ディープラーニングテクノロジーをすばやく理解できるように設計されたシリーズの最初の記事を紹介します。 MNIST(手書き数字の分類)とCIFAR-10(小さな画像の10クラスへの分類:飛行機、車、鳥、猫、鹿、犬、カエル)の適切なパフォーマンスを得るために、基本原則から重要な機能に移行します、馬、船、トラック)。


機械学習技術の集中的な開発により、モデルのプロトタイプを迅速に設計および構築できるだけでなく、学習アルゴリズムのテストに使用されるデータセット(上記のものなど)に無制限にアクセスできるいくつかの非常に便利なフレームワークが登場しました。 ここで使用する開発環境はKerasと呼ばれます。 最も便利で直感的であることがわかりましたが、同時に、必要に応じてモデルを変更するのに十分な表現力を備えています。
このレッスンの終わりに、多層パーセプトロン(MLP)と呼ばれる単純な深層学習モデルがどのように機能するかを理解し、Meristでかなりの精度を得るためにKerasでそれを構築する方法も学びます。 次のレッスンでは、画像を分類する際のより複雑な問題を解決する方法(CIFAR-10など)について説明します。
(人工)ニューロン
「深層学習」という用語はより広い意味で理解できますが、ほとんどの場合、 (人工)ニューラルネットワークの分野で使用されます 。 これらの構造の考え方は生物学から借用されています。ニューラルネットワークは、環境から知覚される画像の脳ニューロンによる処理と、意思決定へのこれらのニューロンの関与を模倣します。 単一の人工ニューロンの動作原理は、本質的に非常に単純です。 入力ベクトルのすべての要素の加重和を計算します 重みベクトルを使用
(同様に、バイアスの追加コンポーネント
)、その後、活性化関数 σを結果に適用できます。
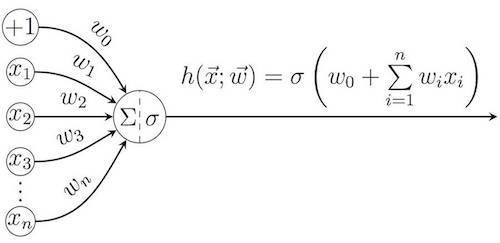
最も人気のあるアクティベーション機能の中で:
- 恒等関数: σ ( z )= z ;
- シグモイド関数、つまりロジスティック関数(ロジスティック):
および双曲線正接(Tanh):
- 半線形関数(整流線形、ReLU)

当初(1950年代から)、パーセプトロンモデルは完全に線形でした。つまり、アイデンティティのみが活性化関数として機能していました。 しかし、主要なタスクは本質的に非線形であることが多く、それが他のアクティベーション関数の出現につながることがすぐに明らかになりました。 シグモイド関数(名前は特性S字グラフに由来) は 、 zがゼロに近い場合のバイナリ解に対するニューロンの初期「不確実性」をモデリングし、 zが任意の方向に変位する場合の高速飽和と組み合わせます。 ここに示す2つの関数は非常に似ていますが、双曲線正接の出力値は区間[-1、1]に属し、ロジスティック関数の範囲は[0、1]です(したがって、ロジスティック関数は確率を表現するのにより便利です)。
近年、深層学習で準線形関数とそのバリエーションが広く普及しています-モデルを非線形にする簡単な方法として登場しました(「値が負の場合、ゼロになります」)が、最終的には歴史的に人気のあるシグモイド関数よりも成功しました。また、生体ニューロンが電気的インパルスを伝達する方法との整合性も向上しています。 このため、このレッスンの一環として、半線形関数(ReLU)に焦点を当てます。
各ニューロンは、その重みベクトルによって一意に決定されます 、および学習アルゴリズムの主な目的は、予測誤差を最小化するために、既知の入力データと出力データのペアのトレーニングサンプルに基づいてニューロンに重みのセットを割り当てることです。 このようなアルゴリズムの典型的な例は勾配降下法で、特定の損失関数に対して
この関数の最大の減少の方向に重みベクトルを変更します。
ここで、 ηは学習率と呼ばれる正のパラメーターです。
損失関数は、パラメーターの現在の値で意思決定を行う際にニューロンがどれほど不正確であるかという考え方を反映しています。 ほとんどのタスクに適した損失関数の最も簡単な選択は、 二次関数です。 特定のトレーニングサンプル これは、 yのターゲット値と特定の入力のニューロンの実際の出力値との差の2乗として定義されます
:
ネットワークには、より詳細な勾配降下アルゴリズムを考慮した多数のトレーニングコースがあります。 私たちのケースでは、フレームワークがすべての最適化を処理するため、今後はあまり注目しません。
ニューラルネットワーク(およびディープラーニング)の概要
ニューロンの概念を導入したので、あるニューロンの出力を別のニューロンの入力に接続することが可能になり、 ニューラルネットワークの基礎を築きます 。 一般に、ニューロンが層を形成し、1つの層のニューロンが前の層の出力を処理する直接伝播ニューラルネットワークに焦点を当てます。 最も強力なこのようなアーキテクチャ( 多層パーセプトロン 、MLP)では、1つの層のすべての出力データが次の図のように次の層のすべてのニューロンに接続されます。
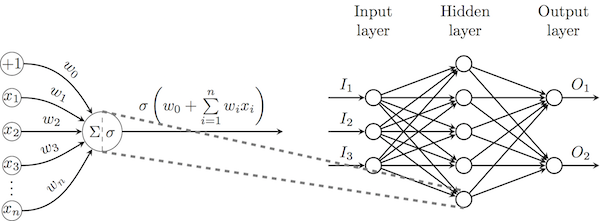
出力ニューロンの重みを変更するには、特定の損失関数を使用した上記の勾配降下法を直接使用できます。他のニューロンの場合、これらの損失を反対方向に(複雑な関数の微分規則を使用して)伝播する必要があり、 逆伝播アルゴリズムを開始します 。 勾配降下法と同様に、すべての計算はフレームワークによって実行されるため、アルゴリズムの数学的正当化には注意を払いません。
