 こんにちは、Habr!
こんにちは、Habr!
この記事は、ポインター分析などのプログラムを分析するための手法に関する短いシリーズのメモの紹介記事になります。 アルゴリズムポインター分析を使用すると、変数または何らかの式が示すことができるメモリの部分を指定された精度で判断できます。 ポインターに関する情報の知識がなければ、ポインターを積極的に使用するプログラム(つまり、C、C ++、C#、Java、Pythonなどの最新のプログラミング言語のプログラム)の分析は事実上不可能です。 したがって、多かれ少なかれ最適化コンパイラまたは深刻な静的コードアナライザーでは、ポインター解析技術を使用して正確な結果を達成します。
このシリーズの記事では、効果的なプロシージャー間ポインター分析アルゴリズムの作成に焦点を当て、問題に対する主要な最新のアプローチを検討し、そしてもちろん、すばらしいLLVMプログラミング言語用の非常に真剣なポインター分析アルゴリズムを作成します。 猫に興味のある皆さん、私たちはプログラムなどを分析します
プログラムの最適化と分析アルゴリズム
お気に入りのプログラミング言語のコンパイラを書いていると想像してみてください。 字句解析器および構文解析器の作成の背後で、変換モジュールの構文ツリーはすでに構築されており、ソースプログラムは内部表現(たとえば、バイトコードJVMまたはLLVMの形式)で作成されています。 次は? たとえば、一部の仮想マシンで結果のビューを解釈したり、すでにマシンコードでこのビューをさらに変換したりできます。 そして、最初にこのパフォーマンスを最適化してから、退屈なブロードキャストを開始することができますか? さらに、プログラムはより高速に実行されます!
どのような最適化を適用できますか? たとえば、このようなコードを考えてみましょう。
k = 2; if (complexComputationsOMG()) { a = k + 2; } else { a = k * 2; } if (1 < a) { callUrEx(); } k = complexComputationsAgain(); print(a); exit();
complexComputationsOMG
関数が
complexComputationsOMG
値に関係なく、変数
a
の値は
4
であることに注意してください。つまり、プログラムビューからこの関数の呼び出しを安全に削除できます(すべての関数がクリーンであると仮定)特に、副作用はありません)。 さらに、変数
a
が単一性と比較されるプログラムのポイントでは、変数
a
は常に値
4
とるので、
callUrEx
を無条件に
callUrEx
ことができます。つまり、不要な分岐を取り除きます。
さらに、行
k = complexComputationsAgain()
割り当てられた変数
k
値はどこでも使用されないため、この関数は
k = complexComputationsAgain()
できます! これは、すべての変換後に得られるものです。
callUrEx(); print(4); exit();
私の意見では悪くない! 残るのは、このようなコード変換を自動的に実行するようオプティマイザーに教えることだけです。 ここでは、さまざまなデータフロー分析アルゴリズムがすべて助けになり、非常にクールな男であるゲイリー・キルダル自身が、彼の記念碑的な原稿「グローバルプログラム最適化への統一アプローチ」で、プログラム、より正確にはいわゆるデータフロー問題を分析するための普遍的なフレームワークを提示しました。
記述的に、データフローの問題を反復的に解決するアルゴリズムは非常に単純に聞こえます。 必要なのは、分析中に追跡する変数のプロパティのセット(変数の可能な値など)、各ベースユニットのそのようなセットの解釈関数、およびベースユニット間でこれらのプロパティを分配するルール(たとえば、交差点)を決定することですセット)。 反復アルゴリズムプロセスでは、 コントロールフローグラフ(CFG )のさまざまなポイント、通常は各ベースユニットの最初と最後で、変数のこれらのプロパティの値を計算します。 これらのプロパティを繰り返し伝播することにより、最終的にアルゴリズムが作業を終了する固定点(fixpoint)に到達する必要があります。

もちろん、100回聞くよりも1回見る方が良いので、例で言葉を補強します。 次のコードフラグメントを検討し、プログラムのさまざまなポイントで変数の可能な値を追跡してください。
