この記事では、新しい追加を考慮してAIの別のレビューを行い、実際のプロジェクトでのAIの使用経験を共有します。
最初に、.NETサービスを開発するチームのカスペルスキーで働いています。 主に、ホスティングとしてAzureおよびAmazonクラウドプラットフォームを使用します。 当社のサービスは、数百万人のユーザーからのかなり高い負荷を処理し、高いパフォーマンスを提供します。 サービスに対する高い評価を維持し、それを達成するには、問題に非常に迅速に対応し、パフォーマンスに影響を与える可能性のあるボトルネックを見つけることが重要です。 同様の問題は、異常に高い負荷や不特定のユーザーアクティビティ、インフラストラクチャ(データベースなど)または外部サービスのさまざまな障害を生成するときに発生する可能性があり、誰もサービスロジックの軽微なバグをキャンセルしませんでした。
さまざまな診断システムを使用しようとしましたが、現時点では、AIはテレメトリーを収集および分析するための最もシンプルで柔軟なツールであることが証明されています。
AIは、診断テレメトリを収集および視覚化するためのクロスプラットフォームツールです。 たとえば、.NETアプリケーションがある場合、AIを接続するには、Microsoft AzureポータルでAIコンテナーを作成し、ApplicationInsigtsパッケージをナゲットアプリケーションに接続するだけです。
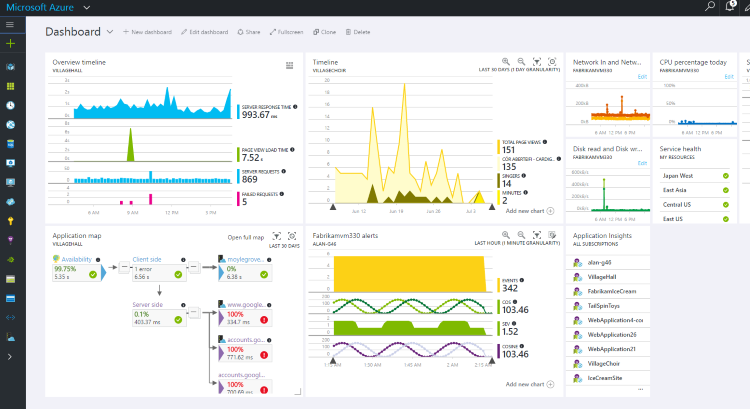
文字通り、AIはアプリケーションが実行されているマシン(メモリ、プロセッサ)のメインパフォーマンスカウンタに関する情報の収集を開始します。
アプリケーションコードを変更せずに、このようなサーバーテレメトリーの収集を開始できます。このためには、マシンに特別な診断エージェントをインストールするだけで十分です。 収集されたカウンターのリストは、ApplicationInsights.configファイルを編集して変更できます。
