
ITインフラストラクチャプロジェクトはどこから始まりますか? 管理者が集まり、議論し、誰かが解決策を提案したようなことを考えた場合、頭に釘を打つ可能性が非常に高くなります。 それがロシア企業での事業のあり方であり、私たちも最近までそうでした。
記事では、優秀な専門家と熱意が大規模なものを実装するのに十分でないことを確認するために500万とほぼ6か月を費やした方法を説明します。
すべては、決済サービスの中心にあるいくつかの巨大なモノリシックアプリケーションは面倒で不便であるという認識から始まりました。 Layout 、 Portal 、Yandex.Milling Billingは 、更新をロールアップし、システムの動作を監視する複数の運用チームによって個別に提供されました。 何年にもわたって順調に機能していたこのプロセスは、プロジェクトチームが社内で形成され始め、リリースの頻度が指数関数的に増加したときに失敗し始めました。
同じコードセクションを使用する場合の競合の数は増加しました。受け入れテストはもちろん、1か月以上続くこともありました。 そのような場合、現代の企業は何をしますか? 彼らはモノリスを多くの小さな(マイクロ)サービスに分割します。
OK、マイクロサービスに行きます
より多くのサービス-より多くのメンテナンス負荷。 結局のところ、現在1日あたり5〜10のリリースがあります。 古いプロセスによると、テスト後にそれぞれを複数のノードに手動でロールする必要があります-1日あたり最大100の手動更新がリリースされました。 テストスタンドを更新する必要があるため、テストスタンドの数はチームの数に等しいため、数千の手動操作で計算されました。
最高のカフェインを使用した静脈内メンテナンスエンジニアのチームでさえ、何千ものシステムの毎日の更新を処理できません。これはすべて自動化する必要があります。 すぐに言った:DevOpsグループは運用から割り当てられ、自動化のタスクを任されました。 まあ、彼らが選ばれたとき-しばらくの間、彼らは管理者と一緒にワークフローと設計作業に従事し、その後特定のタスクのために分離しました。
プログラマーとテスターは魔法の解決策を辛抱強く待ち、大きな野心的なタスクに触発され、DevOpsのスタッフは朝から夜までリリースの自動インストールと「ボタン上の」テストスタンドの展開のインフラストラクチャに取り組みました。
何が起こっているかをよりよく理解するために、DevOpsチームが最初の段階でどのようにアセンブリおよびテストシステムを提示したかを見ていきます。
あらゆる環境のアプリケーションごとにユニバーサルビルドスクリプトを作成します。
戦闘およびさまざまなテスト環境用のアプリケーションを構築するための設定を作成します。
テンプレートごとの設定でテスト環境を作成できる仮想化環境を開発しています。
リリースごとに、更新されたアプリケーションを収集して、戦闘環境と既存の各テスト環境にインストールします。
- 各テスト環境で、戦闘環境のリリースプロセス中に行われた設定と変更を手動で微調整します。
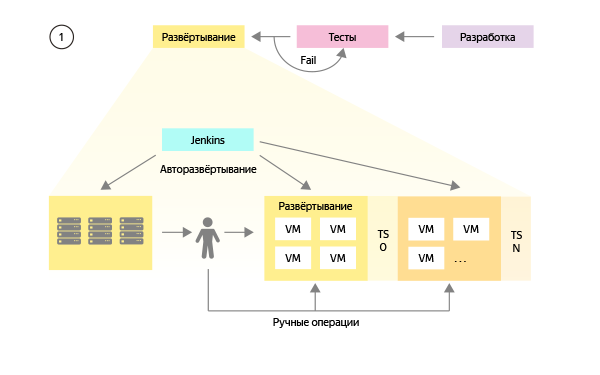
時間が経つにつれて、すべてのプロセスを制御し、すべてのタイプの環境での手動操作を徐々に取り除くようにGUIを構成することも計画しました。
数ヶ月が経ちました
Ansible-Jenkinsの仮想ベンチシステムとラボのリリースビルドは、現実の世界に直面しています。 ここで、最初の実稼働テストでいくつかの基本的な問題が明らかになりました。
多かれ少なかれ、作業台は数時間ではなく、数週間で手作業で組み立てられました。 待機期間中のニーズは数十台から数百台に増加し、それが次の世紀のどこかで完成日を押し上げます。
途中で、各スタンドが約200 GBのディスク容量を使用することが判明しました。 このボリュームに必要なスタンドの数を掛けると、ディスクスペースの毎日の「売上高」の不適当な数字が得られます。
- チームが異なれば、サービスの開発、テスト、構成、および展開の方法がわずかに異なります。 したがって、提案されたオプションは、どの開発チームにも完全には適合しませんでした。
管理者はプロジェクトマネージャーなしで作業することに慣れていることを覚えていますか? 問題の山が発見されると、通常、それらはすべてバックログに入れられ、順番に解決されます。 状況がエスカレートしたとき、彼らは同じことを続けますが、より速く、またはそれ以上です。
一般に、スペシャリストの勤勉さを低く評価し、優先順位を頻繁に変更するほど、士気を落とすことはほとんどできません。 残念ながら、搾取の努力が間違った方向に向けられていたため、このレーキを踏んだ。 結果は論理的です。新しいプロセスは時間通りに機能しませんでしたが、古いプロセスは最終的に壊れ、開発者とテスターに多くの問題を投げかけました。
並行して、到着する新しいスタンドを使用する試みの苦しい時期が始まりました。 このような各スタンドは手動で作業を追加して更新したため、管理者のタスクキューは急速に拡大し始め、このプロジェクトに対する開発者の態度は急速に悪化しました。