b = 3; y = 5; while (...) { y = b * 2; } if (b < 4) { println("Here we go!"); }
以下の挿入図では、プログラム分析の古典的な問題、つまり、考慮されたコードフラグメントの定数の伝播(定数伝播)が解決されています。
反復定数伝播アルゴリズム
最初は、変数の可能な値のセットはすべて空です。
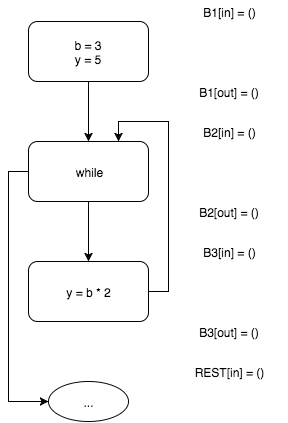
入力ブロック
解釈すると、このブロックの出力で
および
ます。 関数
(同様の関数は残りのブロックに対して定義されます)は、ブロックの解釈関数です。

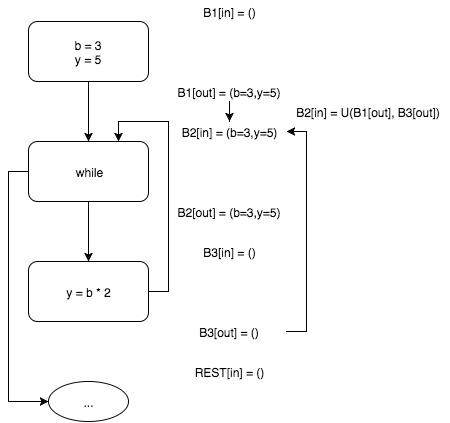
のループエントリブロックには、入力ブロック
とブロック
2つの祖先があります。 ブロック
はまだ変数の可能な値が含まれていないため、アルゴリズムの現在の段階では、ブロック
入出力で
および
であると考えます。 関数
は、変数のプロパティセット(通常、部分的に順序付けられたセットの正確な下限、または完全なラティス )の分布のルールです。
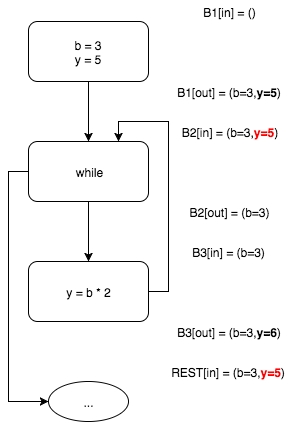
出力では、ベースユニット
および
です。

変数の可能な値に関する情報が変更されているため(初期状態と比較して、つまり、アルゴリズムの0回目の反復のように)、アルゴリズムの次の反復を開始します。 新しい反復は、ブロック
入力セットを計算するステップを除き、前の反復を繰り返します。
ご覧のとおり、今回はブロック
と
出力セットを「クロス」する必要があります。 これらのセットには共通の部分
あり、これは残しますが、異なる部分
および
、これらは破棄せざるを得ません。
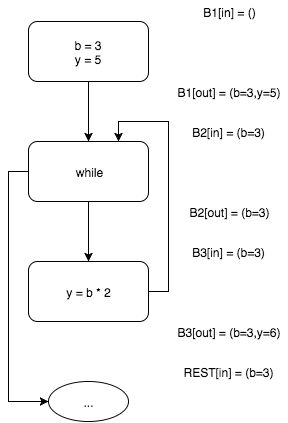
さらに計算を続けると新しい値を受け取らないため、アルゴリズムの操作は完了したと見なすことができます。 これは、定点に到達したことを意味します。
入力ブロック
B1
解釈すると、このブロックの出力で
b=3
および
y=5
ます。 関数
f1
(同様の関数は残りのブロックに対して定義されます)は、ブロックの解釈関数です。
B2
のループエントリブロックには、入力ブロック
B1
とブロック
B3
2つの祖先があります。 ブロック
B3
はまだ変数の可能な値が含まれていないため、アルゴリズムの現在の段階では、ブロック
B2
入出力で
b=3
および
y=5
であると考えます。 関数
U
は、変数のプロパティセット(通常、部分的に順序付けられたセットの正確な下限、または完全なラティス )の分布のルールです。
出力では、ベースユニット
B3
b=3
および
y=6
です。
変数の可能な値に関する情報が変更されているため(初期状態と比較して、つまり、アルゴリズムの0回目の反復のように)、アルゴリズムの次の反復を開始します。 新しい反復は、ブロック
B2
入力セットを計算するステップを除き、前の反復を繰り返します。
ご覧のとおり、今回はブロック
B1
と
B3
出力セットを「クロス」する必要があります。 これらのセットには共通の部分
b=3
あり、これは残しますが、異なる部分
y=5
および
y=6
、これらは破棄せざるを得ません。
さらに計算を続けると新しい値を受け取らないため、アルゴリズムの操作は完了したと見なすことができます。 これは、定点に到達したことを意味します。
Gary Kildallは、このような反復アルゴリズムが常に作業を完了し、さらに次の条件が満たされた場合に可能な限り最も完全な結果をもたらすことを示しました。
- 監視される変数プロパティのドメインは完全な格子です。
- ブロック解釈関数は、格子上の分布特性を持っています。
- ベースブロックの前任者を「満たす」ために、正確な下限の演算子が使用されます(つまり、部分的に順序付けられたセットのミート関数)。
ビッグサイエンスの世界からの逸話
面白いことに、キルダルが彼の仕事(定数伝播)で使用した例は、データフロー問題に対して設定した要件を満たしていません-定数伝播の解釈関数は、格子上の分布特性を持たず、単調です。
したがって、プログラムを最適化するために、たとえば反復アルゴリズムを使用して、データフロー分析アルゴリズムの全機能を使用できます。 最初の例に戻って、定数伝播および活性分析(ライブ変数分析)を使用して、デッドコード除去最適化を実装しました。
