
プログラマーがPHPなどの高水準言語のみに精通している場合、低水準言語の特徴であり、情報とコンピューティングプロセスの機能を理解するために重要ないくつかのアイデアを習得することは容易ではありません。 ほとんどの場合、その理由は、低レベル言語と高レベル言語ではさまざまな問題を解決するためです。
しかし、プロセッサがどのように機能し、計算を実行するのかを効率的な方法でさえ知らない場合、どのように(高級)言語の自分をプロフェッショナルと考えることができますか? 今日、自動メモリ管理はほとんどの高水準言語の主な問題になりつつあり、多くのプログラマーは十分な理論的基礎なしにその解決策を求めています。 低レベルのプロセスに関する知識は、効果的な高レベルのプログラムを開発するのに大いに役立つと確信しています。
多くの学校のプログラミングコースのプログラムは、まだアセンブラーとCの基礎の開発から始まります。これは、将来のキャリアでこの知識が非常に役立つと思う将来のプログラマーにとって非常に重要です。 高レベル言語は絶えず強く変化しており、低レベル言語の変化の強度と頻度は一桁低くなっています。
将来的には、低レベルのプログラミング用のアプリケーションがたくさんあると思います。 すべてが基本から始まるため、これらの基本を作成する人々が他の人がそれらに新しいレベルを構築できるようにする必要はありません。その結果、不可欠で有用かつ効果的な製品が作成されます。
モノのインターネットは高級言語で開発されると本当に思いますか? そして、将来のビデオコーデックについてはどうですか? VRアプリ? ネットワーク? オペレーティングシステム? ゲーム? オートパイロット、衝突警告システムなどの自動車システム? これはすべて、他の多くの製品と同様に、Cなどの低レベル言語で記述されているか、すぐにアセンブラで記述されています。
たとえば、スマートフォンの98%にある非常に興味深いARMプロセッサなど、「新しい」アーキテクチャの開発を観察できます。 今日Javaを使用してAndroidアプリケーションを作成しているのは、Android自体がJavaとC ++で記述されているためです。 また、Java言語(現代の高水準言語の80%など)はC(またはC ++)で記述されています。
言語Cは、いくつかの関連言語と交差します。 しかし、それらは命令型パラダイムを使用しているため、普及していないか、それほど開発されていません。 たとえば、Cと同じ「年齢グループ」に属するFortranは、特定のタスクでより生産的です。 純粋に数学的な問題を解決する上で、多くの特殊言語はCよりも高速です。 それでも、Cは世界で最も人気があり、普遍的で効果的な低レベル言語の1つです。
さあ始めましょう
この記事では、Linuxを実行するX86_64プロセッサーを搭載したマシンを使用します。 0.5秒未満でファイルから10億バイトを合計する非常に単純なCプログラムを見てみましょう。 高級言語のいずれかでこれを試してください。Cに近いパフォーマンスは得られません。Javaでも、JITを使用して、並列コンピューティングとユーザー空間でのメモリ使用量の良いモデルを使用します。 プログラミング言語が機械命令に直接アクセスせず、何らかの中間形式(高水準言語の定義)である場合、それらは(JITを使用しても)パフォーマンスと比較されません。 一部の地域では、ギャップを縮めることができますが、一般的に、Cはライバルを大きく引き離します。
まず、Cを使用してタスクを詳細に分析してから、X86_64命令を検討し、SIMDを使用してプログラムを最適化します。SIMDは、数サイクル(数ナノ秒)で1つの命令で大量のデータを処理できる最新のプロセッサの命令の一種です。
シンプルなCプログラム
言語の機能を示すために、簡単な例を示します。ファイルを開き、そこからすべてのバイトを読み取り、それらを合計し、結果の量を1つの符号なしバイトに圧縮します(つまり、オーバーフローが数回発生します)。 それだけです。 ああ、そうです、私たちはこれらすべてを可能な限り効率的に、つまりより速くしようとします。
行こう:
#include <stdio.h> #include <stdint.h> #include <string.h> #include <fcntl.h> #include <unistd.h> #define BUF_SIZE 1024 int main(int argc, char **argv) { int f, i; ssize_t readed; unsigned char result = 0; unsigned char buf[BUF_SIZE] = {0}; if (argc != 2) { fprintf(stderr, ": %s \n", argv[0]); exit(-1); } f = open(argv[1], O_RDONLY); if (f == -1) { perror(" "); } while ((readed = read(f, buf, sizeof(buf))) > 0) { for (i=0; i < readed; i++) { result += buf[i]; } } close(f); printf(" , %u \n", result); return 0; }
1 . ,
dd
:
> dd if=/dev/urandom of=/tmp/test count=1 bs=1G iflag=fullblock
( file_sum) :
> file_sum /tmp/file Read finished, sum is 186
. :
- CPU ( ).
