
Victor Tarnavskyは、それが機能することを示しています。 レポートHighload ++ 2016のトランスクリプトを以下に示します 。
こんにちは。 私の名前はビクター・タルナフスキーです。 私はYandexで働いています。 私たちが開発した分析タスク用の非常に高速で、非常に耐障害性があり、非常にスケーラブルなClickHouseデータベースについて説明します。
私についていくつかの言葉。 私はビクターです。Yandexで働いており、Yandex.MetricaやYandex.AppMetricaなどの分析製品を開発する部門の責任者です。 多くの人がこれらの製品を使用し、知っていると思います。 まあ、過去には、まだ多くのコードを書いていて、それ以前はまだ鉄の開発に関わっていました。
今日はどうなりますか
少し話をします。なぜ私たちが独自のシステムを作成することを決めたのか、どのように現代世界でどんな問題にも解決策があるような生活にたどり着いたのか、まだ独自のデータベースを作成する必要がありました。 次に、ClickHouseに現在備わっている機能、その構成、使用できる機能について説明します。 その後、もう少し詳しく説明して、ClickHouse内で行った決定とその構成、およびClickHouseが非常に高速に機能する理由を説明します。 最後に、ClickHouseが個人またはあなたが働く会社にどのように役立つか、どのタスクを使用する価値があるか、ClickHouseで構築できるケースを示したいと思います。
ちょっとした歴史
すべては2009年に始まりました。 次に、Web分析ツールであるYandex.Metricaを作成しました。 つまり、サイトの所有者または開発者が自分のサイトに置くようなツールです。 これはJavaScriptの一部であり、Yandex.Metricaにデータを送信します。 次に、「メトリック」で統計を見ることができます:サイトに何人いたか、何をしていたか、冷蔵庫を買ったかどうかなど。
そして、ウェブ分析システムの開発の観点から-これはいくつかの挑戦です。 1つのサービスまたは製品を開発する場合、この1つのサービスまたは製品の一部のRPSおよびその他のパラメーターに耐えるように負荷を設計します。 また、Web分析ツールを開発する場合、Web分析ツールが存在するすべてのサイトの負荷に耐える必要があります。 そして、「メトリック」の場合-それは非常に大規模であり、毎日数百億のイベントが発生します。
Metricaは、数百万のWebサイトに基づいています。 毎日何十万人ものアナリストが座って、Metricsインターフェースを調べ、レポートを要求し、フィルターを選択して、Webサイトで何が起こっているのか、この冷蔵庫を買ったのか、何が起こっているのかを理解しようとします。 外部データによると、Metrikaはこの市場で3大プレーヤーの1つであるシステムです。 つまり、私たちが所有しているサイトの数、およびMetrikaが見ている人の数はトップからの製品であり、実際には大規模な製品はありません。
2009年、Metrikaは次のようにはなりませんでした。
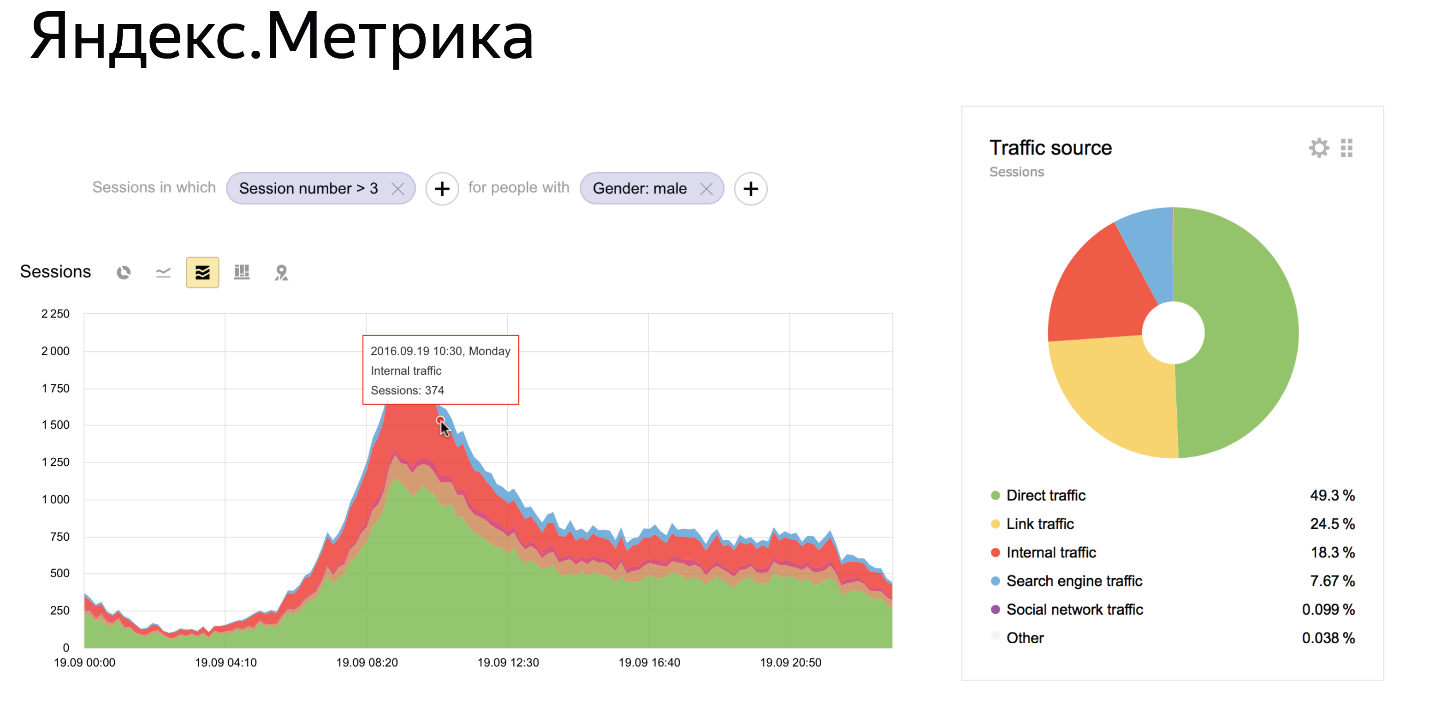
これが彼女の現在の状態です。 Metricには多くのことがあることがわかります。 レポートを作成できるダッシュボードがあります。 何かをリアルタイムで構築できるグラフがあります。 任意のスライスのデータを表示できる高度なフィルターシステムがあります。 たとえば、女の子だけ、またはジンバブエから来た人だけのデータを見るには-そのようなものです。
問題が発生します-これらすべての機能を実現するためにデータを保存する方法は?
