
こんにちは、Habr! カットの下で、 Kerasフレームワークを使用したInceptionV3アーキテクチャの畳み込みニューラルネットワークの実装について説明します。 チュートリアル「 少量のデータを使用した強力な分類モデルの構築 」を読んだ後、記事を書くことにしました。 チュートリアルの著者の承認を得て、記事の内容を少し変更しました。 著者が提案したニューラルネットワークVGG16とは異なり、 KerasにあらかじめインストールされているGoogleディープニューラルネットワークInception V3をトレーニングします。
あなたが学びます:
- KerasライブラリからニューラルネットワークInception V3をインポートします。
- ネットワークを設定します:重みをロードし、モデルの上部を変更し( fc-layers )、モデルをバイナリ分類に適合させます;
- ニューラルネットワークの下位畳み込み層を微調整します。
- ImageDataGeneratorを使用してデータ拡張を適用します。
- ネットワークを部分的にトレーニングして、リソースと時間を節約します。
- モデルのパフォーマンスを評価します。
記事を書くとき、私はKerasフレームワークのいくつかの興味深い機能を明らかにする最も実用的な資料を提示するタスクを自分で設定しました。
最近、ニューラルネットワークの作成とアプリケーションに特化したチュートリアルがますます登場しています。 興味深いトレンドを目にすることは大きな喜びです。プログラミングの分野の非専門家にとって新しい投稿がますます理解しやすくなっています。 一部の著者は、最も自然な言語を使用して、読者にこのトピックを紹介しようとしています。 また、合理的な量の理論と実践を組み合わせた優れた記事( 1、2、3など )もあり、必要な最小値をすばやく理解し、独自の何かを作成し始めることができます。
だから、ポイントに!
まず最初に、ライブラリについて少し説明します。
Anacondaプラットフォームをインストールすることをお勧めします。 Python 2.7を使用しました。 仕事にはJupyter Notebookを使用すると便利です。 Anacondaにはすでにプリインストールされています。 Kerasフレームワークもインストールする必要があります。 バックエンドとして、 Theanoを使用しました。 Kerasは両方をサポートしているため、Tensorflowを使用できます。 WindowsでのTheano用CUDAのインストールについては、 こちらをご覧ください 。
1.データ:
この例では、 kaggle.comで「 犬と猫 」という機械学習コンテストの画像を使用します。 データは登録後に利用可能になります。 このセットには、12,500匹の猫と12,500匹の犬の25,000枚の画像が含まれています。 クラス1は犬、クラス0は猫に対応します。 アーカイブをダウンロードしたら、次のように各クラスの1000個のイメージをディレクトリに配置します。
data/ train/ dogs/ dog001.jpg dog002.jpg ... cats/ cat001.jpg cat002.jpg ... validation/ dogs/ dog1000.jpg dog1001.jpg ... cats/ cat1000.jpg cat1001.jpg ...
データセット全体の使用を妨げるものは何もありません。 私は、元の記事の著者と同様に、限られた選択肢を使用して、小さな画像セットでネットワークの効率を確認することにしました。
次の3つの問題があります。
- 限られた量のデータ。
- 限られたシステムリソース(たとえば、Intel Core i5-4440 3.10GHz、8 GBのRAM、NVIDIA GeForce GTX 745があります)。
- 限られた時間:モデルを1日以内にトレーニングしたい。
限られた画像ボリュームでは、 再トレーニングの可能性が高くなります。 これに対抗するには、次のものが必要です。
- 大きなドロップアウトをインストールします。 私たちの場合、それは0.5になります。
- データ拡張を使用します。 この手法により、さまざまな変換によって画像の数を増やすことができます(この場合、スケール、シフト、水平反射に変化があります)。
- 実験では、深いネットワークを使用します。
