
Rツリーと比較したZ次曲線に基づくインデックスには、多くの利点があります。
- 通常のBツリーとして実装されていますが、
- さらに、Bツリーページはより優れた入力可能性を備えており、
- Zキー自体はよりコンパクトです
- Rツリーとは異なり、Bツリーには自然なトラバース順序があります
- Bツリーの構築が高速化
- Bツリーのバランスがとれている
- Bツリーは、ページ分割/ヒューリスティックのマージに依存せず、より理解しやすい
- Bツリーは絶えず変化しても劣化しません
- ...
ただし、Zオーダーに基づくインデックスには欠点があります-比較的低いパフォーマンスです:)。 カットの下で、この欠点が何に関係しているか、そしてそれを使って何かを行うことができるかどうかを理解しようとします。
おおよそ、Z曲線の意味は次のとおりです。結果として、x座標とy座標のビットを1つの値で交互に入れ替えます。 例は(x = 33( 010 0001 )、y = 22( 01 0110 )、Z = 1577( 0 1 1 0 0 0 1 0 1 0 0 1 )。2つのポイントの座標が近い場合、Z-それらの値は近くなります。
3次元(またはそれ以上)バージョンも同様に配置され、3(またはそれ以上)の座標の数字を交互に並べます。
また、特定の範囲で検索するには、この範囲のZ曲線のすべての値を「ラスタライズ」し、連続した間隔を見つけて、それぞれを検索する必要があります。
エクステント[111000 ... 111000] [111400 ... 111400](675間隔)、右上隅(各連続ポリラインは1間隔)の図です。
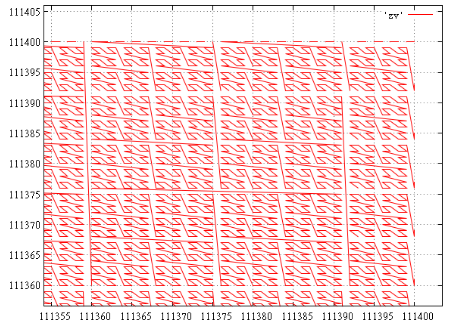
また、たとえば、範囲[111000 ... 111000] [112000 ... 112000]の場合、1688の連続した間隔が得られます。明らかに、その数は主に境界の長さに依存します。 将来を見ると、テストデータでは、6間隔で15ポイントがこの範囲に入りました。
はい、これらの間隔のほとんどは、1つの値から縮退するまで小さくなります。 それにもかかわらず、このすべての範囲に値が1つしかない場合でも、その値は任意の間隔にあります。 そして、それが好きかどうかにかかわらず、1688個すべてのサブクエリを実行して、実際にポイントがいくつあるかを調べる必要があります。
左下の値から右上のすべてを表示することはオプションではありません。この場合の角度の違いは3 144 768です。3倍以上のデータを見る必要があり、これは最悪の場合とはほど遠いです。 たとえば、エクステント[499500 ... 499500] [500500 ... 500500]は、135,263,808の値の範囲(エクステント領域の135倍)を提供します。
そして、ここで伝統的な質問をすることができます-
もしも...
