珍しいですね。 誰が実際にこれを行う必要がありますか? 通常、このような計算は、小学校またはコンパイラのベンチマークの問題でのみ見つかります。 しかし、今では本当に起こりました。
実際には、タスクはIPv4ヘッダーのチェックサムをチェックすることでした。これは、2バイトのマシンワードのリバースコード(1に追加)の合計です。 簡単に言えば、これは、プロセスで生成されるすべてのワードとすべてのキャリービットの追加を意味します。 この手順には、いくつかの便利な機能があります。
-
ADC
プロセッサ命令を使用して効率的に実行できます(残念ながら、この関数はCでは使用できません)。 - 任意のサイズのワードで実行できます(必要に応じて8バイトの値を追加できます。結果のみを2バイトに減らし、すべてのオーバーフロービットを追加する必要があります)。
- バイトオーダーの影響を受けません(驚いたことにそうです)。
重要な要件が1つありました。ソースデータが整列していませんでした(IPフレームは、機器から受信したものやファイルから読み取ったものと同じです)。
コードはIntel x64(LinuxおよびGCC 4.8.3)の単一プラットフォームでのみ動作するため、ソフトウェアの移植性について心配する必要はありませんでした。 Intelは、整数オペランドのアラインメントに制限がありません(アラインされていないデータへのアクセスは以前は遅くなりましたが、もはやなくなりました)。また、バイト順は重要ではないため、ローからハイへのバイト順は下がります。 だから私はすぐに書いた:
_Bool check_ip_header_sum (const char * p, size_t size) { const uint32_t * q = (const uint32_t *) p; uint64_t sum = 0; sum += q[0]; sum += q[1]; sum += q[2]; sum += q[3]; sum += q[4]; for (size_t i = 5; i < size / 4; i++) { sum += q[i]; } do { sum = (sum & 0xFFFF) + (sum >> 16); } while (sum & ~0xFFFFL); return sum == 0xFFFF; }
ソースコードとアセンブリ出力はリポジトリにあります 。
最も一般的なIPヘッダーサイズは20バイト(5ダブルワード、これを単にワードと呼びます )です。このため、コードは次のようになります。 さらに、サイズを小さくすることはできません-これは、この関数を呼び出す前にチェックされます。 IPヘッダーは15ワードを超えることはできないため、ループの反復回数は0〜10です。
このコードは実際にはソフトウェアポータブルではありません。32ビット値へのポインターを使用した任意のメモリへのアクセスは、一部のプロセッサーでは機能しないことが知られています。 たとえば、ほとんどのRISCプロセッサでは、すべてではありません。 しかし、先ほど言ったように、これがx86で問題を引き起こすことを意図していませんでした。
そしてもちろん(さもなければ何も話すことはないだろう)、現実は反対であることが証明され、このコードはSIGSEGVエラーで抜け落ちました。
単純化
障害は、ループが実行されている場合にのみ発生しました。つまり、ヘッダーが20バイトを超えていました。 実生活ではこれはめったに起こりませんが、テストデータセットにそのようなヘッダーがあったので幸運でした。 このループの直前にコードを単純化しましょう。 組み込み関数を避けるために、純粋なCで記述し、2つのファイルに分割します。 こちらが
sum.c
#include <stdlib.h> #include <stdint.h> uint64_t sum (const uint32_t * p, size_t nwords) { uint64_t res = 0; size_t i; for (i = 0; i < nwords; i++) res += p [i]; return res; }
そして、これが
main.c
#include <stdint.h> #include <stdio.h> extern uint64_t sum (const uint32_t * p, size_t nwords); char x [100]; int main (void) { size_t i; for (i = 0; i < sizeof (x); i++) x [i] = (char) i; for (i = 0; i < 16; i++) { printf ("Trying %d sum\n", (int) i); printf ("Done: %d\n", (int) sum ((const uint32_t*) (x + i), 16)); } return 0; }
SIGSEGVは、
i
1のときに
sum
