
Pythonでは、物事はもう少し複雑です。2つのパーサーがあります。 最初のパーサーは、正規表現の形式で
Grammar/Grammar
ファイルに指定された
Grammar/Grammar
(通常とは異なる構文)によってガイドされます。 この文法によると、
Parser/pgen
を使用して、
python
コンパイル中に、特定の正規表現を認識する有限状態マシンのセット全体が生成されます(非終端記号ごとに1 KA)。 結果として得られる宇宙船のセットの形式は、
Include/grammar.h
で説明されており、宇宙船自体は、グローバル構造
_PyParser_Grammar
形式で
Python/graminit.c
設定されています。 終端記号は、
Include/token.h
で定義されており、0..56の数字に対応しています。 非端末番号は256から始まります。
最初のパーサーの動作を説明する最も簡単な方法は、例を使用することです。
if 42: print("Hello world")
ます。
ここに、プログラムの分析に対応する文法の一部があります
single_input:NEWLINE | simple_stmt | compound_stmt NEWLINE
compound_stmt:if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | 装飾された| async_stmt
if_stmt: 'if'テスト ':'スイート( 'elif'テスト ':'スイート)* ['else' ':'スイート]
スイート:simple_stmt | NEWLINE INDENT stmt + DEDENT
simple_stmt:small_stmt( ';' small_stmt)* [';'] NEWLINE
small_stmt:expr_stmt | del_stmt | pass_stmt | flow_stmt | import_stmt | global_stmt | nonlocal_stmt | assert_stmt
expr_stmt:testlist_star_expr(annassign | augassign(yield_expr | testlist)|( '='(yield_expr | testlist_star_expr))*)
testlist_star_expr:(テスト| star_expr)( '、'(テスト| star_expr))* ['、']
テスト:or_test ['if' or_test 'else' test] | ラムデフ
or_test:and_test( 'or' and_test)*
and_test:not_test( 'and' not_test)*
not_test: 'not' not_test | 比較
比較:expr(comp_op expr)*
expr:xor_expr( '|' xor_expr)*
xor_expr:and_expr( '^' and_expr)*
and_expr:shift_expr( '&' shift_expr)*
shift_expr:arith_expr(( '<<' | '>>')arith_expr)*
arith_expr:term(( '+' | '-')term)*
term:factor(( '*' | '@' | '/' | '%' | '//')ファクター)*
ファクター:( '+' | '-' | '〜')ファクター| 力
パワー:atom_expr ['**' factor]
atom_expr:[AWAIT]アトムトレーラー*
アトム: '(' [yield_expr | testlist_comp] ')' | '[' [testlist_comp] ']' | '{' [dictorsetmaker] '}' |
NAME | NUMBER | STRING + | '...' | 「なし」| 「真」| 「False」
予告編: '(' [arglist] ')' | '[' subscriptlist ']' | 「。」 NAME
arglist:引数( '、'引数)* ['、']
引数:テスト[comp_for] | テスト '='テスト| '**'テスト| 「*」テスト
そして、これは_PyParser_Grammar構造の興味深い部分がPython / graminit.cでどのように定義されるかです
