
ネットワーク機器の帯域幅を制限する場合、まずポリサーとシェーパーという2つのテクノロジーが頭に浮かびます。 ポリサーは、「余分な」パケットを廃棄することにより速度を制限し、指定された速度を超えることになります。 Shaperは、パケットをバッファリングすることにより、速度を目的の値に滑らかにしようとします。 Ivan Pepelnjak(Ivan Pepelnjak)のブログのメモを読んだ後、この記事を書くことにしました。 繰り返しになりますが、疑問が生じました。どちらが良いか-ポリサーかシェーパーです。 そして、そのような質問でよくあることですが、それに対する答えは次のとおりです。各テクノロジーには長所と短所があるため、すべて状況に依存します。 簡単な実験を行うことで、これをもう少し詳しく扱うことにしました。 ローリングによって得られた結果。
それでは、ポリサーとシェーパーの違いの概要から始めましょう。
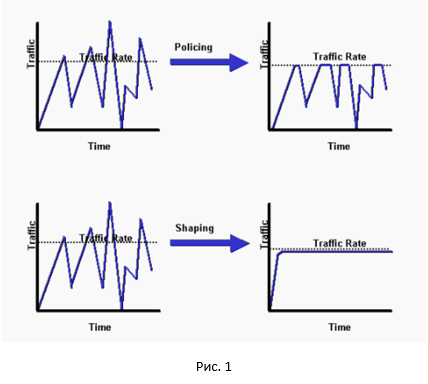
ご覧のとおり、ポリサーはすべてのピークをカットし、シェーパーはトラフィックを平滑化します。 ポリサーとシェーパーのかなり良い比較はここにあります 。
どちらのテクノロジーも基本的にトークンメカニズムを使用します。 このメカニズムには、サイズが制限された仮想トークンバケットがあり、そこに一定の規則を持ってトークンが到着します。 トラベルカードのようなトークンは、パケットの転送に使用されます。 バケットにトークンがない場合、パケットは破棄されます(他のアクションを実行できます)。 したがって、トークンが所定の速度に従ってバケットに入ると、一定のトラフィック転送速度が得られます。
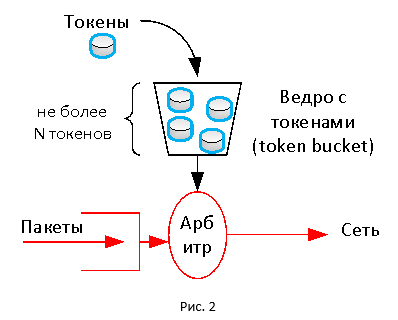
たぶんそれは簡単でしょうか?
セッション速度は、通常、割り当てられた期間、たとえば5秒または5分で測定されます。 データは常にチャネル速度で送信されるため、瞬時値を取得しても意味がありません。 さらに、異なる時間間隔で平均化を行うと、ネットワーク上のトラフィックが均一ではないため、データ転送速度の異なるグラフが得られます。 監視システムでグラフを作成するときに、だれかがこれに遭遇したと思います。
トークンメカニズムにより、速度制限を柔軟に設定できます。 バケットのサイズは、速度の平均化方法に影響します。 バケットが大きい場合(つまり、そこに大量のトークンが蓄積される可能性があります)、特定の時点で割り当てられた制限のためにトラフィックがより「飛び出す」ことを許可します(長時間にわたる平均化に相当)。 バケットサイズが小さい場合、トラフィックはより均一になり、指定されたしきい値(短期間の平均化と同等)を超えることはほとんどありません。
トークンメカニズムにより、速度制限を柔軟に設定できます。 バケットのサイズは、速度の平均化方法に影響します。 バケットが大きい場合(つまり、そこに大量のトークンが蓄積される可能性があります)、特定の時点で割り当てられた制限のためにトラフィックがより「飛び出す」ことを許可します(長時間にわたる平均化に相当)。 バケットサイズが小さい場合、トラフィックはより均一になり、指定されたしきい値(短期間の平均化と同等)を超えることはほとんどありません。
ポリサーの場合、バケットは新しいパッケージが到着するたびに満たされます。 バケットにロードされるトークンの数は、設定されたポリサー速度と、最後のパケットが到着してからの経過時間によって異なります。 バケットにトークンがない場合、ポリサーはパケットをドロップするか、たとえば、再マーキング(新しいDSCPまたはIPP値を割り当てる)できます。 シェイパーの場合、バケットの到着はパッケージの到着に関係なく定期的に発生します。 十分なトークンがない場合、パケットはトークンが現れるのを待つ特別なキューに落ちます。 このため、スムージングがあります。 ただし、パケットが多すぎると、シェーパーのキューが最終的にオーバーフローし、パケットが破棄され始めます。 ポリサーとシェーパーの両方にバリエーションがあるため、上記の説明が簡略化されていることに注意する価値があります(これらのテクノロジーの詳細な分析には、別の記事のボリュームが必要です)。
実験