関数に表示されるようになりました。
調査
sum
関数のコードは驚くほど大きいため、メインループのみを示します。
.L13: movdqa (%r8), %xmm2 addq $1, %rdx addq $16, %r8 cmpq %rdx, %r9 pmovzxdq %xmm2, %xmm1 psrldq $8, %xmm2 paddq %xmm0, %xmm1 pmovzxdq %xmm2, %xmm0 paddq %xmm1, %xmm0 ja .L13
コンパイラはスマートです。 私は賢すぎます。 彼はSSE命令セットを適用しました(どこでも使用してコマンドラインで
-msse4.2
を示したため、これを行うことが許可されました。このコードは4つの値を同時に読み取り(
movdqa
)、2つのレジスタで64ビット形式に変換します( 2つの命令は
pmovzxdq
と
psrldq
)であり、現在の量(
%xmm0
)を追加しますループを反復
%xmm0
後、累積値を加算します。
多数の単語を処理する場合、これは許容できる最適化のように見えますが、そうではありません。 コンパイラーは、ループの一般的な反復回数を確立できなかったため、コードを最大に最適化し、少数のワードの場合は過度の最適化による損失も小さいと正しく推論しました。 ここでどのような損失があり、どの程度の損失があるかを後で確認します。
このコードでエラーが発生する可能性があるのは何ですか? これが
movdqa
命令であることがすぐに
movdqa
。 ほとんどのメモリアクセスSSE命令と同様に、元の引数のアドレスの16バイトのアライメントが必要です。 しかし、
uint32_t
ポインターからそのようなアライメントを期待することはできません。そして、この命令を一般的にどのように使用するのでしょうか?
コンパイラは実際にアライメントを気にします。 サイクルを開始する前に、サイクルを開始する前に処理できる単語数を計算します。
testq %rsi, %rsi ; %rsi is n je .L14 movq %rdi, %rax ; %rdi is p movq %rsi, %rdx andl $15, %eax shrq $2, %rax negq %rax andl $3, %eax
または、より馴染みのある形式で:
if (nwords == 0) return 0; unsigned start_nwords = (- (((unsigned)p & 0x0F) >> 2)) & 3;
16進数で
p
が0、1、2、または3で終わる場合は0を返し、4-7で終わる場合は3を返し、8-Bの範囲では2を返し、C-Fの場合は1を返します。 これらの最初の単語を処理した後、サイクルを開始できます(残りの単語の数が少なくとも4であり、残りを処理している場合)。
要するに、このコードはポインターを16バイトに位置合わせしますが、すでに4バイトに位置合わせされている場合に限ります。
突然、x86はRISCのように動作します
uint32_t
へのポインターが4バイトでアライメントされていないとクラッシュします。
単純なソリューションは適合しません
この関数を簡単に操作して問題を解決することはできません。 たとえば、「ポインターの任意の性質をコンパイラーに説明する」という単純な試みで、パラメーター
p
を
char*
として宣言できます。
uint64_t sum0 (const char * p, size_t nwords) { const uint32_t * q = (const uint32_t *) p; uint64_t res = 0; size_t i; for (i = 0; i < nwords; i++) res += q [i]; return res; }
または、インデックス付けをポインター演算に置き換えることができます。
uint64_t sum01 (const uint32_t * p, size_t n) { uint64_t res = 0; size_t i; for (i = 0; i < n; i++) res += *p++; return res; }
または、両方の方法を適用します。
uint64_t sum02 (const char * p, size_t n) { uint64_t res = 0; size_t i; for (i = 0; i < n; i++, p += sizeof (uint32_t)) res += *(const uint32_t *) p; return res; }
これらの変更はいずれも役立ちません。 コンパイラは、すべての構文糖を無視し、コードをコアに削減するのに十分なほど賢いです。 これらのバージョンはすべて、SIGSEGVエラーでクラッシュします。
規格が言うこと
これはかなり汚いコンパイラートリックのようです。 彼のプログラムの変革は、x86に対するプログラマの通常の期待と矛盾しています。 コンパイラはこれを行うことを許可されていますか? この質問に答えるには、標準を確認する必要があります。
