
Google Deepmindの成功が知られ、話題になっています。 DQN(Deep Q-Network)アルゴリズムは、ますます多くのゲームで人間をかなりのマージンで打ち負かしています。 近年の成果は印象的です。ほんの数十分のトレーニングで、アルゴリズムが学習し、卓球や他のAtariゲームで人を獲得します。 最近、彼らは三次元に入りました-彼らはリアルタイムでDOOMの人を打ち負かします、そして、車とヘリコプターを制御することも学びます。
DQNは、数千のゲームを単独でプレイしてAlphaGoをトレーニングするために使用されました。 それがまだ流行していなかったとき、2015年にこの傾向の発展を予想して、アレクセイ・スパスキーに代表されるフォボスの経営者は研究開発部門に研究を行うよう命じました。 管理ゲームの勝利を自動化するためにそれらを使用する可能性のために、機械学習の既存の技術を考慮する必要がありました。 したがって、この記事では、生産性を向上させるための、生きているチームに対する仮想マネージャーのゲームにおける自己学習アルゴリズムの設計について説明します。
機械学習データの分析に適用されるタスクには、従来、次の解決手順があります。
- 問題の定式化;
- データ収集;
- データ準備;
- 仮説の定式化;
- モデル構築;
- モデル検証;
- 結果のプレゼンテーション。
この記事では、インテリジェントエージェントの設計における重要な決定について説明します。
問題のステートメントから結果の表示までの段階のより詳細な説明は、読者が興味を持っている場合、以下の記事で説明されます。 したがって、おそらく、理解を失うことなく、研究の多次元的で曖昧な結果に関する物語の問題を解決できるでしょう。
アルゴリズムの選択
そのため、チーム管理の最大効率を見つけるタスクを完了するために、強化されたディープラーニング、つまりQラーニングを使用することが決定されました。 インテリジェントエージェントは、環境の新しい状態への移行からの報酬または罰に基づいて、利用可能なアクションから各アクションのユーティリティ関数Qを形成します。これにより、行動戦略を選択する機会が与えられますが、ゲーム環境との以前のやり取りの経験を考慮することができます。
DQNを選択する主な理由は、この方法でエージェントをトレーニングするために、トレーニングまたはアクションの選択にモデルが必要ないためです。 これは、実用的な予測力を持つ人々の集合の形式化されたモデルがまだ存在しないという単純な理由で、教育方法の重要な要件です。 それにもかかわらず、論理ゲームにおける人工知能の成功の分析は、環境がより複雑になるにつれて、エキスパートベースのアプローチの利点がより顕著になることを示しています。 これはチェッカーとチェスにあり、モデルに基づくアクションの評価はQラーニングよりも成功しました。
