
コンピューターには長い間PCI Express v3.0 x16バスがありました。 最新のビデオアダプターのテストでは、このバスの速度は約12 GB /秒です。 FPGA上で同じ速度のモジュールを作成したいと思います。 ただし、利用可能なFPGAには、PCIe v3.0 x8専用のハードウェアコントローラーがあります。 SOFT IPコアの実装は非常に高価ですが。 しかし、方法があります。
FPGA Virtex 7 VX330Tには2つのPCI Express v3.0 x8コントローラーがあります。 明らかな解決策は、コネクタの側面にx16があり、FPGAに接続されている2つのx8バスを持つスイッチを配置することです。 この構造は次のとおりです。
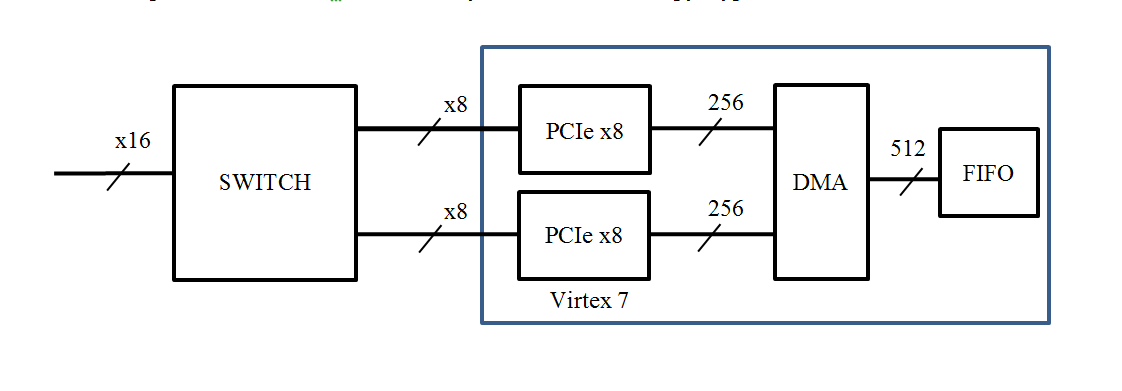
HighTechGlobalのHTG-728モジュールは、このスキームに従って構築されています。
Alpha-Dataは別のパスにあります。 ADM-PCIE-KU3-X16にはスイッチがありません。 ただし、x16コネクタでは、2つのx8バスが出力されます。 FPGAでは、2つの独立したコントローラーを実装できます。 このため、2つのリセット信号と2つの基準周波数がFPGAにセットアップされます。 ただし、このモジュールは、2つのx8もx16コネクタに出力される特別なマザーボードでのみ機能します。 私はそのようなマザーボードを見たことがありませんが、明らかにそうです。
当社は、内部スイッチを備えたFMC122Pモジュールを実装することを決定しました。 主なタスクは、最大為替レートを確認することでした。 もう1つの重要なタスクは、既存のソフトウェアおよびFPGAコンポーネントとの互換性を実現することです。
Virtex 7のPCI Expressコントローラーは、Virtex 6、Kintex 7のコントローラーと根本的に異なります。より便利になりましたが、異なります。 この図は、コントローラーの構造図を示しています。

コントローラーにはコンプリーターとリクエスターの2つの部分があり、それぞれに2つのAXI_Streamバスがあります。 Completerノードは、PCI Expressバスからリクエストを受け取ります。 これらの要求はm_axis_cqバスに送信されます。 バスs_axis_ccには、ユーザーコンポーネントからの応答があります。 通常、これは内部FPGAレジスタへのアクセスポイントです。
s_axis_rqバス上のRequesterノードを介して、DMAはPCI Expressバスにリクエストを送信します。 応答はm_axis_rcバスを介して送信されます。
タイヤシミュレーション
IPコアの構成には、その動作を理解できるサンプルプロジェクトが含まれています。 このプロジェクトはVerilogで記述されていますが、残念ながら、開発しない方法の例としても役立ちます。 例のブロック図を見てみましょう。
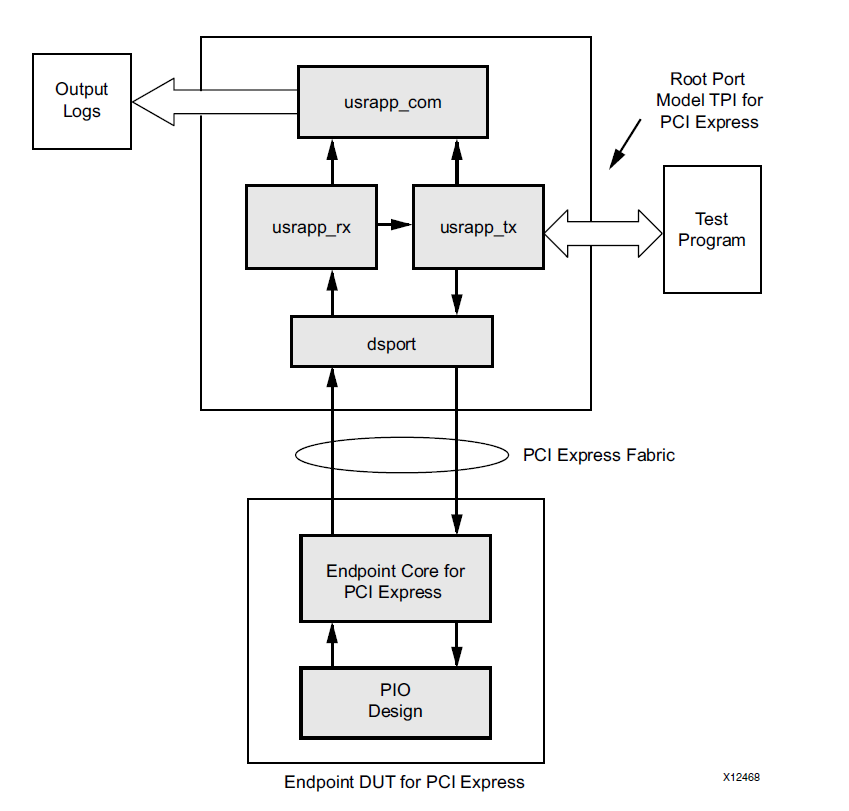
この図は、IPコアの説明からのものです。 一見、すべてが順調です-これは素晴らしい写真で、マネージャー、プロジェクトマネージャー、クライアントに見せることができます。 問題は実装に始まります。 このシステムには、Verilog機能を使用して絶対パスに沿ってオブジェクトにアクセスする多くの場所があります。 私の意見では、このシステムでは、これは1か所でのみ正当化されます-これは、PIPEレベルでのモデリングのためのGTPノードのバイパスです。 ただし、絶対パスを使用してuserapp_txとuserapp_rxを接続することは完全に不要です。
