
私の最近の記事「RAM内のDBMSとは何か、どのように効率的にデータを保存するか」を覚えていますか? その中で、データの安全性を確保するために、RAM内のDBMSで使用されるメカニズムの概要を簡単に説明しました。 それは、トランザクションをログに書き込むことと状態のスナップショットを取ることの2つの主要なメカニズムについてでした。 トランザクションログを操作する原則の一般的な説明を行い、スナップショットのトピックについてのみ触れました。 したがって、この記事ではスナップショットについて詳しく説明します。RAMのDBMSの状態のスナップショットを取得する最も簡単な方法から始め、この方法に関連するいくつかの問題を強調し、このメカニズムがTarantoolでどのように実装されるかを詳しく説明します。
したがって、すべてのデータをRAMに保存するDBMSがあります。 前の記事で述べたように、状態のスナップショットを取得するには、このすべてのデータをディスクに書き込む必要があります。 これは、すべてのテーブルと各テーブルのすべての行を調べて、 writeシステムコールを介してこれらすべてを1つのファイルのディスクに書き込む必要があることを意味します。 一見簡単です。 ただし、問題はデータベース内のデータが常に変化していることです。 スナップショットを撮るときにデータ構造を凍結しても、結果として、ディスク上のデータベースの一貫性のない状態を取得する可能性があります。
一貫した状態を達成する方法は? 最も簡単な(そして最も粗い)方法は、データベース全体を事前に凍結し、状態のスナップショットを撮り、再び凍結を解除することです。 そして、それは動作します。 データベースはかなりの期間凍結することができます。 たとえば、データサイズが256 GBでハードドライブの最大容量が100 MB / sの場合、写真の撮影には256 GB /(100 MB / s)-約2560秒、または(再び)40分かかります。 DBMSは引き続き読み取り要求を処理できますが、データ変更要求を満たすことはできません。 「ほんとに?」と叫ぶ。 数えましょう:たとえば、1日のダウンタイムが40分であれば、DBMSは最高のケースで97%の時間で完全に動作します(実際、もちろん、他の多くの要因がダウンタイムの期間に影響するため、この割合は低くなります)。
どのようなオプションがありますか? 何が起こっているのかを詳しく見てみましょう。 すべてのデータを凍結したのは、遅いデバイスにコピーする必要があるためだけです。 しかし、速度を上げるためにメモリを犠牲にするとどうなりますか? 一番下の行は、すべてのデータをRAMの別の領域にコピーしてから、コピーを低速のディスクに書き込むことです。 これはより良いように見えますが、それはさまざまな重大度の少なくとも3つの問題を伴います:
- すべてのデータを凍結する必要があります。 1 GB / sの速度でデータをメモリ領域にコピーするとします(これは楽観的すぎます。実際には、多少の高度なデータ構造では速度が200-500 MB / sになる可能性があるためです)。 256 GB /(1 GB / s)は256秒、つまり約4分です。 1日あたり4分のダウンタイム、つまりシステムの可用性時間の99.7%が得られます。 もちろん、これは97%よりも優れていますが、それほどではありません。
