この投稿では、このモデルの最低レベル、つまりキャラクターの表現について説明します。

はじめに:言語モデル
まず、 言語モデルの概念を定義します。 言語モデルは、一連の語彙シーケンスの確率分布です。 「Hello world」や「Buffalo buffalo Buffalo buffalo buffalo buffalo buffalo buffalo」などの文の場合、言語モデルはこの文に出会う機会を与えてくれます。
言語モデルの品質はperplexityによって評価されます。perplexityは 、モデルがテストコレクションの詳細を予測する度合いの尺度です(perplexityが小さいほど、モデルは優れています)。
lm_1b
言語モデルは、文から1つの単語を取得し、次の単語の確率分布を計算します。 したがって、彼女は「Hello、world」などの文の確率を次のように計算できます。
P("<S> Hello world . </S>") = product(P("<S>"), P("Hello" | "<S>"), P("world" | "<S> Hello"), P("." | "<S> Hello world"), P("</S>" | "<S> Hello world ."))
(「<S>」および「</ S>」は文の始まりと終わりを示します)。
LM_1Bアーキテクチャ
lm_1b
は3つの主要コンポーネントで構成されています(図を参照)。

- Char CNN(青い長方形)は、単語の文字を入力として受け取り、単語のベクトル表現を表示します(単語の埋め込み)。
- LSTM (長期短期記憶)(黄色)は、単語の表現と状態ベクトル(たとえば、この文で既に発生した単語)を受け取り、次の単語の表現を計算します。
- LSTMから受け取った情報を考慮に入れた最後のレイヤーであるsoftmax(緑)は、すべての辞書の単語に対する分布を計算します。
チャーcnn
これは、文字レベルの畳み込みニューラルネットワークの略語です。 それが何であるかわからない場合は、先ほど述べた内容を忘れてください。この投稿では、ネットワークが畳み込み、つまり文字の埋め込みを実行し始めたときに何が起こるかに焦点を当てます。
文字の埋め込み
ニューラルネットワークの入力値として文字を表す最も明白な方法は、 ワンホットエンコーディングを使用することです。 たとえば、小文字のラテン文字で構成されるアルファベットは、次のように表されます。
onehot('a') = [1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] onehot('c') = [0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
などなど。 代わりに、各シンボルを密に表すことを学びます。 word2vecのような単語のベクトル表現のシステムを既に使用している場合、この方法はおなじみのようです。
CNN Charの最初の層は、入力ワードの生の文字をベクトル表現に変換し、畳み込みフィルターによって入力に送信します。
lm_1b
アルファベットの次元は256(非ASCII文字は数バイトに拡張され、それぞれが個別にエンコードされます)、次元16のスペースにマッピングされます。たとえば、文字「a」は次のベクトルで表されます。
array([ 1.10141766, -0.67602301, 0.69620615, 1.96468627, 0.84881932, 0.88931531, -1.02173674, 0.72357982, -0.56537604, 0.09024946, -1.30529296, -0.76146501, -0.30620322, 0.54770935, -0.74167275, 1.02123129], dtype=float32)
これを理解するのは非常に困難です。 t-SNEアルゴリズムを使用して文字表現の次元を2に減らして、文字の相対位置を想像してみましょう。 t-SNEは、16次元のベクトル空間で最小の距離を持つペアが2次元の投影で互いに近くなるようにビューを配置します。
ほとんどの周波数シンボルのt-SNE表現。 ピンクのマークは、特別なメタ記号に対応しています。 <S>および</ S>は、文の始まりと終わりを示します。 <W>および</ W>は、単語の始まりと終わりを示します。 <PAD>は、50文字の語長制限を使用します。 黄色のマークは句読点、青色のマークは数字、明るい緑色と暗い緑色のマークは大文字と小文字です。
ここで、いくつかの興味深いパターンが印象的です。
- 番号は一緒にグループ化されるだけでなく、順番に「蛇」によって並べられます。
- ほとんどの場合、大文字と小文字の同じ文字が並んで配置されますが、一部(たとえば、k / K)は互いに大幅に削除されます。
- 右上隅には、文を完成できる句読点があります(
.?!
)。 - メタキャラクター(ピンク)は、いわゆるルーズクラスターを形成し、残りの特殊キャラクターはさらに外れています(外れ値として '%'および ')'があります)。
また、規則性の欠如に注目する価値があります。 小文字と大文字のペアがあまりにも規則的に対応していないことに加えて、残りの文字配置はランダムに見えます。 それらは互いにかなり離れており、投影面全体に塗られています。 たとえば、母音または子音の小島では観察されません。 大文字と小文字の普遍的な分離はありません。
おそらく、この情報はビューに反映されますが、t-SNEにはこれらの違いを2次元投影に反映するのに十分な自由度がありません。 各次元を順番に調べることで、より多くの情報が得られるでしょうか?