そして、実際にはどのように見えますか? これを行うには、テストベンチを収集し、次の実験を実施します。 スタンドには、ポリサーとシェーパーテクノロジーをサポートするデバイス(私の場合、Cisco ISR 4000です。これらのテクノロジーをサポートするベンダーのハードウェアまたはソフトウェアデバイスが適しています)、 iPerfトラフィックジェネレーター 、 Wiresharkトラフィックアナライザーが含まれます。
最初に、ポリサーを見てみましょう。 速度制限を20 Mbpsに設定します。
デバイス構成
policy-map Policer_20 class class-default police 20000000 interface GigabitEthernet0/0/1 service-policy output Policer_20
iPerfでは、TCPプロトコルを使用して4つのストリーム内でトラフィックの生成を開始します。
C:\Users\user>iperf3.exe -c 192.168.115.2 -t 20 -i 20 -P 4 Connecting to host 192.168.115.2, port 5201 [ 4] local 192.168.20.8 port 55542 connected to 192.168.115.2 port 5201 [ 6] local 192.168.20.8 port 55543 connected to 192.168.115.2 port 5201 [ 8] local 192.168.20.8 port 55544 connected to 192.168.115.2 port 5201 [ 10] local 192.168.20.8 port 55545 connected to 192.168.115.2 port 5201 [ ID] Interval Transfer Bandwidth [ 4] 0.00-20.01 sec 10.2 MBytes 4.28 Mbits/sec [ 6] 0.00-20.01 sec 10.6 MBytes 4.44 Mbits/sec [ 8] 0.00-20.01 sec 8.98 MBytes 3.77 Mbits/sec [ 10] 0.00-20.01 sec 11.1 MBytes 4.64 Mbits/sec [SUM] 0.00-20.01 sec 40.9 MBytes 17.1 Mbits/sec
平均速度は17.1 Mbpsでした。 各セッションは異なる帯域幅を受け取りました。 これは、このケースで設定されたポリサーがストリームを区別せず、指定された速度値を超えるパケットを破棄するためです。
Wiresharkを使用して、トラフィックダンプを収集し、送信側で受信したデータ転送スケジュールを作成します。
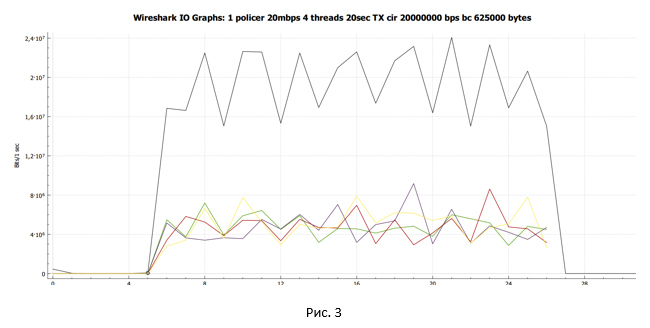
黒い線は総トラフィックを示します。 マルチカラーの線-各TCPストリームのトラフィック。 結論を出して質問を掘り下げる前に、ポリサーをシェーパーに置き換えた場合にできることを見てみましょう。
シェーパーを20 Mbpsの速度制限に設定します。
デバイス構成
セットアップ時には、BCトークンとBEトークンのバケットサイズの8000に自動的に設定された値を使用します。しかし、キューサイズを83(IOS XEバージョン15.6(1)S2のデフォルト)から200に変更します。 'a。 この質問については、サブカテゴリ「キューの深さはセッションに影響しますか?」で詳しく説明します。
policy-map Shaper_20 class class-default shape average 20000000 queue-limit 200 packets interface GigabitEthernet0/0/1 service-policy output Shaper_20
セットアップ時には、BCトークンとBEトークンのバケットサイズの8000に自動的に設定された値を使用します。しかし、キューサイズを83(IOS XEバージョン15.6(1)S2のデフォルト)から200に変更します。 'a。 この質問については、サブカテゴリ「キューの深さはセッションに影響しますか?」で詳しく説明します。