- RAM内の別のバッファーにデータをコピーしたらすぐに、ディスクに書き込む必要があります。 コピーが記録されている間、メモリ内の元のデータは変化し続けます。 何らかの方法で追跡する必要があります。たとえば、トランザクション識別子をスナップショットとともに保存して、どのトランザクションが最後のスナップショットにあったかを明確にします。 複雑なことは何もありませんが、それでもそれを行う必要があります。
- RAM容量の要件は2倍になります。 実際、データのサイズの2倍のメモリが常に必要です。 強調するのは、状態のスナップショットを撮るだけでなく、サーバーのメモリ量を増やして写真を撮ってから再びメモリバーを引っ張ることができないためです。
この問題を解決する1つの方法は、 forkシステムコールによって提供されるコピーオンライト メカニズム (以降、簡潔にするために、 コピーオンライトの英語の略語COWを使用します)を使用することです。 この呼び出しの結果、仮想アドレス空間とすべてのデータの読み取り専用コピーを備えた別のプロセスが作成されます。 すべての変更は親プロセスで発生するため、読み取り専用コピーが使用されます。 そのため、プロセスのコピーを作成し、ゆっくりとデータをディスクに書き込みます。 問題は残っています:以前のコピーアルゴリズムとの違いは何ですか? その答えは、Linuxで使用されるCOWメカニズムにあります。 上記で少し述べたように、COWはコピーオンライトを意味する略語です。 録音中のコピー。 このメカニズムの本質は、子プロセスが最初に親プロセスとともにページメモリを使用することです。 プロセスの1つがRAMのデータを変更するとすぐに、対応するページのコピーが作成されます。
当然、ページのコピーは応答時間の増加につながります。これは、実際のコピー操作に加えて、さらにいくつかのことが起こるためです。 通常、ページサイズは4 KBです。 データベース内の小さな値を変更するとします。 まず、 ページがないために中断があります 。 fork呼び出しの後、親プロセスと子プロセスのすべてのページは読み取り専用です。 その後、システムはカーネルモードに切り替わり、新しいページを選択し、古いページから4 KBをコピーして、再びユーザーモードに戻ります。 これは非常に簡略化された説明であり、実際に何が起こっているかについての詳細は、 リンクを読むことができます。
変更が1つだけでなく複数のページに影響する場合(ツリーなどのデータ構造を使用している場合は非常に可能性が高い)、上記のイベントシーケンスが何度も繰り返され、DBMSのパフォーマンスが大幅に低下する可能性があります。 高負荷では、これにより応答時間が大幅に増加し、ダウンタイムが短くなる可能性があります。 さらに、多数のページが親プロセスで任意に更新されます。その結果、ほとんどすべてのデータベースをコピーでき、その結果、必要なRAMの量が2倍になります。 一般に、運がよければ、データベースの応答時間とダウンタイムにジャンプはありません。そうでない場合は、両方の準備をしてください。 そうそう、メモリ消費量の2倍を忘れないでください。
forkのもう1つの問題は、このシステムコールがページ記述子テーブルをコピーすることです 。 256 GBのメモリを使用している場合、このテーブルのサイズは数百メガバイトに達する可能性があるため、プロセスが1〜2秒フリーズし、応答時間が長くなる可能性があります。