プロジェクトでは、次のようになります。
pci_exp_usrapp_txコンポーネントには、絶対パスを介してpci_exp_userapp_cfgから関数を呼び出す関数TSK_SYSTEM_INITIALIZATIONがあります。
board.RP.cfg_usrapp.TSK_WRITE_CFG_DW (以降、Verilogがタスクを通じて説明する機能を呼び出します)。 pci_exp_userapp_cfgコンポーネントを見ると、次のように表示されます。cfg_ds_bus_number <= board.RP.tx_usrapp.RP_BUS_DEV_FNS [15:8];
pci_exp_userapp_rcコンポーネントを見てください。同じものがあります: board.RP.com_usrapp.TSK_PARSE_FRAME( `RX_LOG);
これは、スタイル的に間違っているだけではありません。 これにより、プロジェクトにモデルを適用することが難しくなります。 まず、自分のプロジェクトで最上位ファイルがボードと呼ばれ、同じ階層がそこに残ることはまったく必要ありません。 第二に、2つのコンポーネントがあります。 両方のケースが発生しました。 Verilogで作業する必要がありましたが、まったく気に入らなかったのです。 結局のところ、小さな順列により、root_portコンポーネント全体を完全に階層的なビューに縮小することができます。 結果はコンポーネントファイルです:
- xilinx_pcie_3_0_7vx_rp_m2.v
- pci_exp_usrapp_tx_m2.v
- pci_exp_usrapp_cfg_m2.v
そして機能のあるファイル:
- task_bar.vh
- task_rd.vh
- task_s1.vh
- task_test.vh
これにより、モデルに2つのroot_portコンポーネントを含めることができました。 VHDLコンポーネントでは、2つのroot_portを含めると次のようになります。
root_port
gen_rp0: if( is_rp0=1 ) generate rp0: xilinx_pcie_3_0_7vx_rp_m2 generic map( INST_NUM => 0 ) port map( sys_clk_p => sys_clk_p, sys_clk_n => sys_clk_n, sys_rst_n => sys_rst_n, -- cmd_rw => cmd_rw, -- -: 0 - , 1 - cmd_req => cmd_req, -- 1 - cmd_ack => cmd_ack, -- 1 - cmd_adr => cmd_adr, -- - cmd_data_i => cmd_data_i, -- cmd_data_o => cmd_data_o, -- cmd_init_done => cmd_init_done_0 -- 1 - ); end generate; gen_rp1: if( is_rp1=1 ) generate rp1: xilinx_pcie_3_0_7vx_rp_m2 generic map( INST_NUM => 1 ) port map( sys_clk_p => sys_clk_p, sys_clk_n => sys_clk_n, sys_rst_n => sys_rst_n, cmd_init_done => cmd_init_done_1 -- 1 - ); end generate;
rp0コンポーネントを介して、32ビットワードの書き込みまたは読み取り呼び出しが行われます。 rp1コンポーネントは初期化のみを実行します。
