すべての人に良い一日を! 私は学生です。論文のトピック「情報ニューラルネットワーク」(ANN)を選びました。 数字を操作する必要があるタスクは非常に簡単に解決されました。 そして、ワープロを追加してシステムを複雑にすることにしました。 そのため、特定のトピックについてコミュニケーションできる「コンパニオンロボット」を開発するタスクを自分で設定しました。
ロボットとのコミュニケーションのトピックは非常に広範囲であるため、対話全体を評価するのではなく(同志チューリングにこんにちは)、人の発言に対する「対談者」の答えの妥当性のみが考慮されます。
次に、ANNの入力で受け取った提案の質問と、出力で受け取った提案の回答を呼び出します。
アーキテクチャ1. 1つの隠れ層を持つ2層直接分布ニューラルネットワーク
ニューラルネットワークは数字でのみ機能するため、単語をエンコードする必要があります。 簡単にするために、句読点は考慮から除外され、固有の名前のみが大文字で書かれています。
各単語は、1から始まる2つの整数でエンコードされます(ゼロは単語の不在に責任があります)-カテゴリ番号とこのカテゴリの単語番号。 意味や種類(色、名前など)が類似した「カテゴリ」に単語を保存することになっています。
表1
|
| カテゴリー1
| カテゴリー2
| カテゴリー3
| カテゴリー4
|
| 1
2 3 4 5 6 7 | あなたは
あなたのもの あなたは あなたのもの あなたに あなたは 私は | 大丈夫
すごい すごい 素晴らしく いいね いいね いいね | ひどく
ひどく 嫌な 悪い 悪い | こんにちは
こんにちは ようこそ こんにちは 健康です |
ニューラルネットワークの場合、データは正規化され、範囲に縮小されます $インライン$ [0、1] $インライン$ 。 カテゴリと単語番号-最大値 $インライン$ M $インライン$ すべてのカテゴリのカテゴリ番号または単語。 文は固定長の実数ベクトルに変換され、欠落している要素はゼロで埋められます。
各文(質問と回答)は、最大10語で構成できます。 したがって、20の入力と20の出力を持つネットワークが取得されます。
N個の例を記憶するために必要なネットワークの接続数は、次の式で計算されました。
$$表示$$ L_W =(m + n + 1)(m + N)+ m、$$表示$$
ここで、 mは入力の数、 nは出力の数、 Nは例の数です。
Hニューロンで構成される1つの隠れ層を持つネットワーク内のリンクの数
$$表示$$ L_W = 20H + 20H = 40H、$$表示$$
必要な数の隠れニューロン
$$表示$$ H = L_W / 40 $$表示$$
のために $インライン$ n = 20 $インライン$ 、 $インライン$ m = 20 $インライン$ 対応が判明
$$ディスプレイ$$ L_W(N)= 41N + 480 $$ディスプレイ$$
その結果、例の数に対する隠れニューロンの数の依存性が得られます。
$$ディスプレイ$$ H(N)= \ frac {41} {40} H + 21 $$ディスプレイ$$
学習ネットワークの構造を図1に示します。
図1.文を記憶する最も単純なANN
ネットワークはMATLABで実装され、トレーニングはエラーの逆伝播の方法です。 トレーニングサンプルには32文が含まれています...
それ以上は必要ありませんでした...
