
Facetz.DCAとは何ですか?
Facetz.DCAは、DMP-データ管理プラットフォーム(ユーザーデータを処理するためのプラットフォーム)と呼ばれるプログラムインフラストラクチャのコンポーネントを指します。 DMPのタスク-ユーザーのアクティビティに関する情報を持ち、彼の「テーマポートレート」を作成する-多くの関心。 このプロセスはセグメンテーションと呼ばれます。 たとえば、人が頻繁に釣り場を訪れることを知っていれば、彼は熱心な釣り人であると結論付けることができます。 結果-ユーザーセグメントは、その後、最も関連性の高い広告を表示するために使用できます。 簡略化された形式では、DMP操作スキームは次のようになります。ユーザーアクティビティのデータがシステムに入り、ユーザーを分析し、IDで多くのセグメントを返します。

Facetz.DCAは、匿名化された6億人以上のユーザーのアクティビティデータを保存し、平均10ミリ秒以内にユーザーの興味を解放します。 このような高速化の必要性は、リアルタイムビッダーテクノロジーを使用して広告を表示するプロセスによって決まります。表示のリクエストに対する応答は、50ミリ秒以内に送信する必要があります。
DMPでデータストレージアーキテクチャを構築する場合、2つのタスクが解決されます。後続の分析のためのユーザー情報の保存と分析結果の保存です。 最初のソリューションは、データにアクセスするときに高い帯域幅、つまりユーザーアクティビティの履歴を提供する必要があります。 2番目のタスクでは、10ミリ秒の最小遅延を提供する必要があります。 両方のソリューションは、水平方向に十分に拡張可能でなければなりません。
生データの保存
Facetz.DCAは1日に数テラバイトのログを受信しますが、そのストレージには分散ファイルシステムHDFSを使用しています。 データ処理は、MapReduceパラダイムを使用して行われます。 生データへのアクセスは、SQLクエリをMapReduceタスクに変換するライブラリであるApache Hiveを介して整理されます。 これらの技術の詳細については、 こちらとこちらの記事をご覧ください。
ユーザープロファイルストレージ
FacetzはApache HBaseを使用してユーザーアクティビティデータを保存します。 訪問したサイトに関する情報は、HDFSから生ログを読み取り、Kafkaを介してストリーミングするMap-Reduceサービスローダーを介してそこに到達します。 HBaseでは、データはテーブルに保存され、キーはユーザーID、列は訪問したページのURL、その名前、ユーザーエージェント、IPアドレスなどのさまざまな種類の事実です。 列は列ファミリファミリに統合され、1つの列ファミリのデータが近くに保存されるため、同じファミリ内の複数の列のデータを含むGETリクエストの速度が向上します。 各セルには多くのバージョンが保存されており、システムではイベントの時間までにそのバージョンの役割が果たされます。 この記事で Apache HBaseの詳細を読むことができます。
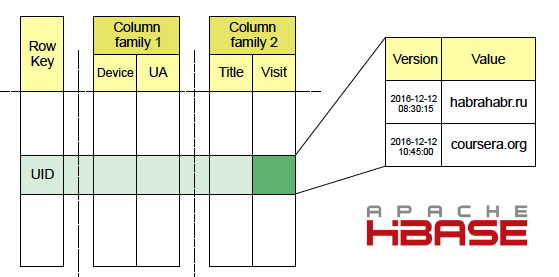
このプロジェクトでは、オフラインとリアルタイムの両方のユーザーセグメンテーションを使用します。これにより、HBaseのデータへの2つの異なるアクセスパターンにつながります。 オフラインセグメンテーションは、完全なSCAN HBaseテーブルを実行するプロセスで1日に1回発生します。 リアルタイムは、ユーザーに関する新しい事実がデータベースに入力された直後に開始されます。 したがって、最小限の遅延で、アクティブユーザーの関心の変化を確認できます。 リアルタイムセグメンテーションでは、HBaseでGETリクエストを使用します。 まず、データベースレベルでトリガーメカニズムを使用します(HBase用語ではコプロセッサー) 。 PUTおよびBulkLoad操作を介して新しいデータがHBaseに書き込まれると起動します。 HBaseで最大速度を確保するために、SSDディスクを備えたサーバーを使用します。