残念ながら、シミュレーションがPIPEレベルで実行された場合でも、これは非常に長い時間シミュレーションされます。 典型的なモデリングセッションは約10分です(もう少し覚えているかもしれませんが)。 DMAチャネルを使用した運用作業には、これは適していません。 この状況では、PCI Expressコントローラーをモデルから削除するという完全に自然な決定が下されました。 また、すでに研究されています。
コントローラーブロック図
一般化されたコントローラー回路を図に示します。
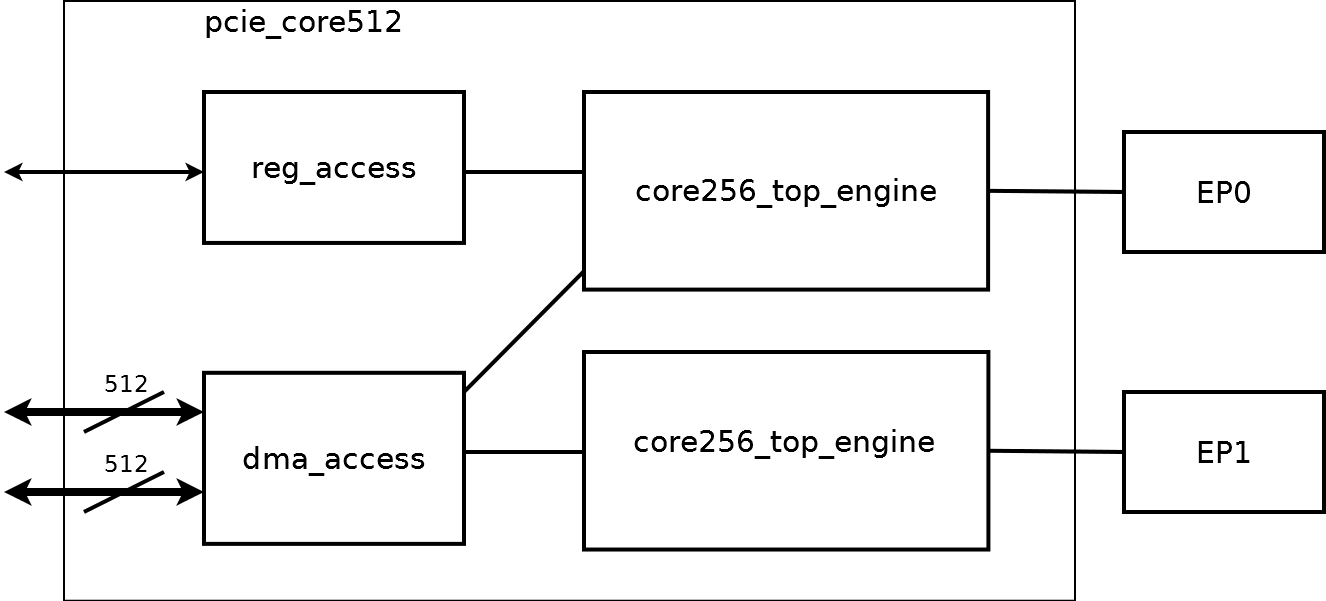
2つの同一のcore256_top_engineコンポーネントは、2つのEP0、EP1コントローラーへのアクセスを提供します。 core256_top_engineは、PCI Expressの側からレジスタへのアクセスを提供します。このため、EP0とreg_accessコンポーネントのみが使用されます。 dma_accessコンポーネントには、メインコントローラーの制御ロジックが含まれています。 下の図の構造図:
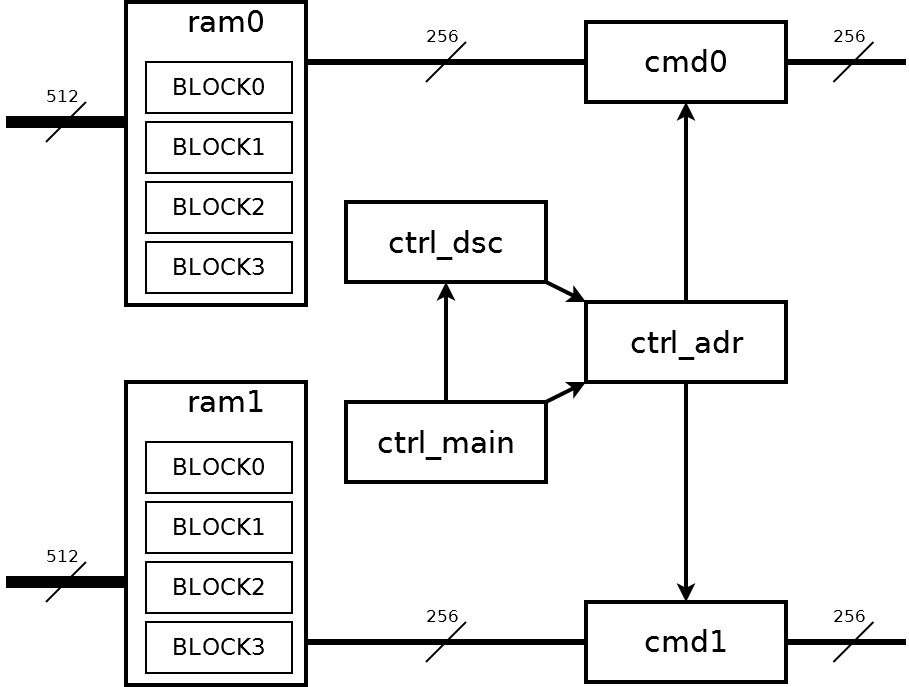
すべてはctrl_mainノードによって制御されます。 ctrl_dscノードには、記述子ブロックが含まれています。 ctrl_adrノードは、記述子を4キロバイトのブロックアドレスのシーケンスに変換します。 core256_top_engineノードと交換するために、アドレスがcmd0およびcmd1ノードに送信されます。
FPGAのユーザー側には、512ビット幅のバスが2つあります。 ただし、これらのバス上のデータは、4キロバイトのブロックで厳密に順番に送信する必要があります。 これは、メモリノードram0、ram1を順番に読み込むために必要です。 各メモリノードには、4キロバイトの4つのブロックが含まれています。 これらのメモリノードでは、512ビット幅のソースストリームが256ビットの2つのストリームに分割されます。 将来、2つの256ビットストリームはすでに完全に独立しています。 データフローはコンピューターのRAMでのみ検出され、隣接するアドレスに配置されます。
dma_accessのモデリング
dma_accessノードは、コントローラーの最も複雑な部分です。 したがって、特に慎重にモデル化する必要があります。 上記で書いたように、2つのPCI Expressコアのシミュレーションには非常に長い時間がかかります。 高速化するために、core256_top_engineの代わりに接続するモデルが開発されました。 dma_accessにも同じインターフェースが残っており、モデリング速度は1桁向上しました。 このプロジェクトおよびPROTEQプロジェクトでは、tclファイルを介した自動テスト実行が使用されます。
tclファイルのスニペットは次のとおりです。
run_test "stend_m4" "test_read_8kb " 6 "50 us" run_test "stend_m4" "test_read_16kb " 7 "100 us" run_test "stend_m4" "test_read_49blk " 8 "150 us" run_test "stend_m4" "test_read_8x4_cont " 9 "150 us" run_test "stend_m4" "test_read_128x1_cont " 12 "200 us" run_test "stend_m4" "test_read_16kbx2 " 13 "150 us" run_test "stend_m4" "test_read_step " 14 "200 us" run_test "stend_m4" "test_read_8kb_sg_eot " 15 "100 us" run_test "stend_m4" "test_read_64x1 " 16 "100 us"
