションを定義しました。
たとえば、このような情報を含むファイルは、すべてのロボットが/ cyberworld / map /または/ tmp /、または/foo.htmlでURLにアクセスすることを防ぎます。
# robots.txt for http://www.example.com/ User-agent: * Disallow: /cyberworld/map/ # This is an infinite virtual URL space Disallow: /tmp/ # these will soon disappear Disallow: /foo.html
この例では、cybermapperを除くすべてのロボットの/ cyberworld / mapへのアクセスを閉じます。
# robots.txt for http://www.example.com/ User-agent: * Disallow: /cyberworld/map/ # This is an infinite virtual URL space # Cybermapper knows where to go. User-agent: cybermapper Disallow:
このファイルは、サイト上の情報にアクセスしようとするすべてのロボットを「展開」します。
# go away User-agent: * Disallow: /
不滅のアーチー
30年ほど前に作成されたArchieは、今回もアップデートを受け取っていません。 そして、彼はインターネットでまったく異なる体験を提供しました。 しかし、今日でも、その助けを借りて、必要な情報を見つけることができます。 まだArchie検索エンジンをホストしている場所の1つは、ワルシャワ大学です。 確かに、サービスによって見つかったファイルのほとんどは2001年に遡ります。
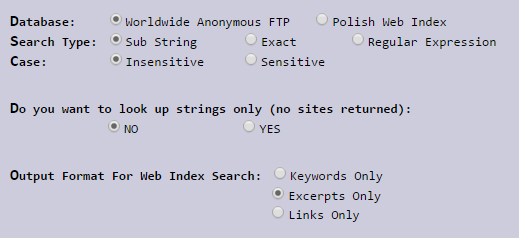
Archieは原始的な検索エンジンであるという事実にもかかわらず、検索をカスタマイズするためのいくつかの機能を提供しています。 データベース(匿名FTPまたはポーランド語Webインデックス)を指定する機能に加えて、システムは入力された文字列を解釈するためのオプションを選択することを提案します:部分文字列として、リテラル検索または正規表現として。 レジスタを選択するためのオプションと、結果を表示するためのオプションを変更するための3つのオプション(キーワード、説明、またはリンク)もあります。
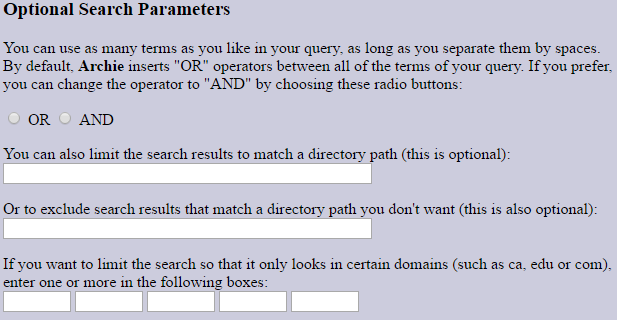
また、必要なファイルをより正確に判断できるオプションの検索パラメーターもいくつかあります。 サービスワードORおよびANDを追加し、ファイル検索の範囲を特定のパスまたはドメイン(.com、.edu、.orgなど)に制限し、出力結果の最大数を指定することができます。
Archieは非常に古い検索エンジンですが、必要なファイルを検索する際にかなり強力な機能を提供します。 ただし、最新の検索エンジンと比較すると、非常に原始的です。 「検索エンジン」ははるかに先を行っています。システムがすでに検索オプションを提供しているため、目的のクエリの入力を開始してください。 使用される機械学習アルゴリズムは言うまでもありません。



現在、機械学習は、GoogleやYandexなどの検索エンジンの主要部分の1つです。 このテクノロジーの使用例としては、検索ランキングがあります。コンテキストランキング、パーソナライズランキングなどです。ランク付け学習( LTR )システムがよく使用されます。
機械学習により、ユーザー入力を「理解」することもできます。 このサイトは、スペルを個別に修正し、同義語を処理し、あいまいさの問題(ユーザーが見つけたいもの、イーグルスグループまたはイーグルスに関する情報)を解決します。 検索エンジンは、URL、ブログ、ニュースリソース、フォーラムなどでサイトを分類する方法と、ユーザー自身がパーソナライズされた検索を作成する方法を独自に学習します。
検索エンジンのGreat祖父
ArchieはGoogleのような検索エンジンを生み出したため、ある程度までは検索エンジンのof祖父と見なすことができます。 それはほぼ30年前です。 今日、検索エンジン業界は年間約7,800億ドルを稼いでいます。
アラン・エムタイについては、逃した金持ちになる機会について尋ねられたとき、彼は謙虚に答えます。 「もちろん金持ちになりたい」と彼は言う 。 「しかし、特許が発行されたとしても、私は億万長者になっていないかもしれません。」 説明を不正確にするのは簡単すぎます。 時々、勝者は最初の人ではなく、最高になった人です。」
Googleや他の企業は最初ではありませんでしたが、競合他社を上回り、数十億ドル規模の産業の設立を可能にしました。
PS IaaSの使用に関する実用的な資料のダイジェスト 。