仮想環境を初めてテストするほとんどの人は間違っています。VMwareに相談することなく、VMwareがそのようなテストの公開をユーザーライセンス契約で禁止している限りでは。 なぜなら、彼らは間違いなくテスト方法論を評価する必要があるからです。
実際、どのアプローチが最初に思い浮かびますか? 仮想マシンを作成し、ディスク、メモリ、プロセッサ、ビデオカードをテストするための一般的なソフトウェアを組み込みます。 そして、すでにその結果は、たとえば物理システムや別の仮想マシンと比較されます。
このアプローチは、予約なしではありませんが、仮想マシンがほぼ常に1であり、それを最大限に活用したい場合、ラップトップまたはワークステーションについて話している場合、生命に対する権利があります-ゲームまたはオフィスアプリケーションを「ブレーキなし」で起動します。
悲しいかな、多くの仮想マシンが存在するサーバーに関しては、このような手法はまったく役に立たない。なぜなら、実際にはそこから結論を引き出すことができないからだ。
なんで?
まず、誰もサーバーを使用して1つの仮想マシンを実行することはありません。ほとんどの仮想マシンは常に存在します。 そして、たとえば、一方が他方を損なうほど高いパフォーマンスを持っている場合(これは、タスクスケジューラの動作が不十分な場合に非常に可能です)、プラットフォームは原則として非常に悪いです-しかし、テストでは表示されません!
第二に、サーバー上の仮想マシンのリソースはほぼ常に制限されています。これは約90%ではなく、サーバーリソースの約数パーセントにすぎません。 同時に、1台、5台、または10台の仮想化仮想マシン上の2つの異なるプラットフォームでも同じ結果が得られます。 これは、システムが同等に良いか悪いかを意味しますか? 絶対に必要ありません! 結局のところ、さまざまなソリューションがさまざまな方法でメモリを操作したり、プロセッサ時間を使用したり、ディスク操作を仮想化したりできます。 また、サーバー上に無料のリソースがある限り、さまざまなプラットフォームの違いは目立ちません。 しかし、実際にはリソースを最大限に使用するための仮想化のポイントであるため、リソースは常に終わります。 そして、彼らが実際の生活の中でより早く終わるという決定はより悪い結果を示しますが、我々はこの方法を見つけることができません。
第三に、ハイパーバイザーには独自の「アキレス腱」セットがあります。特定の負荷パターンでは、それぞれが特に悪い結果を示します。 そのようなパターンに対する負荷がテストを伴うかどうかによって、結果は大きく異なる場合があります。 「必要な」結果(良いか悪いか)を示すテストを選択または作成するのは簡単です。また、有用で客観的な結果をもたらすテストを作成するのははるかに困難です。
紳士の皆さん、どうやってテストしますか?
ただし、Intelアーキテクチャに基づく仮想化はほぼ20年前から存在しており、ベンチマークはこの分野で働く人々にとって新しいトピックではありません。 長年にわたり、このようなテストのための特定の「ゴールドスタンダード」がすでに開発されています。 一部の詳細を省略して、アプローチは次のように定式化できます。
•一般的なサーバーアプリケーションを使用して、複数の仮想マシンのシステムを作成します(これには通常、データベースを備えたサーバー、重いJavaアプリケーションのサーバー、メールサーバー、ファイルサーバーなどが含まれます)。
•これらの各システムのパフォーマンスを特徴付けるこれらのアプリケーションから不可欠なポイントを受け取ります。
•新しい類似システムを追加してポイントを追加する
•構成が等しいポイントの合計によって決定を評価します(違いが1つのパラメーターのみである場合-仮想化システム自体)。
そのようなテストは確かにすべての質問に対する答えを提供するわけではありません。 たとえば、参照ロードのセットはクライアントが実際に必要とするものとは非常に異なる可能性があるため、実際のロードは非常に異なる結果をもたらす可能性があります(仮想化ツールの「アキレス腱」を思い出してください)。 しかし、これは最初に説明した「正面からのアプローチ」よりもはるかに優れています。
Virtuozzoでは、主にクラウドサービスを扱っており、サービスプロバイダー(仮想化プラットフォームメーカーを選択する)だけでなく、顧客の意見を把握しています。 彼が購入した仮想サーバーのパフォーマンスだけが彼にとって重要であるため、彼らはしばしばどの仮想化システムが使用されたか気にしません。 そして、それがどのように達成されるか-生産性の高いハイパーバイザー、生産性の高いハードウェアの助けを借りて、または単に各サーバーに少数のクライアントを配置するだけで-顧客はまったく気にしません。
クライアントの観点から見ると、「デスクトップ」アプローチには存在する権利があります。そのようなテストを試みるプロセッサ、ディスク、およびその他の「オウム」は、購入したサーバーの費用を示しています。 サービスプロバイダーにはあるものが必要で、消費者には別のものが必要であることがわかります。
ゴールデン平均?