これは、9つのテストの自動実行です。 たとえば、1つのテストのコードを示します。
test_read_4kb
procedure test_read_4kb ( signal cmd: out bh_cmd; --! signal ret: in bh_ret --! ) is variable adr : std_logic_vector( 31 downto 0 ); variable data : std_logic_vector( 31 downto 0 ); variable str : line; variable L : line; variable error : integer:=0; variable dma_complete : integer; variable data_expect : std_logic_vector( 31 downto 0 ); begin write( str, string'("TEST_READ_4KB" )); writeline( log, str ); ---- --- for ii in 0 to 127 loop adr:= x"00100000"; adr:=adr + ii*4; int_mem_write( cmd, ret, adr, x"00000000" ); end loop; int_mem_write( cmd, ret, x"00100000", x"00008000" ); int_mem_write( cmd, ret, x"00100004", x"00000100" ); -- int_mem_write( cmd, ret, x"00100080", x"00008000" ); -- int_mem_write( cmd, ret, x"00100084", x"00000100" ); int_mem_write( cmd, ret, x"001001F8", x"00000000" ); int_mem_write( cmd, ret, x"001001FC", x"762C4953" ); ---- DMA ---- block_write( cmd, ret, 4, 8, x"00000025" ); -- DMA_MODE block_write( cmd, ret, 4, 9, x"00000010" ); -- DMA_CTRL - RESET FIFO block_write( cmd, ret, 4, 20, x"00100000" ); -- PCI_ADRL block_write( cmd, ret, 4, 21, x"00100000" ); -- PCI_ADRH block_write( cmd, ret, 4, 23, x"0000A400" ); -- LOCAL_ADR block_write( cmd, ret, 4, 9, x"00000001" ); -- DMA_CTRL - START wait for 20 us; block_read( cmd, ret, 4, 16, data ); -- STATUS write( str, string'("STATUS: " )); hwrite( str, data( 15 downto 0 ) ); if( data( 8 )='1' ) then write( str, string'(" - " )); else write( str, string'(" - " )); error := error + 1; end if; writeline( log, str ); if( error=0 ) then ---- DMA ---- dma_complete := 0; for ii in 0 to 100 loop block_read( cmd, ret, 4, 16, data ); -- STATUS write( str, string'("STATUS: " )); hwrite( str, data( 15 downto 0 ) ); if( data(5)='1' ) then write( str, string'(" - DMA " )); dma_complete := 1; end if; writeline( log, str ); if( dma_complete=1 ) then exit; end if; wait for 1 us; end loop; writeline( log, str ); if( dma_complete=0 ) then write( str, string'(" - DMA " )); writeline( log, str ); error:=error+1; end if; end if; for ii in 0 to 3 loop block_read( cmd, ret, 4, 16, data ); -- STATUS write( str, string'("STATUS: " )); hwrite( str, data( 15 downto 0 ) ); writeline( log, str ); wait for 500 ns; end loop; block_write( cmd, ret, 4, 9, x"00000000" ); -- DMA_CTRL - STOP write( str, string'(" : " )); writeline( log, str ); data_expect := x"A0000000"; for ii in 0 to 1023 loop adr:= x"00800000"; adr:=adr + ii*4; int_mem_read( cmd, ret, adr, data ); if( data=data_expect ) then fprint( output, L, "%r : %r - Ok\n", fo(ii), fo(data)); fprint( log, L, "%r : %r - Ok\n", fo(ii), fo(data)); else fprint( output, L, "%r : %r : %r - Error \n", fo(ii), fo(data), fo(data_expect)); fprint( log, L, "%r : %r : %r - Error \n", fo(ii), fo(data), fo(data_expect)); error:=error+1; end if; data_expect := data_expect + 1; end loop; -- block_write( cmd, ret, 4, 9, x"00000010" ); -- DMA_CTRL - RESET FIFO -- block_write( cmd, ret, 4, 9, x"00000000" ); -- DMA_CTRL -- block_write( cmd, ret, 4, 9, x"00000001" ); -- DMA_CTRL - START fprint( output, L, "\nTest time: %r \n", fo(now) ); fprint( log, L, "\nTest