カットの下には、ロシア科学アカデミーの有力な研究者であり、科学の博士であり、機械学習とデータ分析ジャーナルの編集長であるVadim Strizhovによる講演と、ほとんどのスライドがあります。
モノのインターネットの時系列を例として使用して、モデルを生成および選択する方法について説明します。
モノのインターネットの概念は10年以上前に登場しました。 主に通常のインターネットと異なるのは、要求が人によって行われるのではなく、人がいない他のデバイスと対話するネットワーク上のデバイスまたはメッセージによって行われるという点です。
最初の例。 毎月、誰も懐中電灯を持って角に行き、電気メーターがどれだけ傷ついたかを見て、それから足で支払いたがりません。 現代のメーターがアパートの1時間ごとのエネルギー消費量を監視するだけでなく、各コンセントから消費されたエネルギー量も把握していることは明らかです。
2番目のオプション。 人間の健康モニタリング。 この領域にある時系列の例は次のとおりです。 現在、四肢麻痺の患者は、手足に障害があり、手のひらサイズのセンサーを皮質に直接配置しています。 内部からは見えず、完全に閉じられています。 それは、900ヘルツの周波数で皮質の表面から124のチャネルを提供します。 これらの時系列から、手足の動き、彼が動きたい方法を予測できます。
次の例は取引です。 今、店の出口のレジは高価であり、店の出口のキューも良くありません。 このようなシステムを作成し、出口を過ぎて運転するトロリーを持った人が、購入した製品のすべての価格値をすぐに受信したときに、そのような信号を受信する必要があります。
最後のかなり明白な例は、交通信号、照明、気象センサー、洪水などの都市サービスの作業の自動調整です。

これが最初の時系列の例です。 1時間ごとの電力消費量、最大および最小の毎日の温度、湿度、風、日中時間があります。

2番目の時系列の例は、最初の階層の上に階層的に配置されており、特定の地域の各ポイントについてのみ同じです。 この場合、ヨーロッパの一部が表示され、特にこれらの時系列とともに、大気汚染の価値が各ポイントで取り除かれます。