さまざまなCおよびC ++標準を深く掘り下げるつもりはありません。 そのうちの1つ、つまりC99のみを見てみましょう。具体的には、C99(2007)標準の最新の公開バージョンです 。
アライメントの概念を示します。
3.2
アライメント
特定のタイプのオブジェクトが、バイトアドレスの倍数のアドレスを持つメモリ要素の境界に配置されるための要件
この概念は、ポインター変換を定義するときに使用されます。
6.3.2.3
オブジェクトまたは部分型へのポインターは、別のオブジェクトまたは部分型へのポインターに変換できます。 結果のポインターが指定されている型に対して正しく位置合わせされていない場合、動作は未定義です。 それ以外の場合、逆変換では、結果は元のポインターと等しくなります。 オブジェクトへのポインターが文字データ型へのポインターに変換されると、結果はオブジェクトの最小アドレスバイトを指します。 オブジェクトのサイズまで、結果の増分が成功すると、オブジェクトの残りのバイトへのポインターが与えられます。
また、ポインターの逆参照にも使用されます。
6.5.3.2アドレスおよび逆参照操作
無効な値がポインターに割り当てられている場合、単項*演算子の動作は未定義です。 87 )
87 )単項演算子で演算子を間接参照するための無効な値*:nullポインター。 参照されているオブジェクトのタイプの不適切にアライメントされたアドレス。 使用終了時のオブジェクトのアドレス。
これらの点を正しく理解していれば、ポインターを変換する(何かを
char *
変換する以外)ことは一般に危険です。 変換中にプログラムがここでクラッシュする可能性があります。 あるいは、変換は成功する可能性がありますが、逆参照中にプログラムがクラッシュする(または出力が不要になる)無効な値が生成されます。 この場合、このコンパイラによって実行される
uint32_t
のアライメント要件が1つ(
char*
アライメント)と異なる場合、この両方が発生する可能性があります。
uint32_t
最も自然なアライメントは4であるため、コンパイラーは完全に正しいです。
バージョン
sum0
は問題を解決しませんが、元の
sum
よりも優れています。これは、ポインターが既に
uint32_t*
型である必要があり、呼び出しコードでポインターの変換が必要であるためです。 この変換はすぐにクラッシュするか、無効なポインター値を生成する可能性があります。 sum関数の責任の下でアライメントを行い、
sum
を
sum0
置き換えましょう。
標準のこれらの節は、ポインターのタイプとそれらの計算方法を試すことによって問題を解決する試みが失敗した理由を説明します。 ポインターで何を実行しても、最終的には
uint32_t*
に変換され、ポインターが4バイトの境界に整列されていることをコンパイラーに直ちに
uint32_t*
ます。
適切なソリューションは2つしかありません。
SSEを無効にする
最初の決定はそれほど決定ではなく、むしろトリックです。 x86でのアライメントの問題は、SSEを使用している場合にのみ発生するため、オフにします。
sum
宣言されているファイル全体に対してこれを行うことができます。これが不都合な場合は、この特定の関数に対してのみです。
__attribute__ ((target("no-sse"))) uint64_t sum1 (const char * p, size_t nwords) { const uint32_t * q = (const uint32_t *) p; uint64_t res = 0; size_t i; for (i = 0; i < nwords; i++) res += q [i]; return res; }
このようなコードは、GCCに固有の属性とIntelに固有の属性を使用するため、オリジナルよりもさらに移植性が劣ります。 適切な条件付きコンパイルでクリアできます。
#if defined (__GNUC__) && (defined (__x86_64__) || defined (__i386__)) __attribute__ ((target ("no-sse"))) #endif
ただし、このメソッドはプログラムを他のコンピューターや他のアーキテクチャーでのみコンパイルできるため、実際にはほとんど役に立ちませんが、必ずしもそこでは機能しません。 RISCプロセッサがある場合、またはコンパイラが別の構文を使用してSSEを無効にしている場合、プログラムは依然として失敗する可能性があります。
GCCとIntelのフレームワーク内にとどまっているとしても、10年後にSSE以外の別のアーキテクチャがないことを誰が保証できるでしょうか? 最終的に、SSEが存在しなかった20年前に元のコードを書くことができました(最初のMMXは1997年に登場しました)。
