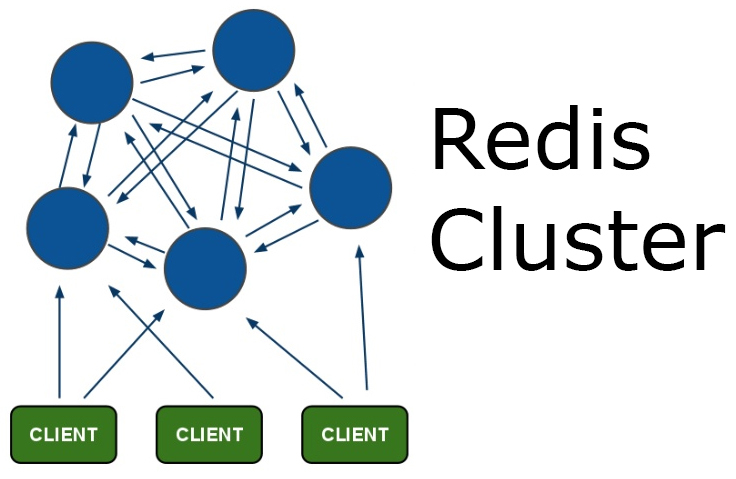
オープンソースの世界には、多くの企業で使用されている膨大な数のテクノロジー、アプローチ、パターン、ツール、およびアップがあります。 使用済みのソフトウェアまたはテクノロジーを競争上の優位性に変える方法 Redisクラスターの例を検討することを提案します。
開始する
Redisは実際、 非常に便利なものであるという事実から始める価値があります。 一言で言えば、Redisはメモリ内の永続的なキーと値のストレージであり、ブラックジャックと遊女がいます。 ほとんどの場合、Redisでできることのほとんど何もできない古いMemcachedと比較されます。
Redisの利点:
- 非常に高速なデータアクセス速度。 これはメカです。
- 混合データ型、ハッシュ。 1つのキー(イベント)に応じて、一連の情報(ユーザーID、イベントのタイプ、時間、トークン、セッション)を消去できます。 バイト、キロバイト、メガバイトのデータを使用できます。
- 汎用TTL。 Redisに保存したものを削除する必要はありません。 内部メカニズム自体が、TTLが到着したキーを削除します。 信じられないほど便利です。
- 単項演算、インクリメント、デクリメント-これらはすべて瞬時に解決するのではなく、信じられないほど瞬時に解決します。 したがって、Redisでは、複雑なプログレスバー、イベントを実装し、システムのさまざまな場所から変更されるカスタムデータを配置するのが便利で簡単です。
- 永続性とビンログ。 定期的にすべてのデータをディスクにフラッシュして、高いデータ可用性を提供し、それらの損失をほぼ平準化することができます。
Redisは、このような「銀の弾丸」であり、すべてのケース、アプローチ、およびプラクティスにとって絶対的なものであることがわかりました。 まあ、それ。 可能性が高いはい。
たとえば、生活を非常に妨げる問題:
- ステンデロン 実際、現時点では、Redisのデフォルトのインストールはstendelonです。 これは、単一障害点がある場合、信じられないほど貧弱なアーキテクチャを持つことを意味します。 Redisがクラッシュすると、システム全体が機能しなくなります。
- ディスクにフラッシュします。 これは非常に高価な操作であり、memcのIOに高い負荷がかかります。 ハードウェアでも大丈夫です-しかし、Redisはそこにあるものをすべて修正し、高速メモリから低速ディスクに大きなフラッシュを作成する必要があるため、サービスは非常に愚かです。 この時点で、すべてのサービスの遅延は数秒に増加します。
結論は明らかです-Redisは製品を高速化し、開発を高速化し、間違いなく使用する必要がありますが 、... 問題があります 。
Redisクラスター
Redisクラスターもあります! あなたは言いますが、急がないようにお願いします。 実際、Redisには2種類のクラスタリングがあります。