static arc arcs_0_0[3] = { {2, 1}, {3, 1}, {4, 2}, }; static arc arcs_0_1[1] = { {0, 1}, }; static arc arcs_0_2[1] = { {2, 1}, }; static state states_0[3] = { {3, arcs_0_0}, {1, arcs_0_1}, {1, arcs_0_2}, }; //... static arc arcs_39_0[9] = { {91, 1}, {92, 1}, {93, 1}, {94, 1}, {95, 1}, {19, 1}, {18, 1}, {17, 1}, {96, 1}, }; static arc arcs_39_1[1] = { {0, 1}, }; static state states_39[2] = { {9, arcs_39_0}, {1, arcs_39_1}, }; //... static arc arcs_41_0[1] = { {97, 1}, }; static arc arcs_41_1[1] = { {26, 2}, }; static arc arcs_41_2[1] = { {27, 3}, }; static arc arcs_41_3[1] = { {28, 4}, }; static arc arcs_41_4[3] = { {98, 1}, {99, 5}, {0, 4}, }; static arc arcs_41_5[1] = { {27, 6}, }; static arc arcs_41_6[1] = { {28, 7}, }; static arc arcs_41_7[1] = { {0, 7}, }; static state states_41[8] = { {1, arcs_41_0}, {1, arcs_41_1}, {1, arcs_41_2}, {1, arcs_41_3}, {3, arcs_41_4}, {1, arcs_41_5}, {1, arcs_41_6}, {1, arcs_41_7}, }; //... static dfa dfas[85] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\102"}, //... {270, "simple_stmt", 0, 4, states_14, "\000\040\200\000\002\000\000\000\012\076\011\007\000\000\020\002\000\300\220\050\037\100"}, //... {295, "compound_stmt", 0, 2, states_39, "\000\010\140\000\000\000\000\000\000\000\000\000\262\004\000\000\000\000\000\000\000\002"}, {296, "async_stmt", 0, 3, states_40, "\000\000\040\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"}, {297, "if_stmt", 0, 8, states_41, "\000\000\000\000\000\000\000\000\000\000\000\000\002\000\000\000\000\000\000\000\000\000"}, // ^^^ //... }; static label labels[176] = { {0, "EMPTY"}, {256, 0}, {4, 0}, // №2 {270, 0}, // №3 {295, 0}, // №4 //... {305, 0}, // №26 {11, 0}, // №27 //... {297, 0}, // №91 {298, 0}, {299, 0}, {300, 0}, {301, 0}, {296, 0}, {1, "if"}, // №97 //... }; grammar _PyParser_Grammar = { 86, dfas, {176, labels}, 256 };
(このリストでのパーサーの作業に関する次の説明に従うと便利です。たとえば、次のタブで開きます。)
パーサーは、
single_input
のSCから解析を開始します。 この宇宙船は、3つの状態の
states_0
配列によって定義されます。 入力
NEWLINE
文字(ラベル番号2、シンボル番号4)、
simple_stmt
(ラベル番号3、シンボル番号270)、
compound_stmt
(ラベル番号4、シンボル番号295)に対応して、3つのアーク(
arcs_0_0
)が初期状態から外れます。 入力端子
"if"
(シンボルNo. 1、ラベルNo. 97)は
d_first
セットに含まれていますが、
d_first
は含まれていません-セットの13番目のバイトのビット\ 002に対応しています。 (解析中に、次の端末が複数の発信アークの
d_first
セットに一度に含まれていることが判明した場合、パーサーは、文法があいまいであり、解析の続行を拒否するというメッセージを表示します。)したがって、パーサーはアーク