またはそうでないかもしれません。 ここでは、16次元すべてのグラフを見ることができます。それらのパターンは見つかりませんでした。
ベクトル計算
おそらく、単語のベクトル表現の最も有名な機能は、単語を加算および減算し、意味的に意味のある結果を取得する機能です。 例えば
vec('woman') + (vec('king') - vec('man')) ~= vec('queen')
キャラクターの表現でも同じことができるのだろうか。 ここには明らかな類似性はあまりありませんが、「タイトル」の追加と削除についてはどうでしょうか?
def analogy(a, b, c): """a is to b, as c is to ___, Return the three nearest neighbors of c + (ba) and their distances. """ # ...
「a」は「a」を指し、「b」は...を指します
>>> analogy('a', 'A', 'b') b: 4.2 V: 4.2 Y: 5.1
さて、良いスタートではありません。 もう一度試してみましょう。
>>> analogy('b', 'B', 'c') c: 4.2 C: 5.2 +: 5.9 >>> analogy('b', 'B', 'd') D: 4.2 ,: 4.9 d: 5.0 >>> analogy('b', 'B', 'e') N: 4.7 ,: 4.7 e: 5.0
部分的な成功?
多くの試みを行った後、私たちは正しい答えを取得し続けましたが、これはランダムよりも優れていますか? 小文字の半分が、対応する大文字に近接していることを忘れないでください。 したがって、文字からランダムな方向に移動すると、かなりの確率でそのペアにつまずきます。
ベクトルコンピューティング(現在は実際)
私は1つだけを試すことは残っていると思います:
>>> analogy('1', '2', '2') 2: 2.4 E: 3.6 3: 3.6 >>> analogy('3', '4', '8') 8: 1.8 7: 2.2 6: 2.3 >>> analogy('2', '5', '5') 5: 2.7 6: 4.0 7: 4.0 # It'd be really surprising if this worked... >>> nearest_neighbors(vec('2') + vec('2') + vec('2')) 2: 6.0 1: 6.9 3: 7.1
将来の注意:ヒントを計算するために文字の埋め込みを使用しないでください。
互換性があるため、互いに近いサイズのフィギュアを配置すると便利なようです。 「36歳」は「37歳」(または「26歳」)に簡単に置き換えることができ、800ドルは100よりも900ドルまたは700ドルに近くなります。t-SNEの予測を見ると、そのようなモデルは機能します。 しかし、これは、数字が並んでいることを意味しません(たとえば、モデルが数字に関連するいくつかの微妙さを学ぶ必要があるという事実から始めるために、たとえば、年が最も頻繁に「19」または「20」で始まることを考慮してください)。
なんでこんなこと?
特定のシンボルがこのように表現されている理由を推測する前に、それ以外の方法ではないことを尋ねる価値があります。 なぜ文字埋め込みを使用するのですか?
1つの理由は、モデルの複雑さの減少かもしれません。 各文字のChar CNNフィルターでは、256の代わりに各文字の16個の重みを覚えておくだけで十分です。ベクトル表現レイヤーを削除すると、特徴抽出の段階での重みの数は16倍になります。つまり、約460K(4096フィルター*最大幅7 * 16-次元表現)7.3Mまで。 たくさんのように思えますが、ネットワーク全体のパラメーターの合計数(CNN + LSTM + Softmax)は10億4,000万です! したがって、数百万の余分な数は大きな役割を果たしません。
実際、Char CNNはKim et。の記事に基づいているため、
lm_1b
はcharの埋め込みが含まれています。 al 2015、これも文字の埋め込みを使用していました。 この記事の脚注では次のことを説明しています。
以来| C | 通常は小さく、一部の著者は文字のベクトル表現に直接コーディングを使用します。 ただし、低次元の文字表現を使用すると、パフォーマンスがわずかに向上することがわかりました。
どうやら、パフォーマンスの向上は、たとえばモデルの学習速度ではなく、複雑さの低下を意味するようです。
キャラクター表現がパフォーマンスを向上させるのはなぜですか? さて、なぜ単語表現は自然言語の問題のパフォーマンスを改善するのですか? それらは一般化を改善します。 言語には多くの単語があり、それらの多くはまれです。 同じコンテキストで「ラズベリー」、「イチゴ」、「グーズベリー」という言葉に出会った場合、それらに同様のベクトルを割り当てます。 また、「ラズベリージャム」と「ストロベリージャム」というフレーズに頻繁に出くわす場合は、建物で会ったことがない場合でも、「グーズベリージャム」の組み合わせがありそうだと想定できます。
キャラクターの一般化?
そもそも、単語ベクトルとの類推は完全に適切ではありません。 Billion Wordコーパスは800,000個の個々の単語で構成されていますが、合計256文字を処理しています。 一般化について考えるべきですか? また、たとえば、「g」を別のキャラクターに一般化するにはどうすればよいですか?