- Redis Sentinel-古いバージョン用
- Redis Cluster-新しいバージョン用
Redis Sentinelは、大根のウォールスタンドからツリー構造を構築し、クラスターと呼ぶ非常に原始的なものです。 シャーディングもバランスもなし。 さらにそれ以上、Redisの古いバージョンで動作しますが、誤解がない限り、3.0以下です。
Redis Clusterはもっと楽しく、既にシャーディング、レプリケーション、フォールトトレランス、マスタースレーブがあり、そこにはさまざまなものがあります。 これは明らかに通常のクラスターのように見えますが、とにかく、そのままでは使用できません。
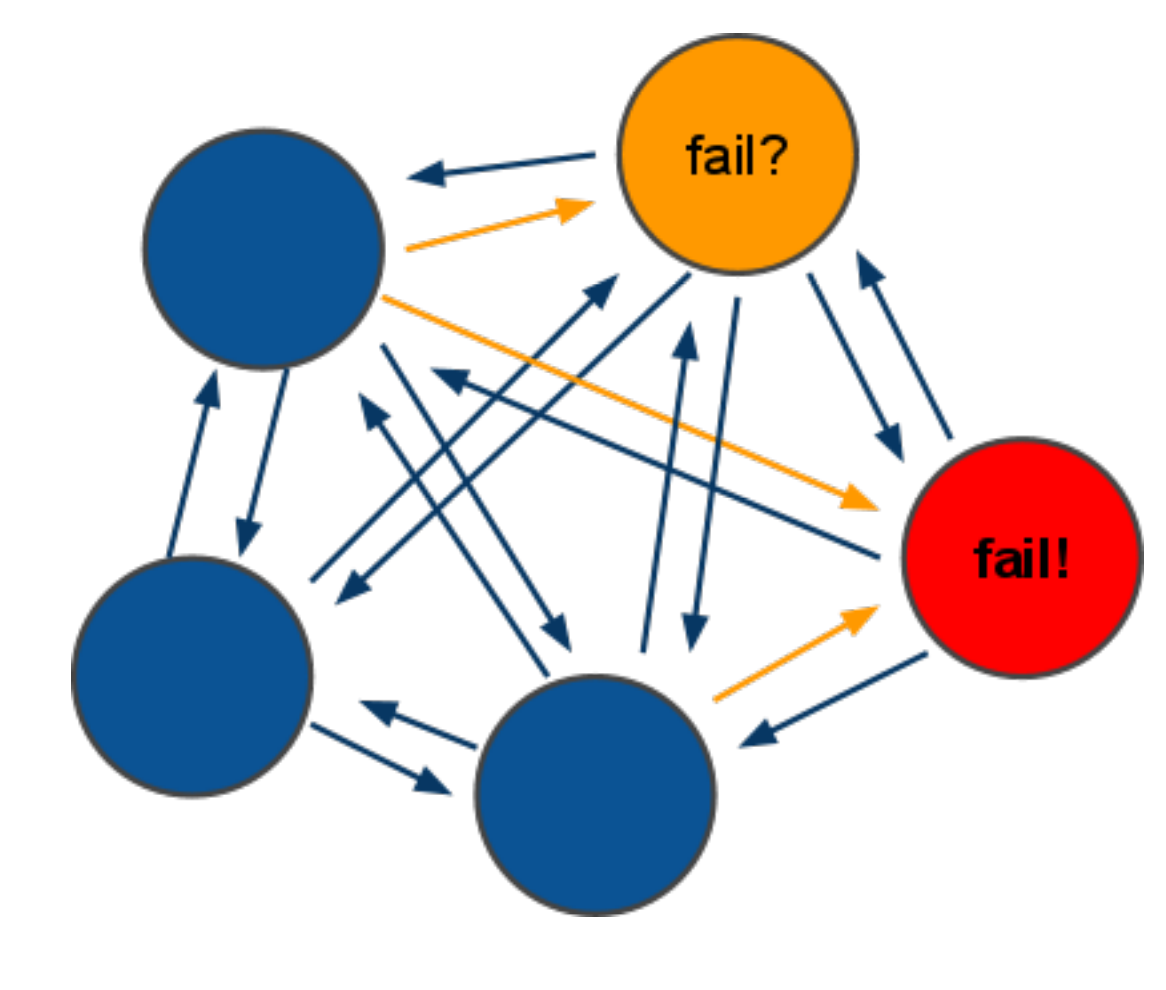
なぜ機能しないのか
これがなぜ機能しないのかを理解するには、内部でどのように機能するかを理解する必要があります。
第一に、ステンデロードからRedisクラスターを作成するまさにそのプロセスは、現在の形の荒野と屈辱です。 私たちの2017年には、誰もが「すべてをやった、すでにクラスターがあり、すべては大丈夫です!」などの発見、プロビジョニング、およびレポートに慣れていました。大根インスタンス、およびそれらをクラスターに接続します。 同様のことを信頼していますか? 確かに、約100500年前にそうだと思います。
OK、クラスターがあります。 さて、ちょっとした理論:クラスター内には、 ハッシュスロットのようなものがあります 。 本質的に、スロットは、特定のクラスターノードが担当するデータのセットを意味する数字です。 合計で16384個のスロットがあり、すべてのマスター間で均等に分割されています。
マスターといえば。 デフォルトでは、Redisクラスターは少なくとも3つのノードで構成でき、これらはすべてマスターになります。 したがって、彼らはスロットを共有します。
クラスターを使用することの2番目のニュアンスは、その信じられないほどの脆弱性です。 たとえば、3つのノードを持つクラスターでは、1つのノードが落ちました。 論理的な解決策は、作業を続けることです-データの66.6%がありますが、すべてがバラ色ではありません。 デフォルトの構成では、任意の要求、さらにはライブキーの要求に対して「CLUSTER IS DOWN」という応答があります。
たとえば、6つのノード(3つのマスターと3つのスレーブ)からのより大きなクラスターを考慮すると、状況が繰り返されます。 落下後、スレーブがマスターに自動的に昇格しますが、答えは同様です-「クラスターがダウンしています」。 これは秒です。ただし、この遅延はクラスター内のデータ量に依存します。
3番目の問題は顧客です。 より正確には、アプリケーションのコネクタ。 前のケースをとると、クラスターをプロモートしているときに、すべてのクライアントがクラスター内のすべてのマスターへの接続を維持するため、ソケットエラー、接続タイムアウトなどで落ちます。 これも完了する必要があります。