さらに複雑な例は電界です。 周波数は縦軸に沿ってプロットされ、時間は横軸に沿ってプロットされます。 これも時系列です。 過去の時系列が時間と空間と空間のデカルト積である場合、ここに時間と周波数のデカルト積があります。
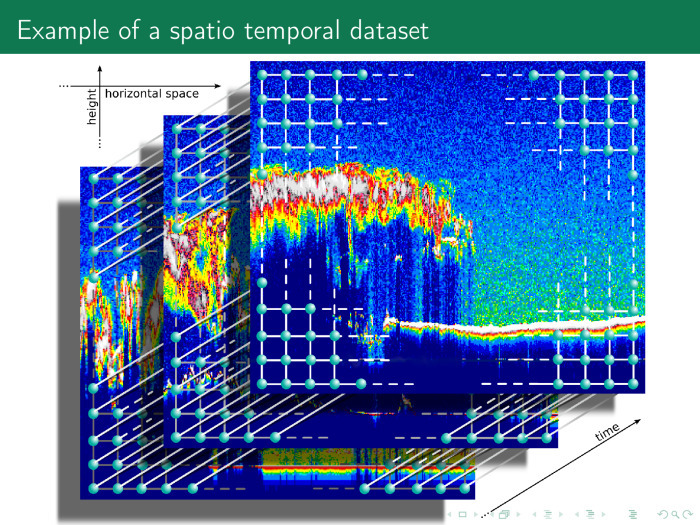
次の時系列はさらに複雑です。 横軸と縦座標軸はスペースで、縦座標軸はスペースです。 したがって、多くの異なる美しい時系列があり、時系列には必ずしも時間と値だけが含まれているわけではありません。 時間、周波数、空間などのいくつかの軸のデカルト積を含む場合があります。
最も単純なオプションを検討してください。 小さな町では時系列の電力消費があります。 価格、消費量、日照時間、温度などがあります。これらの時系列は定期的です。 電力消費は、一年中、週中、日中変動します。
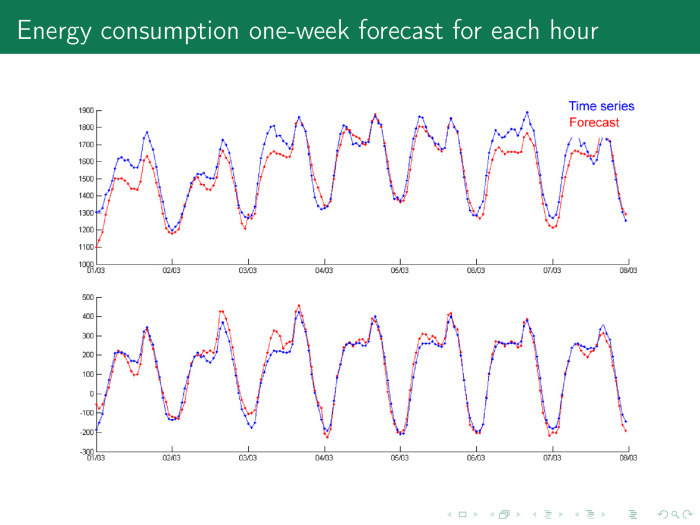
任意の日を取る。 青-時系列、赤-予測。 午前12時、市民は眠りに落ち、マフィアが目を覚ます。 時系列が低下し、消費が低下します。 火力発電所に囲まれているため、一般的にモスクワのすべてがライトで燃えています。エネルギーを投入する場所がないため、電気の価格はゼロを下回ることさえあります。あなたがそれを消費するだけであれば、電気のために余分に支払うことができます。
6時間、市民は目を覚まし、仕事に行き、お茶を飲み、仕事をして、家に帰ります。このサイクルが繰り返されます。
タスクは、翌日の1時間ごとの電力消費を予測し、すぐに1日分のすべての電力を購入することです。 そうしないと、翌日には消費量の差に対して追加料金を支払う必要があり、これはすでにより高価です。
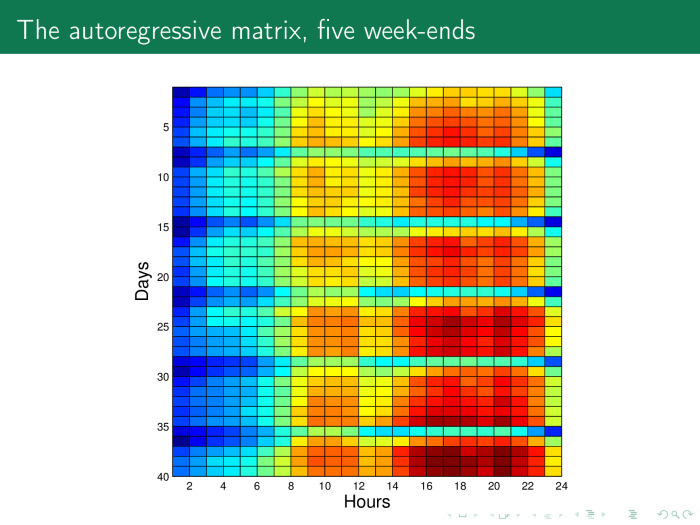
この問題はどのように解決されますか? 前の時系列に基づいてこのようなマトリックスを構築しましょう。 ここでは、行は日数で、24時間で約40日です。 そして、ここでは土曜日と日曜日という特別な行を簡単に見ることができます。 アンカラでは-モスクワのように-土曜日に人々は非常に活発に行動し、日曜日にはリラックスしていることがわかります。
この場合、各列は曜日の20時間です。 ここでわずか5週間。

このマトリックスを正式な形式で表します。 時系列をテールで取得し、曜日または週単位でオフにし、オブジェクト-属性マトリックスを取得します。ここで、オブジェクトは日で、属性は時間であり、標準の線形回帰問題を解きます。
この値を使用して、たとえば翌日の12時になります。 私たちが予測していることは、歴史を通してyを数えることです。 Xは、これらの12時間を除くストーリー全体です。 予測は、先週、値のベクトル、および重みのスカラー積であり、たとえば最小二乗法を使用して取得します。
より正確な予測を得るには何をする必要がありますか? モデルのさまざまな要素を生成しましょう。 それらを生成関数またはプリミティブと呼びます。