ただし、このようなプログラムは非常にきれいなコードにコンパイルされます。
sum0: testq %rsi, %rsi je .L34 leaq (%rdi,%rsi,4), %rcx xorl %eax, %eax .L33: movl (%rdi), %edx addq $4, %rdi addq %rdx, %rax cmpq %rcx, %rdi jne .L33 ret .L34: xorl %eax, %eax ret
これはまさに、関数を書いたときに考えていたコードです。 このコードは、ベクターサイズが小さい場合、SSEベースのコードよりも高速に実行されると思います。これは、IPヘッダーの場合です。 後で測定します。
memcpy
を使用する
別のオプションは、
memcpy
関数を使用することです。 この関数は、整列に関係なく、数値を表すバイトを適切な型の変数にコピーできます。 そして、彼女は標準に完全に従っています。 これは効果がないように思えるかもしれませんが、20年前にはそうでした。 ただし、今日では、関数をプロシージャコールとして実装する必要はありません。 コンパイラはそれを独自の言語関数とみなし、メモリからレジスタへの転送(メモリからレジスタ)に置き換えることができます。 GCCは間違いなくそうです。 次のコードをコンパイルします。
uint64_t sum2 (const char * p, size_t nwords) { uint64_t res = 0; size_t i; uint32_t temp; for (i = 0; i < nwords; i++) { memcpy (&temp, p + i * sizeof (uint32_t), sizeof (temp)); res += temp; } return res; }
元のSSEに似たコードに変換しますが、
movdqu
ではなく
movdqu
のみを使用します。 この命令は、非境界整列データを許可します。 ただし、異なるパフォーマンスで動作します。 一部のプロセッサでは、データが実際に整列されていても、
movdqa
よりもはるかに低速です。 その他では、ほぼ同じ速度で動作します。
生成されたコードのもう1つの違いは、ポインターの位置合わせさえ行わないことです。 位置合わせして
movdqa
を使用できる場合でも、元のポインターで
movdqa
を使用し
movdqa
。 これは、結果として、より普遍的なコードが、一部の入力データの元のコードよりも遅くなることがあることを意味します。
このソリューションは完全にポータブルであり、RISCアーキテクチャ上でもどこでも使用できます。
複合ソリューション
最初の解決策はデータの方が速いようです(まだ測定していませんが)が、2番目の解決策はより移植性があります。 それらを一緒に組み合わせることができます:
#if defined (__GNUC__) && (defined (__x86_64__) || defined (__i386__)) __attribute__ ((target ("no-sse"))) #endif uint64_t sum3 (const char * p, size_t nwords) { uint64_t res = 0; size_t i; uint32_t temp; for (i = 0; i < nwords; i++) { memcpy (&temp, p + i * sizeof (uint32_t), sizeof (temp)); res += temp; } return res; }
このコードは、GCC / Intelで良好な非SSEサイクルにコンパイルされますが、他のアーキテクチャで動作する(そしてかなり良い)コードを生成します。 これは、プロジェクトで使用するバージョンです。
x86用に生成されたコードは、
sum1
から取得したものと同じです。
速度測定
コンパイラが
movdqa
を使用してコードを生成するすべての権利を持っていることが
movdqa
。 このソリューションは、パフォーマンスの点でどれほど優れていますか? すべてのソリューションのパフォーマンスを測定します。 最初に、完全に位置合わせされたデータでそれを行いましょう(ポインターは16の境界に位置合わせされます)。 表の値は、追加する単語ごとにナノ秒単位で指定されます。
| サイズ、言葉 | sum0(movdga) | sum1(ループ) | sum2(movdqu) | sum3(ループ、memcpy) |
|---|---|---|---|---|
| 1 | 2.91 | 1.95 | 2.90 | 1.94 |
| 5 | 0.84 | 0.79 | 0.77 | 0.79 |
| 16 | 0.46 | 0.45 | 0.41 | 0.46 |
| 1024 | 0.24 | 0.46 | 0.26 | 0.48 |
| 65536 | 0.24 | 0.45 | 0.24 | 0.45 |