次に興味深い点は「依存関係の監視」です。 AIは、アプリケーションへのすべての発信外部HTTP呼び出しを追跡します。 外部呼び出しまたは依存関係は、データベースおよび他のサードパーティサービスに対するアプリケーションの呼び出しとして理解されます。 アプリケーションがIISインフラストラクチャでホストされているサービスである場合、AIはすべての外部リクエストを含むサービスへのすべてのリクエストのテレメトリをインターセプトします(CallContextストリームを介して追加の診断情報を転送するため)。 つまり、これのおかげで、興味のあるリクエストを見つけることができ、すべての依存関係を見ることができます。 アプリケーションマップを使用すると、アプリケーションの外部依存関係の完全なマップを表示できます。
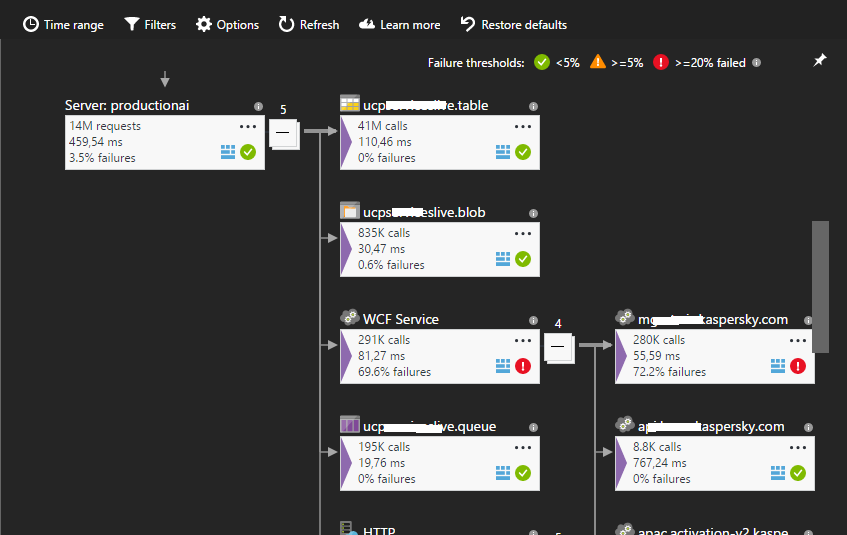
システムに外部サービスに関する明らかな問題がある場合、理論的にはこの図から問題に関する情報を得ることができます。
外部リクエストに関する情報のより詳細な調査のために、さらに深く掘り下げることができます
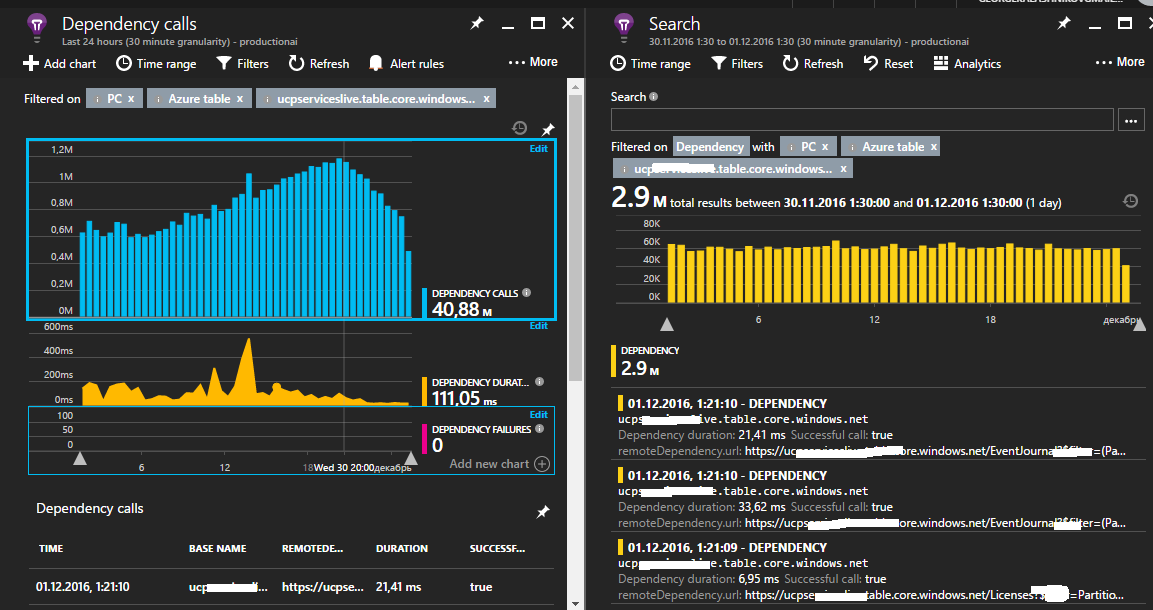
プラットフォームに関係なく、拡張可能なApplication Insights APIをアプリケーションに接続して、任意のテレメトリを保存できます。 ログまたはいくつかのカスタムパフォーマンスカウンターを指定できます。
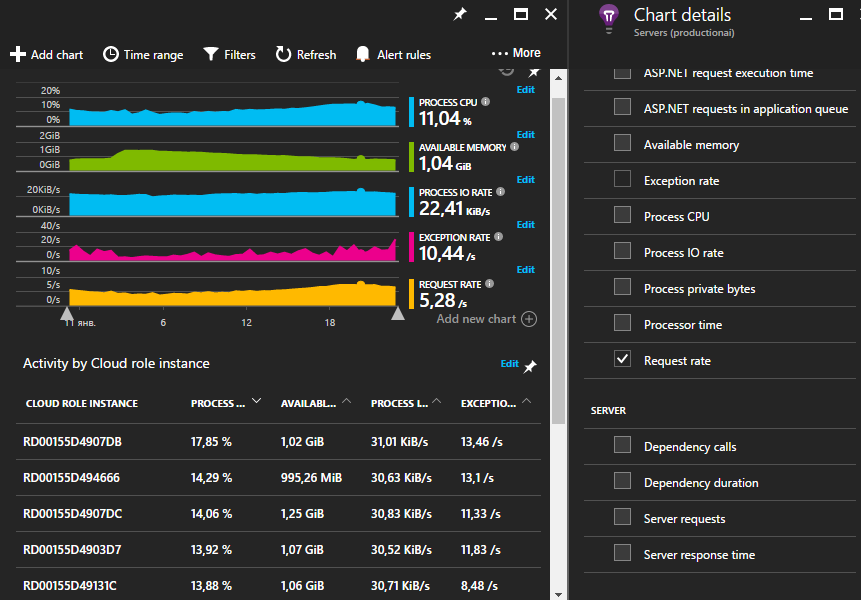
たとえば、呼び出しの数、エラーの割合、操作の時間など、サービスのすべての主要なメソッドに関する情報をAIに集約して書き込みます。 さらに、外部サービスのパフォーマンスと可用性、メッセージキュー(Azure Queue、ServiceBus)のサイズ、処理のスループットなど、アプリケーションの重要な領域に関する情報を保存します。
先ほど書いた依存関係の監視はかなり強力なツールですが、現時点ではすべての発信HTTP要求のみを自動的にインターセプトできるため、別のトランスポートを介して呼び出された依存関係に基づいて、テレメトリを個別に記述する必要があります。 私たちの場合、これらはカスタムプロトコルで動作するAzure ServiceBusとRMQです。