時系列で次のことができます。ルートを取得します。 そのままにして、時系列(時系列のルート、時系列-時系列の対数など)を取得できます。
したがって、オブジェクトに列を追加します(属性マトリックス)。列の数を増やします。行の数は同じままです。
さらに、符号を生成するために、コルモゴロフ-ガボール多項式を使用できます。 最初の用語は時系列そのものです。 2番目の用語は、時系列のすべての作品です。 3番目は時系列のトリプルの積です。 など、退屈するまで。
時系列全体から係数を収集し、再び線形モデルを取得します。 その後、かなりまともな予測が得られます。 そして、私たちが再訓練していないという疑いがありますが、予測はあまりにも良いですか?
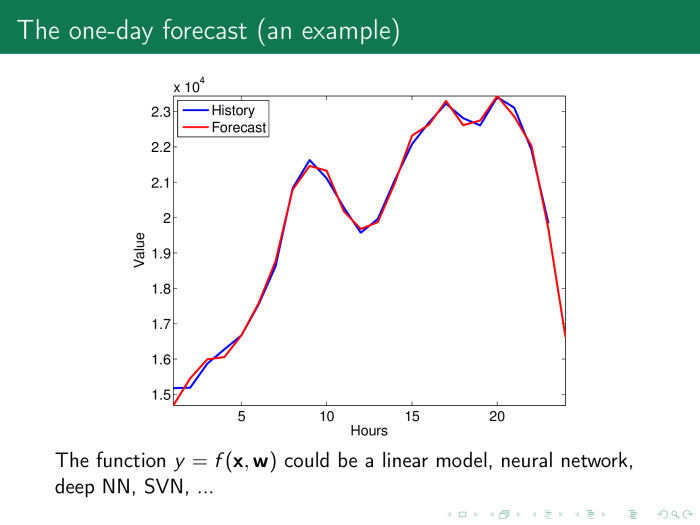
パラメータが一般に意味を失ったほど良いです。
計画マトリックスの行が1週間、7日、168時間であるとします。 たとえば、3年間のデータがあります。 1年に52週間があります。 その後、3年間の基本行列は156行168列です。

リストする6つの時系列を使用する場合(つまり、消費とともに、価格、湿度、温度なども考慮する)、マトリックスには1000を超える列があり、さらに4つの生成関数がある場合、これは4000行です。および156列。 つまり、行列は強く縮退しており、線形方程式を正常に解くことはできません。 どうする?
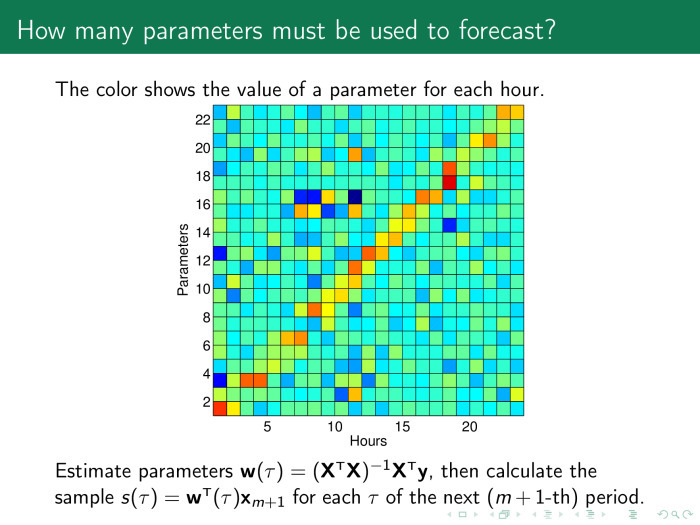
おそらく、モデル選択手順を開始する必要があります。 これを行うには、意味のある重みを確認する必要があります。 1時間ごとに独自のモデルを作成します。ここでは、横座標は翌日のクロックごとにモデルパラメーターの値を示しています。 そして、y軸にはパラメーター自体があります。 黄赤の対角線が表示され、前の日のモデルに1時間があると重みの値が大きくなります。
原理は簡単です。 明日の12時の予測は、前日の12時間、前日の12時間などの値に依存します。したがって、これらの値のみを残して、他のすべてを破棄できます。