- (kernel).
: , .
. , , . , 2016 , (). , . ( , , , ), . — , . , , , , . . , « » — , .
? . , , . . . (hardware mapped memory). , . (Exception code). - (, SIGBUS).
— . . , CS- X86-:
gdb my_file (gdb) p /t $cs $1 = 110011
() . — .
, , ( ). . , , . .
. , , .
open()/read()
close()
. libC (
fopen()
,
fread()
,
fclose()
), , . , : , . LibC — ( ), «-» , , read(). , .
read()
, /. Linux-, perf. , — . , . ! —
read()
. , CPU /. , . , open().
, , . , , , /, . , , . .
, , :
open()
,
read()
close()
. . , SSD-, , .
?
. , . : , .
, , :
> gcc -Wall -g -O0 -o file_sum file_sum.c
time
:
> time ./file_sum /tmp/big_1Gb_file Read finished, sum is 186 real 0m3.191s user 0m2.924s sys 0m0.264s
, . SSD 3,1 . — Intel Core i5-3337U @ 1,80 , — Linux 3.16.0-4-amd64. , X86_64-. GCC 4.9.2.
time
, (90 %) . , - , — . : , . , ?
: . ,
read()
1024*1024 = 1 048 576 . , ? 1 , 1024 . , , , :
#define BUF_SIZE 1024*1024 . > gcc -Wall -g -O0 -o file_sum file_sum.c > time ./file_sum /tmp/big_1Gb_file Read finished, sum is 186 real 0m3.340s user 0m3.156s sys 0m0.180s
, 264 180 . :
read()
, . , Linux- 8 ( ).
. , , / / / .
, ( )
? , . , .
— . . - , . , . 1972 .
, — . . , , Fortran’.
, . -.
. , X86 ( 2016 — X86_64).
X86_64 . . ( Freescale 68HC11), . X86_64 . , : . PDF , .
, , Intel X86_64. . . , - PHP?
, . 80/20 — 80 % 20 % .
- , ( while()), GCC 4.9.2:
#define BUF_SIZE 1024 int main(int argc, char **argv) { int f, i; ssize_t readed; unsigned char result = 0; unsigned char buf[BUF_SIZE] = {0}; if (argc != 2) { fprintf(stderr, ": %s \n", argv[0]); exit(-1); } f = open(argv[1], O_RDONLY); if (f == -1) { perror(" "); } while ((readed = read(f, buf, sizeof(buf))) > 0) { for (i=0; i < readed; i++) { result += buf[i]; } } close(f); printf(" , %u \n", result); return 0; } 00400afc: jmp 0x400b26 < main+198> 00400afe: movl $0x0,-0x4(%rbp) 00400b05: jmp 0x400b1b < main+187> 00400b07: mov -0x4(%rbp),%eax 00400b0a: cltq 00400b0c: movzbl -0x420(%rbp,%rax,1),%eax 00400b14: add %al,-0x5(%rbp) 00400b17: addl $0x1,-0x4(%rbp) 00400b1b: mov -0x4(%rbp),%eax 00400b1e: cltq 00400b20: cmp -0x18(%rbp),%rax 00400b24: jl 0x400b07 < main+167> 00400b26: lea -0x420(%rbp),%rcx 00400b2d: mov -0xc(%rbp),%eax 00400b30: mov $0x400,%edx 00400b35: mov %rcx,%rsi 00400b38: mov %eax,%edi 00400b3a: callq 0x4005d0 < read@plt> 00400b3f: mov %rax,-0x18(%rbp) 00400b43: cmpq $0x0,-0x18(%rbp) 00400b48: jg 0x400afe < main+158> 00400b4a: mov -0xc(%rbp),%eax 00400b4d: mov %eax,%edi 00400b4f: callq 0x4005c0 < close@plt>
, ? , X86_64 .