しかし、少し前に、パートナー企業であるCloud Spectatorと小さなプロジェクトを立ち上げました。そこで、それを把握する必要がありました。サーバーの仮想化をテストするテストを行うことは可能ですが、クライアントの観点からですか。 アプローチを見つけたように思えます-不完全な場合、完全に存在する権利があります。
参考のため。 Cloud Spectatorは、クラウドサーバーのパフォーマンスをテストし、本質的に「デスクトップ」メソッドにします。1台の仮想マシン内でgeekbenchやfioなどのテストを実行し、長時間(たとえば1営業日で1日)の結果を収集します。 1&1社のクラウドサービスの1つが最高のパフォーマンスを示した同様のレポートを読むことができます。
同様の方法を使用して2つの異なる仮想化プラットフォームをテストした実験では、興味深い結果が得られました。 最初に、テストしたサーバーを「実稼働負荷」にする必要がありました(この負荷を「バラスト」と呼びます)。 その唯一の目的は、サーバーを等しくロードし、「その他の等しい条件」を作成することです。
サーバー自体は最新のプロバイダーにとって非常に典型的なものでした。最高のエンドポイントではありませんが、目標は最大数ではなく、相互に比較できるデータを取得することでした。
CPU:2 x Intel Xeon E5-2620
RAM:64GB(4 x 16GB DDR4-2133 ECC REG)
ストレージ:LSI 9271-8i(8ポートSAS2、1GB)RAID0 over 8 x HGST 450GB 15K RPM
両方のサーバーで同じバラスト負荷を作成するために、以前に実行した別のテストを使用しました。 クライアントが来るWebサーバーの動作をエミュレートします。 通常、このテストでは、次の方法を使用して、物理サーバー上の仮想サーバーの最大達成可能密度を測定します:仮想サーバーの追加、応答速度の測定、および95パーセンタイルが4秒を超えると、達成された最大密度を考慮してテストを停止します。
このテストがさまざまな仮想化システム用に作成したグラフの例を次に示します。
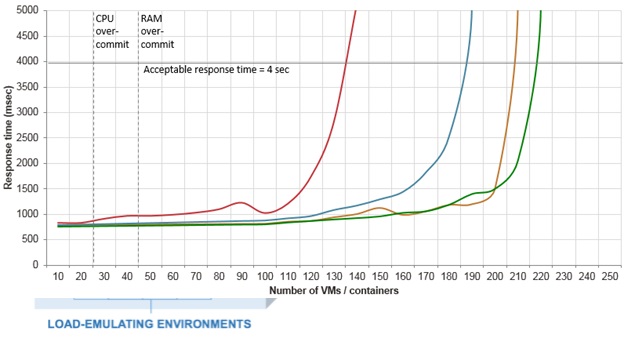
しかし、本日、このテストを別の方法で使用することにしました-仮想サーバーの数を修正し、1秒あたりのリクエストの頻度を変更します。
テストの準備として、両方のホストに同数の仮想サーバー(各50)を作成し、複数のクライアントからそれらを均等にダウンロードし始め、着信要求の頻度を徐々に増やしました。 両方のサーバーが100%に近いCPU使用率を示すようになったとき、そのレベルでバラスト負荷を停止して修正しました(動機-ほとんどのプロバイダーはサーバーにほぼ100%の負荷をかけたいが、クライアントは苦しみません)
さらに、両方のホストで51番目のサーバーを作成し、「クライアントのパフォーマンスビュー」をテストするためにCloud Spectatorに提供しました。 つまり、テストの「スタンド」は次のようになりました。
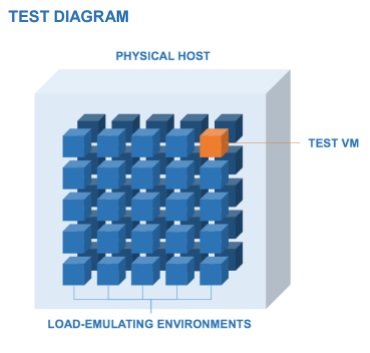
ご想像のとおり、仮想化システムがテスト結果で勝ちました(完全なレポートはこちらのリンクでご覧いただけます)が、この投稿の本質はポイントではありません。 主なことは、クラウドサービスプロバイダーが「他のすべてが等しい」システムパラメーターの1つの変更がクライアントのパフォーマンスレベルにどのように反映されるかを評価できる方法を取得したことです。
興味深い事実...