一般に空のインデックスがあると仮定すると、これを理解するためにこれらの数百および数千のサブクエリをすべて実行する必要がありますか? いいえ、1つで十分です-左下から右上へ。
ここで、範囲が十分に小さく、データがまばらで、何かを見つける可能性が小さいとします。 隅から隅まで同じリクエストを実行してみましょう。 何も見つからなかった場合、何もありません。 そうでなければ、チャンスがあります。 しかし、見たように、隅から隅へのリクエストによってスイープされた領域は、検索範囲よりも何倍も大きくなる可能性があり、明らかに不要なデータを読み取る必要はありません。 したがって、カーソル全体を表示するのではなく、そこから最小のZ値のみを取得します。 これを行うには、クエリは(order by)および(top 1)を使用して実行されます。
ですから、何らかの意味があります。 この値が私たちの範囲からではないと仮定すると、それは何を与えることができますか? [1 ... N]のサブクエリ範囲のソートされた配列があることを思い出してください。 バイナリ検索を実行し、mとm + 1の間であっても、この値が絞り込まれるサブクエリを見つけます。 驚くべきことに、それは1からmまでのリクエストを省略することができることを意味し、明らかにそこには何もない。
値が私たちの範囲に属している場合、それは私たちの範囲の1つに入り、mではありますが、どれであるかを見つけることもできます。 前と同様に、番号1 ... m-1のリクエストは省略できます。 しかし、番号mの間隔は、その中にあるすべてのものを私たちに与える別個の要求に値します。
まあ、まだデータが残っているかもしれないので、続けましょう。 再度、リクエストを実行しますが、コーナーからコーナーではなく、間隔m + 1の開始から右上コーナーまでです。 そして、間隔のリストの最後に達するまでこれを行います。
これが全体の考え方です。大量のデータや大量のデータが範囲内に入った場合でも正常に機能することに注意してください。 一見すると、これはリクエストの数を根本的に減らし、作業を高速化します。
アイデアを実際にテストするときが来ました。 テストサイトとして、 PostgeSQL 9.6.1、 GiSTを使用します。 測定は2つのコアと4 GBのRAMを備えた控えめな仮想マシンで実行されたため、時間には絶対値はありませんが、読み取られたページ数は信頼できます。
ソースデータ
エクステント[0 ... 1 000 000] [0 ... 1 000 000]の1億個のランダムポイントがデータとして使用されました。
2次元のポイントデータのテーブルを取得してみましょう。
create table test_points (x integer,y integer);
データを作成します。
gawkスクリプト
BEGIN {
for(i = 0; i <100000000; i ++)
{
x = int(1000000 * rand());
y = int(1000000 * rand());
print x "\ t" z;
}
exit(0);
}
for(i = 0; i <100000000; i ++)
{
x = int(1000000 * rand());
y = int(1000000 * rand());
print x "\ t" z;
}
exit(0);
}
結果のファイルを並べ替え(以下の説明)、COPY演算子を使用してテーブルに入力します。
COPY test_points from '/home/.../data.csv';
テーブルへの入力には数分かかります。 データサイズ(\ dt +)-4358 Mb
Rツリー
対応するインデックスは次のコマンドで作成されます:
create index test_gist_idx on test_points using gist ((point(x,y)));
しかし、ニュアンスがあります。 インデックスは非常に長い間ランダムデータに基づいて作成されます(いずれの場合も、作成者には一晩で作成する時間がありませんでした)。 事前に並べ替えられたデータの構築には、約1時間かかりました。
インデックスサイズ(\ di +)-9031 Mb
基本的に、テーブル内のデータの順序は重要ではありませんが、さまざまな方法に共通する必要があるため、ソートされたテーブルを使用する必要がありました。
テストリクエストは次のようになります。
select count(1) from test_points where point(x,y) <@ box(point("xmin","ymin"),point("xmax","ymax"));
通常のインデックスの検証
パフォーマンスをテストするために、xとyによって個別のインデックスで空間クエリを実行します。 次のように作成されます。
create index x_test_points on test_points (x); create index y_test_points on test_points (y);