そして2009年、私たちは集約されたデータの「古典的な」アプローチの世界に住んでいたといわれています。 どのように見えますか?
性別ごとにレポートを作成するとします。 ご存知のように、世界には男性、女性、「定義されていない」の3つの性別があります。これは、人の性別を理解できなかったときです。 お気に入りのデータベースを取得し、性別を含む列を作成し、3つの値のいずれかを列挙し、グラフを作成する必要があるため日付を含む列を作成し、考えられる指標(人数、イベント数)を含む列を作成します、たとえば、サイトへの訪問、購入した冷蔵庫の数など。 このようなラベルは、たとえば、Cronで1日に1回、MySQLで新しい行を再カウントして記述すれば、すべてが正常に機能します。
2009年、私たちはそのようなパラダイムに住んでいました。 したがって、実際に行ったレポートごとに、実際に新しいテーブルを作成しました。 また、「メトリック」の場合、事前に集計されたキーが異なる50以上の類似した異なるテーブルがありました。 私たちのシステムはかなり複雑でした。 これをリアルタイムで行うことができました。 どんな負荷にも耐える方法は知っていましたが、それでも意味は変わりませんでした。
このアプローチの問題は、このデータ構造の上にそのようなインターフェースを実装することが不可能であることです。 たとえば、男性の性別などの日付で4台の冷蔵庫が購入されたことをタブレットに書き留めた場合、これらのデータをフィルターで除外することはできません。 そのため、時間の経過とともに、非集約アプローチの概念に到達しました。
これは次のとおりです。 非常に幅の広いソースイベントテーブルを少数保持しています。 たとえば、「Metrics」の場合、これらはページビューです。 1行は1ページビューを意味し、1ページビューには多くの異なる属性があります。性別、年齢、購入した冷蔵庫の有無、その他の列です。 私たちの場合、ビューでは、各ビューに500以上の異なる属性を記録します。
このアプローチで何ができますか? このようなデータモデルの上にレポートを作成できます。 すべてのパラメーターがあるため、データは任意に計算できます。 少数のテーブルが判明します。「メトリック」の場合、片手で数えることができますが、非常に多数の列があります。
このアプローチの問題
このような広くて長いテーブルを可能にするデータベースが必要です-集約されたデータよりも長くなることは明らかなので、すぐにクエリを読み取ります。
DBMSの選択
これが2009年の主な問題でした。 その後、私たちはすでに独自の実験を行いました。 このようなシステムがあり、All Upと呼びました。 すでに非集計データがあり、誰かが古い「Metric」を覚えていれば、いくつかのフィルター、測定値を選択して任意のレポートを作成できるレポートデザイナーがいました。 彼はこのAll Upシステムのすぐ上にいました。 彼女は十分にシンプルで、多くの欠点がありました。彼女は十分に柔軟性がなく、十分に速くありませんでした。 しかし、彼女はこのアプローチが原則として適用可能であることを理解してくれました。
私たちはベースを選択し始め、自分自身にいくつかの要件を形成しました。 ほぼ次の要件のリストがあることがわかりました。

もちろん、できるだけ早くリクエストを処理する必要があります。 製品の主な利点は、大量のデータに対するクエリを可能な限り迅速に実行できることです。 データをすばやく読み取ることができるサイトが大きいほど、より良い結果が得られます。 パターンを理解できるように、人は「メトリック」のインターフェイスを見て、いくつかのパラメーターを変更し、フィルターを追加します。 彼はすぐに結果を取得したい、彼は明日または彼に来るまで30分まで待たない。 これらのクエリを数秒で実行する必要があります。
リアルタイムのデータ処理が必要です。 このリクエストのレベル、人が座ってすぐに結果を確認したい場合、およびサイトで冷蔵庫を購入してから、サイトの所有者が人がこの冷蔵庫を購入したことを確認するまでの時間の両方で。 これは非常に重要な利点でもあります。たとえば、いくつかのニュースをリリースし、成長の速さをすぐに見たいニュースサイトにとっては。 このデータをリアルタイムでデータベースに挿入し、同時にそこから新しい結果と集計データを取得できるシステムが必要です。
ペタバイトのデータがあるため、保存する機能が必要です。 「メトリック」は非常に大きく、ボリュームはペタバイト単位で測定されます。 すべての拠点がそのように拡張できるわけではありません。 これは私たちにとって非常に重要なパラメーターです。
データセンターの観点からの耐障害性。 それはどういう意味ですか?