ディープニューラルネットワークはリソースを要求しているため、最後のポイントは私たちに関係するはずです。 ビデオカードでVGG16を教えることさえできませんでした。インセプションのような巨人は言うまでもありません。 ただし、解決策は次のとおりです。
- 最初に、 imagenetデータベースからの多数の画像でトレーニングされたモデルを使用します。 幸いなことに、一連の画像には猫と犬が含まれていました。
- モデルを部分的にトレーニングします。
- 最初に、ネットワークの下部で(Inceptionのみを介して)拡張画像を実行し、numpy配列として保存します。
- 結果のnumpy配列を使用して、完全に接続された上位層をトレーニングします。
- 次に、モデルの上位層と下位層を組み合わせて新しいモデルを微調整しますが、同時に、最後の層を除くすべての層をInceptionから学習しないようにブロックします。
時間の経過に伴う問題の唯一の解決策は、並列計算の使用を見ています。 このためには、 CUDAをサポートするグラフィックカードが必要です。 Python用のCUDAをインストールしても、それほど大きな問題にならないことを願っています 。
ライブラリをインポートします。
from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential, Model from keras.applications.inception_v3 import InceptionV3 from keras.callbacks import ModelCheckpoint from keras.optimizers import SGD from keras import backend as K K.set_image_dim_ordering('th') import numpy as np import pandas as pd import h5py import matplotlib.pyplot as plt
2. InceptionV3モデルを作成し、イメージをロードして保存します。
私たちの行動の図を含む大きな写真 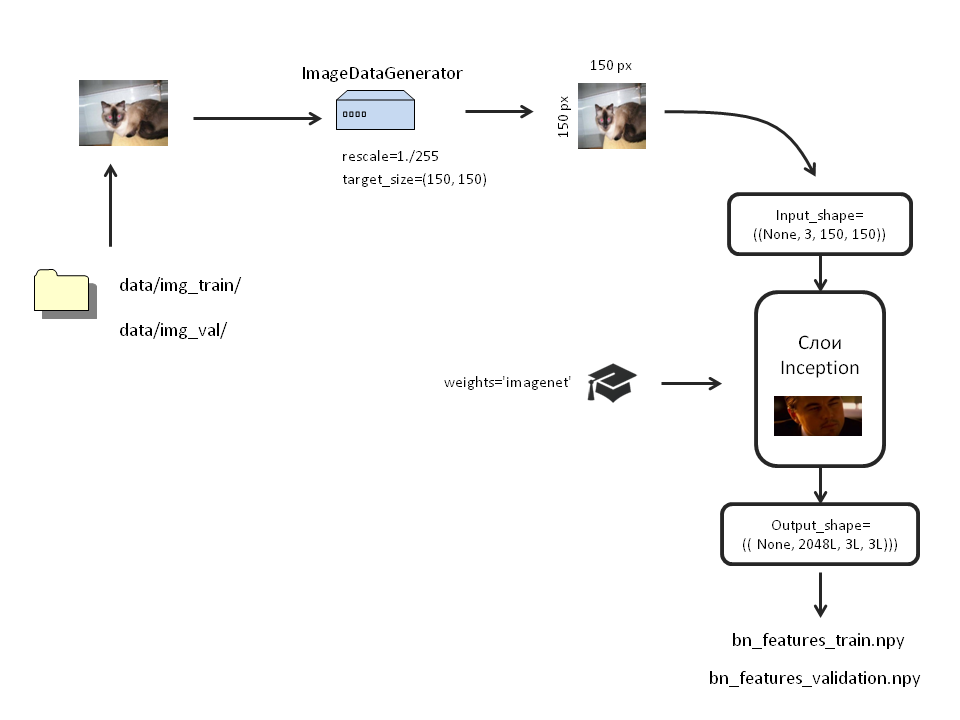
Kerasライブラリには、いくつかの訓練されたニューラルネットワークがあります。
モデル引数リスト
include_top:ネットワークのトップを有効または無効にします。これは、出力が1000個ある完全に接続されたレイヤーです。
必要ないので、次を設定します。include_top = False;
ウェイト :トレーニング済みウェイトをロード/ロードしません。 Noneの場合、重みはランダムに初期化されます。 「imagenet」の場合、 ImageNetデータにロードされたウェイトがロードされます。
このモデルでは重みが必要です。したがって、weights = "imagenet";
input_tensor :この引数は、モデルに入力レイヤーを使用する場合に便利です。
私たちは彼に触れません。
input_shape :この引数では、画像のサイズを設定します。 最上層が切り離されている場合に表示されます(include_top = False)。 モデルに最上層をロードした場合、100の画像サイズは(3、299、299)になります。
最上層を削除し、小さな画像(3、150、150)を分析したいと思います。 したがって、次のようになります:input_shape =()
必要ないので、次を設定します。include_top = False;
ウェイト :トレーニング済みウェイトをロード/ロードしません。 Noneの場合、重みはランダムに初期化されます。 「imagenet」の場合、 ImageNetデータにロードされたウェイトがロードされます。
このモデルでは重みが必要です。したがって、weights = "imagenet";
input_tensor :この引数は、モデルに入力レイヤーを使用する場合に便利です。
私たちは彼に触れません。
input_shape :この引数では、画像のサイズを設定します。 最上層が切り離されている場合に表示されます(include_top = False)。 モデルに最上層をロードした場合、100の画像サイズは(3、299、299)になります。
最上層を削除し、小さな画像(3、150、150)を分析したいと思います。 したがって、次のようになります:input_shape =()