cbs-rtr-4000#sh policy-map interface gigabitEthernet 0/0/1 Service-policy output: Shaper_20 Class-map: class-default (match-all) 34525 packets, 50387212 bytes 5 minute offered rate 1103000 bps, drop rate 0000 bps Match: any Queueing queue limit 200 packets (queue depth/total drops/no-buffer drops) 0/0/0 (pkts output/bytes output) 34525/50387212 shape (average) cir 20000000, bc 80000, be 80000 target shape rate 20000000
iPerfでは、TCPプロトコルを使用して4つのストリーム内でトラフィックの生成を開始します。
C:\Users\user>iperf3.exe -c 192.168.115.2 -t 20 -i 20 -P 4 Connecting to host 192.168.115.2, port 5201 [ 4] local 192.168.20.8 port 62104 connected to 192.168.115.2 port 5201 [ 6] local 192.168.20.8 port 62105 connected to 192.168.115.2 port 5201 [ 8] local 192.168.20.8 port 62106 connected to 192.168.115.2 port 5201 [ 10] local 192.168.20.8 port 62107 connected to 192.168.115.2 port 5201 [ ID] Interval Transfer Bandwidth [ 4] 0.00-20.00 sec 11.6 MBytes 4.85 Mbits/sec [ 6] 0.00-20.00 sec 11.5 MBytes 4.83 Mbits/sec [ 8] 0.00-20.00 sec 11.5 MBytes 4.83 Mbits/sec [ 10] 0.00-20.00 sec 11.5 MBytes 4.83 Mbits/sec [SUM] 0.00-20.00 sec 46.1 MBytes 19.3 Mbits/sec
平均速度は19.3 Mbpsでした。 さらに、各TCPストリームはほぼ同じスループットを受け取りました。
Wiresharkを使用して、トラフィックダンプを収集し、送信側で受信したデータ転送スケジュールを作成します。
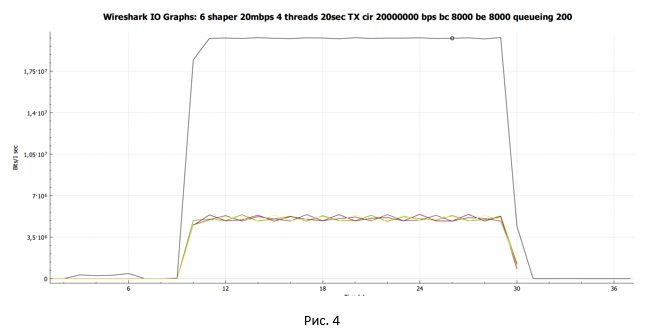
黒い線は総トラフィックを示します。 マルチカラーの線-各TCPストリームのトラフィック。
最初の中間的な結論を下しましょう。
- ポリサーの場合、有効な帯域幅は17.1 Mbpsでした。 異なる時点での各ストリームのスループットは異なりました。
- シェーパーの場合、使用可能なスループットは19.3 Mbit / sでした。 すべてのスレッドのスループットはほぼ同じでした。
ポリサーとシェーパーが機能する場合のTCPセッションの動作を詳しく見てみましょう。 幸い、Wiresharkにはこのような分析を行うのに十分なツールがあります。
パケットの送信時間を参照して表示されるグラフから始めましょう。 最初のチャートはポリサー、2番目のチャートはシェーパーです。
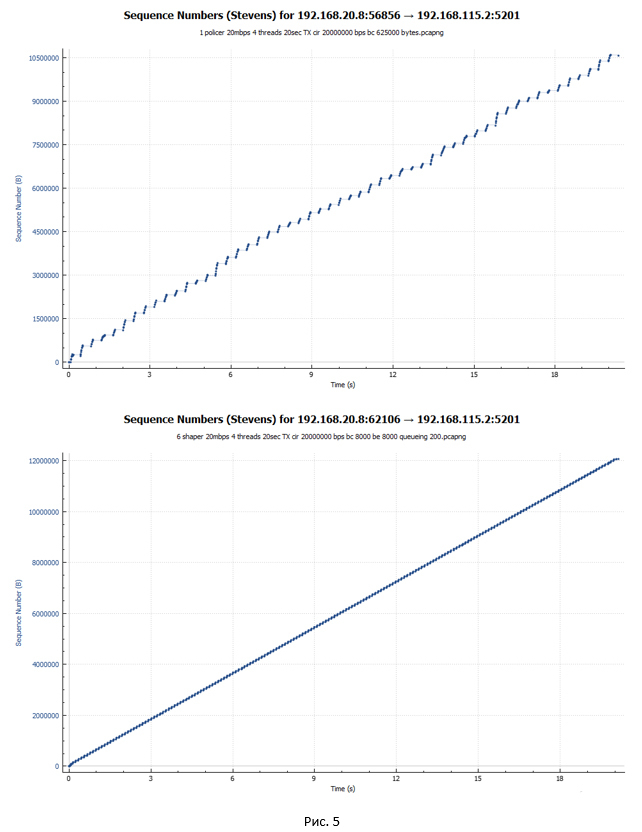
グラフは、シェーパーの場合のパケットが時間内により均等に送信されることを示しています。 さらに、ポリサーの場合、セッションのけいれん的な加速と一時停止の期間が表示されます。
ポリサー動作時のTCPセッションの分析
TCPセッションを詳しく見てみましょう。 ポリサーのケースを検討します。
TCPは、その作業において、かなり大きなアルゴリズムセットに依存しています。 その中でも、私たちにとって最も興味深いのは、輻輳制御を担当するアルゴリズムです。 セッション内のデータ転送速度に責任があります。 iPerfを実行しているPCはWindows 10で実行されます。Windows10では、このようなアルゴリズムとして複合TCP (CTCP)が使用されます。 CTCPは、その作業においてTCP Renoアルゴリズムから多くを借りました。 したがって、TCPセッションを分析するときは、TCP Renoアルゴリズムを実行するときに、セッション状態の画像を見ると非常に便利です。