もちろんforkを使用することは万能薬ではありませんが、これまでのところこれが最善です。 実際、人気のあるインメモリDBMSの中には、 Redisのようにフォークを使用して状態スナップショットを作成するものがあります。
ここで何か改善できますか? COWメカニズムを見てみましょう。 コピーは4 KBです。 1バイトのみを変更すると、ページ全体がとにかくコピーされます(ツリーの場合、リバランスが不要な場合でも、多くのページがコピーされます)。 しかし、実際に変更されたメモリのセクション、または変更された値のみをコピーする独自のCOWメカニズムを実装するとどうなりますか? 当然、このような実装はシステムメカニズムの完全な代替として機能するのではなく、状態のスナップショットを取得するためにのみ使用されます。
改善の本質は次のとおりです。すべてのデータ構造(ツリー、ハッシュテーブル、テーブルスペース)が各要素の多くのバージョンを格納できることを確認します。 この考え方は、 マルチバージョンの同時アクセス制御に近いものです。 違いは、この改善は同時アクセス制御自体には使用されず、状態のスナップショットの作成にのみ使用されることです。 スナップショットの作成を開始するとすぐに、すべてのデータ変更操作により、変更する要素の新しいバージョンが作成されますが、古いバージョンはすべてアクティブのままであり、スナップショットの作成に使用されます。 以下の画像をご覧ください。 このロジックは、ツリー、ハッシュテーブル、およびテーブルスペースに適用されます。
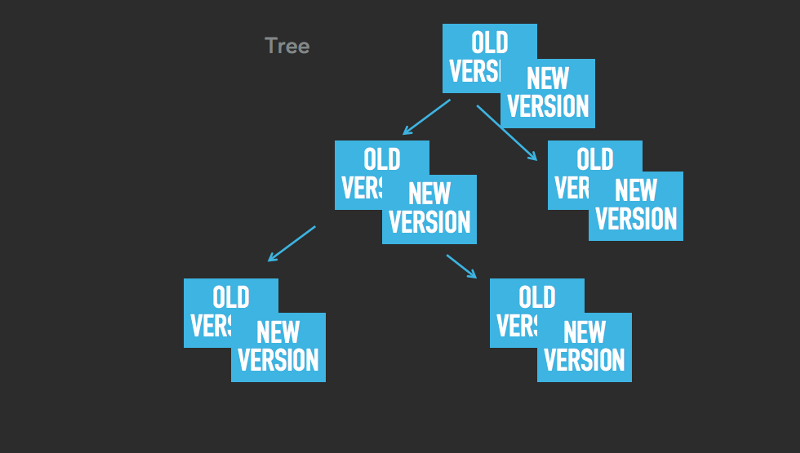
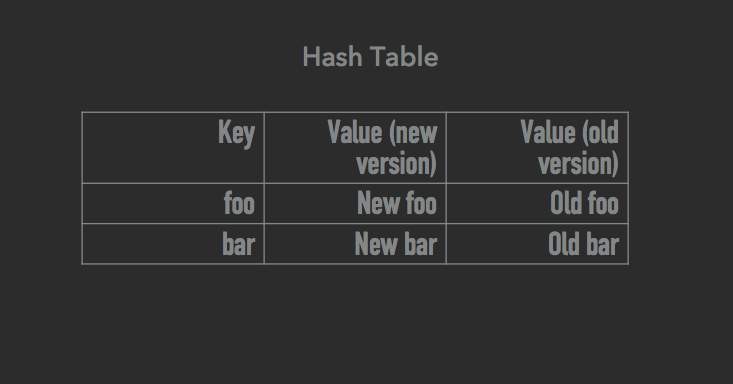

ご覧のとおり、要素には古いバージョンと新しいバージョンの両方を含めることができます。 たとえば、表スペースの最後の画像では、値3、4、5、および8には2つのバージョン(古いバージョンと対応する新しいバージョン)があり、その他(1、2、6、7、9)にはそれぞれ1つのバージョンがあります。
変更は新しいバージョンでのみ発生します。 古いバージョンは、スナップショットを取るときの読み取り操作に使用されます。 COWメカニズムの実装とシステムメカニズムの主な違いは、4 KBページ全体をコピーするのではなく、実際に変更されたデータのごく一部のみをコピーすることです。 たとえば、4バイトの整数を更新すると、このメカニズムによりこの数値のコピーが作成され、これらの4バイトのみがコピーされます(1つの要素の2つのバージョンを維持するための料金としてさらに数バイト)。 そして今、比較のために、システムCOWの動作を見てください:4096バイトがコピーされ、ページが中断され、コンテキストが切り替わります(そのようなスイッチはそれぞれ約1 KBのメモリのコピーと同等です)-そしてこれはすべて数回繰り返されます。 スナップショットを撮るときに、たった1つの4バイトの数字全体を更新するのは面倒ですか?
バージョン1.6.6( forkを使用する前)からTarantoolでスナップショットを取得するために、独自のCOWメカニズムの実装を使用します。
このトピックに関する新しい記事では、稼働中のMail.Ru Groupサーバーから興味深い詳細とグラフを作成しています。 ニュースをフォローしてください。
記事の内容に関するすべての質問は、元のdanikinの著者、メールおよびクラウドサービスMail.Ru Groupのテクニカルディレクターに宛ててください。