私の知る限り、交通を説明する数学的法則はまだ誰も定式化していないため、あらゆる物理現象の交通は、プロセスの性質の観点から非常に複雑です。 それでも、確率論と数学統計の初歩的な方法を適用して、判断の可能性を形式化して評価しようとします。
物理学者、つまり研究者および自然テスターにとって、習慣によって奴隷にされた魂の真実の証拠を探すことは恥ではありませんか? マーク・トゥリウス・キケロ、2000年以上前
真実はしばしば根本的に達成不可能なままです。 研究を行っている間、私たちはまだ明確で信頼できる答えを与えることができない質問に直面しています。
しかし、それはとても悪いですか?
主張する機会を奪われて、我々は常に評価する権利を留保します。 この抜け穴により、真実に触れることはできませんが、真実に近づくことができます。 別のことは、無知や悪意から、人々は定期的に反対の方向に進み、真実から遠ざかっているということです。
私はこの問題の歴史に突入するためにしばらくの間喜びから自分自身を抑えることはできません。
確率論と数学的統計の歴史への遠足
数学で最も重要なスキルの1つは、不正確なコンピューティングの技術です。
質量ランダム現象とそれに対応する数学的装置の出現に関連する問題の体系的な研究の始まりは17世紀に遡り、ガリレオは物理的測定の誤差を調査し、その確率を評価しようとしました。
18世紀から19世紀初頭の全体にわたって、確率論の急速な発展とその広範な熱意が特徴的です。 確率論は「トレンド」科学になりつつあります。 彼らは、このアプリケーションが正当である場合だけでなく、何によっても正当化されない場合にもそれを適用し始めます。 この期間は、社会現象の研究、いわゆる「道徳」または「道徳」科学に確率論を適用しようとする数多くの試みによって特徴付けられます。 法的理論、歴史、政治、さらには神学の問題に専念した作品があり、確率論の装置が使用されました。 これらのすべての疑似科学的研究は、それらで検討されている社会現象に対する極めて単純化された、機構的なアプローチによって特徴付けられています。 推論は、arbitrarily意的に与えられたいくつかの確率に基づいており(たとえば、法的問題を検討する場合、各人の真実または嘘の傾向は、すべての人々に同じ一定の一定の確率によって推定されます)、その後、社会問題は単純な算術問題として解決されます。 当然、そのような試みはすべて失敗する運命にあり、科学の発展に積極的な役割を果たすことはできませんでした。 それどころか、彼らの間接的な結果は、西ヨーロッパの19世紀の1920年代と30年代頃に、確率論への広範囲の魅力が失望と懐疑主義に取って代わったということでした。 彼らは確率論を疑わしい二流の科学、一種の数学的娯楽であり、真剣な研究にはほとんどふさわしくないと見なし始めました。 A.
この時点で、一時停止し、その時点で確率理論と数学的統計がそれらが現在何であるかをすべて見ていないことに注意する価値があります。
ロシアで有名なサンクトペテルブルク数学学校が設立されたのは19世紀の初めで、その助けを借りて確率論が堅固な論理的および数学的基礎に置かれ、信頼できる、正確で効果的な認知方法を作りました。 この学校の出現以来、確率論の発展はロシア人、そしてその後のソビエトの科学者たちの作品と密接に結びついてきました。
敬意を表すために、私は彼らの名前を挙げます。そして、あなたが彼らから名前を思い出すことができます(あなたがTerverとMatstatを研究したことがあるなら)。