私たちはロシアに住んでいて、多くのことを見てきました。 時々、トラクターが到着し、データセンターにつながるケーブルを掘り出します。そして、まったく予期せず、掘削機が到着し、100 km離れた他のデータセンターでバックアップケーブルを掘ります。 そしてまあ、私はそのように冗談を言っていた場合。 しかし、本当にそうでした。 時々、猫が変圧器にintoい込むと、爆発します。 時々met石がクラッシュし、データセンターが破壊されます。 一般的に、すべてが起こります-データセンターはオフになっています。
Yandexでは、すべてのサービスが生きるような方法で設計されています。データセンターがオフになっても、製品の特性が低下することはありません。 データセンターのいずれかが切断される可能性があり、サービスが存続する必要があります。 Metrikaのデータベースレベルでは、ペタバイトのデータを保存してリアルタイムで処理するために、以前のポイントを考慮すると特に困難なデータセンターのクラッシュに耐えられるデータベースが必要です。
Metricaは複雑な製品であり、さまざまな組み合わせ、レポート、フィルター、その他すべてがあるため、柔軟なクエリ言語も必要です。 言語が何らかの集約API MongoDBのように見える場合-誰かがそれを使用しようとした場合、この言語は私たちには合いません。 使いやすい何らかの言語が必要なので、これが私たちにとって重要な基準の1つでした。
それからそれはどうでしたか? 市場には何もありませんでした。 これらの5つのパラメーターのうち最大で3つを実装したベースを見つけることができました。そこには多少の広がりはありましたが、約5つは言葉すらありませんでした。 私たちは、All Upシステムを作成する過程にあり、自分でそのようなシステムを構築できるように思われることに気付きました。 プロトタイピングを開始しました。 システムをゼロから作成し始めました。
新しいシステムを作成するときに追求した主なアイデアは、最初はSQLである必要があることは明らかでした。 その柔軟性は私たちのタスクに十分だからです。
SQLが拡張可能な言語であることは明らかです。SQLにいくつかの機能を追加したり、スーパーベルやホイッスルを追加したりできるためです。 これは、エントリのしきい値が低い言語です。 すべてのアナリストとほとんどの開発者はこの言語に精通しています。
線形のスケーラビリティ。 線形とはどういう意味ですか? 線形とは、何らかのクラスターがあり、そこにサーバーを追加した場合、サーバーの数が増えたため生産性が向上することを意味します。 しかし、十分な拡張性を備えていない、より一般的なシステムを使用すると、サーバーを追加し、すぐにクラスター全体に要求を送信し、パフォーマンスが向上しないことが簡単にわかります。 A.
同じ場合は幸運ですが、ほとんどの場合、時間の経過とともに低下します。 これは私たちには適していません。
最初に、私たちが言ったように、これが私たちの主な機能であるため、高速クエリの実行に焦点を合わせてシステムを設計しました。 システム設計の観点から、最初から、これが列指向の列ソリューションであることが明らかでした。 すべてのニーズをカバーするために、必要なものすべてを実現できるのはマルチソリューションソリューションだけです。
そして、私たちはプロトタイプを作り始めました。 2009年には、いくつかの簡単なことを行うプロトタイプがありました。
2012年に 、制作の一部をClickHouseに翻訳し始めました。 ClickHouseの上で動作を開始した生産要素が登場しました。
2014年 、ClickHouseは、新しい世代の製品を作成できるところまで成長したことに気付きました。 ClickHouseの上にあるMetrica 2.0で、データのコピーを開始しました。
これは非常に簡単なプロセスです。誰かが2ペタバイトをある場所から別の場所にコピーしようとした場合、これは非常に簡単ではありません-フラッシュドライブではできません。
2014年12月 、ClickHouseの上に新しいMetricaをリリースしました。これは、直接的なブレークスルー、セグメンテーション、一連の機能であり、これらはすべてこのベースの上で機能しました。
数か月前の 6月、ClickHouseをオープンソースに投稿しました。 ニッチがあり、すべてがまだ市場にあることに気付きました。 「市場には何もない」というサイトがありましたが、今でもこの状況に近づいており、ほとんど変更されていません。 このタスクのための市場にはあまり良いソリューションはありません。 私たちは時間通りになっていることに気付きました-オープンソースに入れて、人々に多くの利益をもたらすことができるようになりました。 現在、多くのタスクの解決は非常に不十分ですが、ClickHouseはそれらを非常にうまく解決しています。
それはどういうわけか爆発で起こった。 もちろん、私たちはオープンソースを投稿したという事実から大きな効果を期待していました。 しかし、起こったことは私たちの期待をすべて上回りました。 それ以前には、ClickHouseで実装された多くのYandexプロジェクトがありましたが、今すぐ投稿すると、どこでも私たちについて書いてくれました。
彼らが私たちについて書いていないところ:HackerNews、すべての専門出版物。 たくさんの大企業が、新しいソリューションについて、私たち、たくさんの中小企業に尋ね始めました。 誰かがすでにそれを試みましたが、現時点では、ClickHouseが使用しているようなステータスです。Yandex以外の100以上の異なる企業です。 いくつかの既製のプロトタイプの段階で、またはすでに生産中です。 実稼働でClickHouseを直接使用し、ClickHouseの上にサービスの一部を構築する企業があります。
GitHubで1,500個の星を獲得しましたが、これは古いスライドで、現在1,800個あります。メトリックはまあまあですが、念のため、Hadoopには2,500個の星があります。 ほら、レベル。 間もなくHadoopを追い越します。それから、何か話すことがあると思います。
実際、現在多くの活動が行われています。 あらゆる種類のmitapの配置を開始し、それらを配置します。
機会は何ですか
私は何について話しているのですか?