数分かかります。
テストリクエスト:
select count(1) from test_points where x >= "xmin" and x <= "xmax" and y >= "ymin" and y <= "ymax";
Z-index
ここで、x、y座標をZ値に変換できる関数が必要です。
最初に、 拡張子を作成し、その中に関数を作成します。
CREATE FUNCTION zcurve_val_from_xy(bigint, bigint) RETURNS bigint AS 'MODULE_PATHNAME' LANGUAGE C IMMUTABLE STRICT;
彼女の体:
static uint32 stoBits[8] = {0x0001, 0x0002, 0x0004, 0x0008, 0x0010, 0x0020, 0x0040, 0x0080}; uint64 zcurve_fromXY (uint32 ix, uint32 iy) { uint64 val = 0; int curmask = 0xf; unsigned char *ptr = (unsigned char *)&val; int i; for (i = 0; i < 8; i++) { int xp = (ix & curmask) >> (i<<2); int yp = (iy & curmask) >> (i<<2); int tmp = (xp & stoBits[0]) | ((yp & stoBits[0])<<1) | ((xp & stoBits[1])<<1) | ((yp & stoBits[1])<<2) | ((xp & stoBits[2])<<2) | ((yp & stoBits[2])<<3) | ((xp & stoBits[3])<<3) | ((yp & stoBits[3])<<4); curmask <<= 4; ptr[i] = (unsigned char)tmp; } return val; } Datum zcurve_val_from_xy(PG_FUNCTION_ARGS) { uint64 v1 = PG_GETARG_INT64(0); uint64 v2 = PG_GETARG_INT64(1); PG_RETURN_INT64(zcurve_fromXY(v1, v2)); }
これで(もちろんCREATE EXTENSIONの後)、Z-indexは次のように構築されます:
create index zcurve_test_points on test_points(zcurve_val_from_xy(x, y));
これには数分かかります(データの並べ替えは不要です)。
インデックスサイズ(\ di +)-2142 Mb(Rツリーよりも4倍小さい)
Z-Index検索
したがって、最初の(「単純」と呼ぶ)バージョンでは、次のようにします。
- サイズdx * dyのエクステントの場合、対応するサイズの識別子の配列を開始します
- 範囲内の各ポイントについて、Z値が計算されます
- 識別子の配列を並べ替える
- 連続間隔を見つける
- 間隔ごとに、次の形式のサブクエリを実行します。
select * from test_points where zcurve_val_from_xy(x, y) between $1 and $2
- 結果を得る
このオプションを使用して検索するには、関数(下の本文)を使用します。
CREATE FUNCTION zcurve_oids_by_extent(bigint, bigint, bigint, bigint) RETURNS bigint AS 'MODULE_PATHNAME' LANGUAGE C IMMUTABLE STRICT;
この関数を使用した空間クエリは次のようになります。
select zcurve_oids_by_extent("xmin","ymin","xmax","ymax") as count;
この関数はヒット数のみを返します。データ自体は、必要に応じて「 elog(INFO ...) 」を使用して表示できます。
2番目の改善された(「サンプル」と呼びましょう)オプションは次のとおりです。
- サイズdx * dyのエクステントに対して、対応するサイズの識別子の配列を開始します
- 範囲内の各ポイントについて、Z値が計算されます
- 識別子の配列をソートします
- 連続間隔を見つける
- 見つかった最初の間隔から開始します。
- 次のタイプの「テスト」リクエストを実行します(パラメーター-間隔の境界):
select * from test_points where zcurve_val_from_xy(x, y) between $1 and $2 order by zcurve_val_from_xy(x, y) limit 1