V.Ya. ブニャコフスキー、P.L。 チェビシェフ、AA マルコフ、AM リアプノフ、S.N。 バーンスタイン、A.Ya。 キンチン、A.N。 コルモゴロフ、V.I。 N.V.ロマノフスキー スミルノフE.E. Slutsky、B.V. グネデンコなど。
それでは、質問に戻る前に、基本を思い出させてください。それなしでは先へ進むことは困難です。
数学統計の簡単な紹介
免責事項
説明の便宜のために記述の厳密さを犠牲にする準備ができているので、絶対に正確で正しい調合のふりをしません。 気配りがあり、より要求の厳しい読者には、記事の最後で、使用されている文献へのリンクを見つけて、自分で質問に飛び込むことをお勧めします。
イベントは、経験の結果として発生した、または発生しなかった事実です。 例:
- サイコロを投げると、5ポイント落ちました。
- ユーザーはサイトに行きました。
ランダム変数は、実験の結果として、事前に知られていない値をとる量です。 例:
- ダイスに落ちたポイントの数。
- 1000ロールでダイスに落ちたすべてのポイントの合計。
- 日中のサイトでのページビューの数。
通常の六角形の立方体を投げる経験を考えてみましょう。イベントはランダムであり、その結果を予測することはできません。つまり、事前に倒れた顔に名前を付けます。
確率論の数学的法則は、質量ランダム現象に固有の実際の統計法則を抽象化することによって得られます。 これらの法則の存在は、現象の質量特性 、つまり実行された多数の均質な実験と正確に関係しています。
個々のランダムな現象の特定の特徴は、そのような現象の質量の平均結果にほとんど影響を与えません。平均からのランダムな偏差は相互に平準化されます。 多数の法則の物理的内容を表すのは、この平均の安定性です。非常に多数のランダム現象では、それらの平均結果は事実上ランダムでなくなり、高度の確実性で予測できます。
したがって、完全にランダムなイベントであっても、「安定した」メトリックがあります。 前の例では、多数のテストを使用して六角形キューブに平均でいくつのポイントが入るかを推定できます。 これを行うには、サイコロを何度も振って、落ちたすべてのポイントを合計し、試行回数で割ります。
ところで、私はあなたがあなた自身をチェックし、この数を評価することを提案します;)答えは内部にあります
平均して、サイコロごとに3.5ポイントがロールごとにドロップされます。 また、同時に3つのヘックスダイスを投げると、平均で何ポイント獲得できますか? コメントにオプションを書いてください!
同様に、サイトの訪問履歴を知ることで、特定の日の出席を正確に予測できます。
ウェブ解析で数学的統計を試す
免責事項#2
私が知る限り、このような方法でWeb分析のトラフィックと統計の詳細な分析を行っている人はいないため、同僚の経験を参照することはできません。 したがって、これは問題に対する著者のアプローチであり、真実であると主張するものではなく、あなた自身の危険とリスクにおいて誰にも承認されないことに留意してください。
サイトXXXのliveinternetからオープンビュー統計を取得しましょう
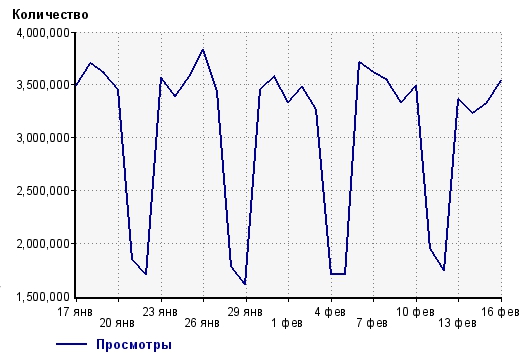
質問:この変更が現在の測定基準に影響を与えたことを明確に(または、かなり高い確率で)述べることができるように、サイト/マーケティングの変更はどの程度「大きく」すべきですか?