X86_64
, , .
2 16.
- , .
- (): LEA — MOV — JMP . X86_64 .
- X86_64 — CISC-. , (clock cycles) (1 != 1 ).
- 0, 1, 2 3 . 1 2.
- : AT&T ( GAS) Intel.
- AT&T INSTR SRC DEST.
- Intel INSTR DEST SRC.
- . , . , .
- AT&T, - Intel. X86 AT&T GDB. AT&T.
- X86_64 (little-endian), . .
- X86_64 «-». - .
- $ (, $1 — '1').
- % (%eax — EAX).
- — , ( (%eax) , EAX).
— . ! RAM. 100 ( ), — 0 . — , :
- : «» .
- - (, 3).
- .
- , .
, X86_64 «-»: .
. « » — . X86_64 «» : a, b, c, d, di, si, 8, 9, 10, 11, 12, 13, 14 15 ( 32- X86 ).
64- (8 ), : 64-, 32-, 16- 8-. .
A — 64- . RAX — 64-. EAX — 32-. AX — 16-. : AL, : AH.
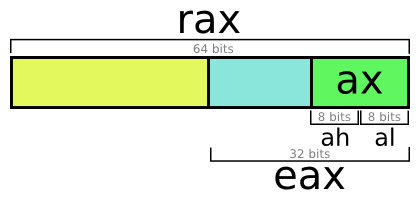
. — , . , . :
- = 8 , . BYTE.
- = 16 , WORD.
- = 32 , DWORD ( WORD).
- 8 = 64 , QWORD ( WORD).
- 16 = 128 , DQWORD ( WORD).
X86 http://sandpile.org/ Intel/AMD/Microsoft. : X86_64 , X86 (32- ). Intel.
X86_64
00400afc: jmp 0x400b26
JMP — (unconditional jump). 0x400b26:
00400b26: lea -0x420(%rbp),%rcx 00400b2d: mov -0xc(%rbp),%eax 00400b30: mov $0x400,%edx 00400b35: mov %rcx,%rsi 00400b38: mov %eax,%edi 00400b3a: callq 0x4005d0 < read@plt>
read()
. X86_64, , , . X86_64 Linux 32- , .
,
read(int fd, char *buf, size_t buf_size)
( ) RDI, ( ) — RSI, ( ) — RDX.
. RBP (Register Base Pointer, ). RBP , RSP (Register Stack Pointer, ) , , - . — , . ,
alloca()
, , , .
main()
, :
00400b26: lea -0x420(%rbp),%rcx
LEA (Load Effective Address) RBP 0x420, RCX. —
buf
. , LEA , . GDB :
> (gdb) p $rbp - 0x420 $2 = (void *) 0x7fffffffddc0
info registers
:
> (gdb) info registers rax 0x400a60 4196960 rbx 0x0 0 rcx 0x0 0 rdx 0x7fffffffe2e0 140737488347872 rsi 0x7fffffffe2c8 140737488347848 ... ...
:
00400b2d: mov -0xc(%rbp),%eax
, RBP 0xc — EAX. ,
f
. :
> (gdb) p $rbp - 0xc $1 = (void *) 0x7fffffffe854 > (gdb) p &f $3 = (int *) 0x7fffffffe854
:
00400b30: mov $0x400,%edx
EDX 0x400 (1024 ).
sizeof(buf)
: 1024,
read()
.
00400b35: mov %rcx,%rsi 00400b38: mov %eax,%edi 00400b3a: callq 0x4005d0 < read@plt>
RCX RSI,
read()
. EAX EDI,
read()
.
read()
.
A ( D).
read()
ssize_t
, 64 . , A. RAX (64- A):
00400b3f: mov %rax,-0x18(%rbp) 00400b43: cmpq $0x0,-0x18(%rbp) 00400b48: jg 0x400afe < main+158>
read()
RAX , RBP 0x18. ,
readed
-.
CMPQ (Compare Quad-Word, WORD).
readed
0.
JG (Jump if greater, «»). 0x400AFE.
while()
-.
0x400AFE,
for()
.