この表は、単語数が非常に少ない場合(1)、通常のループはSSEベースのバージョンよりも速く動作することを確認していますが、違いはそれほど大きくありません(単語ごとに1ナノ秒、単語は1つだけです)。
SSEは多数のワード(1024以上)ではるかに高速であり、ここで全体的なゲインの結果は非常に重要です。
中規模の入力データ(16など)では、速度はほぼ同じですが、SSE(
movdqu
)のわずかな利点があります。
1〜16のすべての値でテストを実行し、平衡点がどこにあるかを確認します。 バージョン
sum1
(非SSEサイクル)と
sum3
は非常によく似た結果を示します(コードは同じであるため、予想される結果です。結果の違いは、0.02 nsの領域での測定誤差を示しています)。 そのため、最終バージョン(
sum3
)のみがチャートに表示されます。
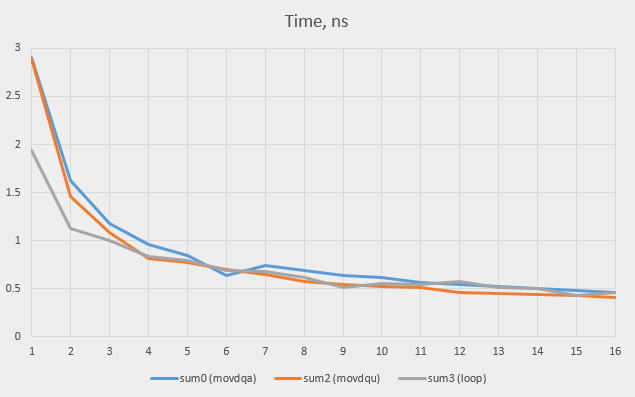
単純なループは、最大3ワードのSSEバージョンよりも優れていることがわかります。その後、SSEバージョンが引き継がれ始めます(通常、
movdqu
バージョンは元の
movdqf
よりも高速
movdqf
)。
追加情報がない場合、コンパイラは、任意のループが3回以上実行されるという前提で正しいと思うので、SSEを使用する決定は完全に正しいと思います。 しかし、なぜ彼はすぐに
movdqu
オプションにアクセスしなかったのですか?
movdqa
を使用する理由はありますか?
データが整列されると、
movdqu
バージョンは、多数の単語で
movdqa
と同じ速度で実行され、少数の単語でより高速に動作することが
movdqa
ました。 後者は、ループの前にあるより少ない命令で説明できます(アライメントをチェックする必要はありません)。 アライメントされていないデータでテストを実行するとどうなりますか? 一部のオプションの結果は次のとおりです。
| サイズ、言葉 | オフセット0 | オフセット1 | オフセット4 | |||||
|---|---|---|---|---|---|---|---|---|
| movdqa | movdqu | ループ | movdqu | ループ | movdqa | movdqu | ループ | |
| 1 | 2.91 | 2.90 | 1.94 | 2.93 | 1.94 | 2.90 | 2.90 | 1.94 |
| 5 | 0.84 | 0.77 | 0.79 | 0.77 | 0.79 | 0.84 | 0.79 | 0.78 |
| 16 | 0.46 | 0.41 | 0.46 | 0.42 | 0.46 | 0.52 | 0.40 | 0.46 |
| 1024 | 0.24 | 0.26 | 0.48 | 0.26 | 0.51 | 0.25 | 0.25 | 0.47 |
| 65536 | 0.24 | 0.24 | 0.45 | 0.25 | 0.50 | 0.24 | 0.24 | 0.46 |
ご覧のとおり、1つの例外を除いて、アライメントは速度にわずかな変化しか与えません:
movdqa
バージョンは16ワードで4のオフセットで少し(0.46 nsではなく0.52 ns)遅くなり始めます。 直接的なループは、少数の単語では依然として最適なソリューションです。
movdqu
は、多数の最適なソリューションです。 コンパイラは
movdqa
を使用して間違ってい
movdqa
。 考えられる説明は、古いIntelプロセッサモデル用に最適化されていることです。
movdqu
命令は、完全にアライメントされたデータであっても、Xeonプロセッサでは
movdqa
よりも少し遅くなり
movdqa
た。 現在、これはもはや観察されていないようであるため、コンパイラを簡素化できます(およびアライメント要件が緩和されます)。
オリジナル機能
IPヘッダーをチェックするための元の関数は、次のように書き換えられるはずです。
#if defined (__GNUC__) && (defined (__x86_64__) || defined (__i386__)) __attribute__ ((target ("no-sse"))) #endif _Bool check_ip_header_sum (const char * p, size_t size) { const uint32_t * q = (const uint32_t *) p; uint32_t temp; uint64_t sum = 0; memcpy (&temp, &q [0], 4); sum += temp; memcpy (&temp, &q [1], 4); sum += temp; memcpy (&temp, &q [2], 4); sum += temp; memcpy (&temp, &q [3], 4); sum += temp; memcpy (&temp, &q [4], 4); sum += temp; for (size_t i = 5; i < size / 4; i++) { memcpy (&temp, &q [i], 4); sum += temp; } do { sum = (sum & 0xFFFF) + (sum >> 16); } while (sum & ~0xFFFFL); return sum == 0xFFFF; }