頭の周りの知能
最も不快な問題でさえ、時間内に認識し、その解決策に取り組み始めることが重要です。 私たちの主な間違いはテクノロジーに関連するものではなく、プロジェクト管理への十分な注意、要件の決定、およびステークホルダーの期待の評価にありました。
原則として、DevOpsはこのプロジェクトだけを行うことはできませんでした。 開発とテストが含まれるまで、すべての作業は主にテーブルで行われました。
開発者とテスターは一般に、何が必要なのかほとんど聞かれませんでした。 システム管理者は展開タスクに重点を置いており、開発者とテスターは、スタンドを自動的に作成してテストスクリプトを実行するツールを本当に必要としていました。
法人顧客にはリソースの制限がありました。 新しいプロセスの開発と古いプロセスの保守は、単にそれに適合しませんでした。 これは遅すぎて発見されました。
- そして、最も一般的なのは、プロジェクトマネージャーがいなかったため、全体の話が明日または翌日の作業を完了することを約束することになりましたが、6か月後には結果が出ませんでした。
最初の感情的な反応が起こり、すべての主要な人々が彼らの「ウィッシュリスト」について議論するために集まったとき、問題を最初に解決しなければならないことが明らかになりました。 今回だけ、これを開発中のプロジェクトとして扱いました。目標、要件、期限、リソース、顧客、責任者、作業計画、技術的ソリューションなどを備えています。
再構築された要件には、最初の反復で見落とした詳細が含まれていました。 致命的であることが判明した詳細。
2番目のアプローチでは、次のことを考慮しました。
数年のうちにいくつのテストスタンドが必要になりますが、現在は必要ありません。
各テストベンチに必要なデータ量。
スタンドが互いに、また軍事環境からどのように隔離されるか。
開発チームがそれらを更新するための要件は何ですか?
テスターがスタンドでどのように働くか。
- テスト環境と外部サービスとの通信を確認する方法。
詳細を理解することで、一見不可欠なプロジェクトを、仮想空間の提供、ネットワークの分離、更新の配信、アプリケーションの構成機能などに関連するサブプロジェクトに分割しました。
その結果、最も効率的なオプションは、戦闘と参照テストの2つの環境が存在することが判明しました。 また、カスタマイズされたコンポーネントを使用してリファレンスベンチを複製することにより、チームテスト環境のセット全体が作成されます。 この状況では、開発チームは、外部サービスのコンポーネントとスタブに最小限の変更を加える必要があります。 テストデータの量が20倍減少すると、スタンド内のデータベースを転送できます。 スタンド絶縁は、サブネットレベルおよびDNSサーバー設定でネットワークエンジニアによって提供されます。
変更されたスキームは次のようになります。
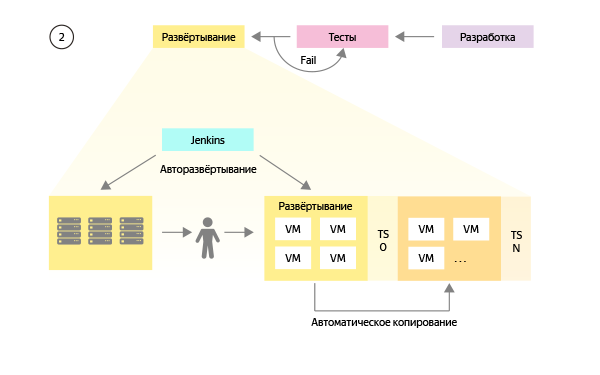
すべてのテスト環境への変更の転送は自動的に行われ、エンジニアの細心の注意を必要としないため、作業の図の視覚的なわずかな違い(手動操作の減少)は大きく変わります。
「レーキガーデン」を通過した後の結論
上記のすべてが明らかであると思うかもしれません。 ただし、ある領域で明らかなことは、別の領域では必ずしも明らかではありません。 運用中の大規模インフラストラクチャプロジェクトが「ひざまずく」変化する例は非常に多くあります。 DCの変更、新しいオフィスの立ち上げ、DBMSからDBMSへの移行に成功し、そのようなプロジェクトを以前に行ったことがあるエンジニアの能力を残すことができます。
しかし、開発、サポートなどと一緒に運用する必要があるプロジェクトに出くわすと、プロジェクト管理なしで失敗する可能性が何度も高まります。 ソフトウェア会社のインフラストラクチャプロジェクトの専任マネージャーをたくさん見ましたか?
「彼らは結婚し、幸せに暮らした」という精神での結論の代わりに、私たちが未来のためにした結論を引用します。
プロジェクトの作業は、開発者と同じようにシステム管理者によって要求されます。 プロジェクトマネージャーがいなければ、各参加者には独自のビジョンがあり、最終的にチーム全体が特定のポイントに到達することはできません。
スペシャリストをやる気にさせるのは、タスクに費やす時間の無駄さを認識することほど悪くはありません。 時間を無駄にしないために、プロジェクト参加者が達成する必要がある目標とその理由を明確に理解する必要があります。 開発者、テスター、および管理者の定期的な会議は、私たちを大いに助けてくれました。
システム管理者の作業の中間結果を確認して使用しようとする方法を見つける必要があります。そうすることで、後で多くの月の作業を消す必要がなくなります。
- 真空の中で完璧な動機を持つ最高のエンジニアのチームでさえ、頭と脚の不一致による損傷を補償しません。
おもしろいですが、会社で大規模なITプロジェクトにどのように取り組んでいますか?プロジェクト管理で同様の問題に遭遇しましたか?