{4, 2}
d_first
{4, 2}
に沿って状態に進みますNo. 2、同時に、
states_39
配列で指定された
compound_stmt
宇宙船に切り替えます。 この宇宙船では、9つのアークがすぐに初期状態(
arcs_39_0
)を離れます。 その中で、入力シンボル
if_stmt
(No. 297)に対応するアーク
{91, 1}
if_stmt
{91, 1}
を選択します。 パーサーは状態1に切り替わり、
states_41
配列で指定された
states_41
宇宙船に切り替わります。
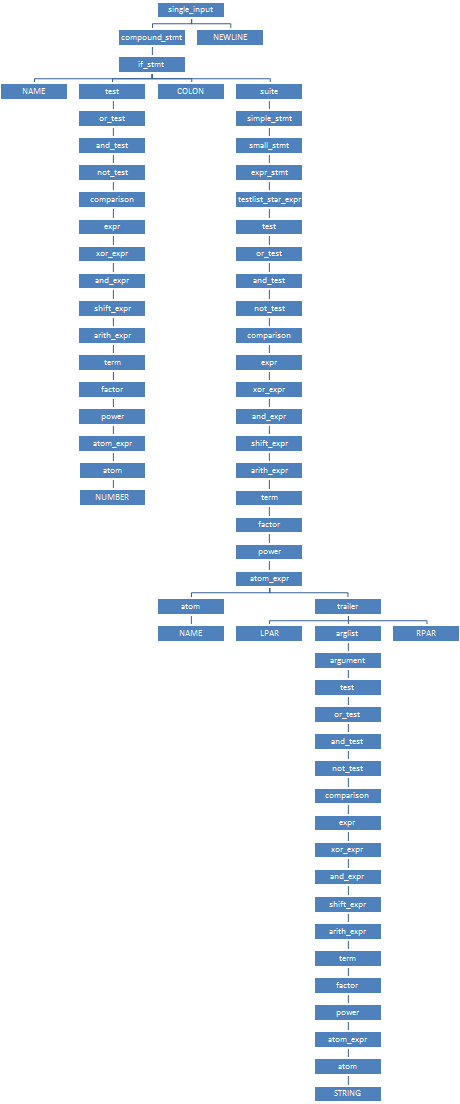
この宇宙船の初期状態からは、入力端子
"if"
対応する1つのアーク
{97, 1} のみが出現します。 その上で、パーサーは状態No. 1に切り替わり、そこから唯一のアーク
{26, 2}
26、2
{26, 2}
が出ます。これは、非終端
test
(No. 305)に対応します。 このアークでは、パーサーは状態2に切り替わり、
test
宇宙船に切り替わります。 番号
42
の
test
非終端記号への長い長い変換の後、パーサーは状態2に戻り、そこから唯一のアーク
{27, 3}
if_stmt
{27, 3}
COLON
し、
COLON
端末(記号番号11)に対応し、
if_stmt
非終端記号の解析を続行します。 分析の結果、パーサーは特定の構文ツリー (
node
構造)のノードを作成します。ノードは、ノードタイプ297、および4
NAME
(タイプNo. 1(
NAME
)、No。305(
test
)、No。11(
COLON
)およびNo. 304(
suite
)。 状態番号4で
if_stmt
のノードの作成
if_stmt
完了すると、パーサーはスペースクラフト
compound_stmt
状態番号1に戻り、
if_stmt
新しく作成されたノードが
if_stmt
対応するノードの唯一の子になります。 プログラムのKSD全体は、右の図のようになります。 7つの端末の短いプログラム
NAME NUMBER COLON NAME LPAR STRING RPAR
がどのように「竹」になったかに注目してください。これは、
NAME NUMBER COLON NAME LPAR STRING RPAR
64ノードの巨大で分岐のない解析ツリーです。 バイト単位でカウントすると、元のプログラムは27バイトを消費し、そのKSDは2桁大きくなります。32ビットシステムでは1.5キロバイト、64ビットシステムでは3キロバイトです。 (それぞれ24または48バイトの64ノード)。 これは、サイズが数十メガバイトの
python
ソースファイルを通過しようとするCSDの無制限のストレッチが原因で、致命的な
MemoryError
です。
PythonでKSDを使用する場合、標準の
parser
モジュールがあります。
$ python Python 3.7.0a0 (default:98c078fca8e0, Oct 31 2016, 08:33:23) [GCC 4.7.3] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import parser >>> parser.suite('if 42: print("Hello world")').tolist() [257, [269, [295, [297, [1, 'if'], [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [2, '42']]]]]]]]]]]]]]]], [11, ':'], [304, [270, [271, [272, [274, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [3, '"Hello world"']]]]]]]]]]]]]]]]]], [8, ')']]]]]]]]]]]]]]]]]]], [4, '']]]]]], [4, ''], [0, '']] >>>
そのソースコード(
Modules/parsermodule.c
)で、CSDがPythonの文法に準拠しているかどうかを確認するために、次のような手書き行が2000行以上ありました。