線形スケーラビリティは、同様のソリューションと比較してClickHouseの非常に重要な利点です。 すぐに使用できるClickHouseは直線的にスケーリングでき、非常に大きなクラスターを構築でき、すべてがうまく機能します。 たとえば、私たちと非常にうまく機能するからです。 ペタバイトのデータ-ClickHouseでペタバイトのクラスターを構築することは問題ではありません。 クロスデータセンターはそのまま使用できます。このために何もする必要はありません。元々はクロスデータセンターソリューションとして考えられていました。 当社では、Yandexは主にこのようなクラスターを使用しています。
高可用性とは、データ、および一般的にクラスターが常に読み取りおよび書き込みに使用できることを意味します。 この意味で、ClickHouseはそのようなコンストラクターです。必要な保証があればクラスターを構築できます。 データセンターの落下に耐えたい場合-典型的なケースでは、3つのデータセンターに複製係数x2のクラスターを配置します。 ソリューション(データセンターと1つのノードの落下に耐えるクラスター)を構築する場合、これは通常、x3レプリケーション係数を取得し、少なくとも3つのデータセンターに基づいて構築する必要があることを意味します。 これはかなり柔軟なシステムです;方法を知っていれば、保証を構築できます。
データ圧縮。 ClickHouseはWebベースのシステムであり、それ自体はデータ圧縮が非常にうまく機能することを意味します。 ソリューションの意味は1つであるため、1つの列からのデータは実際にはハードディスク上の1つのファイルに格納され、同じことを言えば非常に効率的に圧縮されます-そして、行ごとに格納すると、すべてがそこに行き、十分に圧縮されますひどく。
ClickHouseはこのトピックでかなり多数の最適化を使用しているため、データは非常によく圧縮されています。 通常のデータベース、Hadoop、または他の何かと比較すると、違いは数十倍から数百倍まで簡単です。 通常、これには問題があります。ClickHouseを試して、そこにデータをロードし、占有しているスペースを調べます。「すべてをダウンロードしていないと思います」など、すべてをロードしているように見えました。 実際に非常に効果的な圧縮-人々はこれを期待していません。
Yandex.Metricaクラスターの例:

いくつかのクラスターがあります-これはそれらの中で最大です。 現在、3ペタバイト、3.4か何かがあります-スライドは古く、412で、現在420のサーバーがあります。 ゆっくりと増やしています。 このクラスターは、さまざまな国の6つのデータセンターに分散しています。 複雑な構成にも関わらず、クラスターには存在する間ずっとダウンタイムの単位があります。 これは非常に小さく、信じられないほどの数の9です。 これは明らかに、バグの数が最も多いClickHouseの最新バージョンをアップロードするたびに、どうやら必要な保証を提供することを止めるわけではないという事実にもかかわらずです。
これは、このソリューションが問題なく24時間年中無休で機能することを示しています。 はい、Metrikaは年中無休で稼働しており、メンテナンス期間はありません。
お問い合わせ
はい、SQLはサポートされています。 基本的に、SQLがClickHouseに何かを尋ねる唯一の方法です。 厳密に言えば、これはSQLの方言です。これは、標準とは多少の違いがあるためですが、ほとんどの場合、何らかのSQLクエリを作成すれば、ほとんどの場合うまく動作します。 精度を犠牲にできる近似計算のためのさまざまな追加機能がありますが、リクエストはより速く動作するか、メモリに収まります。 たとえば、URLのように、さまざまなデータ型にはさまざまな関数があります-もちろん、Yandex.Metricaには多くのURLがあり、URLを操作するための非常に多くの関数セットがあります。ドメインを引き出したり、パスやパラメーターを展開したりできます。 各データタイプには、多数の関数セットがあります。 メトリックにはおそらく多種多様なデータがあり、ほとんどすべてのタイプのデータについて、ほとんどすべての可能性があります。