アライメントされていないポインターを
uint32_t*
(標準では未定義の動作について述べている)に変換するのが怖い場合、コードは次のようになります。
#if defined (__GNUC__) && (defined (__x86_64__) || defined (__i386__)) __attribute__ ((target ("no-sse"))) #endif _Bool check_ip_header_sum (const char * p, size_t size) { uint32_t temp; uint64_t sum = 0; memcpy (&temp, p, 4); sum += temp; memcpy (&temp, p + 4, 4); sum += temp; memcpy (&temp, p + 8, 4); sum += temp; memcpy (&temp, p + 12, 4); sum += temp; memcpy (&temp, p + 16, 4); sum += temp; for (size_t i = 20; i < size; i+= 4) { memcpy (&temp, p + i, 4); sum += temp; } do { sum = (sum & 0xFFFF) + (sum >> 16); } while (sum & ~0xFFFFL); return sum == 0xFFFF; }
どちらのバージョンも、特に2番目のバージョンでは非常に見苦しくなります。 どちらも純粋なアセンブリ言語プログラミングを思い出させます。 ただし、これはポータブルCコードを記述する正しい方法です。
興味深いことに、テストでは、サイクルは
movdqu
と同じ速度で5ワードで動作しましたが、0から
size
までの1サイクルでこの関数を記述した後
size
より遅く動作し始めました(通常の結果は0.48 nsおよび0.83単語あたりのns)。
C ++バージョン
C ++では、いくつかのテンプレートを適用することで、同じ関数をより読みやすい方法で作成できます。 パラメーター化された型
const_unaligned_pointer
を導入します。
template<typename T> class const_unaligned_pointer { const char * p; public: const_unaligned_pointer () : p (0) {} const_unaligned_pointer (const void * p) : p ((const char*)p) {} T operator* () const { T tmp; memcpy (&tmp, p, sizeof (T)); return tmp; } const_unaligned_pointer operator+ (ptrdiff_t d) const { return const_unaligned_pointer (p + d * sizeof (T)); } T operator[] (ptrdiff_t d) const { return * (*this + d); } };
これがフレーム全体です。 この定義には、同等性テスト、2つのポインターのマイナス演算子、他の方向のプラス演算子、いくつかの変換、およびおそらく他のものを含める必要があります。
パラメータ化された型を使用すると、関数は開始した場所に非常に近くなります。
bool check_ip_header_sum (const char * p, size_t size) { const_unaligned_pointer<uint32_t> q (p); uint64_t sum = 0; sum += q[0]; sum += q[1]; sum += q[2]; sum += q[3]; sum += q[4]; for (size_t i = 5; i < size / 4; i++) { sum += q[i]; } do { sum = (sum & 0xFFFF) + (sum >> 16); } while (sum & ~0xFFFFL); return sum == 0xFFFF; }
これから、cコード
memcpy
とまったく同じアセンブラコードを取得し、明らかに同じ速度で動作します。
さらにいくつかのテンプレート
コードは非境界整列データのみを読み取るため、
const_unaligned_pointer