//... /* simple_stmt | compound_stmt * */ static int validate_stmt(node *tree) { int res = (validate_ntype(tree, stmt) && validate_numnodes(tree, 1, "stmt")); if (res) { tree = CHILD(tree, 0); if (TYPE(tree) == simple_stmt) res = validate_simple_stmt(tree); else res = validate_compound_stmt(tree); } return (res); } static int validate_small_stmt(node *tree) { int nch = NCH(tree); int res = validate_numnodes(tree, 1, "small_stmt"); if (res) { int ntype = TYPE(CHILD(tree, 0)); if ( (ntype == expr_stmt) || (ntype == del_stmt) || (ntype == pass_stmt) || (ntype == flow_stmt) || (ntype == import_stmt) || (ntype == global_stmt) || (ntype == nonlocal_stmt) || (ntype == assert_stmt)) res = validate_node(CHILD(tree, 0)); else { res = 0; err_string("illegal small_stmt child type"); } } else if (nch == 1) { res = 0; PyErr_Format(parser_error, "Unrecognized child node of small_stmt: %d.", TYPE(CHILD(tree, 0))); } return (res); } /* compound_stmt: * if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated */ static int validate_compound_stmt(node *tree) { int res = (validate_ntype(tree, compound_stmt) && validate_numnodes(tree, 1, "compound_stmt")); int ntype; if (!res) return (0); tree = CHILD(tree, 0); ntype = TYPE(tree); if ( (ntype == if_stmt) || (ntype == while_stmt) || (ntype == for_stmt) || (ntype == try_stmt) || (ntype == with_stmt) || (ntype == funcdef) || (ntype == async_stmt) || (ntype == classdef) || (ntype == decorated)) res = validate_node(tree); else { res = 0; PyErr_Format(parser_error, "Illegal compound statement type: %d.", TYPE(tree)); } return (res); } //...
このような均一なコードは、正式な文法を使用して自動的に生成できると推測するのは簡単です。 そのようなコードがすでに自動的に生成されていると推測するのは少し難しいです-これがまさに、最初のパーサーで使用されるマシンの動作です! 上記で、今年の3月に、文法が変更されるたびに編集する必要がある手書きコードのこれらすべてのシートを、使用する同じ自動生成されたすべての宇宙船の実行で置き換えることを提案する方法を説明するために、その構造を詳細に説明しましたパーサー自体。 これは、プログラマがアルゴリズムを知る必要があるかどうかについて話すことです。
6月に私のパッチが受け入れられたため、Python 3.6以降では、上記の
Modules/parsermodule.c
シートはなくなりましたが、数十行のコードがあります。
上記のように、このようなかさばって過剰なKSDを扱うのは非常に不便です。 したがって、完全に手書きで記述された2番目のパーサー(
Python/ast.c
)はKSDをバイパスし、 そこから抽象構文ツリーを作成します 。 SDAの文法は
Parser/Python.asdl
記述されてい
Parser/Python.asdl
。 このプログラムの場合、SDAは右のようになります。
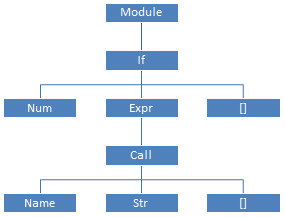
parser
モジュールを使用してKSDを操作する代わりに、ドキュメントでは、
ast
モジュールを使用して抽象ツリーを操作することを
ast
ます。