次の図は、初期データ転送セグメントを示しています。
- 最初の段階で、TCPセッションをセットアップします(トリプルハンドシェイクが発生します)。
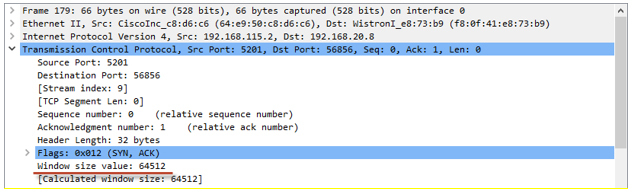
- 次に、TCPセッションのオーバークロックが開始されます。 TCP スロースタートアルゴリズムが機能します。 既定では、Windows 10のTCPセッションの輻輳ウィンドウ(cwnd)値は、10個の最大TCPセッションデータセグメント(MSS)のボリュームに等しくなります。 つまり、このPCはACKの形式で確認を待たずに、一度に10個のパケットを送信できます。 スロースタート(ssthresh)終了しきい値の初期値と輻輳回避モードへの移行は、受信者が提供した最大ウィンドウ(広告されたウィンドウ-awnd)です。 この例では、ssthresh = awnd = 64Kです。 Awnd-受信者がバッファで受信する準備ができているデータの最大値。
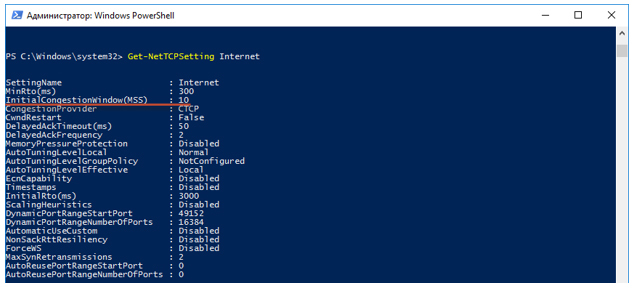
最初のセッションデータはどこにありますか?PowerShellを使用してTCPパラメーターを表示できます。
システムでデフォルトで使用されるグローバルTCPテンプレートを確認します。

次に、Get-NetTCPSettingインターネット要求を実行し、InitialCongestionWindow(MSS)値の値を探します。
awnd値は、受信者から受信したACKパケットで見つけることができます。
TCPスロースタートモードでは、ACKを受信するたびにウィンドウサイズ(cwnd)が増加します。 ただし、awnd値を超えることはできません。 この動作により、送信パケット数はほぼ指数関数的に増加します。 TCPセッションは非常に積極的に加速します。
TCPパケット転送のスロースタート- PCはTCP接続を確立します(No. 1-3)。
- cwnd = 10 * MSSであるため、確認(ACK)を待たずに10パケット(No. 4-13)を送信します。
- 2つのパケットを同時に確認するACK(No. 14)を受信します(No. 4-5)。
- ウィンドウサイズを大きくするCwnd =(10 + 2)* MSS = 12 * MSS。
- 追加の3パケットを送信します(No. 15-17)。 理論上、PCは4つのパケットを送信することになっています。2つは、以前に送信された2つのパケットの確認を受信したためです。 さらに、ウィンドウの拡大のために2つのパッケージ。 しかし、実際には、最初の段階で、システムは(2N-1)パケットを送信します。 この質問に対する答えが見つかりませんでした。 誰かが私に言ったら、私は感謝します。
- 2つのACKを取得します(No. 18-19)。 最初のACKは、リモート側が4つのパケットを受信したことを確認します(No. 6-9)。 2番目-3(No. 10-12)。
- ウィンドウサイズCwnd =(12 + 7)* MSS = 19 * MSSを増やします。
- 14個のパケット(No. 20-33)を送信します。7個の新しいパケット。以前に送信された7個のパケットに対してACKを受信し、ウィンドウが大きくなるにつれて7個の新しいパケットを受信しました。
- などなど。
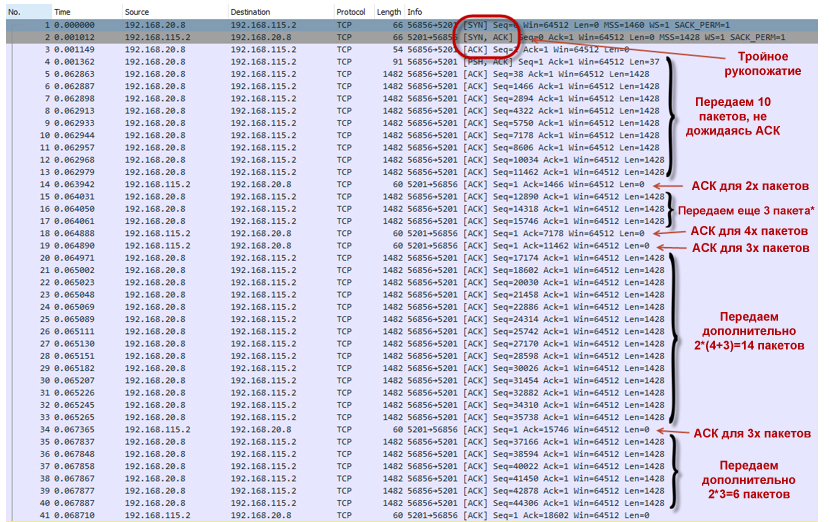
- ポリサーは、セッションの分散を妨げません。 バケットには多くのトークンがあります(ポリサーが初期化されると、バケットはトークンで完全に満たされます)。 20 Mbpsの速度の場合、デフォルトのバケットサイズは625,000バイトに設定されます。 したがって、ある時点でセッションはほぼ18 Mbpsに加速されます(このようなセッションが4つあることを覚えています)。 cwndウィンドウのサイズは最大値に達し、awndと等しくなります。つまり、cwnd = ssthershです。