普遍近似定理によると、シグモイドニューロンの1つの隠れ層を持つ十分に広い多層パーセプトロンであるTsybenkoは、与えられた間隔で実変数の連続関数を近似できます。 この定理の証明は実用的ではなく、そのような構造に対する効果的なトレーニングアルゴリズムを提供しません。 答えは深層学習を提供します。 幅の代わりに深さを増やします。 定義では、複数の隠れ層を持つニューラルネットワークはすべてディープと見なされます。
深さの移動により、ニューラルネットワークの入力に生の入力を提供することもできます。これまで、単一層ネットワークには、特殊な機能を使用して入力から抽出された重要な機能が提供されていました。 これは、 コンピュータービジョン 、 音声認識、 自然言語処理などのさまざまなクラスのタスクが異なるアプローチを必要とし、これらの分野間の科学的協力を妨げることを意味していました。 しかし、ネットワークに複数の隠れ層が含まれている場合、入力データを最もよく説明する主要な機能を識別する方法を学習する機能を獲得するため、エンドツーエンド学習の使用を見つけることができます(入力と出力の間の従来のプログラム可能な処理なし)また、主要な属性を取得するための関数を導出する必要がなくなったため、 幅広いタスクの同じネットワーク。 畳み込みニューラルネットワークを検討するときに、講義の第2部で上記のグラフィック確認を行います。
Deep MLPをMNISTに適用する
ここで、可能な限り単純なディープニューラルネットワーク(2つの隠れ層を持つMLP)を実装し、MNISTデータセットから手書き数字を認識するタスクに適用します。
次のインポートのみが必要です。
from keras.datasets import mnist # subroutines for fetching the MNIST dataset from keras.models import Model # basic class for specifying and training a neural network from keras.layers import Input, Dense # the two types of neural network layer we will be using from keras.utils import np_utils # utilities for one-hot encoding of ground truth values
次に、モデルのいくつかのパラメーターを定義します。 これらのパラメーターは、トレーニングの開始前に洗練されることが想定されるため、しばしばハイパーパラメーターと呼ばれます。 このマニュアルでは、事前に選択された値を使用しますが、後続のレッスンでそれらの改良のプロセスにさらに注意を払います。
特に、以下を定義します。
batch_size-勾配降下アルゴリズムの1回の反復で同時に処理されるトレーニングサンプルの数。
num_epochs-トレーニングセット全体のトレーニングアルゴリズムの反復回数。
hidden_size -2つの非表示MLPレイヤーのそれぞれのニューロンの数。
batch_size = 128 # in each iteration, we consider 128 training examples at once num_epochs = 20 # we iterate twenty times over the entire training set hidden_size = 512 # there will be 512 neurons in both hidden layers
それでは、MNISTをダウンロードして、いくつかの前処理を行います。 Kerasを使用すると、これは非常に簡単に実行されます。リモートサーバーからNumPyライブラリの配列にデータを直接読み込むだけです。
データを準備するには、最初に画像を1次元配列の形式で提示し(各ピクセルを個別の入力フィーチャと見なすため)、各ピクセルの強度値を255で除算して、新しい値が区間[0、1]に収まるようにします。 これは、データを正規化する非常に簡単な方法です;以降のレッスンで他の方法について説明します。
分類問題への良いアプローチは確率的分類です。この分類では、各クラスに1つの出力ニューロンがあり、入力要素がこのクラスに属する確率を与えます。 これは、トレーニング出力を直接エンコーディングに変換する必要があることを意味します。たとえば、目的の出力クラスが3で、合計5つのクラスがあり(0〜4の番号が付けられている)、適切な直接エンコーディングは[0、0、0、1、0]です。 Kerasがこの機能をすべて提供してくれたことを繰り返します。
num_train = 60000 # there are 60000 training examples in MNIST num_test = 10000 # there are 10000 test examples in MNIST height, width, depth = 28, 28, 1 # MNIST images are 28x28 and greyscale num_classes = 10 # there are 10 classes (1 per digit) (X_train, y_train), (X_test, y_test) = mnist.load_data() # fetch MNIST data X_train = X_train.reshape(num_train, height * width) # Flatten data to 1D X_test = X_test.reshape(num_test, height * width) # Flatten data to 1D X_train = X_train.astype('float32') X_test = X_test.astype('float32') X_train /= 255 # Normalise data to [0, 1] range X_test /= 255 # Normalise data to [0, 1] range Y_train = np_utils.to_categorical(y_train, num_classes) # One-hot encode the labels Y_test = np_utils.to_categorical(y_test, num_classes) # One-hot encode the labels
そして今、私たちのモデルを定義する時が来ました! これを行うには、3つの密なレイヤーのスタックを使用します。これは、完全に接続されたMLPに対応し、1つのレイヤーのすべての出力が後続のレイヤーのすべての入力に接続されます。 最初の2つの層のニューロンにはReLUを、最後の層にはsoftmaxを使用します。 この活性化関数は、実数値を持つベクトルを確率ベクトルに変換するように設計されており、 j番目のニューロンに対して次のように定義されています。
他のフレームワーク(TansorFlowなど)と区別するKerasの注目すべき機能は、レイヤーサイズの自動計算です。 入力レイヤーの次元を指定するだけで、Kerasは他のすべてのレイヤーを自動的に初期化します。 すべてのレイヤーが定義されたら、次のように入力データと出力データを設定するだけです。
inp = Input(shape=(height * width,)) # Our input is a 1D vector of size 784 hidden_1 = Dense(hidden_size, activation='relu')(inp) # First hidden ReLU layer hidden_2 = Dense(hidden_size, activation='relu')(hidden_1) # Second hidden ReLU layer out = Dense(num_classes, activation='softmax')(hidden_2) # Output softmax layer model = Model(input=inp, output=out) # To define a model, just specify its input and output layers
ここで、損失関数、最適化アルゴリズム、および収集するメトリックを決定する必要があります。
確率的分類を扱うときは、損失関数として、上で定義した二乗誤差ではなく、クロスエントロピーを使用するのが最善です。 特定の出力確率ベクトルの場合 実際のベクトルと比較
、損失( k番目のクラス)は次のように定義されます。
主にこの関数はクラスの正しい定義に対するモデルの信頼性を最大化するように設計されており、他のクラスに入るサンプルの確率の分布を気にしないため、損失は確率的なタスクでは減少します(たとえば、出力層のロジスティック/ソフトマックス関数を使用) (二次誤差関数は、残りのクラスに陥る確率ができるだけゼロに近くなるようにする傾向があります)。
使用される最適化アルゴリズムは、何らかの形の勾配降下アルゴリズムに似ています。違いは、 トレーニングレート ηが選択される方法のみです。 これらのアプローチの優れた概要をここで紹介します。次に、通常は良好なパフォーマンスを示すAdamオプティマイザーを使用します。
クラスはバランスが取れているため(各クラスに属する手書き数字の数は同じです)、 精度は適切なメトリック(正しいクラスに割り当てられた入力データの割合)になります。
model.compile(loss='categorical_crossentropy', # using the cross-entropy loss function optimizer='adam', # using the Adam optimiser metrics=['accuracy']) # reporting the accuracy
最後に、トレーニングアルゴリズムを実行します。 データのサブセットを取り除いて、アルゴリズムが(まだ)データを正しく認識していることを確認することをお勧めします。このデータは検証セットとも呼ばれます。 ここでは、この目的のためにデータの10%を分離します。
Kerasのもう1つの優れた機能は、粒度です。アルゴリズムのすべてのステップの詳細なログを表示します。
model.fit(X_train, Y_train, # Train the model using the training set... batch_size=batch_size, nb_epoch=num_epochs, verbose=1, validation_split=0.1) # ...holding out 10% of the data for validation model.evaluate(X_test, Y_test, verbose=1) # Evaluate the trained model on the test set!