00400afe: movl $0x0,-0x4(%rbp) 00400b05: jmp 0x400b1b < main+187>
MOVL (Move a Long, ). LONG (32 ) 0 , RBP 4.
i
— C-, 32 , 4 .
main()
( RBP).
0x400B1B,
for()
.
00400b1b: mov -0x4(%rbp),%eax 00400b1e: cltq 00400b20: cmp -0x18(%rbp),%rax 00400b24: jl 0x400b07
EAX , RBP 4 (, ).
CLTQ (Convert Long To Quad). CLTQ A. EAX 64- , RAX.
CMP (Compare value, ). RAX , RBP 0x18.
i
for()
readed
.
JL (Jump if Lower, «»). 0x400B07.
for()
, , .
00400b07: mov -0x4(%rbp),%eax 00400b0a: cltq 00400b0c: movzbl -0x420(%rbp,%rax,1),%eax 00400b14: add %al,-0x5(%rbp) 00400b17: addl $0x1,-0x4(%rbp) 00400b1b: mov -0x4(%rbp),%eax 00400b1e: cltq 00400b20: cmp -0x18(%rbp),%rax 00400b24: jl 0x400b07 < main+167>
.
(MOV)
i
EAX ( ,
i
— –0x4(%rbp)). CLTQ: 64 .
MOVZBL (MOV Zero-extend Byte to Long). , (1*RAX+RBP) 0x420, EAX. , ;-)
buf[i]
. C:
buf[i] — buf + i*sizeof(buf[0])
. , , .
EAX,
result
:
00400b14: add %al,-0x5(%rbp)
: AL — 8- RAX (RAX AL A) —
buf[i]
,
buf
char .
result
–0x5(%rbp):
i
, 0x4 RBP. ,
result
— char, .
00400b17: addl $0x1,-0x4(%rbp)
ADDL (Add a long, — 32 ). 1
i
00400b1b:
for()
.
? , . , — : , , , . , , . «» «»?
, , 10. . , , 2, 8 16. .
, , 10. 10 2 , . 2 16 8 . , .
,
for()
. C-: . 0x40000000 , 1 073 741 824.
2 ( CISC != ) 1 073 741 824 . 3 , .
SIMD
SIMD — Single Instruction Multiple Data, , . . SIMD , , WORD, DWORD, .
SSE — Streaming SIMD Extensions, SIMD-. , SSE, SSE2, SSE4, SSE4.2, MMX 3DNow. , SSE — SIMD-. , .

, . . : 8 8 ?
SIMD- . , . :
- , ( GPU ).
- , ( LZ, GZ, MP3, Divx, H264/5, JPEG FFT ).
- .
- .
, , (Motion Estimation) Intel SSE 4. . , F, F+1. , . — H264 H265, , ( MPEG).
:
> cat /proc/cpuinfo processor : 2 vendor_id : GenuineIntel cpu family : 6 model : 58 model name : Intel(R) Core(TM) i5-3337U CPU @ 1.80GHz (...) flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm ida arat epb xsaveopt pln pts dtherm tpr_shadow vnmi flexpriority ept vpid fsgsbase smep erms
— .
sse, sse2, sse4_1, sse4_2, aes, avx.
AES AES-! CPU, .
SSE4.2 CRC32, — .
str()
libC SSE4.2, .
SIMD
- SIMD , .
MMX, 8 64- , MM0 MM7. MMX 1990-, - Pentium 2 Pentium 3 . .
SSE, SSE4.2, 2000- 2010-. .

— SSE4.2. 16 128- ( X86_64): XMM0 XMM15. 128 = 16 . , SSE- - , 16 .