正確に何を捨てるべきですか? 行列xを一連の列として表します。 時系列yを、行列xの列の線形(またはオプションで線形)の組み合わせで近似します。 yに近い列χを見つけたいと思います。 2つの列を残したい場合、特性を選択するためのアルゴリズムの重要な部分は、列χ1とχ2を選択します。 しかし、生成したものの中には、χ3とχ4が必要です。 正確で安定したモデルを提供します。 正確-χ3とχ4の線形結合が yに正確に近似し、安定しているため-直交しているため。
なぜちょうど2列なのか? 作業スペース、描画された選択範囲内のオブジェクトの数を確認する必要があります。 3つのオブジェクトがあります。 行列xには3行6列が含まれています。
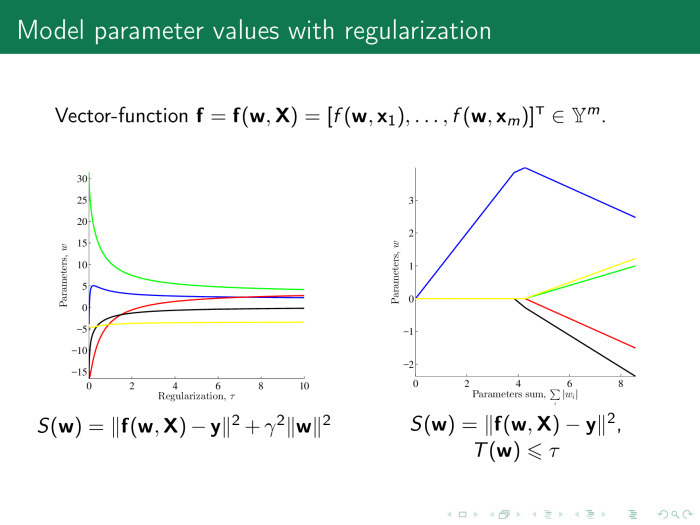
機能選択アルゴリズムはどのように機能しますか? 通常、エラー関数を使用します。 線形回帰では、これらは回帰残差の平方和です。 また、機能選択アルゴリズムには2つのタイプがあります。 最初のタイプは、アルゴリズムの正則化です。 エラーに加えて、彼らは前回の講義でコンスタンチン・ヴィャチェスラヴォヴィッチが言ったように、いくつかのレギュラライザー、パラメーターの値の罰金、罰金の重要性の原因となる係数を使用します。
この係数は、そのようなまたはそのような罰金の形で提示されてもよい。 重みはτの値以下でなければなりません。
最初のケースでは、マトリックスxの列の数、つまり特徴の数を失うことではなく、安定性を高めることだけを話します。 2番目のケースでは、かなりの数の列が失われます。
列が互いにどの程度相関しているかを理解することが重要です。 調べる方法は?
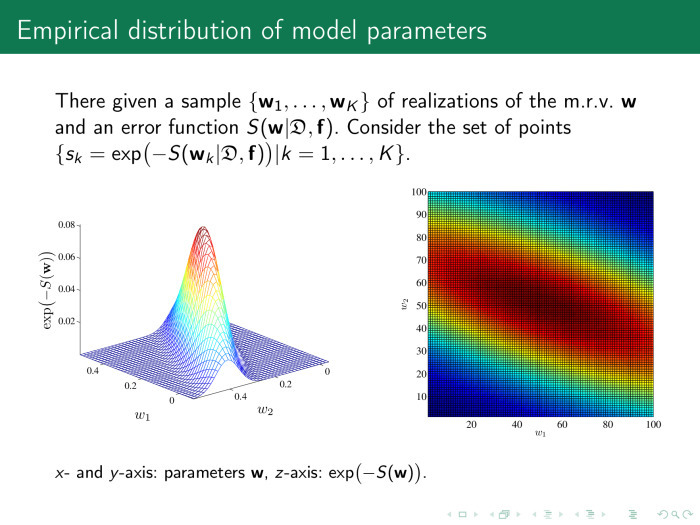
モデルのパラメーター空間、ベクトルwを考慮し、さまざまなポイントwでエラー値を計算します。 右側の図は、スペース自体、w 1またはw 2を示しています。 それぞれ100ポイントの2つの重みがサンプリングされます。 100組の重みが判明しました。 この図の各ポイントは、エラー関数の値です。 左側では、便宜上、同じものは指数のマイナスからエラー関数の値です。
最適値が0.2〜0.25のどこかにあることは明らかであり、これが我々が探しているものです。 そして、パラメーターの重要性は次のように定義されます。パラメーター値を最適値から少し変えてみましょう。 wを変更しても、エラー関数はほとんど変化しません。 なぜこのようなパラメーターが必要なのですか? おそらく必要ありません。
ここで、パラメータの値はw 2軸に沿ってわずかに揺れ、エラー関数は落ちました-正常です。 パラメータ空間分析のこの基礎は、多重相関特性を見つける方法です。
これらの兆候はどこから来たのですか? 特性を生成する4つの主な方法を見てみましょう。 最初の兆候自体です。 どこから来たの? 時系列を取り、それを断片に切り刻みます。たとえば、周期の倍数です。 または偶然に、または重複して。 これらの切り刻まれたセグメントを、計画マトリックスであるマトリックスXに追加します。
2番目の方法。 同じこと。 いくつかのパラメトリックまたはノンパラメトリック記号を使用して、時系列を変換します。
3番目の方法は非常に興味深く、有望です。 一部のモデルで時系列の一部を近似しています。 これをローカルモデリングと呼びます。 そして、これらのモデルのパラメーターを予測の兆候として使用します。
4番目。 すべてはあるメトリック空間で起こります。 この空間で重心、クラスターのクラスターを見つけ、各時系列からこれらのクラスターの重心までの距離を考えてみましょう。