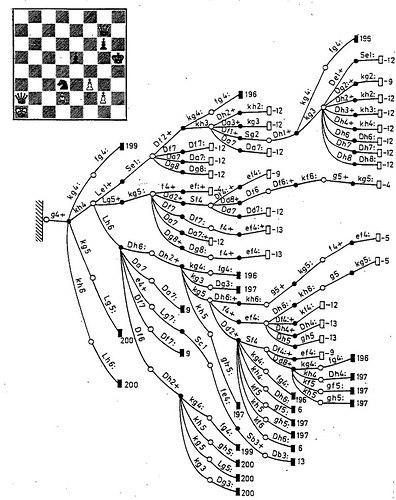
強化訓練が仕事なしで事務員を残さない理由の1つは、この方法がうまくスケールしないことです。 環境調査を行うQ学習エージェントは、Qファンクションを作成するために各状況で各アクションを繰り返し適用し、あらゆる状況で起こりうるすべてのアクションの収益性を評価しなければならない積極的な学生です。

古いビンテージゲームのように、アクションの数がジョイスティックのボタンの数で計算され、状態がボールの位置で計算される場合、エージェントは人を倒すために訓練するのに数十分と数時間かかります。そして、学生が通過する可能性のある宇宙行動。
仮説とモデル
Qラーニングを効果的に使用してチームを管理するには、環境条件とアクションの次元を最小限に抑える必要があります。
当社のソリューション:
- 最初のエンジニアリングソリューションは、管理アクティビティを一連のミニゲームの形で提示することでした。 それぞれに個別の量の状態とアクションがあり、組み合わせの順序はゲームの問題の解決に匹敵します。 したがって、多次元空間で最適な制御戦略を求めるアルゴリズムを構築する必要はありませんが、多くのエージェントは戦術ゲームの人間のプレーヤーよりも優れています。 このようなゲームの例は、YouTrackのタスク管理です。 環境の状態(大まかに)-作業時間とステータス、およびアクション-開始、再発見タスク、責任者の任命。 詳細は以下をご覧ください。
簡単なゲームをオンラインで学習する例:
https://cs.stanford.edu/people/karpathy/convnetjs/demo/rldemo.html
- 各オフィスの従業員は、環境と彼のさまざまな行動を複雑にしているインテリジェントなエージェントです。 パーソナライズにより、マルチエージェント環境を回避できるため、1人の従業員と1人のトレーニングエージェントが対戦します。 タスク設定のミニゲームでは、従業員がより効率的に作業する(タスクをより速く解決する)と、エージェントは報酬を受け取ります。 従業員(開発者など)がQラーニングエージェントを管理できない場合、アルゴリズムは収束しません。
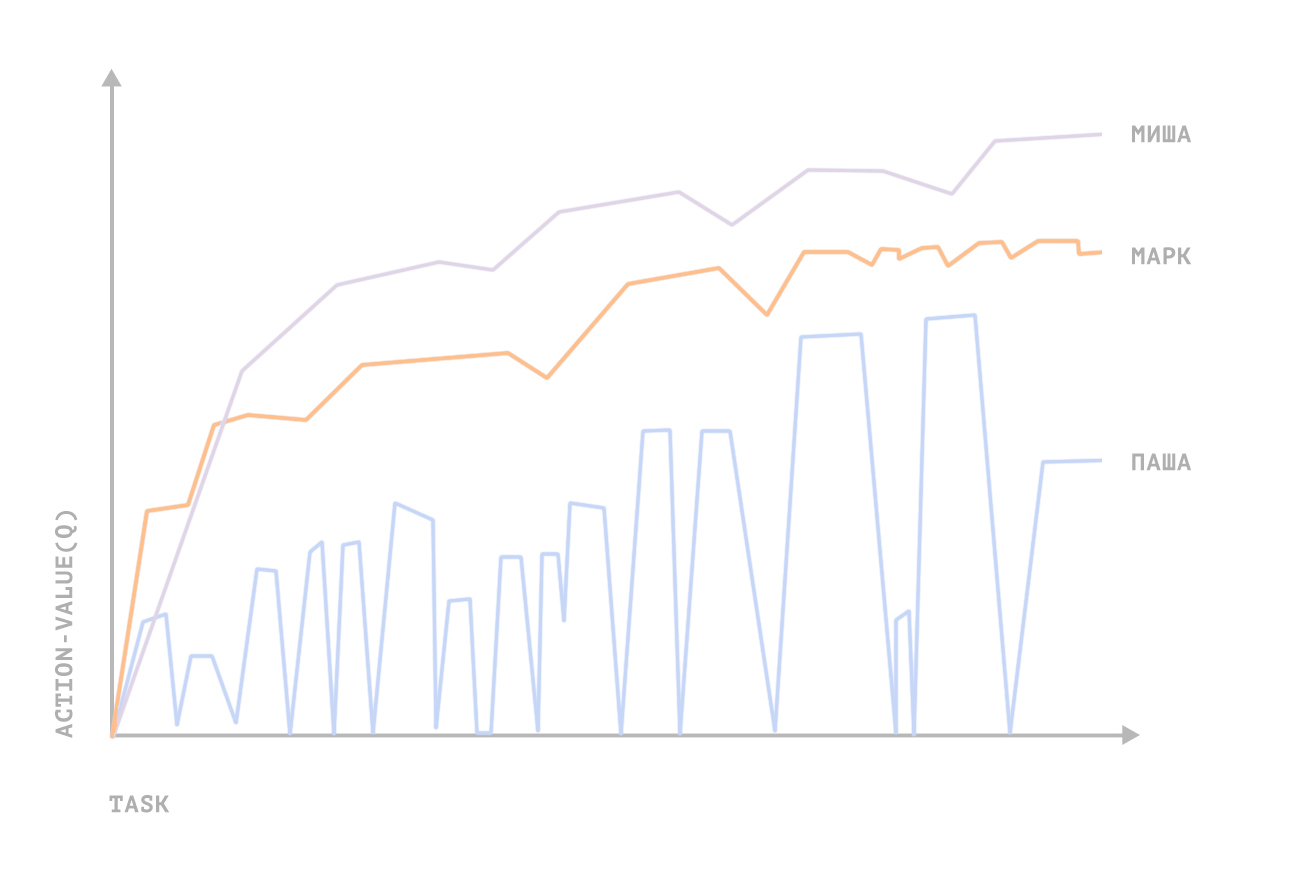