time: %r \n", fo(now) ); -- -- writeline( log, str ); if( error=0 ) then write( str, string'("TEST finished successfully" )); cnt_ok := cnt_ok + 1; else write( str, string'("TEST finished with ERR" )); cnt_error := cnt_error + 1; end if; writeline( log, str ); writeline( log, str ); -- -- writeline( output, str ); if( error=0 ) then write( str, string'("TEST finished successfully" )); else write( str, string'("TEST finished with ERR" )); end if; writeline( output, str ); writeline( output, str ); end test_read_4kb
int_mem_writeコマンドは、コンピューターのホストRAMへの書き込みを提供します。 このテストでは、記述子ブロックがそこに書き込まれます。 block_writeおよびblock_readコマンドは、コントローラのDMAレジスタへのアクセスを提供します。 コントローラはプログラムされており、交換の開始と完了です。 その後、int_mem_readコマンドが受信データを読み取り、検証します。 このテストのコードは、opencores.orgでオープンソースプロジェクトとして公開したPCIe_DS_DMAコントローラーのテストとほぼ同じです。 オリジナルと比較して、受信データの検証が追加されました。
コントローラーの論理構成
レジスタレベルでは、コントローラーはFPGA Virtex 4、Virtex 5、Virtex 6、Kintex 7に対して以前のコントローラーを繰り返します。 組織はPCIe_DS_DMAプロジェクトにあります。
すべてのコントローラーの機能は、単一の記述子を結合して記述子ブロックにすることです。 これにより、断片化されたメモリを使用する際の速度が大幅に向上します。
ノートブックへの接続
このコントローラーをノートブックに接続することが重要です。 前回の記事「ADMインターフェイス:ノートブックとは」で書いたノートブックとは何ですか 。 512ビットバスを使用するには、アプローチを変更する必要がありました。 ノートブックを接続するには、追加のリパッカーユニットを使用する必要がありました。 ブロック図を図に示します。
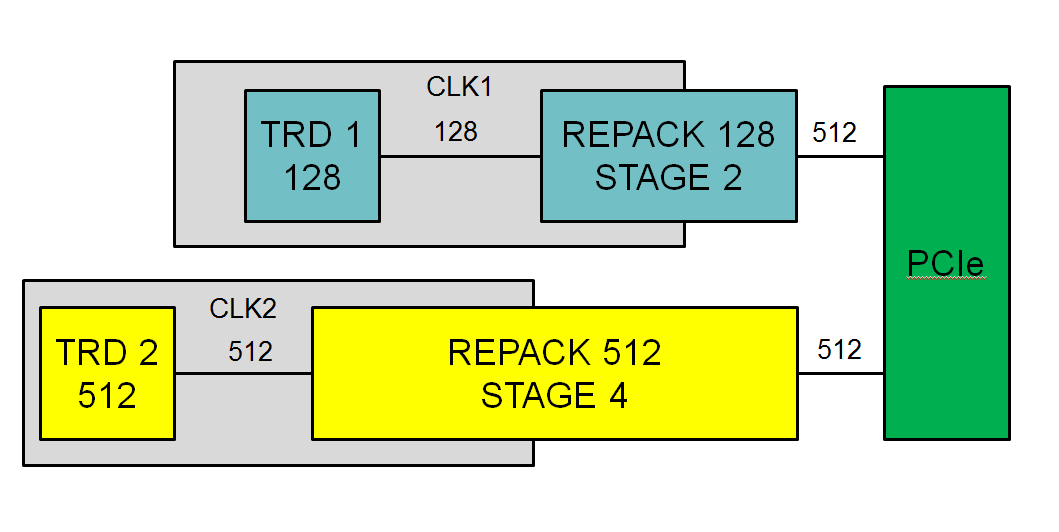
リパッカーは2つの問題を解決します。
- チップ上でタイヤをトレースします。このために、コンベアの追加ステージの数を設定できます
- 64および128ビットバスを備えたノートブックへの接続
メモリ使用量
コントローラーの開発とノートブックへの接続の最終的な目標は、ADCからコンピューターへのデータの連続ストリームを取得することです。 そして、ここでPCI Expressバスが安定した速度を提供しないという事実に直面しています。 バスに遅延がある場合があります。 これは特に高い為替レートで顕著です。 他のデバイスの動作が原因で遅延が発生します。 遅延量は異なる場合があり、5〜10μs、またはそれ以上の場合があります。 11 GB / sの速度で10μsの遅延は、110キロバイトのメモリブロックに対応します。 