十分なclassがあります。私たちもそれを書きたいならどうしますか?このためのクラスを作成できますが、この場合、2つのクラスが必要です。1つはポインター用で、もう1つはl値用で、このポインターの逆参照中に取得されます。
template<typename T> class unaligned_ref { void * p; public: unaligned_ref (void * p) : p (p) {} T operator= (const T& rvalue) { memcpy (p, &rvalue, sizeof (T)); return rvalue; } operator T() const { T tmp; memcpy (&tmp, p, sizeof (T)); return tmp; } }; template<typename T> class unaligned_pointer { char * p; public: unaligned_pointer () : p (0) {} unaligned_pointer (void * p) : p ((char*)p) {} unaligned_ref<T> operator* () const { return unaligned_ref<T> (p); } unaligned_pointer operator+ (ptrdiff_t d) const { return unaligned_pointer (p + d * sizeof (T)); } unaligned_ref<T> operator[] (ptrdiff_t d) const { return *(*this + d); } };
繰り返しますが、このコードはアイデアを示しています。本番環境での使用に適したものにするために、多くの追加が必要です。簡単なテストを実行してみましょう。
char mem [5]; void dump () { std::cout << (int) mem [0] << " " << (int) mem [1] << " " << (int) mem [2] << " " << (int) mem [3] << " " << (int) mem [4] << "\n"; } int main (void) { dump (); unaligned_pointer<int> p (mem + 1); int r = *p; r++; *p = r; dump (); return 0; }
出力は次のとおりです。
0 0 0 0 0 0 1 0 0 0
私たちは書くことができます
++ *p;
しかし、これには
operator++
cの定義が必要
unaligned_ref
です。
結論
- RISC. - SSE x86 ( 32-, 64- ).
- , SSE . — , ( , - ).
- : .
- 20年にわたって書かれたコードはたくさんあり、Intelだけで機能していました。このコードは、同じ方法で突然失敗し始める可能性があります。実用的なアドバイスが1つあります。このようなコードのコンパイル中に、可能な限り拡張された命令セットをすべて無効にします。ただし、これでも解決しない場合があります。
- このストーリーは、コードカバレッジツールに役立つものがあることを示しています。ここでは、入力によりコード全体が実行されたことが幸運でした。次回は違うかもしれません。
更新する
枝に/ R / CPP /ユーザーOldWolf2は 気づいたチェックサムコードが最後の行にエラーが含まれていること:
} while (sum & ~0xFFFFL);
彼は正しい:常に同じではない
0xFFFFL
タイプ。長さは32ビットにすることができ、64ビットへの拡張の前にビットの反転(逆コード)が発生し、テストの実際の定数はになります。このようなテストが失敗した場合、たとえば2つの単語の配列の場合、入力を取得するのは簡単です:と。64ビットに変換した後、リバースコードを実行できます。
unsigned long
uint64_t
long
0x00000000FFFF0000
0xFFFFFFFF
0x00000001
} while (sum & ~(uint64_t) 0xFFFF);
または、オプションとして、比較を行います。
} while (sum > 0xFFFF);
興味深いことに、GCCは2番目のケースでより簡潔なコードを生成します。テストバージョンは次のとおりです。
.L15: movzwl %ax, %edx shrq $16, %rax addq %rdx, %rax movq %rax, %rdx xorw %dx, %dx testq %rdx, %rdx jne .L15
そして、ここに比較のバージョンがあります:
.L44: movzwl %ax, %edx shrq $16, %rax addq %rdx, %rax cmpq $65535, %rax ja .L44
以下またはredditでコメントを歓迎します。