配列とタプルはそのまま使用できます 。 これは、列の1つが列ではなく配列になるプレートを作成できることを意味します。 たとえば、多数の数値などの単なる配列でも、タプル(複数のフィールドの複雑な構造を持つ配列)でもかまいません。 配列のサポートはクエリレベルで機能します。ベーススキーマレベルでは上から下まで、配列を操作するための多くの機能があり、それらを効果的に操作できます。 たとえば、この配列の残りのデータを乗算したり、配列から情報を抽出したりできます。 特別なラムダ構文もあり、それを使用して配列にマップしたり、配列にフィルターをかけたりできます。
箱から出して、すべてのリクエストは分散された方法で機能します。何も変更する必要はありません。別のプレートを指定する必要があります。それを配信する先は、クラスター全体のレベルで動作します。
外部辞書などの機能もあります。 そのような機会、私は少し別々に言いたいです。 開発したとき、「Metric」で問題を解決しました。おそらく80%が参加しました。 彼らは存在しなくなった。 ポイントは何ですか? メインデータプレートがあり、その中にいくつかの識別子があるとします-これが何らかのクライアントの識別子であるとします。 この識別子をクライアントの名前に変換する別のディレクトリがあります。 非常に古典的な状況。 プレーンSQLではどのように見えますか?
結合を行います-その結果、名前を取得したい場合は、正しい結合を行い、IDを名前に変換します。 ClickHouseでは、設定内の非常に単純な構文を使用して、このテーブルを外部辞書として接続できます。その後、リクエストレベルで、この識別子を値に変換する関数を指定することができます。リモートテーブル。
これはどういう意味ですか? つまり、メインテーブルから選択を行う場合、たとえば、識別子のセット5-これらの識別子を何らかの種類の復号化に変換することは、1つの機能の問題です。 結合を介してこれを行った場合、5〜6個の結合が行われ、ひどく見えます。 さらに、外部辞書は、MySQL、ファイル、ODBCをサポートするデータベース(PostgreSQLなど)から接続できます。 これにより、これらの名前が何らかの方法で更新され、要求レベルですぐに取得されます。 信じられないほど便利な機能。
クエリの例:
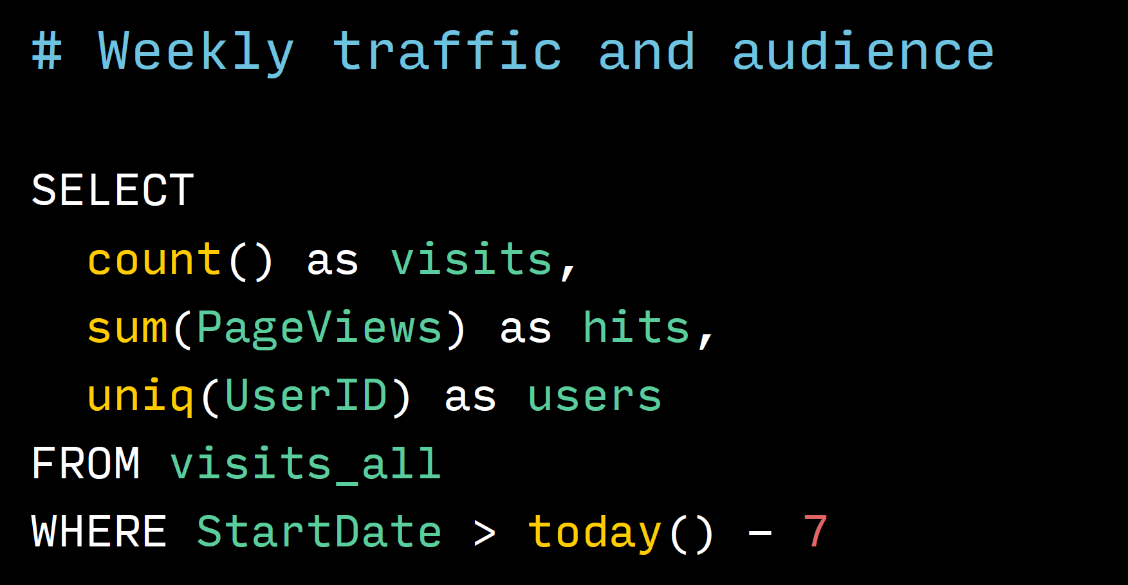
これは、トラフィックとオーディエンスのサイズ、つまり、Metricsクラスターからの週あたりのユーザー数を取得するリクエストです。 このクエリは非常に単純なプレーンSQLであることがわかります。 ここには特別なことは何もありません。アスタリスクなしでカウントのみが記述され、それが可能な場合はアスタリスクが付いていますが、私たちはそのような記述に慣れています。
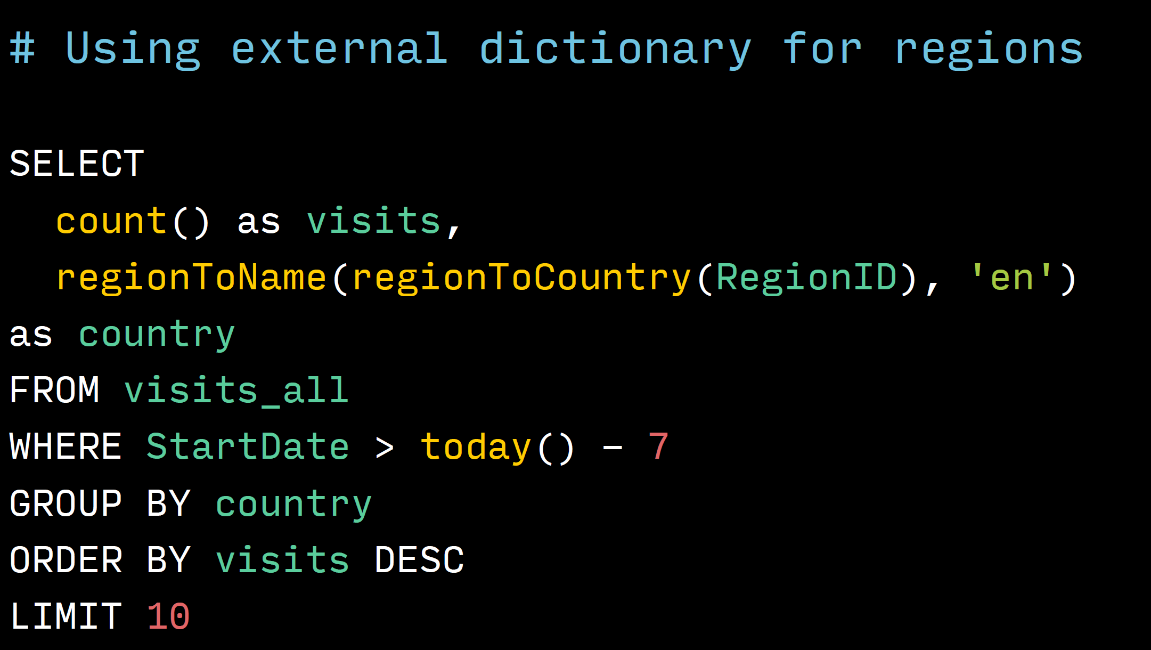
これは外部辞書の使用例です。 この行のregionToName行がどこにあるかを見ると、RegionID-人がいた地域の識別子を変換します。 まず、彼がいた国の識別子。 地域から国へ、そして英語で国の名前へのディレクトリがあります。 ご覧のとおり、これは2つの関数の呼び出しであるため、非常に明確で非常にシンプルに見えます。 従来のSQLでは、これは2つのJOINになり、クエリはこのスライドに収まらず、3つのスライドに分割する必要があります。 作業が大幅に簡素化されます。
スピード
ClickHouseの最も重要な機能は速度です。 速度は信じられないほどです。 ClickHouseがどのように機能するかについて、誰もが期待していると思います。 彼らは彼らの期待で私たちのところに来ます-ここであなたはいくつかの期待を持っています。 最も可能性の高いClickHouseはあなたの期待を超えています-これは私たちに来るすべての人々に当てはまります。
通常、データは通常の(非ソリッドステート)ハードドライブに保存されますが、Metrikaクラスターの規模でさえ、通常のクエリは1秒よりも速く動作します。つまり、1秒未満でペタバイトです。
従来のデータベースと比較すると、Hadoop、MySQL、PostgreSQLに比べて数十万倍の利益が得られます。 数十万倍高い結果が得られます。 これは現実です-ベンチマークがあります。後で紹介します。

毎秒10億行までのクールな数値-ClickHouseは単一のノードを処理できますが、これは非常に多くのことです。 Metricsクラスターの規模では、1つのリクエストが1秒あたり最大2テラバイトを処理できます。 あなたは2テラバイトが何であるか想像できます-これらはそのようなハードドライブです、今では2テラバイトしかなく、干渉することができます、彼らは4TBですが、それほど頻繁ではありません。 そして、1秒あたり、この量の情報はMetricsクラスターによって処理されます。