さらに、情報セキュリティのコンテキストで静的コード分析を実行する場合、データフロー分析アルゴリズムを使用できます。 たとえば、SQLインジェクションクラスの脆弱性を検索するプロセスでは、攻撃者によって何らかの方法で影響を受ける可能性のあるすべての変数(たとえば、HTTP要求パラメーターなど)を特別なフラグでマークできます。 このフラグでマークされた変数が適切な処理なしでSQLクエリの形成に関与していることが判明した場合、おそらくアプリケーションに重大なセキュリティホールが見つかりました! 可能性のある脆弱性についてのメッセージを表示し、そのような脆弱性を診断して除去するための推奨事項をユーザー
乗算悲しみ
イワンはピーターにうなずき、ピーターはイヴァンにうなずきます
前の段落を要約すると、データフロー分析アルゴリズムは、あらゆるコンパイラの毎日のパン(そしてバターです!)です。 それで、ポインター分析は実際にそれと何の関係があり、なぜ実際に必要なのでしょうか?
次の例で気分を台無しにしてしまいます。
x = 1; *p = 3; if (x < 3) { killTheCat(); }
変数
p
指す場所を知らないと、条件付き
if
の式
x < 3
値が等しくなるかどうかを確実に言うことはできません。 特定のコードフラグメントが出現するコンテキストを見つけた後にのみ、この質問に答えることができます。 たとえば、
p
は別のモジュールのグローバル変数(Cファミリのプログラミング言語では何でもいつでも示すことができます)またはヒープ内のどこかを指すローカル変数です。 コンテキストを知っていても、この変数が指すことができる多くの場所(抽象的なメモリセル)を知る必要があります。 たとえば、示されたコードフラグメントの前に、変数
p
p = new int
として初期化された場合、最適化されたプログラムから条件付きジャンプを削除し、無条件で
killTheCat
メソッドを呼び出す必要があります。
その場合、分析されたプログラムの変数が指し示す可能性のあるすべての場所を一度に見つける方法を見つけるまで、このコードに単一の最適化を適用することはできません。
ポインター解析アルゴリズムを使用せずには実行できないことが明らかになったと思います(その理由は、この困難で正確なアルゴリズムで解決できない問題を解決する必要が生じたためです)。 ポインター分析は、ポインターの値またはポインター型の式に関する情報を定義する静的コード分析メソッドです。 解決されるタスクに応じて、ポインター分析は、プログラム内の各ポイントまたはプログラム全体の情報(フロー感度)、または関数呼び出しのコンテキスト(コンテキスト感度)に応じて情報を決定できます。 ポインター分析タイプについては、シリーズの今後の記事で詳しく説明します。
通常、分析結果は、多くのポインターからこれらのポインターが参照できる多くの場所のセットへのマッピングの形式で表示されます。 つまり、簡単に言えば、各ポインター
p
、それが指すことができるオブジェクトのセットに関連付けられています。 たとえば、以下のコードスニペットでは、分析の結果はマッピング
p -> {a, b}, q -> {p}
です。
int a, b, c, *p, **q; p = &a; q = &p; *q = &b;
ポインタ分析によって計算されたマッピングは、セキュリティ基準を満たしている必要があります。つまり、できるだけ保守的であることに注意することが重要です。 それ以外の場合、最適化により元のプログラムのセマンティクスを台無しにすることができます。 たとえば、上記のプログラムフラグメントのポインタ解析の結果の安全な近似値は、
p -> {a, b, c}, q -> {unknown}
です。
unknown
値は、ポインターが使用可能なすべてのプログラムオブジェクトを参照できることを示すために使用されます。
たとえば、次のコードスニペットでは、変数
p
逆参照すると、プログラムオブジェクトの値が変更される可能性があります。
extern int *offensiveFoo(); p = offensiveFoo(); *p = 77;
offensiveFoo
関数については何も知りません。これは別の翻訳モジュールからインポートされたため、
p
が絶対に何でも指すことができると仮定することを余儀なくされています!