Train on 54000 samples, validate on 6000 samples Epoch 1/20 54000/54000 [==============================] - 9s - loss: 0.2295 - acc: 0.9325 - val_loss: 0.1093 - val_acc: 0.9680 Epoch 2/20 54000/54000 [==============================] - 9s - loss: 0.0819 - acc: 0.9746 - val_loss: 0.0922 - val_acc: 0.9708 Epoch 3/20 54000/54000 [==============================] - 11s - loss: 0.0523 - acc: 0.9835 - val_loss: 0.0788 - val_acc: 0.9772 Epoch 4/20 54000/54000 [==============================] - 12s - loss: 0.0371 - acc: 0.9885 - val_loss: 0.0680 - val_acc: 0.9808 Epoch 5/20 54000/54000 [==============================] - 12s - loss: 0.0274 - acc: 0.9909 - val_loss: 0.0772 - val_acc: 0.9787 Epoch 6/20 54000/54000 [==============================] - 12s - loss: 0.0218 - acc: 0.9931 - val_loss: 0.0718 - val_acc: 0.9808 Epoch 7/20 54000/54000 [==============================] - 12s - loss: 0.0204 - acc: 0.9933 - val_loss: 0.0891 - val_acc: 0.9778 Epoch 8/20 54000/54000 [==============================] - 13s - loss: 0.0189 - acc: 0.9936 - val_loss: 0.0829 - val_acc: 0.9795 Epoch 9/20 54000/54000 [==============================] - 14s - loss: 0.0137 - acc: 0.9950 - val_loss: 0.0835 - val_acc: 0.9797 Epoch 10/20 54000/54000 [==============================] - 13s - loss: 0.0108 - acc: 0.9969 - val_loss: 0.0836 - val_acc: 0.9820 Epoch 11/20 54000/54000 [==============================] - 13s - loss: 0.0123 - acc: 0.9960 - val_loss: 0.0866 - val_acc: 0.9798 Epoch 12/20 54000/54000 [==============================] - 13s - loss: 0.0162 - acc: 0.9951 - val_loss: 0.0780 - val_acc: 0.9838 Epoch 13/20 54000/54000 [==============================] - 12s - loss: 0.0093 - acc: 0.9968 - val_loss: 0.1019 - val_acc: 0.9813 Epoch 14/20 54000/54000 [==============================] - 12s - loss: 0.0075 - acc: 0.9976 - val_loss: 0.0923 - val_acc: 0.9818 Epoch 15/20 54000/54000 [==============================] - 12s - loss: 0.0118 - acc: 0.9965 - val_loss: 0.1176 - val_acc: 0.9772 Epoch 16/20 54000/54000 [==============================] - 12s - loss: 0.0119 - acc: 0.9961 - val_loss: 0.0838 - val_acc: 0.9803 Epoch 17/20 54000/54000 [==============================] - 12s - loss: 0.0073 - acc: 0.9976 - val_loss: 0.0808 - val_acc: 0.9837 Epoch 18/20 54000/54000 [==============================] - 13s - loss: 0.0082 - acc: 0.9974 - val_loss: 0.0926 - val_acc: 0.9822 Epoch 19/20 54000/54000 [==============================] - 12s - loss: 0.0070 - acc: 0.9979 - val_loss: 0.0808 - val_acc: 0.9835 Epoch 20/20 54000/54000 [==============================] - 11s - loss: 0.0039 - acc: 0.9987 - val_loss: 0.1010 - val_acc: 0.9822 10000/10000 [==============================] - 1s [0.099321320021623111, 0.9819]
ご覧のように、このモデルはテストデータセットで約98.2%の精度を達成します。これは、 ここで説明する超現代的なアプローチによってはるかに優れているという事実にもかかわらず、このような単純なモデルにとって非常に価値があります 。
このモデルをもう一度実験することをお勧めします。さまざまなハイパーパラメーター、最適化アルゴリズム、アクティベーション関数を試して、隠れ層を追加するなど。 最終的には、99%を超える精度を達成できるはずです。
おわりに
この投稿では、ディープラーニングの基本概念を検証し、Kerasフレームワークを使用して単純な2層のディープMLPを正常に実装し、MNISTデータセットに適用しました。これらすべてを30行未満のコードで実行しました。
次回は、MLPを大容量画像(CIFAR-10など)に適用する際に発生する問題のいくつかを解決する畳み込みニューラルネットワーク(CNN)を見ていきます。