cwnd = ssthershcwnd = ssthershの正確な答え、スロースタートから輻輳回避アルゴリズムへのアルゴリズムの変更があるかどうか、私は見つけることができませんでした。 RFCは正確な答えを提供していません。 実用的な観点からは、ウィンドウのサイズをそれ以上大きくすることはできないため、これはあまり重要ではありません。
- セッションが非常に強力に分散されたため、トークンは非常に迅速に消費され、最終的に終了します。 バケットには一杯になる時間はありません(トークンの充填は20 Mbit / sの速度のためですが、ある時点での4つのセッションすべてによる合計使用率は80 Mbit / sに近いです)。 ポリサーはパケットのドロップを開始します。 したがって、彼らは向こう側に到達しません。 受信者はDuplicate ACK(Dup ACK)を送信します。これは送信者にパケットの損失があり、再度転送する必要があることを通知します。
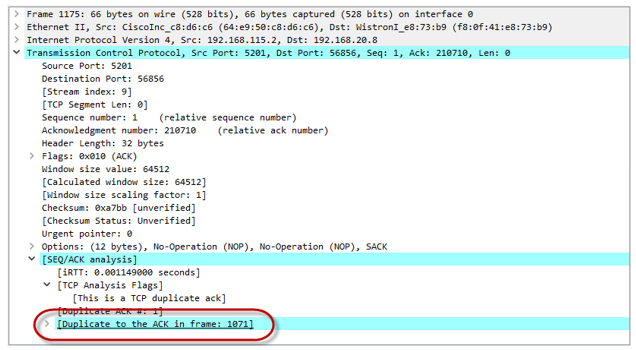
3つのDup ACKを受信した後、TCPセッションは損失後の回復フェーズに入ります(高速再送信/高速回復アルゴリズムを含む損失回復)。 送信者は新しい値ssthresh = cwnd / 2(32K)を設定し、ウィンドウをcwnd = ssthresh + 3 * MSSにします。
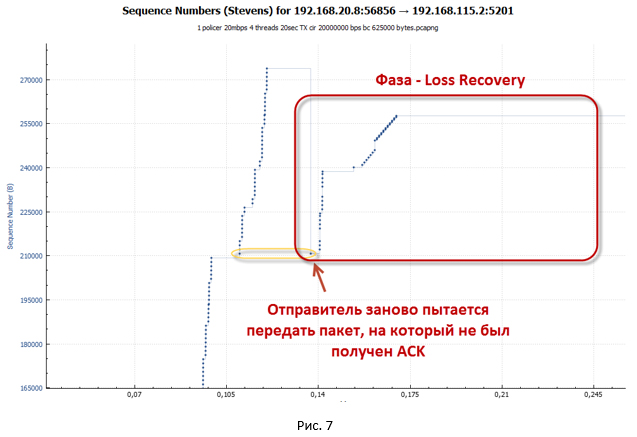
- 送信者はすぐに失われたパケットの再送信を試みます(TCP高速再送信アルゴリズムが機能します)。 同時に、Dup ACKが引き続き送信されます。その目的は、cwndウィンドウを人為的に増やすことです。 これは、パケット損失のためにできるだけ早くセッション速度を回復するために必要です。 Dup ACKにより、cwndウィンドウは最大値(awnd)に成長します。
cwndウィンドウに収まるパケット数が送信されるとすぐに、システムが停止します。 データ転送を続行するには、新しいACK(Dup ACKではない)が必要です。 しかし、ACKは届きません。 繰り返されるすべてのパケットはポリサーによって破棄されるため、バケット内でトークンが不足し、それらを埋めるのに時間がかかりすぎます。
- この状態では、システムはリモート側から新しいACKを受信するためのタイムアウト(Retransmission timeout- RTO )が機能するまで待機します。 チャートに表示される大きな一時停止は、これと正確に関連しています。
- RTOタイマーがトリガーされると、システムはスロースタートモードになり、ssthresh = FlightSize / 2(FlightSizeは未確認データの数)、およびウィンドウcwnd = 1 * MSSに設定されます。 次に、失われたパケットを転送しようとします。 確かに、cwnd = 1 * MSSであるため、1つのパケットのみが送信されます。
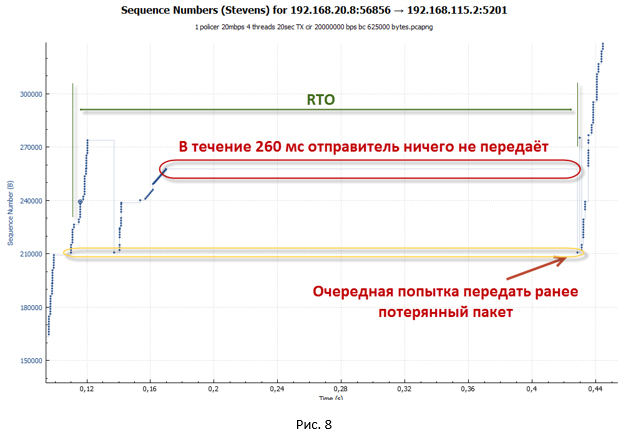
- しばらくの間、システムは何も送信しなかったため、トークンがバケットに蓄積されました。 したがって、最終的に、パケットは受信者に到達します。 そのため、新しいACKを取得します。 この瞬間から、システムは以前に失われたパケットの送信をスロースタートモードで開始します。 セッションの加速があります。 cwndウィンドウがssthreshより大きいとすぐに、セッションは輻輳回避モードに入ります。
複合TCPアルゴリズムでは、送信ウィンドウ(wnd)を使用して伝送速度を制御します。これは、過負荷ウィンドウ(cwnd)と遅延ウィンドウ(遅延ウィンドウ-dwnd)の2つの重み付け値に依存します。 前と同様、Cwndは受信したACKに依存し、dwndはRTT遅延の量(往復時間)に依存します。 wndウィンドウは、RTT期間ごとに1回だけ拡大します。 覚えているように、スロースタートの場合、ACKを受信するたびにcwndウィンドウが大きくなりました。 したがって、輻輳回避モードでは、セッションはそれほど速く加速しません。
- セッションが十分に強力に加速すると(バケット内のトークンよりも多くのパケットが送信された場合)すぐに、ポリサーが再びトリガーされます。 パケットは破棄されます。 これに続いて、損失回復フェーズが行われます。 つまり プロセス全体が新たに繰り返されます。 そして、これはすべてのデータの転送が完了するまで続きます。