モデルを作成します。
inc_model=InceptionV3(include_top=False, weights='imagenet', input_shape=((3, 150, 150)))
それでは、データの拡張を行いましょう。 このために、KerasはいわゆるImageDataGeneratorを提供します。 フォルダから画像を直接取得し、必要な変換をすべて実行します。
各クラスの写真は別々のフォルダーに入れる必要があります。 RAMに画像を読み込まないために、ネットワークにアップロードする直前に画像を変換します。 これを行うには、.flow_from_directoryメソッドを使用します。 画像のトレーニングとテスト用に別々のジェネレーターを作成しましょう:
bottleneck_datagen = ImageDataGenerator(rescale=1./255) #, train_generator = bottleneck_datagen.flow_from_directory('data/img_train/', target_size=(150, 150), batch_size=32, class_mode=None, shuffle=False) validation_generator = bottleneck_datagen.flow_from_directory('data/img_val/', target_size=(150, 150), batch_size=32, class_mode=None, shuffle=False)
重要なポイントを強調したい。 shuffle = Falseを指定しました。 つまり、異なるクラスの画像は混在しません。 最初に、最初のフォルダーから画像が到着し、それらがすべて終了すると、2番目からフォルダーに到着します。 なぜ必要なのか、後で見てください。
訓練されたInceptionを通じて拡張画像を実行し、出力をnumpy配列として保存します。
bottleneck_features_train = inc_model.predict_generator(train_generator, 2000) np.save(open('bottleneck_features/bn_features_train.npy', 'wb'), bottleneck_features_train) bottleneck_features_validation = inc_model.predict_generator(validation_generator, 2000) np.save(open('bottleneck_features/bn_features_validation.npy', 'wb'), bottleneck_features_validation)
このプロセスには時間がかかります。
3.モデルの上部を作成し、データをロードして保存します。
スキーム 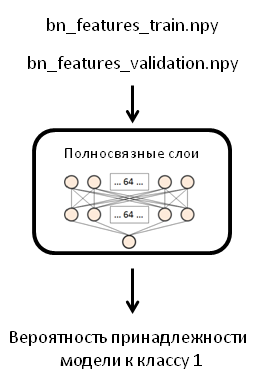
元の投稿では、著者は256個のニューロンを持つ1つのネットワークレイヤーを使用しましたが、それぞれ64個のニューロンを持つ2つのレイヤーと0.5の値を持つドロップアウトレイヤーを使用します。 完成したモデルをトレーニングすると(次のステップで行います)、コンピューターがクラッシュして再起動したため、この変更を余儀なくされました。
配列をロードします。
train_data = np.load(open('bottleneck_features_and_weights/bn_features_train.npy', 'rb')) train_labels = np.array([0] * 1000 + [1] * 1000) validation_data = np.load(open('bottleneck_features_and_weights/bn_features_validation.npy', 'rb')) validation_labels = np.array([0] * 1000 + [1] * 1000)
以前にshuffle = Falseを指定したことに注意してください。 そして今、簡単にラベルを指定できます。 各クラスには2000個の画像があり、すべての画像が順番に受信されるため、トレーニング用とテストサンプル用に1000個のゼロと1000個のユニットがあります。