内部メモリについては、最新のFPGAでさえ多くのことがあります。 ただし、遅延が長くなる場合があります。 データストリームを一時停止できない場合、ADCが使用されている場合は、外部メモリにバッファリングするしか方法がありません。 さらに、メモリは22 GB / sの速度で動作できる必要があります。 モジュールには2つのSODIMM DDR3-1600がインストールされています。 メモリは800 MHzの周波数で動作します。 これは、8400 MB / sの連続データストリームに対応します。 この数値は実験により確認されています。 8400 MB / sの速度は、1800 MHzの2つのADCがインストールされている最速のサブモジュールからのデータ出力の速度を超えていることに注意してください。
トレース
スクリーンショットは、PlanAheadプログラムのトレース結果を示しています。

写真は、2つのPCI Expressコントローラー(黄色と緑色で強調表示)と2つのメモリコントローラー(PCI Expressの隣)を示しています。
結局のところ、そのようなプロジェクトはVivadoにとって非常に困難であり、非常に不十分に対処します。 Vivadoのプロジェクトは繁殖が悪く、しばしば機能しません。 ISEは、はるかに安定した結果を示します。 PCI Expressノードは、ザイリンクスの推奨事項に従ってレイアウトされましたが、チップ上で間隔が空いていることがわかりました。 そして、これはすでに、残りのマルチギガビット回線を共有するための問題を引き起こしています。
結果
モジュールの動作は、いくつかのコンピューターでテストされました。 結果は非常に興味深いものです。
| Intel Core i7 4820K | P9X79 WS | DDR3-1866 | 11140 MB / s |
|---|---|---|---|
| Intel Core i7 5820K | X99-A | DDR4-2400 | 11128 MB /秒 |
| Intel Core i7 3820K | P9X79 | DDR3-1600 | 11120 MB / s |
これは検証なしのデータ入力速度です。 データは、システムメモリ領域に割り当てられた1 GBのサイズのバッファに連続的に入力されます。つまり、物理アドレスによって連続的に入力されます。 少なくとも1分間の間隔で平均入力速度を測定します。
DDR3-1600メモリを搭載したコンピューターでは、チェックをオンにすると、速度が8500 MB / sに低下します。
DDR3-1866を搭載したコンピューターでは、1つのモジュールでスキャンがオンになっても速度は低下しません。
検証なしのDDR3-1866を搭載したコンピューターの2つのFMC122Pモジュールも、各モジュールの最大速度が約11,000 MB / sであることを示しています。 ただし、テストをオンにすると、速度が低下します。
これらの測定では、1 MBは1024バイトであり、1 KBは1024バイトであると想定されています。
この論文では、大規模なチームの作業の結果を紹介します。 このプロジェクトで素晴らしい仕事をしてくれたDmitry Avdeevに感謝します。
PS開発が進行中に、Virtex 7は何とか廃止されました。 Kintex Ultrascaleはすでに作業中により便利です。 また、Kintex Ultrascale +にはすでにPCI Express v3.0 x16 HARDが搭載されているため、この分離は不要です。
PSSしかしKintex Ultrascale +にはPCI Express v4.0 x8 HARDユニットもあります-分離はまだ有効ですか?