収集するテレメトリは、フラットな構造(counterName-counterValue)である必要はありません。 さまざまなネストを持つマルチレベル構造が含まれる場合があります。 これは、動的データ型を使用して実現されます。
サンプルのメトリック構造
{ "metric": [ ], "context": { ... "custom": { "dimensions": [ { "ProcessId": "4068" } ], "metrics": [ { "dispatchRate": { "value": 0.001295, "count": 1.0, "min": 0.001295, "max": 0.001295, "stdDev": 0.0, "sampledValue": 0.001295, "sum": 0.001295 } }, "durationMetric": { "name": "contoso.org", "type": "Aggregation", "value": 468.71603053650279, "count": 1.0, "min": 468.71603053650279, "max": 468.71603053650279, "stdDev": 0.0, "sampledValue": 468.71603053650279 } } ] } }
AIは1年前に同様の洗練されたテレメトリを作成することを許可しましたが、使用することは実質的に不可能でした。 当時、チャートは単純なメトリックを使用してのみ作成できました。 このテレメトリを使用する唯一のオプションは、発生頻度のみを推定できるカスタムクエリでした。 非常に強力な分析ツールが登場しました。
このツールを使用すると、テレメトリにさまざまなクエリを記述し、特別な(SQLに似た)言語を使用して任意のイベントのプロパティにアクセスできます。