FFNネットワークのモデルを作成し、コンパイルします。
fc_model = Sequential() fc_model.add(Flatten(input_shape=train_data.shape[1:])) fc_model.add(Dense(64, activation='relu', name='dense_one')) fc_model.add(Dropout(0.5, name='dropout_one')) fc_model.add(Dense(64, activation='relu', name='dense_two')) fc_model.add(Dropout(0.5, name='dropout_two')) fc_model.add(Dense(1, activation='sigmoid', name='output')) fc_model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
配列をそれにロードします。
fc_model.fit(train_data, train_labels, nb_epoch=50, batch_size=32, validation_data=(validation_data, validation_labels)) fc_model.save_weights('bottleneck_features_and_weights/fc_inception_cats_dogs_250.hdf5') #
現在、フォルダからデータをロードしていないため、通常の近似方法を使用します。
学習プロセスは非常に高速です。 各時代は私に1秒かかりました。
Train on 2000 samples, validate on 2000 samples Epoch 1/50 2000/2000 [==============================] - 1s - loss: 2.4588 - acc: 0.8025 - val_loss: 0.7950 - val_acc: 0.9375 Epoch 2/50 2000/2000 [==============================] - 1s - loss: 1.3332 - acc: 0.8870 - val_loss: 0.9330 - val_acc: 0.9160 … Epoch 48/50 2000/2000 [==============================] - 1s - loss: 0.1096 - acc: 0.9880 - val_loss: 0.5496 - val_acc: 0.9595 Epoch 49/50 2000/2000 [==============================] - 1s - loss: 0.1100 - acc: 0.9875 - val_loss: 0.5600 - val_acc: 0.9560 Epoch 50/50 2000/2000 [==============================] - 1s - loss: 0.0850 - acc: 0.9895 - val_loss: 0.5674 - val_acc: 0.9565
モデルの精度を推定します。
fc_model.evaluate(validation_data, validation_labels)
[0.56735104312408047、0.95650000000000002]
私たちのモデルは、そのタスクに十分に対応しています。 ただし、numpy配列のみを受け入れます。 これは私たちには合いません。 入力画像を受け入れる本格的なモデルを取得するために、2つのモデルを接続して再度トレーニングします。
4.最終モデルを作成し、拡張データをロードして、重みを保存します。
スキーム 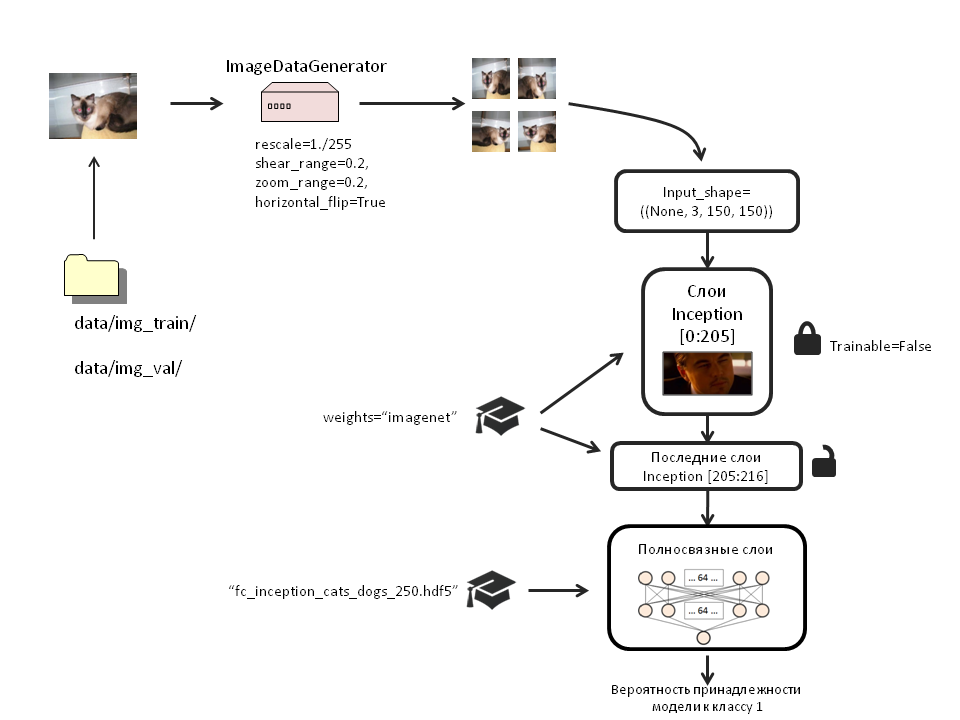
weights_filename='bottleneck_features_and_weights/fc_inception_cats_dogs_250.hdf5' x = Flatten()(inc_model.output) x = Dense(64, activation='relu', name='dense_one')(x) x = Dropout(0.5, name='dropout_one')(x) x = Dense(64, activation='relu', name='dense_two')(x) x = Dropout(0.5, name='dropout_two')(x) top_model=Dense(1, activation='sigmoid', name='output')(x) model = Model(input=inc_model.input, output=top_model)