そして、ポイントは何ですか? この速度がなぜそんなに重要なのか
おおまかに言って、それが重要です:

これにより、アプローチが完全に機能するように変更されます。 特に、アナリストやデータサイエンスを掘り下げている人々のために。 これは今流行です。
通常はどのように機能しますか
たとえば、Hadoopや何らかのMapReduceの従来のシステムにリクエストを送信します。 リクエストを行い、[OK]をクリックし、マグカップを持ってキッチンに行きます。 そしてキッチンで、彼らはそこで誰かと浮気し、誰かとコミュニケーションを取り、30分後に戻ってきて、リクエストはまだ満たされているか、すでに満たされていますが、幸運だけです。
ClickHouseの場合、彼らはClickHouseへの切り替えを開始し、次のようになります。リクエストを入力し、Enterを押し、マグカップを取り、リクエストが既に完了したことを確認します。他の人は、そこで何かが間違っていることを既に見ていて、それも実行されているため、何度もリクエストを繰り返し、ループに入ります。
これにより、データを操作する方法が完全に変更され、すぐに結果が得られます-まあ、文字通り数秒で。 これにより、膨大な数の仮説を非常に迅速にテストし、データなどをある角度から別の角度で見ることができます。 研究作業を行うことは非常に高速であり、非常に迅速に発生したインシデントを調査しています。
社内でもこれに問題があります。 アナリストは、Metricsクラスターまたは他のクラスターなどのClickHouseを試します。 それから、彼らはある種の感染症に感染し、Hadoopまたはある種のMapReduceに行き、それを使用することができなくなります。 彼らはすでに異なった考え方をしています。 彼らは歩き回り、全員に次のように伝えます。 「ClickHouseにデータが欲しい。 ClickHouseですべてが必要です。」
実際、ClickHouseは厳密に言えば、MapReduceが解決するすべての問題を解決するわけではありません。MapReduceはわずかに異なるシステムですが、一般的なタスクではClickHouseは非常に高速に動作し、データの処理を実際に変更します。
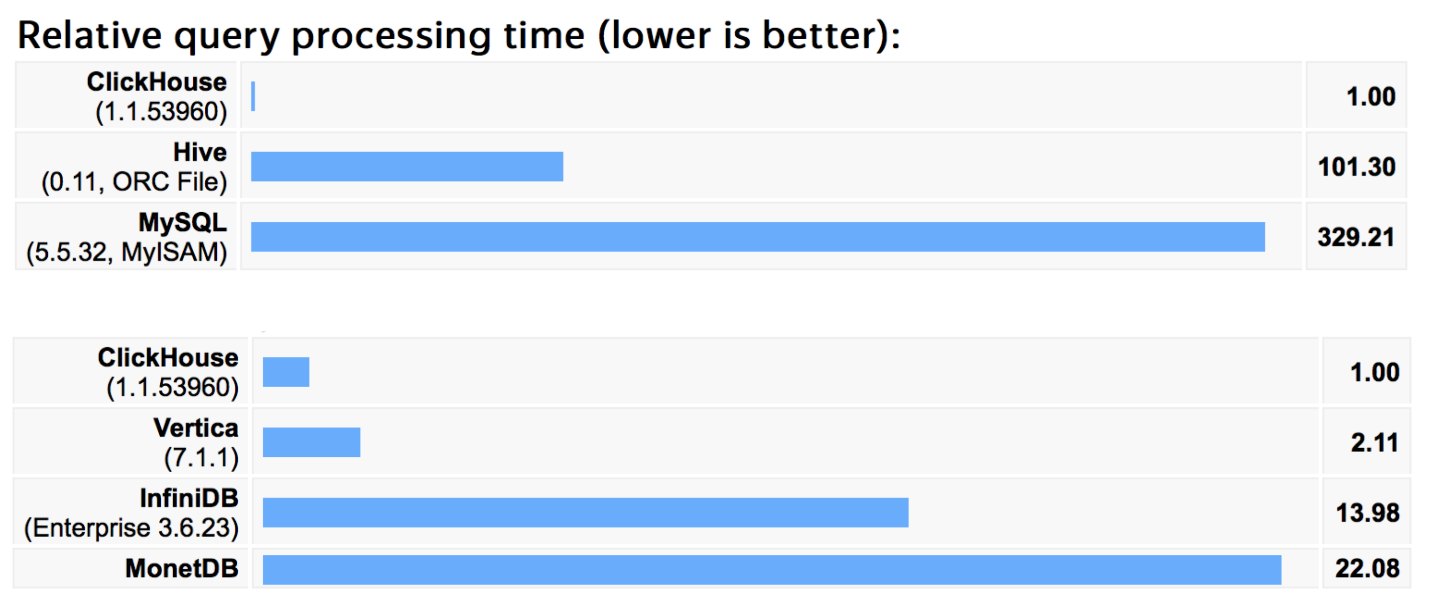
根拠がないように、いくつかのベンチマーク。1年前に、Yandex.Metricaの10億行でこれらのベンチマークを実行しました。このベンチマークにあったリクエストは異なります。基本的に、これらは私たちがメトリックで使用するクエリであり、通常の分析クエリです。グループクエリを選択し、かなり複雑またはかなり単純な、約100個のクエリのセットを選択します。
私たちのデータでは、結果はHiveやMySQLと比較するとほぼ同じです。一部の古典的なソリューションでは、数百回の違いがあります。先ほど言ったように、完全ではなく、完全に調整されていないためです。
以下に、より現実的な競合他社があります。同じ問題を解決する基盤であり、私たちが試した中で最もクールなのはVerticaであることがわかります。 Verticaは、非常に優れたデータベースであり、適切に設計され、適切に記述されており、非常に高価です。
私たちの測定によると、ClickHouseは2年前にこれらのベンチマークで2倍高速でした。それ以来、多くのことを最適化しました。
リンクの詳細:https : //clickhouse.yandex/benchmark.html
このリンクはエラーではありません-実際、ClickHouse.yandex。それ以上のことはありません-Yandexは.yandexドメインを購入しました-非常にクールに見えますが、かなりの費用がかかりますが、おそらくそれがかかります。一般的に、あなたは誤解されません。
インターフェース
ClickHouseで異なる方法で作業できます。優れたコンソールクライアントがあります。非対話型モードで動作できるため、高速作業に非常に便利で、高速自動化に便利です。スクリプトの場合、これは非常に便利です。デフォルトのプロトコルはHTTPであり、これを使用して、データの要求、データのダウンロードなど、すべてを実行できます。何でも。
HTTPの上に、JDBCドライバーがあります。これはオープンソースにもあります。Java、Scala-あらゆる環境で使用できます。また、人々はすでにさまざまな言語用のさまざまなコネクタを作成しているので、それを使用することもできます。お気に入りの言語に対応するコネクタがない場合は、もちろん-それを書くと、人々は再び喜ぶでしょう。