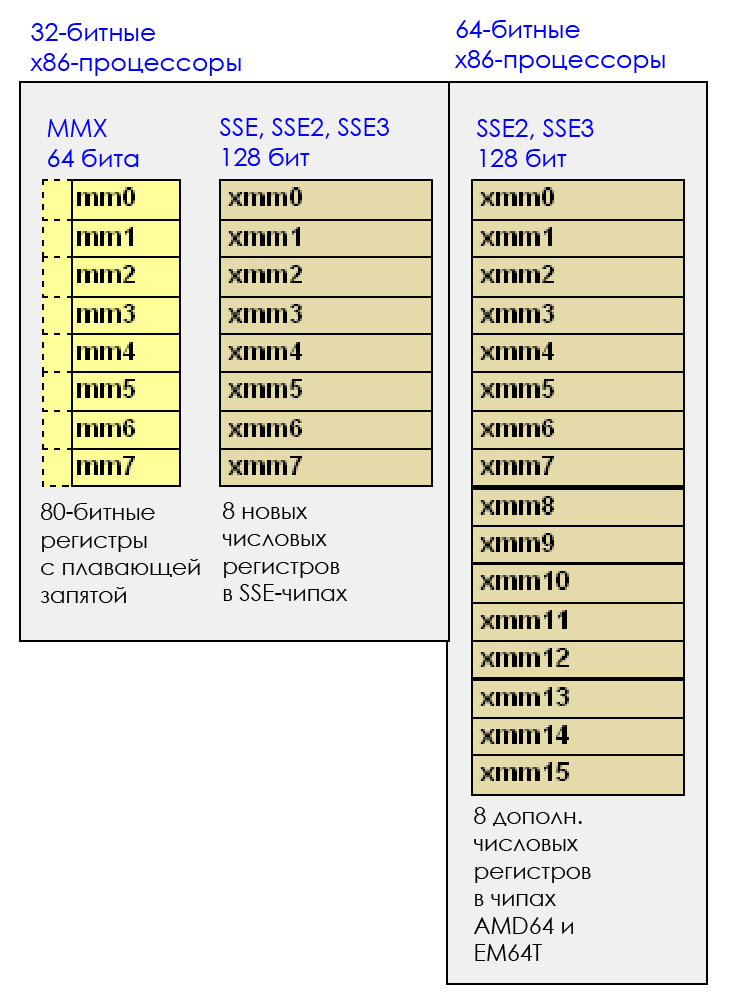
SSE-, 32 . .
16 ( LP64):
- 16 : C-.
- 8- : (double precision float).
- 4- : (single precision float).
- 2- : C.
:
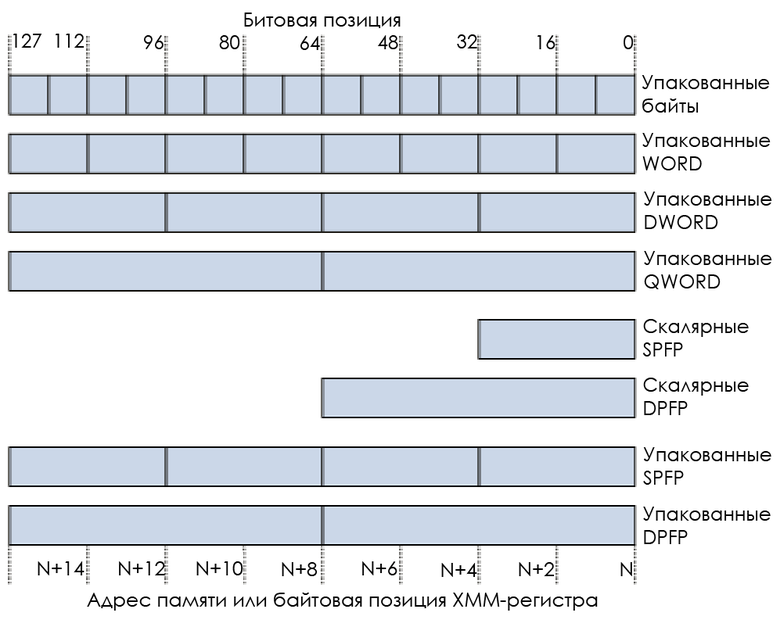
SIMD «» , «» — , . , — .
SIMD :
- , .
- Intel Intrinsics — API, C-, SSE-.
, .
:
#include <stdio.h> #include <stdint.h> #include <string.h> #include <fcntl.h> #include <unistd.h> #include <tmmintrin.h> #define BUF_SIZE 1024 int main(int argc, char **argv) { int f, i; ssize_t readed; __m128i r = _mm_set1_epi8(0); unsigned char result = 0; unsigned char buf[BUF_SIZE] __attribute__ ((aligned (16))) = {0}; if (argc != 2) { fprintf(stderr, ": %s \n", argv[0]); exit(-1); } f = open(argv[1], O_RDONLY); if (f == -1) { perror(" "); } while ((readed = read(f, buf, sizeof(buf))) > 0) { for (i=0; i < readed; i+=16) { __m128i a = _mm_load_si128((const __m128i *)(buf+i)); r = _mm_add_epi8(a, r); } memset(buf, 0, sizeof(buf)); } for (i=0; i<16; i++) { result += ((unsigned char *)&r)[i]; } close(f); printf(" , %u \n", result); return 0; }
tmmintrin.h? API. .