その中にウェイトをロードします。
weights_filename='bottleneck_features_and_weights/fc_inception_cats_dogs_250.hdf5' model.load_weights(weights_filename, by_name=True)
率直に言って、私は荷重をかける場合と使わない場合のモデルのトレーニングの有効性に違いは見られませんでした。 ただし、名前(by_name = True)によって特定のレイヤーにウェイトをロードする方法について説明しているため、このセクションを終了しました。
ロック開始レイヤー1〜205:
for layer in inc_model.layers[:205]: layer.trainable = False
モデルをコンパイルします。
model.compile(loss='binary_crossentropy', optimizer=SGD(lr=1e-4, momentum=0.9), #optimizer='rmsprop', metrics=['accuracy'])
.npy配列から完全に接続されたレイヤーを最初にトレーニングしたときに、 RMSpropオプティマイザーを使用したことに注意してください。 次に、モデルを微調整するために、確率的勾配降下法を使用します。 これは、すでに訓練されたスケールに対するあまりにも顕著な更新を防ぐために行われます。
テストサンプルで最も正確な重みのみがトレーニングプロセスで保存されるようにします。
filepath="new_model_weights/weights-improvement-{epoch:02d}-{val_acc:.2f}.hdf5" checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=1, save_best_only=True, mode='max') callbacks_list = [checkpoint]
新しいイメージジェネレーターを作成して、完全なモデルをトレーニングします。 トレーニングサンプルのみを変換します。 テストには触れません。
train_datagen = ImageDataGenerator( rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True) test_datagen = ImageDataGenerator(rescale=1./255) train_generator = train_datagen.flow_from_directory( 'data/img_train/', target_size=(150, 150), batch_size=32, class_mode='binary') validation_generator = test_datagen.flow_from_directory( 'data/img_val/', target_size=(150, 150), batch_size=32, class_mode='binary') pred_generator=test_datagen.flow_from_directory('data/img_val/', target_size=(150,150), batch_size=100, class_mode='binary')
後でpred_generatorを使用して、モデルの動作を示します。
モデルに画像をアップロードします。
model.fit_generator( train_generator, samples_per_epoch=2000, nb_epoch=200, validation_data=validation_generator, nb_val_samples=2000, callbacks=callbacks_list)
クーラーノイズが聞こえて待ちます...