$ python Python 3.7.0a0 (default:98c078fca8e0, Oct 31 2016, 08:33:23) [GCC 4.7.3] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import ast >>> ast.dump(ast.parse('if 42: print("Hello world")')) "Module(body=[If(test=Num(n=42), body=[Expr(value=Call(func=Name(id='print', ctx=Load()), args=[Str(s='Hello world')], keywords=[]))], orelse=[])])" >>>
ASDが作成されるとすぐに、KSDは不要になり、KSDが占有していたすべてのメモリが解放されます。 したがって、Pythonの「長時間再生」プログラムの場合、KSDがどれだけのメモリを使用するかは実際には関係ありません。 一方、大規模ではあるが「高速
dict
」スクリプト(たとえば、巨大な
dict
リテラルで値を検索する)の場合、RDCのサイズによってスクリプトによるメモリ消費が決まります。 KSDのサイズによって、プログラムをダウンロードして実行するために十分なメモリがあるかどうかが決まるという事実に加えて、このすべて。
長い「竹の枝」に沿って歩く必要があるため、
Python/ast.c
単にうんざりします。
static expr_ty ast_for_expr(struct compiling *c, const node *n) { //... loop: switch (TYPE(n)) { case test: case test_nocond: if (TYPE(CHILD(n, 0)) == lambdef || TYPE(CHILD(n, 0)) == lambdef_nocond) return ast_for_lambdef(c, CHILD(n, 0)); else if (NCH(n) > 1) return ast_for_ifexpr(c, n); /* Fallthrough */ case or_test: case and_test: if (NCH(n) == 1) { n = CHILD(n, 0); goto loop; } // case not_test: if (NCH(n) == 1) { n = CHILD(n, 0); goto loop; } // not_test case comparison: if (NCH(n) == 1) { n = CHILD(n, 0); goto loop; } // comparison case star_expr: return ast_for_starred(c, n); /* The next five cases all handle BinOps. The main body of code is the same in each case, but the switch turned inside out to reuse the code for each type of operator. */ case expr: case xor_expr: case and_expr: case shift_expr: case arith_expr: case term: if (NCH(n) == 1) { n = CHILD(n, 0); goto loop; } return ast_for_binop(c, n); // case yield_expr: case factor: if (NCH(n) == 1) { n = CHILD(n, 0); goto loop; } return ast_for_factor(c, n); case power: return ast_for_power(c, n); default: PyErr_Format(PyExc_SystemError, "unhandled expr: %d", TYPE(n)); return NULL; } /* should never get here unless if error is set */ return NULL; }
if (NCH(n) == 1) n = CHILD(n, 0);
2番目のパーサー全体で繰り返し繰り返され
if (NCH(n) == 1) n = CHILD(n, 0);
-時々、この関数のように、サイクル内で-「現在のKSDノードに子が1つしかない場合、現在のノードの代わりにその子を考慮する必要がある」ことを意味します。
しかし、KSDの作成中に「1子」ノードを削除し、その子をそれらの代わりに使用することをすぐに防ぐことはできますか? 結局のところ、これにより多くのメモリが節約され、2番目のパーサーが簡素化され、
goto loop;