() SSE- . . , 4 ( ), 256 16 :D
SSE-? — . , 16 . , , «» «» . . 16 8 WORD 4 DWORD. . SIMD , .
, 16 .
.
__m128i r = _mm_set1_epi8(0);
XMM- (16 ) .
for (i=0; i < readed; i+=16) { __m128i a = _mm_load_si128((const __m128i *)(buf+i)); r = _mm_add_epi8(a, r); }
for()
1 , 16.
i+=16
.
buf+i
__m128i*
. 16 .
_mm_load_si128()
16
a
. XMM- «16* ».
_mm_add_epi8()
16-
r
. 16 .
. , . WORD, DWORD , ! ,
_mm_hadd_epi16()
.
:
for (i=0; i<16; i++) { result += ((unsigned char *)&r)[i]; }
.
:
> gcc -Wall -g -O0 -o file_sum file_sum.c > time ./file_sum /tmp/test Read finished, sum is 186 real 0m0.693s user 0m0.360s sys 0m0.328s
700 . C 3000 700 16 .
while()
, :
00400957: mov -0x34(%rbp),%eax 0040095a: cltq 0040095c: lea -0x4d0(%rbp),%rdx 00400963: add %rdx,%rax 00400966: mov %rax,-0x98(%rbp) 0040096d: mov -0x98(%rbp),%rax 00400974: movdqa (%rax),%xmm0 00400978: movaps %xmm0,-0x60(%rbp) 0040097c: movdqa -0xd0(%rbp),%xmm0 00400984: movdqa -0x60(%rbp),%xmm1 00400989: movaps %xmm1,-0xb0(%rbp) 00400990: movaps %xmm0,-0xc0(%rbp) 00400997: movdqa -0xc0(%rbp),%xmm0 0040099f: movdqa -0xb0(%rbp),%xmm1 004009a7: paddb %xmm1,%xmm0 004009ab: movaps %xmm0,-0xd0(%rbp) 004009b2: addl $0x10,-0x34(%rbp) 004009b6: mov -0x34(%rbp),%eax 004009b9: cltq 004009bb: cmp -0x48(%rbp),%rax 004009bf: jl 0x400957
?
%xmm0
%xmm1
? SSE-. ?
MOVDQA (MOV Double Quad-word Aligned) MOVAPS (MOV Aligned Packed Single-Precision). : 128 (16 ). ? CISC, .
PADDB (Packed Add Bytes): 128- !
.
AVX
AVX (Advanced Vector eXtension) — SSE. AVX - SSE++, SSE5 SSE6.
2011- Intel Sandy Bridge. SSE MMX, AVX SSE, «» , , 2000—2010.
AVX SIMD, XMM- 256 , 32 . , XMM0 YMM0. , .

AVX- XMM- SSE, 128 YMM-. SSE AVX.
AVX : . , SSE , «» ( , , ). :
VADDPD %ymm0 %ymm1 %ymm2 : ymm1 ymm2 ymm0
AVX MNEMONIC DST SRC1 SRC2 SRC3 SRC DST ( ). , AVX- ( ) , , , .
, AVX FMA-. FMA (Fused Multiply Add) : A = (B * C) + D.
AVX2
2013 Haswell AVX2. 256- . , . , AVX1 . 256- AVX ( , ) . !
, AVX2 VPADDB, YMM- ( 32 ). , AVX2.
AVX AVX2 .
AVX-512
2016 AVX-512 «» Xeon-Phi. , 2018 .
AVX-512 AVX-, 256 512 , 64 . 15 SIMD-, 32 512- . 256 ZMM-, YMM- AVX, YMM- XMM- SSE.
Intel.
15 .
SIMD ?
SIMD :
- .
- .
. 16 , 16? ( MOV).
Lego .