1.パフォーマンスが低下する可能性があります
テスト中に、興味深い事実を見つけることができました。 たとえば、「バラスト」負荷のわずかな変化が、テストクライアントの重大なパフォーマンス障害につながる可能性があることを学びました。 さらに、それは本当に小さいです-約10-15%の増加は、特定の負荷制限があるため、テスト結果が大幅に悪化するという事実につながり、それを超えると失敗につながります。 これは、安定器の負荷を選択して、ギークベンチのパフォーマンスのグラフです。
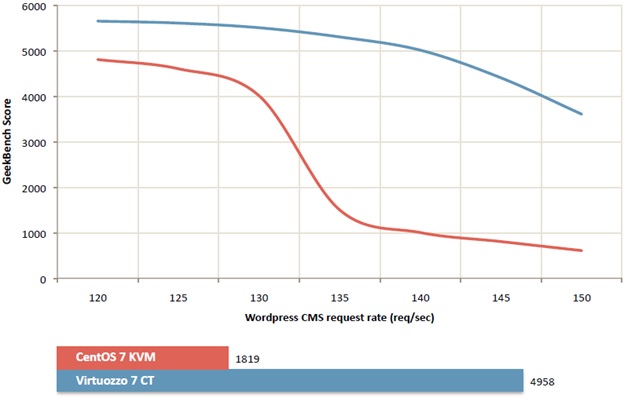
ご覧のとおり、バラスト負荷でのクライアントリクエストの数が1秒あたり約125から135に増加すると、「最初に降伏した」プラットフォームでのテスト環境のパフォーマンスが数回低下します。 このような低下は、1つまたは複数のクライアントの負荷が増加しても再現できません。仮想化のリソース分離により、すべてのリソースを使い果たすことはできません。 しかし、これが多数またはすべてのクライアントで同時に発生した場合、そのようなパフォーマンスの低下は非常に可能です。
これは結論につながります。クラウドサーバーを使用していて、特定の時間にWebサイトが遅い場合(おそらく、プロバイダーが1つのサーバー上に作成したクライアントが多すぎる)、これは「当面」のみ目に見えません。
2.パフォーマンスが必要ですか? 常に測定する必要があります!
これは、クライアントに文句を言わないようにしたいプロバイダーとクライアント自身の両方で行わなければなりません。 実際には、物理サーバーの負荷は1日の異なる時間で異なるため、通常、Cloud Spectatorはサーバーを24時間継続的にテストして、1日の作業サイクル全体をカバーします。 1回のテストではこれで十分かもしれません(もちろん、週末にこれらの24時間が落ちない限り)が、実際の生活では、状況は長期的に変わる可能性があります。 仮想サーバーは、物理サーバーにアクセスする最初のサーバーの1つになります。他のクライアント用のサーバーを作成するまで、すべてが「飛ぶ」ことになります。 周りに「空の」クラウドサーバーがあり、1〜2か月で実際の負荷でいっぱいになる場合があります。 最終的に、休日前にオンラインショッピングシーズンが始まるまで、パフォーマンスは十分です。
3.最後に、「高速で安価」は発生しません。
機器、ネットワーク、データセンター、電気-すべてにお金がかかります。 「標準」とは、最大性能/価格比の機器を使用するなどのコストを最適化する手段であり、ほとんどすべてのプロバイダーで使用されていますが、絞り出すことはあまりありません。 市場よりも安くサービスを販売すると同時にネガティブにならないようにする唯一の方法は、1台のサーバーでより多くのクライアントを実行することです。 しかし、そのようなアプローチは、現在または近い将来、常に生産性を犠牲にして行われます。 したがって、クラウドサービスのパフォーマンスが重要である場合、サービスプロバイダーを選択する際に価格だけが要因であってはなりません。