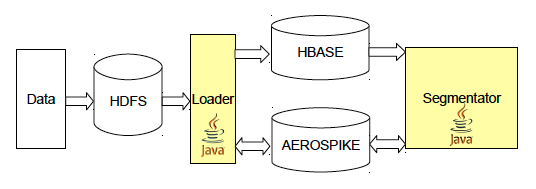
ユーザーセグメンテーション結果の保存
ユーザーが分析された後、結果は後で使用するために別のデータベースに保存されます。 ストレージは、データの記録と出力の両方の高速を提供する必要があり、そのボリュームは数テラバイトです-これは、すべてのユーザーのセグメントの合計ボリュームが占める量です。 これらの目的のために、SSD専用に設計された分散型キーバリューストレージであるAerospikeを使用します。 このDBMSは多くの点でユニークな製品であり、最も頻繁に使用するユーザーの1人はプログラム製品です。 Aerospikeのその他の機能の中でも、LUAのUDF機能のサポートと、Hadoopデータベース上でタスクを実行する機能(追加のライブラリを使用)に注目する価値があります。
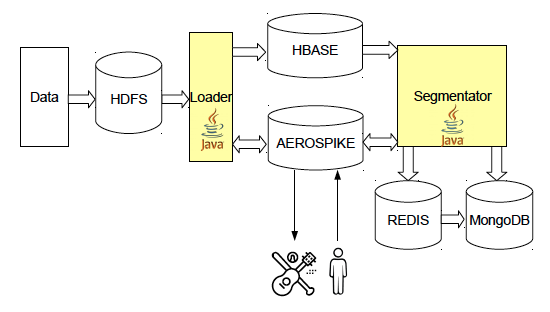
セグメント内のユニークユーザーの数を数える
分析中、DMPは各セグメントのユーザー数をカウントします。 より困難なタスクは、関連付けまたは交差のサイズを決定することです。たとえば、Tverの妊婦の数は、セグメント「妊娠女性」と「Tverでの生活」の交差のボリュームとして計算できます。 また、Niva車を所有し、VologdaまたはRyazanに住んでいるユーザーの数は、セグメント「Nivaの所有者」と「live in Vologda」および「live in Ryazan」との共通部分のボリュームです。 この情報の主な用途の1つは、広告キャンペーンの対象範囲を予測することです。
セグメントボリュームを計算するには、Redisキーバリューストレージに実装されているHyperLogLogデータ構造を使用します。 HLLは確率的なデータ構造であり、小さな(〜0.81%)エラーでセット内の一意のオブジェクトの数を決定できますが、かなり少ないメモリを占有します。タスクでは、これはキーごとに最大16 KBです。 HLLの特徴は、追加のエラーを発生させることなく、いくつかのセットの和集合内の一意のオブジェクトの数をカウントできることです。 残念ながら、HLLでの集合の共通部分の操作はより複雑です:包含例外式は、集合のボリュームに大きな差がある場合に非常に高い誤差を与えます.MinHashはしばしば精度を上げるために使用されますが、これには特別な改善が必要であり、それでもかなり大きな誤差を与えます。 HLLの別の問題は、redis-clusterでの使用が必ずしも便利ではないことです。 追加のデータコピーなしで、同じノードにあるキーのみを結合できます。 HLLに加えて、Redisを使用して、たとえば1日あたりのサイトへのアクセス数などのカウンターを保存します。 このデータにより、広告サイトの親和性を計算できます 。
設定と統計ストア
MongoDBを使用して、サービスの構成、統計、さまざまなメタ情報を保存します。 Json形式では、複雑なオブジェクトを保存すると便利です。また、データスキームがないため、構造を簡単に変更できます。 実際、私たちは
多くのプロジェクトでメインリポジトリとして使用されるこのベースの機能のごく一部のみ。
今後の計画
ストレージアーキテクチャに関しては、現時点での主な計画は、ユーザーセグメントのボリューム計算の品質を向上させることです。ここでは、ClickHouseとCloudera Impalaに注目します。 これらのデータベースの両方を使用すると、セット内の一意のオブジェクトのおおよその数をすばやく計算できます。
まとめ
NoSQL-データベースは、オンライン広告でスフィアプロジェクトを構築するときに、リポジトリとして完全に表示されます。 拡張性に優れ、同時にデータへの高速アクセスを提供します。 残念ながら、Facetz.DCAでは、1つのテクノロジのみを使用してすべてのタスクを解決できるとは限りません。一度に複数のNoSQLデータベースを使用できます。