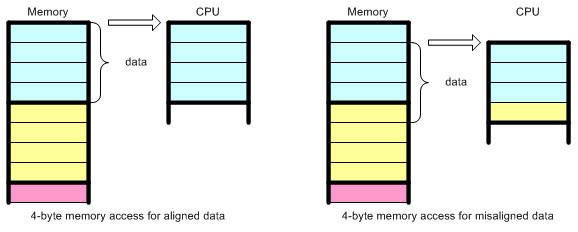
? -:
unsigned char buf[BUF_SIZE] __attribute__ ((aligned (16))) = {0};
buf
, 16.
SIMD , , SIMD. , Y, , Y, . .
:
, «» . PHP. - . «» , (), , . -.
, SIMD, — . . , SIMD. .
, SIMD , .
:
. 700 , 500!
.
, -. . , PHP , OPCache PHP- .
, . , . .
: , . ( — ) .
- 1970- . 50 . - , . .
, , , . , . .
— Intrinsics — :
> gcc -Wall -g -O3 -o file_sum file_sum.c > time ./file_sum /tmp/test Read finished, sum is 186 real 0m0.416s user 0m0.084s sys 0m0.316s
416 , 84 , 316 .
.
. .
:
00400688: mov %rcx,%rdi 0040068b: add $0x1,%rcx 0040068f: shl $0x4,%rdi 00400693: cmp %rcx,%rdx 00400696: paddb 0x0(%rbp,%rdi,1),%xmm0 0040069c: ja 0x400688 0040069e: movdqa %xmm0,%xmm1 004006a2: psrldq $0x8,%xmm1 004006a7: paddb %xmm1,%xmm0 004006ab: movdqa %xmm0,%xmm1 004006af: psrldq $0x4,%xmm1 004006b4: paddb %xmm1,%xmm0 004006b8: movdqa %xmm0,%xmm1 004006bc: psrldq $0x2,%xmm1 004006c1: paddb %xmm1,%xmm0 004006c5: movdqa %xmm0,%xmm1 004006c9: psrldq $0x1,%xmm1 004006ce: paddb %xmm1,%xmm0 004006d2: movaps %xmm0,(%rsp) 004006d6: movzbl (%rsp),%edx (...) (...) (...) (...)
. , . , (unroll) , , .
SIMD-, «» — SIMD.
, , . . , . , GCC .
— O3, « — », « — slp», .
O2, - O3 . , . , 2016 . , GCC 4.9.2, PHP -O2. FPU.
PHP. (-O0) . -O2 -O3. - .
-O2 . -O2 GCC SIMD. , Linux- -O2. , . . , Linux- , , ? , IBM Oracle.
, -O3 -O2 . -march=native , , . , .
GCC, , LLVM ICC ( Intel). gcc.godbolt.org . Intel Intel. GCC LLVM , , .
, . : .
, , , , . ? .
PHP?
PHP? PHP . , , , -.
, :
- PHP . , , . .
- alloca() , . , alloca(), .
- GCC. , __builtin_alloca(), __builtin_expect() __builtin_clz().
- , Zend Virtual. .
PHP JIT ( ). . JIT — « », . JIT , PHP (Zend), . , JIT. PHP- PHP-, JIT , . PHP , «» (). PHP JIT, , Java. , -, CLI. CLI- , Web PHP.
PHP . , « », . .
SIMD- PHP. : , .
PHP-, SIMD. , math-php SIMD. , PHP- SIMD . , - PHP.
, . , GDB , . GCC , , SIMD-. -O3 GCC SIMD.
, SIMD — . AVX . mmap(), .
, , . . - API Intel Intrinsics. «» , . GCC-.
- Intel Intrinsics, - , . -, . , .
— . 45 , , , . , . , . , , NUMA. - , , Intel AMD : , .
, , , . , . , .
, , - . , , . , , , .
:
- Intel: The significance of SIMD, SSE and AVX
- NASM
- GCC SIMD switches
- Online JS based X86 compilers
- ARM Processor Architecture
- Modern X86 Assembly Language Programming: 32-bit, 64-bit, SSE, and AVX
- X86 Opcode and Instruction Reference
- Dragon Book
- X264 Assembly with SIMD
- LAME MP3 quantizer SIMD
- Mandelbrot Set with SIMD Intrinsics
- ASM.js
- Joe's PHP SIMD