悪いニュース。 計画マトリックスを作成するには、シリーズがマルチパートの場合、サンプリング時系列に対する周波数の比率を短くする必要があります。 この場合、計画マトリックスが拡大します。 確かに、ここに示すように、時系列の一部を捨てることができます。 時系列全体の「夏時間」は不要であり、1日1ポイントのみが必要です。計画マトリックスは次のようになります。連続24ポイントが電力消費量で、1ポイントと別の1ポイントが夏時間です。

これが時系列です。 すでに検討したこと。 x ln xはペアで、合計、差、積、その他のさまざまな組み合わせです。

以下はノンパラメトリック変換です。 ちょうど平均量、標準偏差。 時系列の変位値のヒストグラム。

次のオプション。 ノンパラメトリック変換、Haar変換。 算術平均を取り、2つではなく1つの点として置きます。 または違いを取ります。 したがって、符号を生成し、時系列のポイント数をそれぞれ減らして、空間の次元を減らします。

生成関数の次のセットは、パラメトリック関数です。 それらの助けを借りて、時系列を概算できます。 最初の方法は、最初の行ではなくこの近似行を使用することです。 2番目は、wで示されるパラメーター自体を使用することです。
定数、放物線、双曲線、対数シグモイド、積、べき関数、指数関数。

別の非常に便利なクラスは単調な関数です。 ここで、ニューラルネットワークの専門家は、たとえば、ネットワークでよく使用されるアクティベーション関数を見ることができます。 これらは、ネットワークの出力だけでなく、入力でも使用できます。 これにより、予測の質も大幅に向上します。

生成関数の次のクラスは、時系列のパラメトリック変換です。 ここでは、シリーズ自体のパラメーターに興味があります。 上記の関数を使用して、パラメーターをベクトルbに収集します。 2つのタイプのパラメーターがあります:1つ目は近似関数自体のパラメーター、ローカル近似の関数、2つ目のベクトルはモデルパラメーター、以前に検討されたパラメーター、つまり行列Xの列の線形結合の重みパラメーターです。同時に構成できますが、繰り返し構成し、それらを計画マトリックスの列としても使用します。 つまり、計画マトリックスXが繰り返し変更されます。
モデルパラメータは他にどこで取得できますか? 最後から検討します。 時系列を近似する場合、スプラインにはパラメーター、スプラインノードがあります。
高速フーリエ変換。 時系列の代わりに、そのスペクトルを使用して、オブジェクト(属性マトリックス)に挿入することもできます。
重要かつ適切に機能する手法は、特異構造解析またはキャタピラー法のパラメーターを使用することです。