データをテーブルに転送します 。
現在の統計資料は、単純な統計シリーズです。 シリーズの各要素は、十分に大きなボリュームのランダム変数のサンプルであるため、放射分布の本質的な特徴が明らかになります。 これを支持して、グラフ上で特定の周期的パターンを見ることができるという事実によって語られます。
得られたデータの分析表現の検索はそれ自体は未定義のタスクであり、まず第一に物理的考察から解決されるため、統計シリーズの整列の問題(つまり、統計の特徴を表す理論的な分布曲線を見つける問題)を解決するという目標は設定していませんプロセス。 残念ながら、トラフィックの性質は非常に複雑であるため、理論的に説明することはできません。
さらに、分布の法則を見つけるには、広範な統計が必要です。 数百回の観測の材料。 残念ながら、これはありませんが、それでもランダム変数の最も重要な数値特性である数学的期待値 、 分散 、 標準偏差を暫定的に決定できます。
プロセスの物理学について結論を下しましょう。
トラフィックは本質的に周期的であるため、異なる曜日を互いに比較することは正しくありません。 つまり、月曜日にトラフィックがどのように動作し、どの程度異常であるかを知りたい場合は、現在の月曜日を以前のすべての月曜日と比較する必要があります。 または、定期的な依存関係を取り除くために、たとえば1週間など、より長い期間調査します。
上記の表では、最後の5つの水曜日(つまり、1月18日、1月25日、2月1日、2月8日、および2月15日のビューに関するデータ)を使用します。
これらの日のサンプルの数学的期待値と分散を推定します。 ランダム変数の統計的平均は一致する傾向があることが知られています。 無限の傾向がある実験の数の期待。 残念ながら、実際には多くの実験が行われることはめったにないので、数学的期待値が不正確に計算されるという事実を考慮します。
5つの要素のサンプルが提供されます。
3 703 900
3 577 305
3 329 611
3 538 719
3 325 899
マット 期待値(統計平均でもあります): 3 495 087
偏りのない分散: 27 068 326 459
標準偏差(分散の平方根): 164 525
マットと思ったように。 期待と分散
今から楽しい部分です。 チェビシェフ不等式と呼ばれるものが1つあります。 つまり、ランダム変数は基本的にその平均に近い値を取ると主張しています。 同じ不等式により、このイベントの数値推定が得られます。
確率付き確率変数
は、間隔(m-ks、m + ks)に分類されます。ここで、kは正の係数(k> 1)、sは標準偏差です。
これはどういう意味ですか? サンプルではk = 2を使用します。
確率変数は、75%の確率で間隔(3 166 037、3 824 137)に分類されます。
最悪の場合の精度は88%であるため、ほとんどの場合、k = 3標準偏差(有名な3シグマルール)を使用します。
この精度は、間隔(3 001 512、3 988 662)に対応します。
教育を受けた読者は、3シグマルールが場合によってはより高い精度を与えることに気付くかもしれません。 はい、場合によっては推定の精度を強化できますが、そのためには分布の性質についてもう少し知る必要があり、この記事ではそのようなタスクを設定していません。
結論
結論を出す前に、結果をグラフで示しましょう。
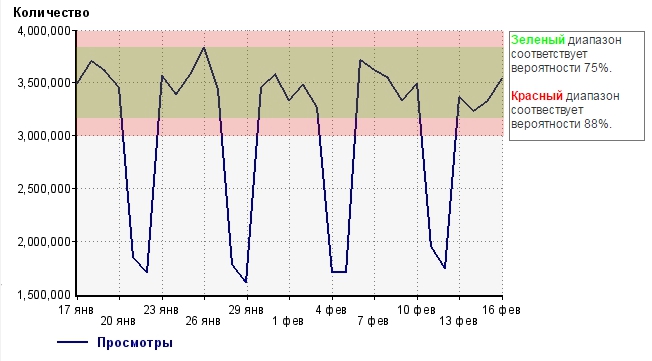
この量の発生の性質を根本的に変更しない場合、確率変数75%の確率変数(日中のサイトビューの合計)が緑の範囲に、確率88%が赤の範囲に落ちることがわかりました。つまり、サイトのインターフェースを変更するか、マーケティング活動を表示します。
それで、これは何を私たちに与えますか まず、「信じる」境界線を選択します。 伝統的に、3シグマ、つまり赤の間隔を取ります。
これにより、平均から14.1%外れたウィンドウが得られます。
たとえば、次の水曜日(2月22日)にA / Bテストを実行して結果を測定するなど、何らかの実験を行う場合、次の結論を導き出すことができます。
1.実験の結果が指標を14.1%以上変化させた場合-おそらく実験は成功しました。
2.実験の結果が指標を14.1%未満変化させた場合、考えられる効果は統計誤差内にあり、それによって「潤滑」されているため、実験は信頼できません。 つまり、プラスの効果があったとしても、現在の評価ではこれを確実に証明することはできません。
どうする? 評価を改善し(私が行ったように5回ではなく、より多くの観察を行います)、実験の期間を延長します。
読んでくれてありがとう。 批判、提案、説明に喜んでいます。
投稿で使用された出版物のリスト:
- E.S. ウェンツェルの「確率論」(1969年、非常に面白い本、2番目のタスクはすべて軍事問題に関するものです。どうやら、冷戦の痕跡:)
- V.V. スヴェトザロフ「測定結果の基本処理」