複数の繰り返しを取り除くことができます
goto loop;
コード全体で、 ダイクストラが彼のtopでトップを回すという観点から!
3月に、前述の
Modules/parsermodule.c
パッチとともに、 別のパッチを提案しました。
- 非分岐サブツリーの自動「圧縮」を最初のパーサーに追加します- 折りたたみ (KSDノードを作成し、現在の宇宙船から前の宇宙船に戻る)時に、適切なタイプの「1つの子」ノードがその子に置き換えられます:
diff -r ffc915a55a72 Parser/parser.c --- a/Parser/parser.c Mon Sep 05 00:01:47 2016 -0400 +++ b/Parser/parser.c Mon Sep 05 08:30:19 2016 +0100 @@ -52,16 +52,16 @@ #ifdef Py_DEBUG static void s_pop(stack *s) { if (s_empty(s)) Py_FatalError("s_pop: parser stack underflow -- FATAL"); - s->s_top++; + PyNode_Compress(s->s_top++->s_parent); } #else /* !Py_DEBUG */ -#define s_pop(s) (s)->s_top++ +#define s_pop(s) PyNode_Compress((s)->s_top++->s_parent) #endif diff -r ffc915a55a72 Python/ast.c --- a/Python/ast.c Mon Sep 05 00:01:47 2016 -0400 +++ b/Python/ast.c Mon Sep 05 08:30:19 2016 +0100 @@ -5070,3 +5056,24 @@ FstringParser_Dealloc(&state); return NULL; } + +void PyNode_Compress(node* n) { + if (NCH(n) == 1) { + node* ch; + switch (TYPE(n)) { + case suite: case comp_op: case subscript: case atom_expr: + case power: case factor: case expr: case xor_expr: + case and_expr: case shift_expr: case arith_expr: case term: + case comparison: case testlist_star_expr: case testlist: + case test: case test_nocond: case or_test: case and_test: + case not_test: case stmt: case dotted_as_name: + if (STR(n) != NULL) + PyObject_FREE(STR(n)); + ch = CHILD(n, 0); + *n = *ch; + // All grandchildren are now adopted; don't need to free them, + // so no need for PyNode_Free + PyObject_FREE(ch); + } + } +}
- 「bambooブランチ」をバイパスすることを除いて、2番目のパーサーを正しく修正します。たとえば、上記の関数
ast_for_expr
は次のように置き換えられます。
static expr_ty ast_for_expr(struct compiling *c, const node *n) { //... switch (TYPE(n)) { case lambdef: case lambdef_nocond: return ast_for_lambdef(c, n); case test: case test_nocond: assert(NCH(n) > 1); return ast_for_ifexpr(c, n); case or_test: case and_test: assert(NCH(n) > 1); // case not_test: assert(NCH(n) > 1); // not_test case comparison: assert(NCH(n) > 1); // comparison case star_expr: return ast_for_starred(c, n); /* The next five cases all handle BinOps. The main body of code is the same