この方法は次のように機能します。 最初に、マトリックスXを作成しました-同様のスキームに従って新しいマトリックスを作成しましょう。 ここで、局所近似行列はHと呼ばれ、次のように構築されます。時系列のセグメントは、行列の行に次々にではなく、重複して含まれます。 ここでp = 1、k = 3とします。インデックスによる行列は1,2,3のようになります。 2,3,4; 最後まで3,4,5など。
同じ最小二乗法によって前の列に従って最後の列を調整し、係数を属性として使用します。 特に、この手法は身体活動の判定に有効です。 たとえば、アスリートは時計を手に持っていて、どれだけ効率的に動くかを知りたいと思っています。 スイマーの間では、このタスクは特に人気があります。 水泳の種類だけでなく、ストロークの力も決定する必要があります。
プロセッサは弱く、メモリはありません。 そして、時系列のクラスを決定したり、時系列を予測したりするという大きなタスクを解決する代わりに、データが到着するとすぐに同様の方法で近似します。 近似された時系列ではなく、近似パラメーターを使用します。
これが機能する理由です。
これは時系列自体ではなく、ログに記録された値を示します。 このポイントは、特定の瞬間とその1カウント後のシリーズの値です。 サインが楕円のように見えることは明らかです。 幸いなことに、記録された変数の空間におけるこの楕円の次元は常に2になります。この空間で背景をどれだけ長くしても、空間の次元は固定されたままです。 そして、空間の次元は常に特異分解を使用して決定できます。

次に、各時系列をその主要コンポーネントの形で特異展開で表すことができます。 したがって、最初の主要な成分はある種の傾向であり、2番目は主要な高調波など、高調波の増加です。 モデルを近似する際の特徴として、これらのコンポーネントの重みを使用します。

これが特性を生成する最後の方法です。 兆候はメトリックです。 すでに何らかの方法でプランマトリックスを生成しています。たとえば、ユークリッドなどのメトリック空間で列がどのように配置されているかを見てみましょう。
メトリックρを割り当て、オブジェクトの行をクラスター化します–属性行列X。
当然、すべてのサンプルオブジェクトからすべてのサンプルオブジェクトまでの距離の数は、サンプルの2乗の乗数です。 そのため、クラスターの中心を選択し、各行から中心までの距離を測定し、オブジェクト属性マトリックスで符号として取得した距離を使用します。
実際には、これは次のとおりです。 距離を正しく計算するために、まず時系列を調整します。 加速度計の6つのクラスの行がここに示されています。人が歩いて、階段を上って、階段を下って、立って横になります。 最初に何らかの手順で行を整列し、たとえばそのような行を取得することが提案されています。 次に、各行の平均値または重心を計算します。
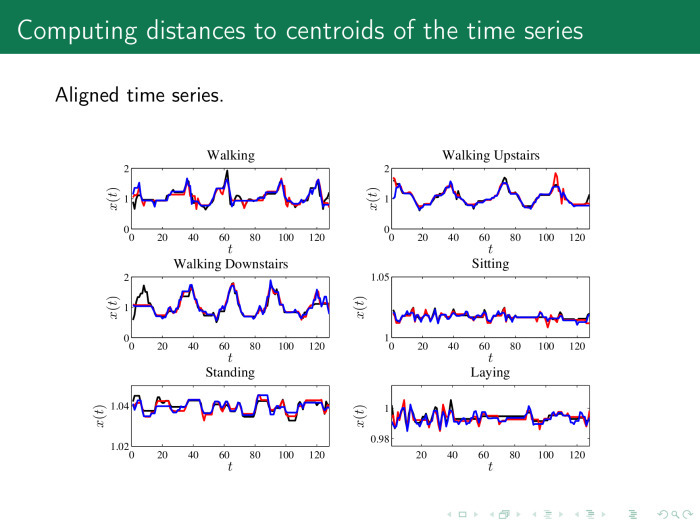
そして、マトリックスXの各時系列からオブジェクト-記号、これらの重心までの距離を計算します。
さまざまな方法でサインを生成した結果、何が起こりましたか? 最初と同じデータを見てみましょう。
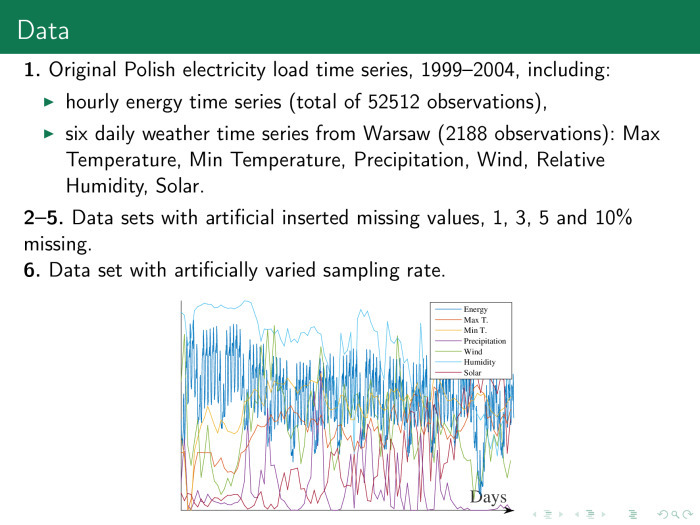
, . , , . . , 3, 5, 10%. , .
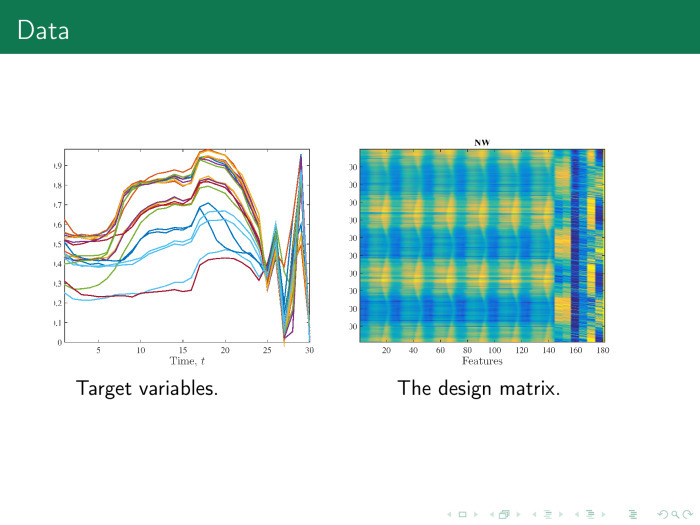
–. , . 24 — . .