構文の例として、過去10分間にWebアプリケーションに成功したクエリのうち10件を表示するクエリを見ることができます。
requests | where success == "True" and timestapm > ago(10m) | take 10
この言語には、分析(関数と接続の集約、百分位数、中央値の検索、レポートの作成など)およびテレメトリをグラフ形式で視覚化するための多くの既製の演算子が付属しています。
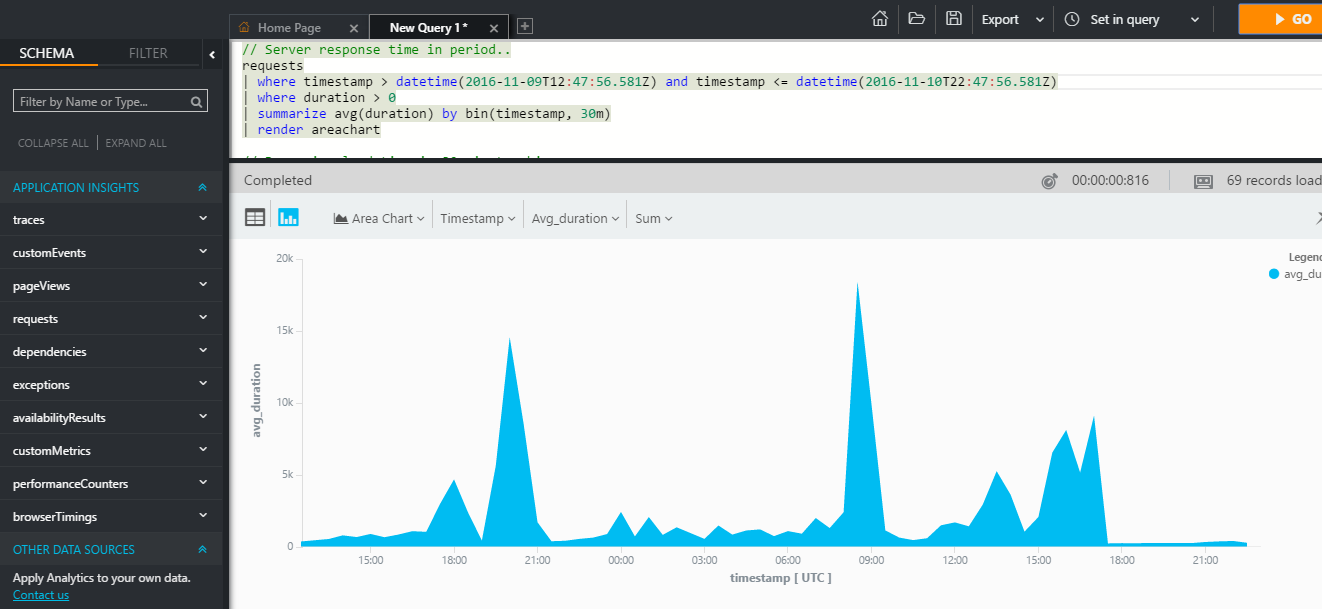

このような情報は、パフォーマンス分析と、ビジネス上の問題を解決するための分析の取得の両方に使用できます。 たとえば、AIアナリティクスを使用して、ほとんどすぐに使用できる何らかのオンラインストアを開発している場合、地理的な場所に応じて顧客の好みを知ることができます。
AIの構成には、ProactiveDetectionコンポーネントが含まれています。これは、機械学習アルゴリズムに基づいて、収集されたテレメトリの異常を特定できます。 たとえば、サービスへのリクエストの数が急激に増加または減少し、エラーの数または一部の操作の合計時間が増加しました。
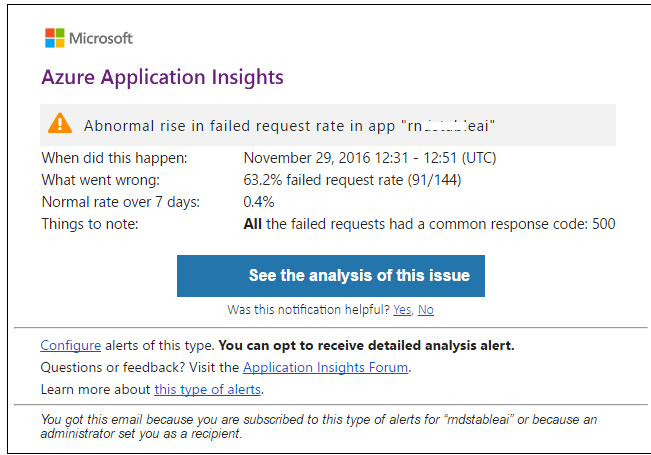
必要なテレメトリカウンターのアラートを構成することもできます。
AIは30日間テレメトリを保存します。 これで十分でない場合は、継続エクスポート機能を使用して、テレメトリをAzure Blobsにエクスポートできます。 Azure Stream Analyticsを使用して、エクスポートされたテレメトリで関心のあるパターンを検索することをお勧めします。
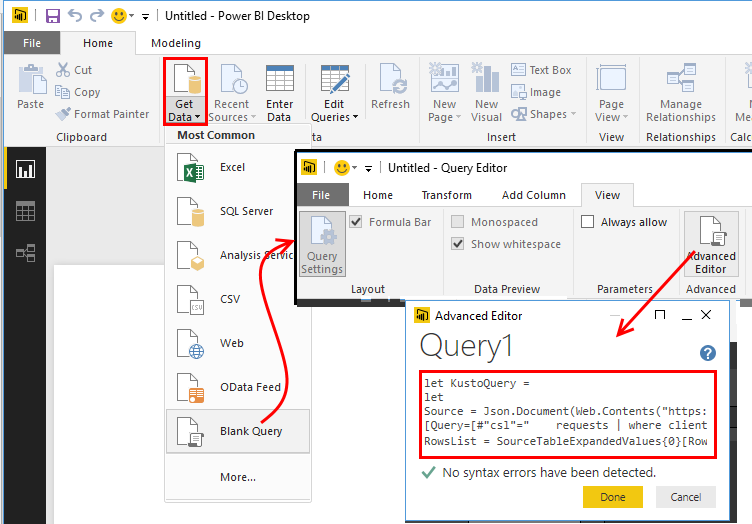
Power BIは、データの視覚化と分析のための強力なツールです。 特別なApplication Insights Power BIアダプターを接続して、一部の診断をPower BIに自動的に転送できます。 これを行うには、Analyticsで目的のクエリを作成し、エクスポートボタンをクリックします。 この結果、AIデータソースとして使用される小さなMスクリプトが取得されます。