- このクエリは、現在のテスト間隔の開始から検索範囲の終了までのZ値が最小のテーブルの行を提供します。
- 要求で何も見つからなかった場合、検索範囲にデータが残っていないため、終了します。
- これで、見つかったZ値を分析できます。
- いずれかの間隔に収まるかどうかを確認します。
- そうでない場合は、次の残りの間隔の番号を見つけて、ステップ5に進みます。
- ひどい場合は、このタイプの間隔でクエリを実行します。
select * from test_points where zcurve_val_from_xy(x, y) between $1 and $2
- 次の間隔を取り、ステップ5に進みます。
- 次のタイプの「テスト」リクエストを実行します(パラメーター-間隔の境界):
このオプションを使用して検索するには、次の関数を使用します。
CREATE FUNCTION zcurve_oids_by_extent_ii(bigint, bigint, bigint, bigint) RETURNS bigint AS 'MODULE_PATHNAME' LANGUAGE C IMMUTABLE STRICT;
この関数を使用した空間クエリは次のようになります。
select zcurve_oids_by_extent_ii("xmin","ymin","xmax","ymax") as count;
また、この関数はヒット数のみを返します。
ラスタライズ
説明されているアルゴリズムでは、間隔のリストを取得するために、非常に単純で非効率的な「ラスタライズ」アルゴリズムが使用されています。
一方、彼の作品の平均時間を適切なサイズのランダムな範囲で測定することは難しくありません。 ここにあります:
| エクステントdx * dy | SERPの予想される平均ポイント数 | 時間、ミリ秒 |
|---|---|---|
| 100X100 | 1 | .96(.37 + .59) |
| 316X316 | 10 | 11(3.9 + 7.1) |
| 1000X1000 | 100 | 119.7(35 + 84.7) |
| 3162X3162 | 1000 | 1298(388 + 910) |
| 10000X10000 | 10,000 | 14696(3883 + 10813) |
結果
データを含むピボットテーブルを次に示します。
| Nポイント | 種類 | 時間(ミリ秒) | 読みます | 共有ヒット |
|---|---|---|---|---|
| 1 | X&Y
rtree Z値 Z値II | 43.6
.5 8.3(9.4) 1.1(2.2) | 59.0173
4.2314 4.0988 4.1984(12.623) | 6.1596
2.6565 803.171 20.1893(57.775) |
| 10 | X&Y
rtree Z値 Z値II | 83.5
.6 15(26) 4(15) | 182.592
13.7341 14.834 14.832(31.439) | 9.24363
2.72466 2527.56 61.814(186.314) |
| 100 | X&Y
rtree Z値 Z値II | 220
2.1 80(200) 10(130) | 704.208
95.8179 95.215 96.198(160.443) | 16.528
5.3754 8007.3 208.214(600.049) |
| 1000 | X&Y
rtree Z値 Z値II | 740
12 500(1800) 200(1500) | 3176.06
746.617 739.32 739.58(912.631) | 55.135
25.439 25816 842.88(2028.81) |
| 10,000 | X&Y
rtree Z値 Z値II | 2,500
70 ... 1 200 4700(19000) 1300(16000) | 12393.2
4385.64 4284.45 4305.78(4669) | 101.43
121.56 86274.9 5785.06(9188) |
タイプ -
- 'X&Y'-xおよびyによる個々のインデックスの使用
- 'rtree'-Rツリーを介した要求
- Z値-間隔を置いた公正な検索
- 'Z-value-ii'-サンプルを使用して間隔で検索
時間(ミリ秒) -リクエスト実行の平均時間。 これらの条件下では、値は非常に不安定で、DBMSキャッシュ、仮想マシンのディスクキャッシュ、およびホストシステムのディスクキャッシュに依存します。 ここで参照する可能性が高くなります。 Z-valueおよびZ-value-iiには、2つの数値が与えられます。 括弧内は実際の時間です。 括弧なし-時間から「ラスタライズ」のコストを引いたもの。
読み取り -要求ごとの読み取りの平均数(EXPLAIN(ANALYZE、BUFFERS)を介して受信)
共有ヒット -バッファの呼び出し回数(...)
