原則として、ある日、戦闘になるまでテストでした。 後で発生した問題を知らなかったことがわかります。 当局は喜んで手をこすり、システムの艦隊を更新することにしました。 OpenStackテストプラットフォームを含む。
現時点では、Mitakaバージョンの燃料ソリューションがなかったため、手動で展開することにしました。 そのため、公式サイトのレシピに従ってすべてを展開しました。 もちろん、たとえばMemcachedをCouchbaseに置き換え、データベースとしてクラスターモードのperconaを使用するなど、独自に少し追加しました。 そして、すべてがうまくいきました。 ある時点まで。
パッケージを失い始めました。 最初は、スイッチのせいだと思っていました。 その上には、かなり古いバージョンのJunos-11があり、これには既知のバグがあります。 そしてコンソールには、私たちの推測を裏付けるメッセージが本当にありました。 このハードウェアを新しい15th Junosファームウェアを備えた別のハードウェアに交換しました。
その間、問題は消えませんでしたが、ゆっくりと拡大し始めました。 一般的な症状は次のようになります-pingが突然失われます。 常に切断します。
私たちと顧客のために気のめいる。
1つのクライアントがあり、多くのトラフィックを消費します。 応答で生成しすぎます。 彼はウェブカメラからの放送を持っています。 彼は文句を言い始めました:接続が失われ、それだけです。
監視で見たものは次のとおりです。
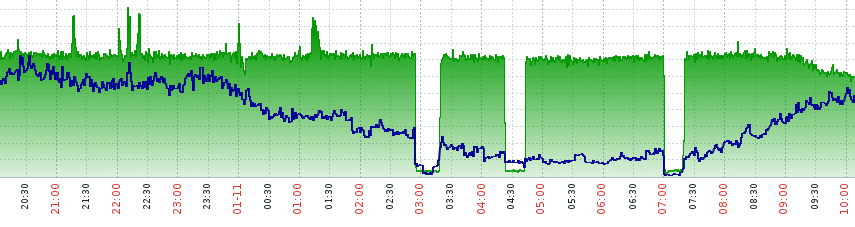
確かに-クライアントは正しい、何かが間違っています。 しかし、どこ? これらの瞬間の1つで、理由を見つけました-ネットワーク上で間違ったARPが発光しました。 犯人はどこですか? 有罪アドレスは、発行元のファイアウォールで見つかりました。 管理者が誤って入力した行がありました。
set security nat proxy-arp interface xxxx address yy.zz.tt.cc/32
彼らが見つけた神に感謝します-それは最初の考えでした。 しかし、そこにありました。 パケットの損失は、どのtcp、icmp、udpが継続しても関係ありません。
検索を続けたところ、問題はOpenStack内のどこかにあることが明らかになりました。 テスト仮想マシンにpingを開始したとき-私は椅子から落ちそうになりました:

これは、何らかの理由でパケットの一部がブロードキャストされず、灰色のアドレスで落ちたことを意味します! 当然、これらのパッケージは誰にも届いていません。
発掘できたものは後で共有します。 尊敬されている大衆の意見、私たちが何を間違えたか、どこを見るべきかを見たい