答えは「仕方がない」ようです。 1つの文字の大文字と小文字のバージョンの一般化に基づいて結論を出すこともできますが、ほとんどの場合、アルファベット文字は分離されているため、一般化については心配しないでください。
しかし、一般化が重要な役割を果たすのに十分な珍しいキャラクターはいますか? 見てみましょう。

n番目に人気のあるキャラクターの出現頻度。 Billion Word Benchmarkのトレーニングセット(約77万語)に基づいて計算されます。 エンクロージャーには50文字以上の文字が完全に含まれていません(たとえば、ASCII制御文字)。
はい、Zipfの法則ではありません(二重対数ではなくy軸に沿った対数目盛のみを使用して直線に近づいています) )
おそらく、ベクトル表現は、一般化を使用してそのような文字に関する結論を引き出すのに役立ちます。 上記のt-SNEチャートでは、非常に頻繁に見つかった文字のみを描画しました(下側の境界線には最小頻度のアルファベット文字「x」を使用しました)。 ケースで見つかったキャラクターの表現を少なくとも50回描画するとどうなりますか?
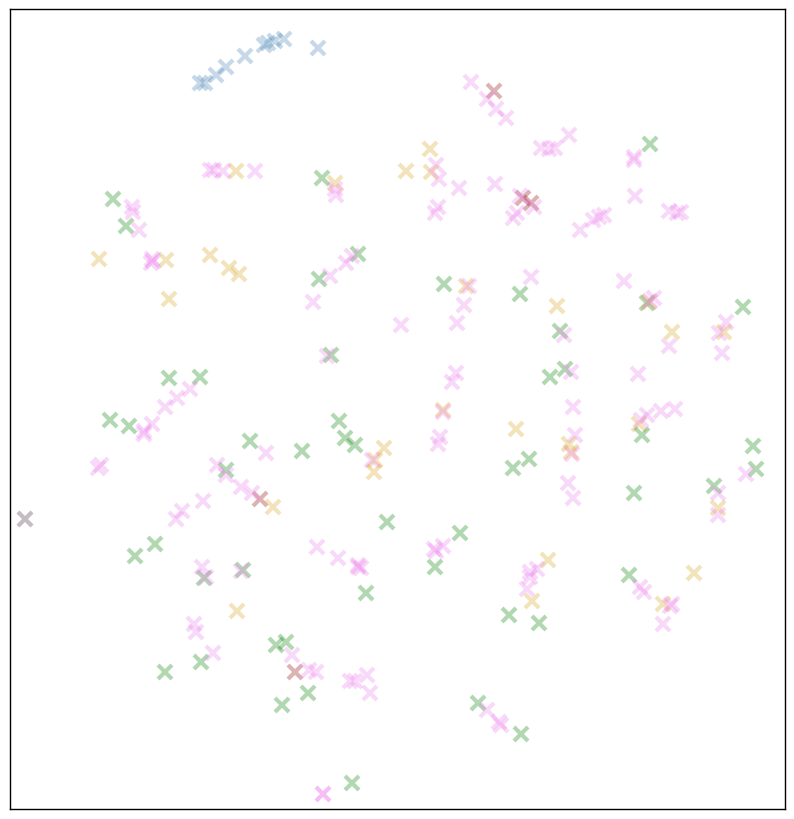
緑=文字、青=数字、黄色=句読点、赤茶色=メタキャラクター。 ピンクのマークは、127までのバイトと、以前のグループに含まれていなかった他のすべてです。
これは私たちの仮説を裏付けているようです! 以前のように、文字は反社会的であり、めったに互いに触れない。 しかし、いくつかの領域では、珍しい「ピンク」のキャラクターが密集したクラスターまたは線を形成します。
最もありそうな仮定:アルファベット文字は単独で使用されますが、まれな文字と互換性の高い文字(数字、文末の句読点)は互いに近い傾向があります。
今のところすべてです。
lm_1b
のリリースについてGoogle Brainチームに感謝します。 このモデルで実験を行いたい場合は、 こちらの指示を必ずお読みください 。 この投稿の視覚化に使用したスクリプトをここに投稿しました 。ひどく見えますが、自由に再利用または変更してください。
次回は、Char CNNの第2段階である畳み込みフィルターについて検討します。
ああ、仕事に来てくれませんか? :)wunderfund.ioは、 高頻度アルゴリズム取引を扱う若い財団です。 高頻度取引は、世界中の最高のプログラマーと数学者による継続的な競争です。 私たちに参加することで、あなたはこの魅力的な戦いの一部になります。
熱心な研究者やプログラマー向けに、興味深く複雑なデータ分析と低遅延の開発タスクを提供しています。 柔軟なスケジュールと官僚主義がないため、意思決定が迅速に行われ、実施されます。
チームに参加: wunderfund.io