Z-value-iiの場合、読み取りと共有のヒット列に2つの数値が表示されます。 括弧内は測定値の総数です。 括弧なし-order byおよびlimit 1を使用したクエリの調査を除く したがって、そのような要求に関する統計は不要と見なされましたが、参照用に提供されました。
ホットサーバーと仮想マシンでの2回目の実行で時間が表示されます。 読み取られたバッファーの数は、新しく生成されたサーバー上にあります。
すべてのタイプのクエリで、テーブル自体のデータはインデックスに属していませんでした。 ただし、これは同じテーブルからの同じデータであるため、すべての種類のクエリで定数値を取得しました。
結論
- Rツリーは静的な状態では依然として非常に優れており、ページ読み取りの効率は非常に高くなっています。
- ただし、Zオーダーインデックスは、必要なデータがないページを読み取る必要がある場合があります。 これは、テストカーソルが間隔の間にある場合に発生し、この間隔には多くの外部ポイントが存在する可能性があり、特定のページには集計データが含まれません。
- それにもかかわらず、より高密度のパッケージングにより、Zオーダーは実際に読み取られるページ数においてRツリーに近くなります 。 これは、 潜在的に Zオーダーが同様のパフォーマンスを生成できることを示唆しています。
- Zオーダーインデックスは、キャッシュから膨大な数のページを読み取ります。 要求は同じ場所で何度も行われます。 一方、これらの測定値は比較的安価です。
- 大規模なクエリでは、Zオーダーの速度がRツリーよりも大幅に低下します。 これは、サブクエリを実行するために高レベルで高速ではない機構であるSPIを使用するという事実によって説明されます。 そして、もちろん「ラスタライズ」では、何かをする必要があります。
- 一見、間隔サンプルを使用しても作業が大幅に加速されることはありませんでしたが、正式にはページ読み取りの統計がさらに悪化しました。 ただし、これは使用する必要があった高レベルの資金のコストであることを理解する必要があります。 潜在的に、Zオーダーベースのインデックスは、パフォーマンスの点ではRツリーより悪くなく、他の戦術的および技術的特性の点でははるかに優れています。
見込み
同等の条件でRツリーと競合できるZオーダーに基づいた本格的な空間インデックスを作成するには、次の問題を解決する必要があります。
- 範囲ごとのサブインターバルのリストを取得するための安価なアルゴリズムを考え出す
- インデックスツリーへの低レベルアクセスに切り替える
幸いなことに、これらの両方は不可能とは思えません。
ソースコード
#include "postgres.h" #include "catalog/pg_type.h" #include "fmgr.h" #include <string.h> #include "executor/spi.h" PG_MODULE_MAGIC; uint64 zcurve_fromXY (uint32 ix, uint32 iy); void zcurve_toXY (uint64 al, uint32 *px, uint32 *py); static uint32 stoBits[8] = {0x0001, 0x0002, 0x0004, 0x0008, 0x0010, 0x0020, 0x0040, 0x0080}; uint64 zcurve_fromXY (uint32 ix, uint32 iy) { uint64 val = 0; int curmask = 0xf; unsigned char *ptr = (unsigned char *)&val; int i; for (i = 0; i < 8; i++) { int xp = (ix & curmask) >> (i<<2); int yp = (iy & curmask) >> (i<<2); int tmp = (xp & stoBits[0]) | ((yp & stoBits[0])<<1) | ((xp & stoBits[1])<<1) | ((yp & stoBits[1])<<2) | ((xp & stoBits[2])<<2) | ((yp & stoBits[2])<<3) | ((xp & stoBits[3])<<3) | ((yp & stoBits[3])<<4); curmask <<= 4; ptr[i] = (unsigned char)tmp; } return val; } void zcurve_toXY (uint64 al, uint32 *px, uint32 *py) { unsigned char *ptr = (unsigned char *)&al; int ix = 0; int iy = 0; int i; if (!px || !py) return; for (i = 0; i < 8; i++) { int tmp = ptr[i]; int tmpx = (tmp & stoBits[0]) + ((tmp & stoBits[2])>>1) + ((tmp & stoBits[4])>>2) + ((tmp & stoBits[6])>>3); int tmpy = ((tmp & stoBits[1])>>1) + ((tmp & stoBits[3])>>2) + ((tmp & stoBits[5])>>3) + ((tmp & stoBits[7])>>4); ix |= tmpx << (i << 2); iy |= tmpy << (i << 2); } *px = ix; *py = iy; } PG_FUNCTION_INFO_V1(zcurve_val_from_xy); Datum zcurve_val_from_xy(PG_FUNCTION_ARGS) { uint64 v1 = PG_GETARG_INT64(0); uint64 v2 = PG_GETARG_INT64(1); PG_RETURN_INT64(zcurve_fromXY(v1, v2)); } static const int s_maxx = 1000000; static const int s_maxy = 1000000; #ifndef MIN #define MIN(a,b) ((a)<(b)?(a):(b)) #endif static int compare_uint64( const void *arg1, const void *arg2 ) { const uint64 *a = (const uint64 *)arg1; const uint64 *b = (const uint64 *)arg2; if (*a == *b) return 0; return *a > *b ? 