少し内側
まず、最も重要な質問に答えたいと思います。「ClickHouseはなぜこんなに高速なのですか? 魔法とは何ですか?なぜそうなのですか?」いくつかの答えがあります。まず、コードの観点から、既に述べたように、最初にソリューションを設計し、パフォーマンスに合わせて最大限に調整しました。したがって、そこにあるすべてのコードは可能な限り最適化されます。
機能が作成されると、パフォーマンステストが常に実行され、この機能をさらに最適化できるかどうかがチェックされます。そのため、ClickHouseには低速実行機能がなくなりました-誰もが理にかなった範囲で可能な限り高速に動作します。ベクターデータ処理も使用されます-これは、データが行ごとに処理されることはなく、列によってのみ処理されることを意味します。数字の列がある場合-合計に数字を書き、数字の大きな配列を取り、クールなSSE何かの命令を適用すると、すべてがすぐに加算されます。これにより、処理を大幅に高速化できます。
データの観点から-もちろん、列ソリューションは非常に効率的に機能します。なぜなら、すべての列ではなく、必要なデータのみを要求するからです。 Merge Treeは、なじみのない人が使用します。データを保存するためのすばらしい構造であるWikipediaを読んで、ClickHouseで使用します。これは、データが限られた数のファイルで保証された少数のファイルにあることを意味します。したがって、ハードディスク上のシークの観点から見ると、それらの数は最小限になります。一般的に、ClickHouseはハードドライブを使用するために最適化されています。「Metric」ではハードドライブを使用するため、SSDに大量のデータが収まらないためです。
データ処理は、このデータに可能な限り近いところで行われます。リモートリクエストがある場合、ClickHouseは、いくつかの集計と少量の情報をネットワーク経由で転送するために、データに近い最大量の作業を試みます。これは、特に、ClickHouseがデータセンター間環境でうまく機能する理由の1つです。これは、ネットワークを介して送信されるデータが少ないためです。
また、必要に応じて、ClickHouseがすぐに動作してクエリを高速化する機能がいくつかあります。
サンプリングがあります。
これは次のように機能します。リクエストが十分に速く動作しない場合、すべてのデータではなく、リクエストに対して10%または1%を計算できます。これは調査作業に必要です-データを調査したい場合、通常1%で実行でき、約100倍高速に動作します。とても快適です。
確率的アルゴリズムを備えた関数があります-速度と精度の間で何らかの妥協を選択できます。たとえば、この特定の要求を処理するスレッドの数を選択するなど、要求レベルでパラメーターを編集する機能があり、柔軟性が向上します。
スケーラビリティと復元力
ここで、ClickHouseはそのような完全に分散したシステムであり、これらの要求を受け入れる単一のポイントはなく、何が起こっているのかを何らかの形で規制する単一のポイントはないと言う必要があります。
非同期複製がデフォルトです。これは、何らかの種類のレプリカにデータを書き込んでおり、いつか別のレプリカにコピーされることが保証されることを意味します。さて、非同期レプリケーションはどのように機能しますか?ClickHouseの観点では数秒ですが、実際には、必要に応じてすべてを同期的に実行できるモードがあります。通常、これは必要ありません。
飼育係アクションの同期、リーダーの選出、その他の操作に非常に積極的に使用されます。 ZooKeeperはRPSに耐えられないため、リクエスト中は使用されません。一般に、彼は能力がありますが、これにより追加の遅延が発生しますが、内部では非常に積極的に使用されています。
Yandex.Metricaクラスターの例:
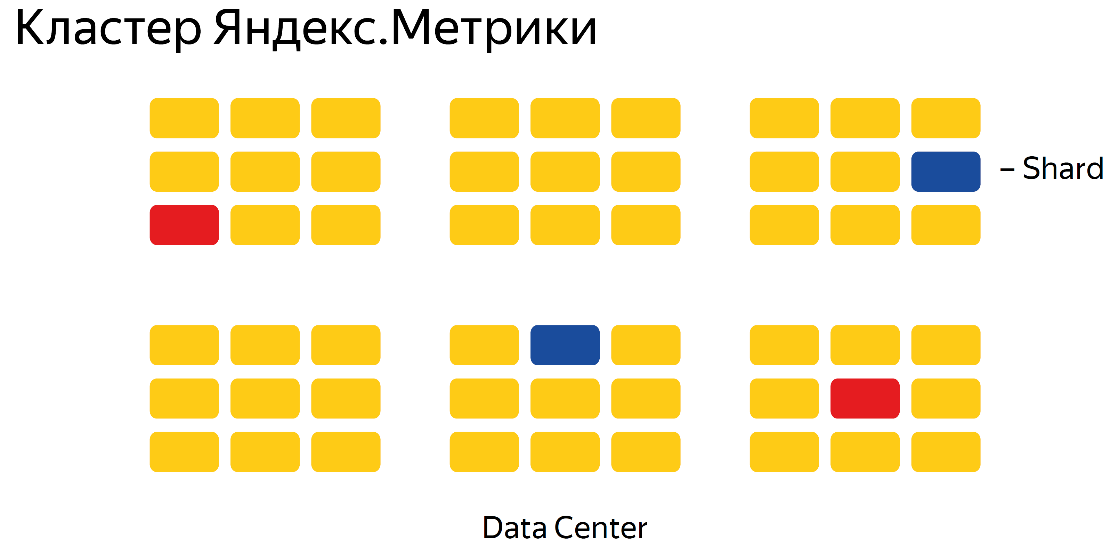
6つのデータセンターがここに示されています。 1つの破片は青色で描かれ、これらは2つのコピー、x2レプリケーションファクターです。データは2つのデータセンターに平等に配置され、すべてが非常に単純です。複製係数がx3の場合、3個の青と赤の正方形があります。
最も興味深いこと。 ClickHouseはどのように使用できますか?