4番目の、そして最も不快なニュアンスの1つは、コマンドセットの変更です。 ワイルドカードを扱う標準的なチームは機能しません。これは驚くことではありません。 プロジェクト全体でこれをやり直し、アプリケーションにstendellとクラスターの両方で動作するように教える必要があります。 実際、これはRedisクラスターの実装の中で最も長く、最も高価な部分です。
動作させる方法
おそらくChefのLWRPを作成し、それを何らかの方法で通常にする以外は、プロビジョニングで最初のニュアンスを修正することはできません。 基本的に、それは私たちがやったことです。
しかし、2番目と3番目-これが私たちの能力です!
スロットの一部がない場合に「CLUSTER IS DOWN」を修正するのは非常に簡単で簡単です-設定パラメータを追加するだけです:
cluster-require-full-coverage no
落ちた顧客の問題は、少し時間をかけることで解決できます。 このプロジェクトでは、PHPとJavaの2つの言語を使用しているため、同じ作業を2回行う必要がありました。 一般的なアルゴリズムはそのようなステップに縮小されます:
- クライアントで「CLUSTER IS DOWN」を受け取ります-クラスタの再構築中
- このエラーを取得し、既存の機能していないslotmapuを保存します。
- 接続を一定回数再トレーニングし、新しいスロットマップを待っています。
- スロットマップが変更されたら、値を減算して喜ぶ。
スロットマップを変更すると、クラスターが動作状態になり、ある種のスレーブがすでにデータを賞賛し、それらを使用する準備ができたことを意味します。
6ノード以上のクラスターでは、データをディスクにフラッシュしても意味がないと言えば、誰にとっても秘密ではありません。 したがって、永続性を無効にすると、すべてが非常に高速に機能します。
結果

結果は何ですか?
- 優れたTTFBパフォーマンスを達成しました(現在、Redisにセッションを保存することを恐れていないため)。
- おそらく、世界で最高のローダーの進歩-私たちは成功しました-最も関連性の高い情報があります(これ以上関連性のあるものはありません!)
- Redis Clusterに入れて平和に眠るデータを恐れていません。
- アプリケーションの多くの部分の応答が速いため、SLAとユーザーエクスペリエンスが大幅に向上しています。
ここには、このような興味深い道があります。
一般に入手可能なツールをどのように使用しますか?
PS情報があなたにとって有用であり、あなたがこの方向で発展したいなら-私の個人的な電報チャンネルを購読してください : https : //goo.gl/1MnG9v
いつでも登録解除できます。 気に入ったらどうしますか?