ANNは15を超える文を記憶できませんでした。これを次のグラフに示します(図2)。 エラーは、NSの現在の出力と必要な出力の差のモジュラスとして計算されます。
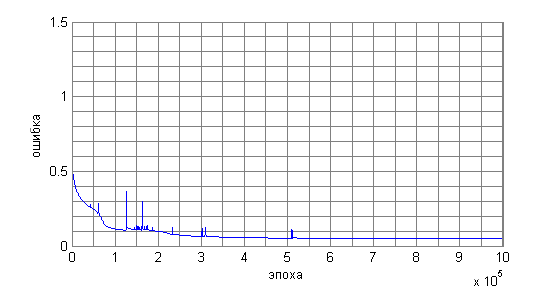
図2. 32例のトレーニング中のNSエラー
ダイアログの例(トレーニングサンプルのすべての質問):
|
|
さまざまな数のサンプルをテストした結果、ANSトレーニングサンプルでさえ非常に困難に記憶されていることが明らかになりました(図2を参照)。 100万時代であっても、エラーを必要な値まで減らすことはできませんでした。
アーキテクチャ2. 2層直接分布ニューラルネットワーク
ANNのワードをエンコードする次の方法は、ワンホットエンコードです[4] 。 その本質は次のとおりです。辞書に入れましょう $インライン$ D $インライン$ アルファベット順の単語。 そのような辞書の各単語は、長さベクトルによってエンコードされます $インライン$ D $インライン$ 辞書の単語番号に対応する場所に単位を含み、他の場所にゼロを含む。
実験のために、辞書はから作成されました $インライン$ D = 468 $インライン$ 単語と95文のトレーニングセット。 国民議会の入力に6つの単語が提出され、その答えも6つの単語から検討されました。
隠れ層のニューロンの数は、ネットワークがエラーなしで学習できる例の数に対する接続数の依存性によって決定されました。
|
|
結果は、システムがより多くの単語を記憶できることを示しています。 ほぼ勝利...しかし、別の問題が発生します-同義語と同様の言葉の定義[4] 。
アーキテクチャー3. 2層直接分布ニューラルネットワーク
1つの隠しレイヤーとword2vecエンコーディング
単語と同義語の類似性の問題を解決するために、word2vec [4]を試してみることにしました。これにより、単語を適切にエンコードできます。
ネットワークの動作に関する実験では、長さベクトルの単語ベクトルの辞書が使用されました $インライン$ D = 50 $インライン$ ニューラルネットワークのトレーニングベースでトレーニングされています。
6ワードがニューラルネットワークの入力(長さ300のベクトル)に送信され、6ワードから成る回答を受け取ることが提案されています。 逆符号化では、文ベクトルは6つの単語ベクトルに分割されます。それぞれのベクトルについて、ベクトル間の角度のコサインによって可能な最大の対応が辞書で求められます。 $インライン$ a $インライン$ そして $インライン$ B $インライン$ :
$$ display $$ cos [A、B] = \ frac {\ sum_ {d = 1} ^ {D} {(A_d B_d)}} {\ sqrt {\ sum_ {d = 1} ^ {D} {A_d ^ 2}} \ sqrt {\ sum_ {d = 1} ^ {D} {B_d ^ 2}}} $$ディスプレイ$$
しかし、そのような実装を使用しても、word2vecはロシア語の観点からは単語間の必要な接続を行いません。 シノニムができるだけ正確に配置されるディクショナリを作成するために、グループ化されたシノニムを持つ訓練隊が形成され、おそらく互いに意味が組み合わされます。
| ME MY ME I AM MY
あなたあなたあなたあなたあなたあなたあなたあなた はい、そうでない場合でも、これだけでも 誰が何ですか 出産 ロボットロボットロボットロボットロボット |
このようなプレゼンテーションの結果として、同じ答えを与えることができる多くの同義語(「hello」、「hello」、「welcome」など)を覚えておく必要はありません。 たとえば、トレーニングサンプルには「hello-hello」のみが参加し、残りの回答は、「hello」、「hello」、および「welcome」の余弦が大きいために受信されました。
|
|
ただし、同時に、回答内の同義語が近接しているため(会話=会話=会話= ...、I =ミー=鉱山=ミー= ...)、質問のわずかな再定式化と混同されることがよくあります(「どのように勉強しますか?」あなたは人から学びますか?」。
ミスアドベンチャー
ご覧のとおり、ANNを使用して人とコミュニケーションをとろうとすると、「2人の金髪」が得られました。
Habrahabrと他のサイトの両方の説明から判断すると、誰もがこの問題に直面しているわけではありません。 したがって、疑問が生じます:犬はどこに埋葬されていますか? 少なくとも100〜200のフレーズを記憶および理解できるANNを取得するには、どのアプローチを使用する必要がありますか。
同様の質問に直面した人、私はあなたのアドバイスや提案をお願いします。
参照資料
- LSTMネットワークを理解する方法
- 開発:ニューラルネットワーク上のチャットボット
- 開発:Google TensorFlow Machine Learning Library-第一印象と私たちの実装との比較
- 開発:前処理なしのニューラルネットワークを使用した文の分類
- 開発:ロシアのニューラルネットワークチャットボット