- 最も重要な単純化。 従業員にタスクを設定するためのミニゲームでは、タスクに費やされる時間パラメーターのためだけに、継続的な多次元ゲーム状態があります。 そして、最悪の部分は、エージェントの行動に対する報酬が明らかでないことです ゲーミング環境は、各ミニゲームの条件の有限セットおよびある州または別のプロモーションの計算として、マネージャーのビジネスロジックによって90%正式に定められています。 これは最も時間のかかる重要なポイントです。なぜなら、環境と行動の暗黙的なモデルであり、エージェントのトレーニングにおける報酬の量を決定する専門知識が含まれている状態の専門家評価の公式にあるからです。 エージェントトレーニングの成功は、この暗黙的なモデルの予測力に依存していました。
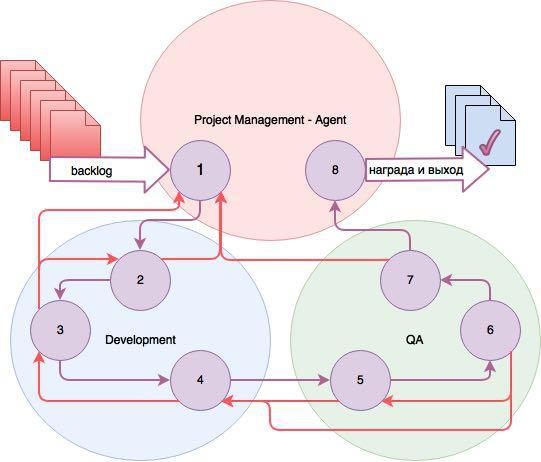
この図は、タスクの作業の進行を制御する3人のエージェントの3つのゲーム環境の状態を示しています。
ステータス:
- 登録されたタスク(バックログ);
- タスクは開いています。
- 仕事中;
- 開発が完了し、タスクはテスト用に開いています(QA)。
- テスト用にオープン;
- テスト中;
- 準備完了、テスト済み。
- 閉じた。
3つのエージェントのそれぞれのアクションのリストは異なります。 プロジェクトマネージャー-エージェントは、エグゼキューターとテスター、タスクの時間と優先度を割り当てます。 DevとQAで作業するエージェントは、各エグゼキューターとテスターに個人的です。 タスクがさらに進んだ場合、タスクが戻ってきた場合、エージェントは報酬を受け取ります-罰。
すべてのエージェントは、タスクを閉じるときに最大の報酬を受け取ります。 また、Qトレーニングの場合、DFとLF(それぞれ割引率と学習率)が選択されたため、エージェントはタスクの終了に特に焦点を合わせました。 一般的な場合の補強の計算は、とりわけ、時間と実際のコストの見積りの差、タスクのリターン数などを考慮して、最適な制御式に従って行われます。 このソリューションの利点は、大規模なチームに対するスケーラビリティです。
おわりに
計算が実行されたハードウェアはGeForce GTX 1080です。
Youtrackでタスクを設定および管理する上記のミニゲームでは、5人中3人で制御機能が平均を超える値に収束しました(従業員の生産性は人間のマネージャーと比較して増加しました)。 テストに満足したテストグループの従業員はいませんでした。 不満4; 1つは評価を控えました。
それにもかかわらず、「戦い」の方法を使用するには、心理学の専門知識をモデルに導入する必要があるという結論を導き出しました。 開発とテストの合計期間は1年以上です。