将来、反対の言葉が明示的に議論されない限り、考慮中のすべての関数とグローバル変数は分析された翻訳モジュールに属すると想定します。
貧乏人のポインター分析
 ためらうことなく、ポインターエイリアシングの問題に初めて直面したとき、ラティスで既に知られている反復アルゴリズムを使用して問題を解決しようとすることにしました(その後、ポインター分析アルゴリズムが解決する問題と同じ問題を解決しているとは知りませんでした)。 実際、ポインターがこれらのポインターのプロパティのセットとして参照できるオブジェクトを追跡できないのはなぜですか? 簡単な例でアルゴリズムの動作を追跡してみましょう。 オブジェクトのセットの配布のルールをプログラムの「自然な」セマンティクスに対応させて(たとえば、
ためらうことなく、ポインターエイリアシングの問題に初めて直面したとき、ラティスで既に知られている反復アルゴリズムを使用して問題を解決しようとすることにしました(その後、ポインター分析アルゴリズムが解決する問題と同じ問題を解決しているとは知りませんでした)。 実際、ポインターがこれらのポインターのプロパティのセットとして参照できるオブジェクトを追跡できないのはなぜですか? 簡単な例でアルゴリズムの動作を追跡してみましょう。 オブジェクトのセットの配布のルールをプログラムの「自然な」セマンティクスに対応させて(たとえば、 p = &a
場合、
p -> {a}
)、これらのセットをセットの単純な結合によってベースブロック間で配布します(たとえば、
q -> {a, b}
と
q -> {c}
はいくつかの基本ブロックへの入力であり、そのようなブロックの入力セットは
q -> {a, b, c}
)です。
簡単な例でアルゴリズムの動作を検討してください。
x = &a; a = &z; if (...) { x = &b; } else { c = &x; }
反復アルゴリズムが処理を完了するまで待って、結果を見てみましょう。
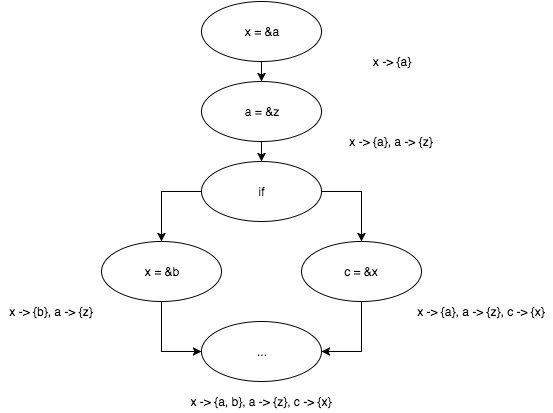
動作します! アルゴリズムの単純さにもかかわらず、提示されたアプローチには生命権があります。 これは、Andersenの研究「Cプログラミング言語のプログラム分析と専門化」が登場する前に、ポインターのエイリアシングの問題を(もちろん大幅に改善されて)解決した方法です。 ちなみに、シリーズの次の記事はこのまさに仕事に捧げられます!
説明したアプローチの主な欠点は、スケーラビリティが低く、結果が保守的すぎることです。実際のプログラムを分析するときは、他の関数の呼び出し(つまり、分析が手続き間でなければならない)と、多くの場合、関数呼び出しのコンテキストを考慮する必要があるためです このアプローチの重要な利点は、プログラム内の各ポイントでポインター情報が利用できることです(つまり、フローセンシティブアルゴリズム)。一方、アンダーセンと彼のフォロワーのアルゴリズムは、プログラム全体の結果を計算します(フローインセンシティブ)。
結論の代わりに

これで、ポインター分析アルゴリズムに関する一連のメモの最初の部分を終了します。 次回は、LLVM用のシンプルで効果的な手続き間ポインター解析アルゴリズムを作成します。
この記事にご協力いただきありがとうございます!