? — , , . .
, . . random forest. , . , , : , , random forest .
, . . . . — .
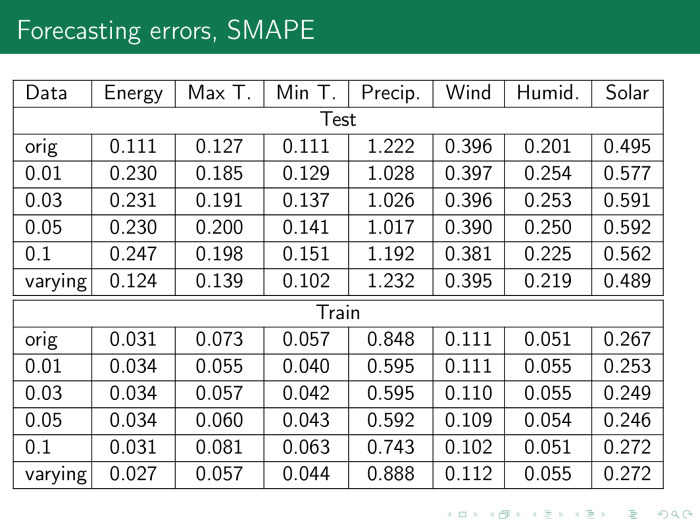
. — , . — .
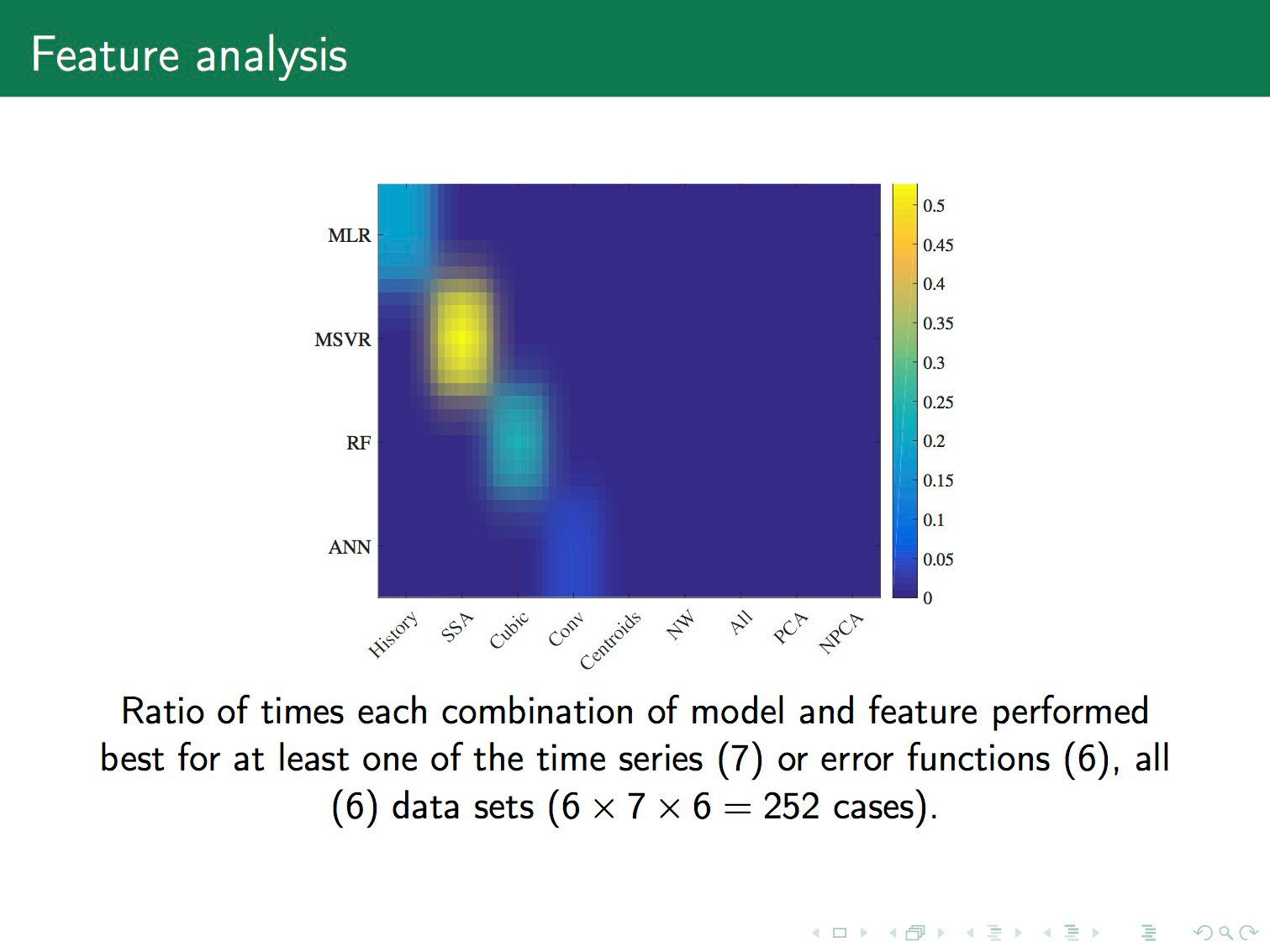
. . , . – , . , — . Support vector machine . random forest . .