in each case, but the switch turned inside out to reuse the code for each type of operator. */ case expr: case xor_expr: case and_expr: case shift_expr: case arith_expr: case term: assert(NCH(n) > 1); return ast_for_binop(c, n); // case yield_expr: case factor: assert(NCH(n) > 1); return ast_for_factor(c, n); case power: return ast_for_power(c, n); case atom: return ast_for_atom(c, n); case atom_expr: return ast_for_atom_expr(c, n); default: PyErr_Format(PyExc_SystemError, "unhandled expr: %d", TYPE(n)); return NULL; } /* should never get here unless if error is set */ return NULL; }
一方、多くのノードでは、「ブランチ圧縮」の結果として、子は新しいタイプになる可能性があるため、コードの多くの場所で新しい条件を追加する必要があります。
- 「
Modules/parsermodule.c
されたKSD」はPythonの文法に対応していないため、「raw」_PyParser_Grammar
代わりにModules/parsermodule.c
その正確性を確認するために、たとえば、プロダクションのペアの「推移的閉包」に対応するオートマトンを使用する必要があり_PyParser_Grammar
-次の「推移的な」製品が追加されました。or_test :: = and_test テスト:: = or_test 'if' or_test 'else'テスト
test :: = or_test 'if' and_test 'else' test テスト:: = and_test 'if' or_test 'else'テスト テスト:: = and_test 'if' and_test 'else' test
parser
モジュールの初期化中、Init_ValidationGrammar
関数はInit_ValidationGrammar
で_PyParser_Grammar
生成された宇宙船をバイパスし、それらに基づいて「推移的に閉じた」宇宙船を作成し、ValidationGrammar
構造に保存します。ValidationGrammar
、KSDの正確性を検証するために使用されます。
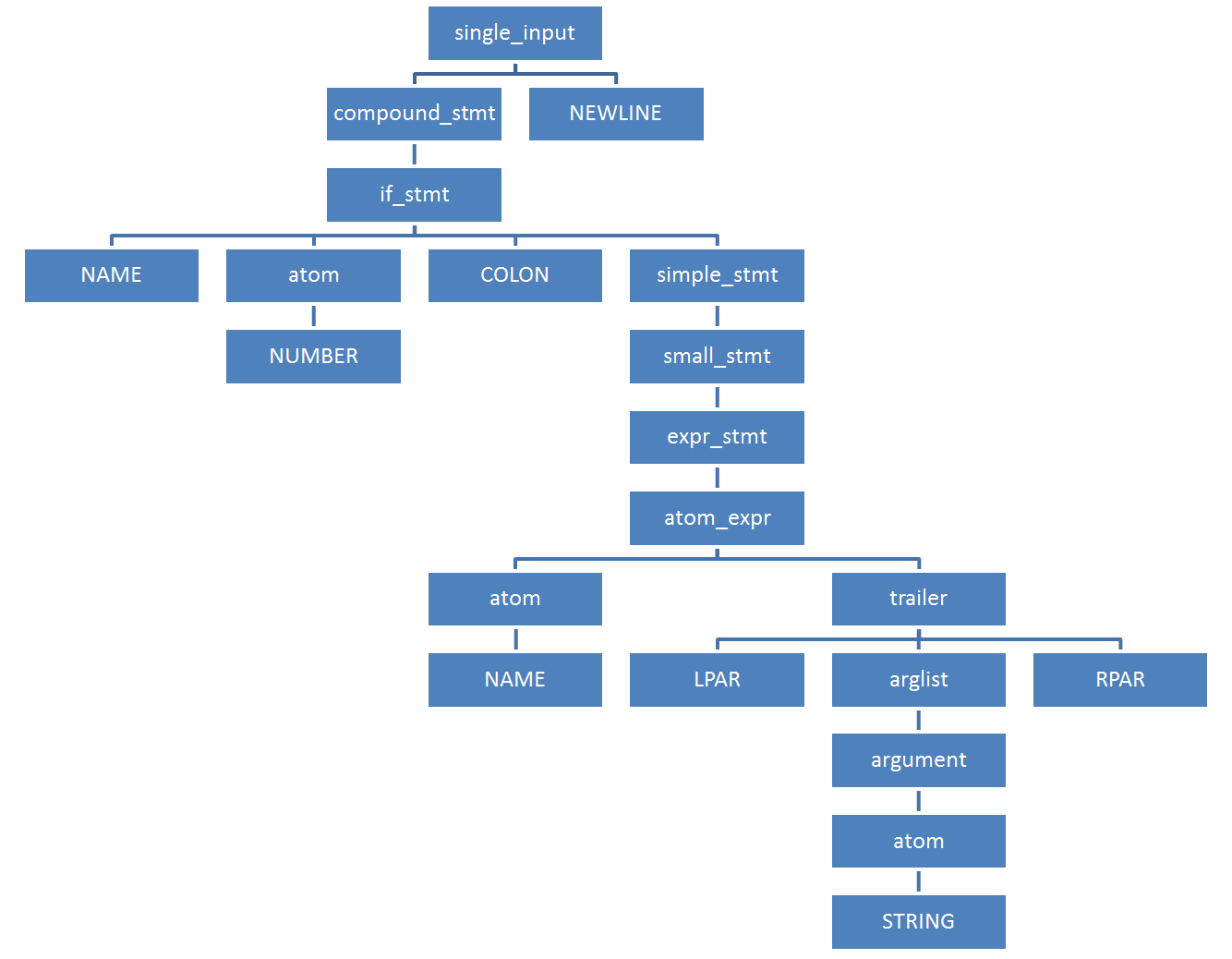
サンプルコードの圧縮されたKSDには、合計21個のノードが含まれています。
$ python Python 3.7.0a0 (default:98c078fca8e0+, Oct 31 2016, 09:00:27) [GCC 4.7.3] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import parser >>> parser.suite('if 42: print("Hello world")').tolist() [257, [295, [297, [1, 'if'], [324, [2, '42']], [11, ':'], [270, [271, [272, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [324, [3, '"Hello world"']]]], [8, ')']]]]], [4, '']]]], [4, ''], [0, '']] >>>
私のパッチでは、ベンチマークの標準セットは 、
python
プロセスによるメモリ消費量が最大30%削減され、動作時間は変わらないことを示しています。 縮退した例では、メモリ消費の削減は3倍に達します!
しかし、残念ながら、パッチを提案してから半年間、メンテナは誰もそれを改訂しようとはしませんでした-とても大きくて怖いです。 9月、 Guido van Rossum自身が私に答えました 。 「以来、このパッチには誰も関心を示していません。つまり、パーサーは他の人のメモリ消費を気にしません。 そのため、メンテナーのレビューに時間を浪費しても意味がありません。」
この記事で、私の大きくて恐ろしいパッチが実際に必要で便利な理由を説明してくれることを期待しています。 この説明の後、Pythonコミュニティがそれを手に入れることを願っています。