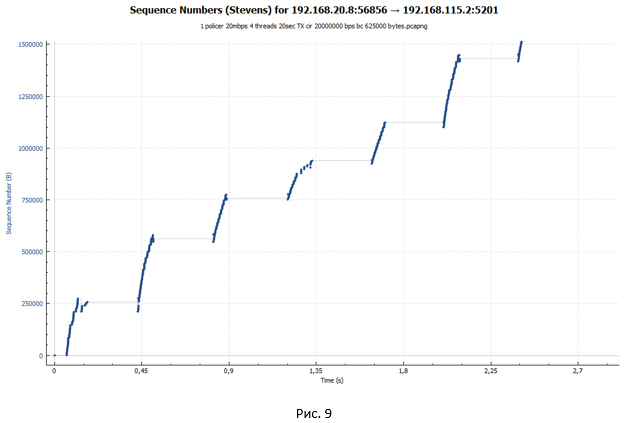
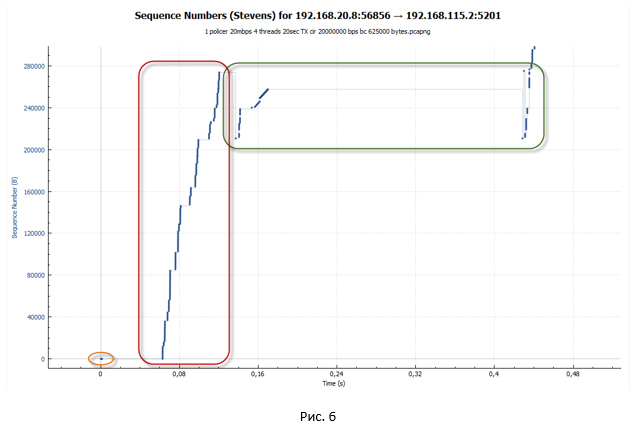
ポリサーTCPセッションは、はしごのように見えます(送信フェーズの後に一時停止があります)。
シェーパーを操作するときのTCPセッションの分析
次に、シェーパーケースのデータセグメントを詳しく見てみましょう。 わかりやすくするために、図6のポリサーグラフと同様の尺度を採用しています。
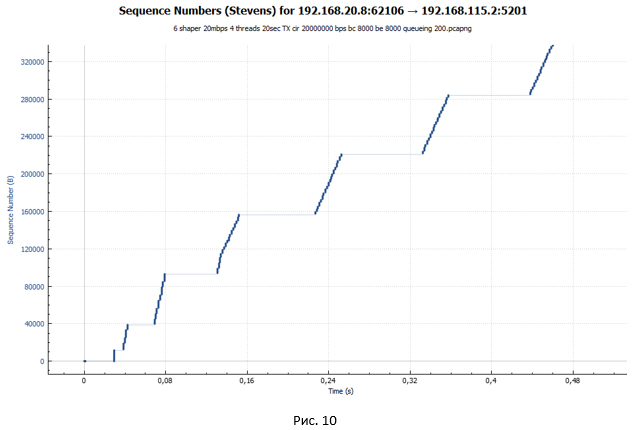
グラフから、同じ梯子が見えます。 しかし、ステップのサイズは大幅に小さくなりました。 ただし、図のグラフをよく見ると 図10のように、各ステップの終わりに小さな「波」は見られません。 9.そのような「波」はパケット損失の結果であり、それらを再送信しようとします。
シェーパーケースの初期データ転送セグメントを検討します。
セッションが確立されています。 次に、TCPスロースタートモードでオーバークロックが開始されます。 しかし、この加速はより穏やかで、一時停止が顕著であり、サイズが大きくなります。 より穏やかなオーバークロックは、シェーパー合計のデフォルトのバケットサイズ(BC + BE)= 20,000バイトであるためです。 ポリサーの場合、バケットサイズは625,000バイトです。 したがって、シェーパーはずっと早く動作します。 パケットはキューに入り始めます。 遅延は送信者から受信者へと増加し、ACKはポリサーの場合よりも遅くなります。 ウィンドウの成長はずっと遅くなります。 システムがパケットを送信するほど、キューに蓄積されるパケットの量が増えることがわかります。つまり、ACKを受信する際の遅延が大きくなります。 自主規制のプロセスがあります。
しばらくすると、cwndウィンドウはawndに到達します。 しかし、この時点で、キューが存在するため、かなり顕著な遅延が累積しています。 最終的に、特定のRTT値に達すると、セッション速度がそれ以上変化せず、特定のRTTの最大値に達すると平衡状態が発生します。 私の例では、平均RTTは107ミリ秒、awnd = 64512バイトであるため、最大セッション速度はawnd / RTT = 4.82 Mbit / sに対応します。 およそこの値は、測定中にiPerfによって提供されました。
しかし、伝送の顕著な休止はどこから来るのでしょうか? TCPセッションが1つしかない場合のシェーパーを備えたデバイスを介したパケット送信のスケジュールを見てみましょう(図12)。 実験では、データ転送は4つのTCPセッション内で発生することを思い出させてください。
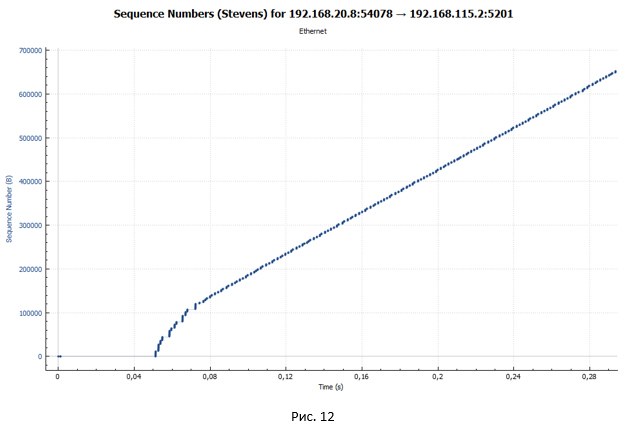
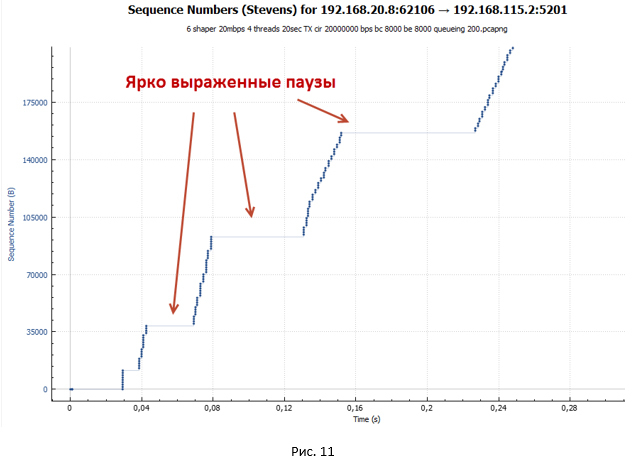
このグラフでは、休止がないことが非常にはっきりとわかります。 これから、図10および11の一時停止は、4つのストリームが同時に送信され、シェーパーに1つのキュー(FIFOキューのタイプ)があるという事実によるものであると結論付けることができます。
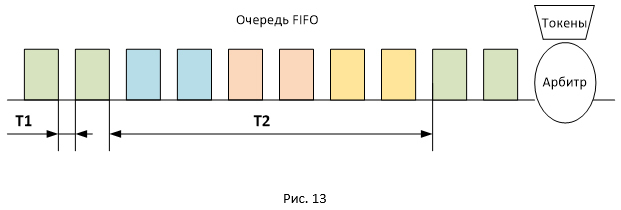
図13は、FIFOキュー内のさまざまなセッションのパケットの場所を示しています。 パケットはバッチで送信されるため、同じ方法でキューに入れられます。 この点で、受信側でのパケットの受信間の遅延は、T1とT2の2つのタイプになります(T2はT1を大幅に超えます)。 すべてのパケットのRTT値の合計は同じですが、パケットは、T2の値によって時間的に分離されたパケットで到着します。 そのため、時間T2では送信者にACKが届かないため、セッションウィンドウは変更されません(最大値はawndに等しい)ので、一時停止が取得されます。
WFQキュー
セッションごとに1つの一般的なFIFOキューを複数のFIFOキューに置き換えた場合、顕著な休止は発生しないと考えるのが論理的です。 このようなタスクの場合、たとえば、Weighted Fair Queuing( WFQ )タイプのキューが適しています。 セッションごとに、独自のパケットキューを作成します。
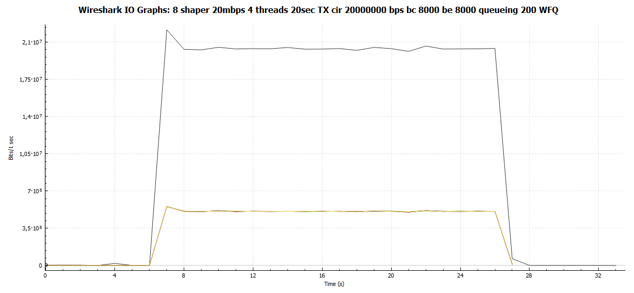