1: -1; } SPIPlanPtr prep_interval_request(); int fin_interval_request(SPIPlanPtr pplan); int run_interval_request(SPIPlanPtr pplan, uint64 v0, uint64 v1); SPIPlanPtr prep_interval_request() { SPIPlanPtr pplan; char sql[8192]; int nkeys = 2; Oid argtypes[2] = {INT8OID, INT8OID}; /* key types to prepare execution plan */ int ret =0; if ((ret = SPI_connect()) < 0) /* internal error */ elog(ERROR, "check_primary_key: SPI_connect returned %d", ret); snprintf(sql, sizeof(sql), "select * from test_points where zcurve_val_from_xy(x, y) between $1 and $2"); /* Prepare plan for query */ pplan = SPI_prepare(sql, nkeys, argtypes); if (pplan == NULL) /* internal error */ elog(ERROR, "check_primary_key: SPI_prepare returned %d", SPI_result); return pplan; } int fin_interval_request(SPIPlanPtr pplan) { SPI_finish(); return 0; } int run_interval_request(SPIPlanPtr pplan, uint64 v0, uint64 v1) { Datum values[2]; /* key types to prepare execution plan */ Portal portal; int cnt = 0, i; values[0] = Int64GetDatum(v0); values[1] = Int64GetDatum(v1); portal = SPI_cursor_open(NULL, pplan, values, NULL, true); if (NULL == portal) /* internal error */ elog(ERROR, "check_primary_key: SPI_cursor_open"); for (;;) { SPI_cursor_fetch(portal, true, 8); if (0 == SPI_processed || NULL == SPI_tuptable) break; { TupleDesc tupdesc = SPI_tuptable->tupdesc; for (i = 0; i < SPI_processed; i++) { HeapTuple tuple = SPI_tuptable->vals[i]; //elog(INFO, "%s, %s", SPI_getvalue(tuple, tupdesc, 1), SPI_getvalue(tuple, tupdesc, 2)); cnt++; } } } SPI_cursor_close(portal); return cnt; } PG_FUNCTION_INFO_V1(zcurve_oids_by_extent); Datum zcurve_oids_by_extent(PG_FUNCTION_ARGS) { SPIPlanPtr pplan; uint64 x0 = PG_GETARG_INT64(0); uint64 y0 = PG_GETARG_INT64(1); uint64 x1 = PG_GETARG_INT64(2); uint64 y1 = PG_GETARG_INT64(3); uint64 *ids = NULL; int cnt = 0; int sz = 0, ix, iy; x0 = MIN(x0, s_maxx); y0 = MIN(y0, s_maxy); x1 = MIN(x1, s_maxx); y1 = MIN(y1, s_maxy); if (x0 > x1) elog(ERROR, "xmin > xmax"); if (y0 > y1) elog(ERROR, "ymin > ymax"); sz = (x1 - x0 + 1) * (y1 - y0 + 1); ids = (uint64*)palloc(sz * sizeof(uint64)); if (NULL == ids) /* internal error */ elog(ERROR, "cant alloc %d bytes in zcurve_oids_by_extent", sz); for (ix = x0; ix <= x1; ix++) for (iy = y0; iy <= y1; iy++) { ids[cnt++] = zcurve_fromXY(ix, iy); } qsort (ids, sz, sizeof(*ids), compare_uint64); cnt = 0; pplan = prep_interval_request(); { // FILE *fl = fopen("/tmp/ttt.sql", "w"); int cur_start = 0; int ix; for (ix = cur_start + 1; ix < sz; ix++) { if (ids[ix] != ids[ix - 1] + 1) { cnt += run_interval_request(pplan, ids[cur_start], ids[ix - 1]); // fprintf(fl, "EXPLAIN (ANALYZE,BUFFERS) select * from test_points where zcurve_val_from_xy(x, y) between %ld and %ld;\n", ids[cur_start], ids[ix - 1]); // elog(INFO, "%d -> %d (%ld -> %ld)", cur_start, ix - 1, ids[cur_start], ids[ix - 1]); // cnt++; cur_start = ix; } } if (cur_start != ix) { cnt += run_interval_request(pplan, ids[cur_start], ids[ix - 1]); // fprintf(fl, "EXPLAIN (ANALYZE,BUFFERS) select * from test_points where zcurve_val_from_xy(x, y) between %ld and %ld;\n", ids[cur_start], ids[ix - 1]); // elog(INFO, "%d -> %d (%ld -> %ld)", cur_start, ix - 1, ids[cur_start], ids[ix - 1]); } // fclose(fl); } fin_interval_request(pplan); pfree(ids); PG_RETURN_INT64(cnt); } //------------------------------------------------------------------------------------------------ struct interval_ctx_s { SPIPlanPtr cr_; SPIPlanPtr probe_cr_; uint64 cur_val_; uint64 top_val_; FILE * fl_; }; typedef struct interval_ctx_s interval_ctx_t; int prep_interval_request_ii(interval_ctx_t *ctx); int run_interval_request_ii(interval_ctx_t *ctx, uint64 v0, uint64 v1); int probe_interval_request_ii(interval_ctx_t *ctx, uint64 v0); int fin_interval_request_ii(interval_ctx_t *ctx); int prep_interval_request_ii(interval_ctx_t *ctx) { char sql[8192]; int nkeys = 2; Oid argtypes[2] = {INT8OID, INT8OID}; /* key types to prepare execution plan */ int ret =0; if ((ret = SPI_connect()) < 0) /* internal error */ elog(ERROR, "check_primary_key: SPI_connect returned %d", ret); snprintf(sql, sizeof(sql), "select * from test_points where zcurve_val_from_xy(x, y) between $1 and $2"); ctx->cr_ = SPI_prepare(sql, nkeys, argtypes); if (ctx->cr_ == NULL) /* internal error */ elog(ERROR, "check_primary_key: SPI_prepare returned %d", SPI_result); snprintf(sql, sizeof(sql), "select * from test_points where zcurve_val_from_xy(x, y) between $1 and %ld order by zcurve_val_from_xy(x::int4, y::int4) limit 1", ctx->top_val_); ctx->probe_cr_ = SPI_prepare(sql, 1, argtypes); if (ctx->probe_cr_ == NULL) /* internal error */ elog(ERROR, "check_primary_key: SPI_prepare returned %d", SPI_result); return 1; } int probe_interval_request_ii(interval_ctx_t *ctx, uint64 v0) { Datum values[1]; /* key types to prepare execution plan */ Portal portal; values[0] = Int64GetDatum(v0); { // uint32 lx, ly; // zcurve_toXY (v0, &lx, &ly); // // elog(INFO, "probe(%ld:%d,%d)", v0, lx, ly); } if (ctx->fl_) fprintf(ctx->fl_, "EXPLAIN (ANALYZE,BUFFERS) select * from test_points where zcurve_val_from_xy(x, y) between %ld and %ld order by zcurve_val_from_xy(x::int4, y::int4) limit 1;\n", v0, ctx->top_val_); portal = SPI_cursor_open(NULL, ctx->probe_cr_, values, NULL, true); if (NULL == portal) /* internal error */ elog(ERROR, "check_primary_key: SPI_cursor_open"); { SPI_cursor_fetch(portal, true, 1); if (0 != SPI_processed && NULL != SPI_tuptable) { TupleDesc tupdesc = SPI_tuptable->tupdesc; bool isnull; HeapTuple tuple = SPI_tuptable->vals[0]; Datum dx, dy; uint64 zv = 0; dx = SPI_getbinval(tuple, tupdesc, 1, &isnull); dy = SPI_getbinval(tuple, tupdesc, 