システムの状態をリアルタイムで監視すると便利な場合があります。 これは、更新プログラムのインストール後に特に当てはまります。 ごく最近、Live Metrics StreamツールがAIに登場しました。

AIは監視サービスとしても機能します。 アプリケーションの正常性をテストするテストをVisual Studioからインポートできます。 または、AIポータルから一連のチェックを直接作成して、関心のあるエンドポイントの可用性の地理的に分散した検証を行うことができます。 AIはスケジュールされたチェックを実行し、適切なスケジュールで結果を表示します。
また、dabegでデバッグされたアプリケーションからのテレメトリをVisual Studioで直接表示できる特別なプラグインもあります。
これらはすべてのツールとはほど遠いものです。 また、ユーザーのテレメトリの分析にAIを使用することをお勧めします。
現在、AIはいわゆるセーブポイントの数に応じて課金されます。 100万は約100 pかかります。 1つのセーブポイントは1つの診断イベントに対応します。 なぜなら AIクライアント自体はテレメトリを集計しません。アプリケーションが集計自体を処理することをお勧めします。
この推奨事項は、AIを調整しても1秒あたり300を超える診断イベントを保存できないという前提に基づいている必要があります。 依存関係はますます難しくなっています。
たとえば、当社のサービスでは、データベースは毎秒約1万回呼び出されます。 AIはリクエストの全体的なレートを保持しますが、詳細情報(期間、URL、リターンコードなど)は数百のリクエストに対してのみ保存され、他のリクエストのデータは失われます。 それにもかかわらず、発生する問題を特定するのに十分なデータがあります。
分析およびその他の新機能のおかげで、AIはすでにサービスのいくつかの深刻なパフォーマンスの問題を特定するのに役立ちました。
このツールのさらなる開発を引き続き監視しています。