Epoch 1/200 1984/2000 [============================>.] - ETA: 0s - loss: 1.0814 - acc: 0.5640Epoch 00000: val_acc improved from -inf to 0.71750, saving model to new_model_weights/weights-improvement-00-0.72.hdf5 2000/2000 [==============================] - 224s - loss: 1.0814 - acc: 0.5640 - val_loss: 0.6016 - val_acc: 0.7175 Epoch 2/200 1984/2000 [============================>.] - ETA: 0s - loss: 0.8523 - acc: 0.6240Epoch 00001: val_acc improved from 0.71750 to 0.77200, saving model to new_model_weights/weights-improvement-01-0.77.hdf5 2000/2000 [==============================] - 215s - loss: 0.8511 - acc: 0.6240 - val_loss: 0.5403 - val_acc: 0.7720 … Epoch 199/200 1968/2000 [============================>.] - ETA: 1s - loss: 0.1439 - acc: 0.9385Epoch 00008: val_acc improved from 0.90650 to 0.91500, saving model to new_model_weights/weights-improvement-08-0.92.hdf5 2000/2000 [==============================] - 207s - loss: 0.1438 - acc: 0.9385 - val_loss: 0.2786 - val_acc: 0.9150 Epoch 200/200 1968/2000 [============================>.] - ETA: 1s - loss: 0.1444 - acc: 0.9350Epoch 00009: val_acc did not improve 2000/2000 [==============================] - 206s - loss: 0.1438 - acc: 0.9355 - val_loss: 0.3898 - val_acc: 0.8940
時代ごとに210〜220秒かかった。 200時代の研究には約12時間かかりました。
5.モデルの精度を推定する
model.evaluate_generator(pred_generator, val_samples=100)
[0.2364250123500824、0.9100000262260437]
そのため、 pred_generatorが役に立ちました。 val_samplesはジェネレーターのbatch_sizeの値と一致する必要があることに注意してください!
精度91.7%。 サンプリングが限られていることを考えると、これは精度が悪いわけではないと言う自由度があります。
モデルの説明
正解の割合とエラーの大きさを見るだけでは興味がありません。 モデルが各クラスに対していくつの正解と不正解を与えたかを見てみましょう。
imgs,labels=pred_generator.next() array_imgs=np.transpose(np.asarray([img_to_array(img) for img in imgs]),(0,2,1,3)) predictions=model.predict(imgs) rounded_pred=np.asarray([round(i) for i in predictions])
pred_generator.next()は便利なものです。 画像を変数にロードし、ラベルを割り当てます。
各クラスの画像の数は、世代ごとに異なります。
pd.value_counts(labels) 0.0 51 1.0 49 dtype: int64
モデルは各クラスの画像をいくつ予測しましたか?
pd.crosstab(ラベル、rounded_pred)
| Col_0 | 0.0 | 1.0 |
|---|---|---|
| Row_0 | ||
| 0.0 | 47 | 4 |
| 1.0 | 8 | 41 |
このモデルでは、100のランダムな画像がアップロードされました。猫の画像51枚と犬の画像49枚です。 51匹の猫のうち、モデルは47匹を正しく認識し、50匹の犬のうち41匹が正しく認識され、この狭いサンプルのモデルの全体的な精度は88%でした。
間違って認識された写真を見てみましょう。
wrong=[im for im in zip(array_imgs, rounded_pred, labels, predictions) if im[1]!=im[2]] plt.figure(figsize=(12,12)) for ind, val in enumerate(wrong[:100]): plt.subplots_adjust(left=0, right=1, bottom=0, top=1, wspace = 0.2, hspace = 0.2) plt.subplot(5,5,ind+1) im=val[0] plt.axis('off') plt.text(120, 0, round(val[3], 2), fontsize=11, color='red') plt.text(0, 0, val[2], fontsize=11, color='blue') plt.imshow(np.transpose(im,(2,1,0)))

青の数字は画像の真のクラスです。 モデルによって赤の数値が予測されます(赤の数値が0.5未満の場合、モデルは写真の猫、0.5を超える場合、犬を信じます)。 数値が0に近づくほど、ネットワークの前に猫がいると確信できます。 興味深いことに、多くの犬の画像エラーには、小型犬や子犬が含まれています。
モデルが正しく予測した最初の20個の画像を見てみましょう。
right=[im for im in zip(array_imgs, rounded_pred, labels, predictions) if im[1]==im[2]] plt.figure(figsize=(12,12)) for ind, val in enumerate(right[:20]): plt.subplots_adjust(left=0, right=1, bottom=0, top=1, wspace = 0.2, hspace = 0.2) plt.subplot(5,5,ind+1) im=val[0] plt.axis('off') plt.text(120, 0, round(val[3], 2), fontsize=11, color='red') plt.text(0, 0, val[2], fontsize=11, color='blue') plt.imshow(np.transpose(im,(2,1,0)))

このモデルは、比較的小さなサンプルでの画像認識のタスクにうまく対応していることがわかります。
この投稿がお役に立てば幸いです。 ご質問やご提案をお待ちしております。
Githubプロジェクト