2, &isnull); zv = zcurve_fromXY(DatumGetInt64(dx), DatumGetInt64(dy)); // elog(INFO, "%ld %ld -> %ld", DatumGetInt64(dx), DatumGetInt64(dy), zv); ctx->cur_val_ = zv; SPI_cursor_close(portal); return 1; } SPI_cursor_close(portal); } return 0; } int run_interval_request_ii(interval_ctx_t *ctx, uint64 v0, uint64 v1) { Datum values[2]; /* key types to prepare execution plan */ Portal portal; int cnt = 0, i; values[0] = Int64GetDatum(v0); values[1] = Int64GetDatum(v1); // elog(INFO, "[%ld %ld]", v0, v1); if (ctx->fl_) fprintf(ctx->fl_, "EXPLAIN (ANALYZE,BUFFERS) select * from test_points where zcurve_val_from_xy(x, y) between %ld and %ld;\n", v0, v1); portal = SPI_cursor_open(NULL, ctx->cr_, values, NULL, true); if (NULL == portal) /* internal error */ elog(ERROR, "check_primary_key: SPI_cursor_open"); for (;;) { SPI_cursor_fetch(portal, true, 8); if (0 == SPI_processed || NULL == SPI_tuptable) break; { TupleDesc tupdesc = SPI_tuptable->tupdesc; for (i = 0; i < SPI_processed; i++) { HeapTuple tuple = SPI_tuptable->vals[i]; // elog(INFO, "%s, %s", SPI_getvalue(tuple, tupdesc, 1), SPI_getvalue(tuple, tupdesc, 2)); cnt++; } } } SPI_cursor_close(portal); return cnt; } PG_FUNCTION_INFO_V1(zcurve_oids_by_extent_ii); Datum zcurve_oids_by_extent_ii(PG_FUNCTION_ARGS) { uint64 x0 = PG_GETARG_INT64(0); uint64 y0 = PG_GETARG_INT64(1); uint64 x1 = PG_GETARG_INT64(2); uint64 y1 = PG_GETARG_INT64(3); uint64 *ids = NULL; int cnt = 0; int sz = 0, ix, iy; interval_ctx_t ctx; x0 = MIN(x0, s_maxx); y0 = MIN(y0, s_maxy); x1 = MIN(x1, s_maxx); y1 = MIN(y1, s_maxy); if (x0 > x1) elog(ERROR, "xmin > xmax"); if (y0 > y1) elog(ERROR, "ymin > ymax"); sz = (x1 - x0 + 1) * (y1 - y0 + 1); ids = (uint64*)palloc(sz * sizeof(uint64)); if (NULL == ids) /* internal error */ elog(ERROR, "can't alloc %d bytes in zcurve_oids_by_extent_ii", sz); for (ix = x0; ix <= x1; ix++) for (iy = y0; iy <= y1; iy++) { ids[cnt++] = zcurve_fromXY(ix, iy); } qsort (ids, sz, sizeof(*ids), compare_uint64); ctx.top_val_ = ids[sz - 1]; ctx.cur_val_ = 0; ctx.cr_ = NULL; ctx.probe_cr_ = NULL; ctx.fl_ = NULL;//fopen("/tmp/ttt.sql", "w"); cnt = 0; prep_interval_request_ii(&ctx); { int cur_start = 0; int ix; for (ix = cur_start + 1; ix < sz; ix++) { if (0 == probe_interval_request_ii(&ctx, ids[cur_start])) break; for (; cur_start < sz && ids[cur_start] < ctx.cur_val_; cur_start++); // if (ctx.cur_val_ != ids[cur_start]) // { // cur_start++; // continue; // } ix = cur_start + 1; if (ix >= sz) break; for (; ix < sz && ids[ix] == ids[ix - 1] + 1; ix++); //elog(INFO, "%d %d %d", ix, cur_start, sz); cnt += run_interval_request_ii(&ctx, ids[cur_start], ids[ix - 1]); cur_start = ix; } } if (ctx.fl_) fclose(ctx.fl_); fin_interval_request(NULL); pfree(ids); PG_RETURN_INT64(cnt); }
私はここに投稿しましたが、githubには投稿していません コードは純粋に実験的なものであり、実用的な価値はありません。
PPS:この仕事をするよう私を励ましてくれたPostgresProの皆さんに感謝します。
PPPS: こことここで続きます