ClickHouseを使用する必要がない方法から始めたいと思います。顕微鏡で釘を打たないでください。 ClickHouseはOLTPソリューションではありません。つまり、次のことを意味します。何らかのトランザクション性が必要な場合、データベース上で何らかのビジネスロジックを実行する場合は、ClickHouseを使用しないでください。 PostgreSQL、MySQLなど、お好きなクラシックソリューションを使用してください。 ClickHouseは、分析、研究、およびリアルタイムレポート用のデータベースです。 ClickHouseはキーと値のソリューションではありません。ストレージファイルなどとして使用しないでください。お気に入りの映画をそこに置かないで、どこかに置いてください。
ClickHouseはドキュメント指向のシステムではありません。つまり、ClickHouseには厳しいスキームがあります。テーブルの作成レベルで設定し、構造を記述する必要があります。この構造をより効率的に記述すればするほど、より正確に記述できます。パフォーマンスと使いやすさの点でClickHouseから得られる利益は大きくなります。
ClickHouseはデータを変更できません。これは多くの人にとって驚きかもしれませんが、実際にはデータを変更する必要はありません-これは幻想です。実際、ClickHouseではデータを変更できます-サポートがあり、大きな部分をすべて削除できます。データを操作する機会があります-これは、データを変更せずに変更する、つまり新しいレコードを挿入するときのSRDTの概念です。 ClickHouseではこの方法で作業できますが、ここでの主な考え方は、データを頻繁に変更する必要がある場合、ClickHouseを使用する必要はほとんどないということです。これは、タスクにほとんど適していません。
ClickHouseはいつ使用する必要がありますか?
幅の広いプレートに多数の列がある場合は、ClickHouseを使用する必要があります。これは、他の多数のデータベースとは異なり、ClickHouseでうまく機能します。これは、多くの人々にとってのソリューションであるためです。分析が素晴らしいソリューションだと思うなら。
リクエストがあまり多くないが、各リクエストが大量のデータを使用するようなパターンがある場合、ClickHouseはそのようなパターンで正常に機能します。この場合の「小さな」とは、単位、数十、数百のRPSです。
大量の着信データがある場合は、常にデータベースに流れ込みます。 「メトリック」の場合、1日あたり約200億のイベントであり、リアルタイムで書き込まれます。絶えず質問をしながら、常にすべてを書き込むような状況で動作できるデータベースはほとんどありません。 ClickHouseは、その下に地面ができます。
基本的にペタバイトのデータがあり、それらの分析を検討する必要がある場合、一般的に言えば、これを実行できるソリューションは多くありません。片方の手の指で直接数えることができますが、おそらく2本です。ClickHouseはこれに完全に対応しています(指の数ではありません)。
いくつかの小さなケースがあります。彼らは通常、現在の生産で何が起こっているかを分析しようとしています。
どのように見えるか
人々は、アクセスログまたはログを単にデーモンにし、文字通り単純なスクリプトで興味深い列に配置し、ClickHouseに書き込みます。 それだけですこれは非常に簡単に行われます。このスクリプトをPythonまたはBashで書くのは何時間も現実的です。
そして、出力は何ですか?いつでも奇妙な状況を簡単に分析できます。一部のクライアントは何か奇妙なことをしました-このクライアントが私であるかどうかにかかわらず、DDoS-umを見る必要があるかどうかを確認する必要があります。これらすべてを選択して、すぐに結果を取得できます。上記から任意のコントロールを構築し、任意のメトリックを計算できます。これも即座に機能します。このケースから開始し、Metrica ClickHouseはこのケースを使用して正確にクロールしました。また、他の部門はログをアップロードし、何らかのインシデントレポートを作成し始めました。
2番目の、より大きく、より一般的なケースは、データウェアハウス内の分析のベースです。
なにがある
同社には、生産プロセスに使用される何らかの種類のベースがあります。Oracle、PostgreSQLなどです。分析を目的としたものではなく、理解しやすいものです。ビジネスロジックを実装するように設計されています。そして、その分析は考慮するのが非常に不便です。または、Hadoopがあり、すべてが注ぎ込まれ、アナリストもそこに座って、このHadoopで非常に遅い動作を理解しようとする状況があります。
何ができますか?
ClickHouseクラスター、つまり文字通り1つのサーバーを上げることができます。または、ClickHouseのデータが現在のデータベースのデータよりもはるかに少ないスペースを占有することを覚えて、どれだけ計算する必要があります。そこにデータをコピーするだけです。たとえば、定期的に-1日に1回コピーします。その結果、ビジネスまたは開発に関連するデータの処理速度が驚くほど速くなります。アナリストはすぐに絹のような髪になります。インシデントをすばやく調査し、ビジネスインジケータを非常に迅速に作成し、ClickHouseの上にある種のダッシュボードを非常に迅速に作成することもできます。速度の違いは、あなた自身が100回見ました。それをすべて設定するのは非常に簡単であり、それを拾うのは簡単です。一般に、ClickHouseを入力するためのしきい値は、Hadoopなどの一般的なシステムよりもはるかに低くなっています。
どこから始めますか?
私たちは、完璧なチュートリアルを持っている -あなたが遊んで、彼と一緒に行くことができ、ClickHouseを入れて、完全なチュートリアルでは、いくつかの時間のために渡されます。既にデータセットがあり、ダウンロード、アップロードが可能で、どれだけ簡単かを確認できます。本当に簡単です。昨日、まったく新しいサーバーでClickHouseをセットアップしましたが、文字通り2分かかりました。ニュースレターに
質問を書いてください、私たちは常に答えます。
GitHubにアクセスしてください-コードをご覧ください。これは最も最適な方法であり、コード全体が開いています。
そして、Googleグループおよびその他のソースにアクセスします。ClickHouse.yandexリンクの詳細については、優れたドキュメントなど、必要なすべてのものがあります。
まとめ
apache2ライセンスの下ですべてに開かれたオープンソースデータベース。素晴らしいライセンス。
線形のスケーラビリティを必要とし、非常に高速なクエリ速度が必要なタスクに使用できます。一般に、分析クエリの速度に問題がある場合は、ClickHouseを試してください。
SQLはさまざまな付加機能でサポートされています。
みんなありがとう。
レポート:ClickHouse:非常に高速で非常に便利です。