一般的なグラフから、4つのTCPセッションすべてのグラフが同一であることがすぐにわかります。 つまり それらはすべて同じ帯域幅を取得しました。
そして、これは、図1とまったく同じスケールでの送信時間によるパケットの分布のグラフです。 11.一時停止はありません。
WFQタイプのキューを使用すると、スループットをより均等に分散できるだけでなく、あるタイプのトラフィックが別のタイプのトラフィックの「目詰まり」を防ぐことができます。 私たちは常にTCPについて話しましたが、UDPトラフィックもネットワーク上に存在します。 UDPには、伝送速度(フロー制御、輻輳制御)を調整するメカニズムがありません。 このため、UDPトラフィックはシェーパーの共有FIFOキューを簡単に詰まらせる可能性があり、これはTCP伝送に劇的に影響します。 FIFOキューがパケットで完全に満たされると、デフォルトでテールドロップメカニズムが動作を開始し、新しく到着したすべてのパケットが破棄されることを思い出してください。 WFQキューを構成している場合、各セッションはそのキューでのバッファリングの瞬間を待ちます。つまり、TCPセッションはUDPセッションから分離されます。
policy-map Shaper class shaper_class shape average 20000000 queue-limit 200 packets fair-queue
一般的なグラフから、4つのTCPセッションすべてのグラフが同一であることがすぐにわかります。 つまり それらはすべて同じ帯域幅を取得しました。
そして、これは、図1とまったく同じスケールでの送信時間によるパケットの分布のグラフです。 11.一時停止はありません。
WFQタイプのキューを使用すると、スループットをより均等に分散できるだけでなく、あるタイプのトラフィックが別のタイプのトラフィックの「目詰まり」を防ぐことができます。 私たちは常にTCPについて話しましたが、UDPトラフィックもネットワーク上に存在します。 UDPには、伝送速度(フロー制御、輻輳制御)を調整するメカニズムがありません。 このため、UDPトラフィックはシェーパーの共有FIFOキューを簡単に詰まらせる可能性があり、これはTCP伝送に劇的に影響します。 FIFOキューがパケットで完全に満たされると、デフォルトでテールドロップメカニズムが動作を開始し、新しく到着したすべてのパケットが破棄されることを思い出してください。 WFQキューを構成している場合、各セッションはそのキューでのバッファリングの瞬間を待ちます。つまり、TCPセッションはUDPセッションから分離されます。
シェーパーを使用する際にパケット転送スケジュールを分析した後にできる最も重要な結論は、失われたパケットがないということです。 RTTの増加により、セッション速度はシェーパーの速度に適応します。
キューの深さはセッションに影響しますか?
もちろん! 最初(他の誰かがこれを覚えている場合)、キューの深さを83(デフォルト値)から200パケットに変更しました。 これは、キューが十分なRTT値を取得するのに十分であり、セッションの合計速度が20 Mbpsにほぼ等しくなるようにするためです。 そのため、パッケージはシェーパーのキューから「抜け落ちる」ことはありません。
83パケットの深さでは、キューは目的のRTT値に達するよりも速くオーバーフローします。 パケットは破棄されます。 これは、TCPスロースタートメカニズムが機能する初期段階で特に顕著です(セッションは可能な限り積極的に加速します)。 RTTの増加はセッション速度がよりスムーズに増加するという事実につながるため、ドロップされたパケットの数はポリサーの場合よりも比較にならないほど少ないことに注意する価値があります。 思い出すように、CTCPアルゴリズムでは、ウィンドウサイズもRTT値に依存します。
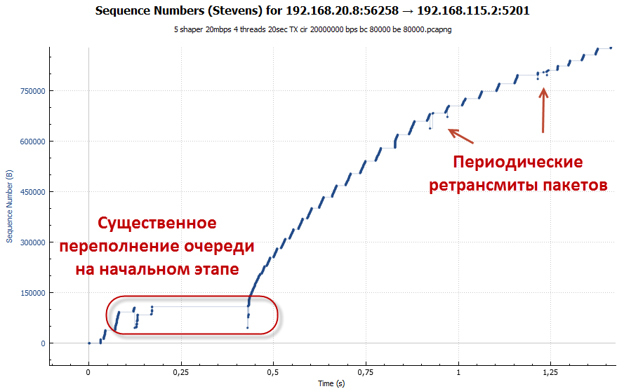
83パケットの深さでは、キューは目的のRTT値に達するよりも速くオーバーフローします。 パケットは破棄されます。 これは、TCPスロースタートメカニズムが機能する初期段階で特に顕著です(セッションは可能な限り積極的に加速します)。 RTTの増加はセッション速度がよりスムーズに増加するという事実につながるため、ドロップされたパケットの数はポリサーの場合よりも比較にならないほど少ないことに注意する価値があります。 思い出すように、CTCPアルゴリズムでは、ウィンドウサイズもRTT値に依存します。