. , support vector regression . , . , , , , . — support vector regression . , .
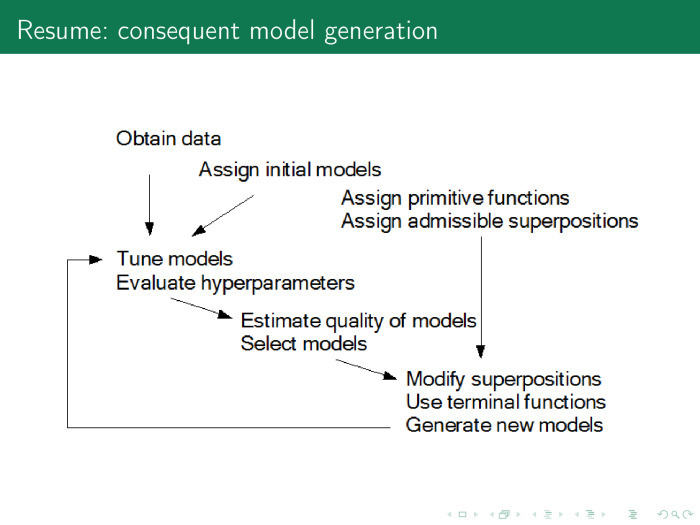
モデルを生成する一般的な手順は何ですか?データがあり、生成関数があり、以前に使用したいくつかの優れたモデルがあります。次のチェーンを実行します:モデルパラメーターとハイパーパラメーターを見つけ、モデルの品質を計算し、いくつかの最適なモデルを選択し、新しい生成関数とその重ね合わせを含め、良好なモデルが得られるまで円を描き続けます。私にはすべてがあります、ありがとう。