ポリサーとシェーパーの帯域幅使用率と遅延グラフ
小規模な研究の結論として、より一般的なグラフをいくつか作成し、その後、取得したデータの分析に進みます。
帯域利用率のスケジュール:
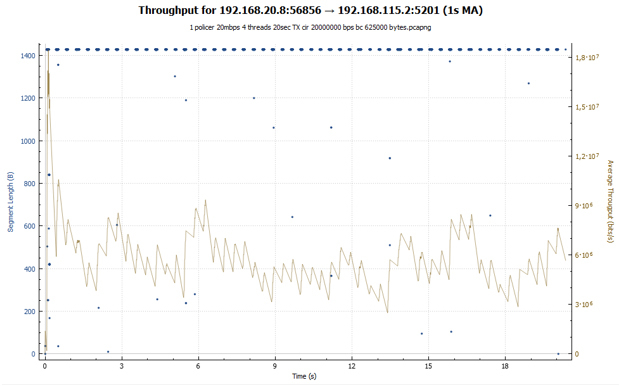
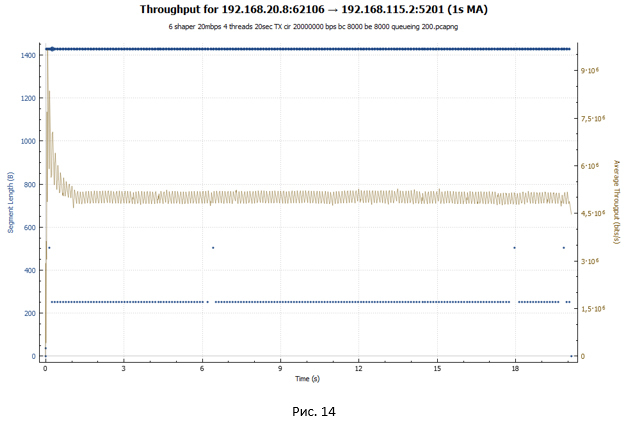
ポリサーの場合、急激なグラフが表示されます。セッションが加速し、その後損失が発生し、速度が低下します。 その後、すべてが再び繰り返されます。 シェーパーの場合、セッションは送信全体でほぼ同じスループットを受け取ります。 セッション速度は、RTT値を増やすことで調整されます。 両方のチャートで、爆発的な成長が最初に観察されます。 これは、バケットが最初は完全にトークンで満たされ、TCPセッションは何にも拘束されないため、比較的大きな値に加速されるためです(シェーパーの場合、この値は2倍小さくなります)。
ポリサーとシェーパーのRTT遅延グラフ(良い意味で、これはシェーパーについて話すときに覚えておくべき最初のことです):
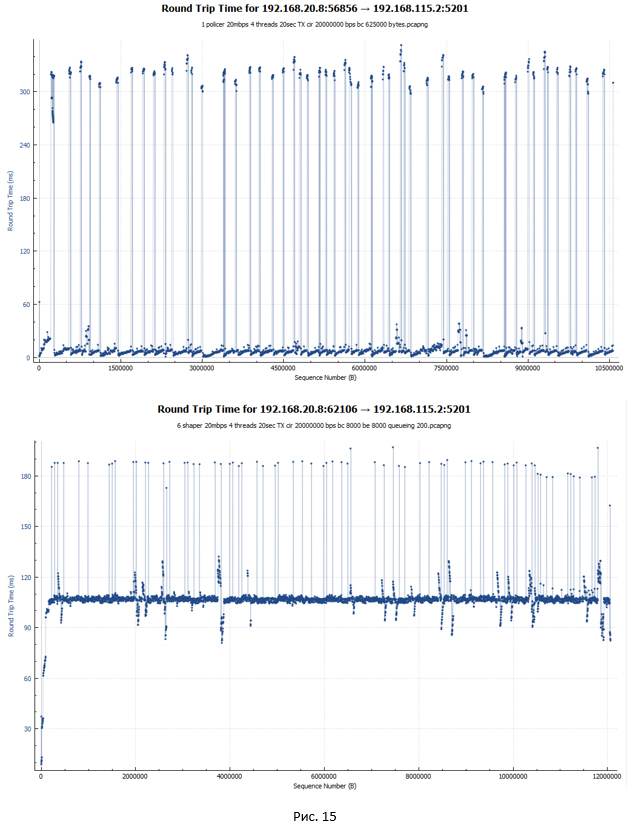
ポリサー(最初のグラフ)の場合、ほとんどのパケットのRTT遅延は最小で、5ミリ秒のオーダーです。 大幅な飛躍(最大340ミリ秒)もチャートに示されています。 これらは、パケットが破棄されて再送信された瞬間です。 WiresharkがTCPトラフィックのRTTをどのように考慮するかは注目に値します。 RTTは、元のパケットを送信してからACKを受信するまでの時間です。 これに関して、元のパケットが失われ、システムがパケットを再送信した場合、RTT値は増加します。これは、開始点がいずれにしても元のパケットが送信された瞬間だからです。
シェーパーの場合、ほとんどのパケットのRTT遅延は107ミリ秒でした。これらはすべてキューで遅延しているためです。 最大190 msのピークがあります。
結論
それで、最終的な結論は何ですか。 誰かがこれが理解できることに気付くかもしれません。 しかし、私たちの目標はもう少し深く掘ることでした。 実験でTCPセッションの動作を分析したことを思い出してください。
- Shaper 13% , policer (19.3 17.1 /) 20 /.
- shaper' . WFQ. policer' .
- shaper' (, ). policer' – 12.7%.
policer , , policer'. , , .
- shaper' ( – 102 ). , , shaper' (jitter) . , jitter.
– ( Bufferbloat ). .
- shaper . , . policer' , .
- Policer shaper , UDP «» TCP. .
- shaper' , policer'. .
, . Shaper (FIFO, WFQ .), . , (, WAN ).
policer
Google , policer' . , 2% 7% policer'. policer' 21%, 6 , , . , policer', , , policer .
policer' .
-:
shaper . Shaper , ( BC = 8 000 ). . , . .
- , policer'. . — TCP: TCP Pacing ( RTT, ACK) loss recovery ( ACK ).
policer' .
-:
- policer' (burst size). , TCP , , .
- policer' shaper ( ).
- shaper, policer . shaper , policer. Shaper , . - policer , . .
shaper . Shaper , ( BC = 8 000 ). . , . .
- , policer'. . — TCP: TCP Pacing ( RTT, ACK) loss recovery ( ACK ).
, , : shaper policer. . - , . shaper. - – policer. . .