
コンスタンチン・オシポフ( kostja )、アレクセイ・リバク ( fisher )
Konstantin Osipov:このレポートは、次の会話から生まれました。 私はいつものように、アレクセイにもっとタランツールを使うよう説得しようとしましたが、彼はまだそこにシャーディングはなく、一般的には面白くないと言いました。 それから私たちはなぜそうでないかについて話し始めました。 普遍的な解決策はありません。自動化があなたのために完全に機能し、職場でコーヒーを飲むだけで、それがすべてです...
したがって、このレポートは生まれました。シャーディングが発生する状況、どのシステムでどの方法が使用されるのか、利点と欠点は何か、なぜ特効薬を解決できないのでしょうか。
シャーディングを問題として話す場合、一般的に言えば、そのような問題はありません。 分散システムの問題があります。 水平方向に拡張する大規模なデータベースがあり、多くのタスクがあります。それらをリストしました。

まず、ノードが多いほど、障害の問題が深刻になります。 1000台のコンピューターから1台ずつ、平均して1日またはそれ以上の頻度で故障することを想像してください。 したがって、データを失わないように、データの冗長性のタスクに直面しています。 そして、これはシャーディングではありません。 むしろ複製です。
分散システムで最も難しい問題は、メンバーシップの問題です。 マシンに障害が発生し、エラーが発生し、分散システムの永続的なメンバーシップが変更されるため、誰が侵入したか、誰が侵入しないか。 これについても話しません。
複雑なクエリの分散実行のタスクがあります。 MapReduceまたは分散SQL。 これもそうではありません。
それで、私たちは何について話すつもりですか?
1つのトピック、つまり、1台のマシンに収まらない一定量のデータを水平クラスター全体に水平に分散する方法と、それをすべて後で管理する方法のトピックを取り上げます。
Alexey Rybak:追加します。 この用語はすでに確立されていますが、それでも、シャーディングとは何ですか? 突然、誰かが知りません。 シャーディングは、原則として、水平方向のデータ分離の方法です。 ほとんどの場合、シャーディングは分散データベースだけでなく、一般に分散ストレージについても語られます。 主にデータベースに焦点を当てます。

Konstantin Osipov:レポートでは、シャーディング自体を構成する3つの要素を取り上げました。
- シャーディング関数の選択
- データの場所(見つけ方)、
- データを再配布する方法。
このレポートは理論的なものではなく、私たちが知っているプロジェクトでどのように機能するか、つまり 人生の物語があります。
Alexei Rybak:何が行われたのか、それにもかかわらず、レポートの基礎は方法論的であるかについて、あらゆる種類の物語を語るという事実にもかかわらず。 すべてが通常どのように行われるかを想像し(何らかの方法ですべてがいくつかの方法でのみ行われる)、用語が決着するようにし、次回、いくつかのトピックを掘り下げる場合、同じ言語を話します。
Konstantin Osipov:この製品を使用するように説得するタスクはありませんが、このレポートの助けを借りて、この製品が「内部」でどのように機能し、開発者が選択したソリューションの長所と短所を理解できるかもしれませんこの製品の。
どのように動作するかを理解することによってのみ、システムを制御できます。
実際、表面のシャーディングとは何ですか? これは方法の選択です。 この選択肢を次のように指定します。

特定のキーがあり、シャードを定義する必要があります。 シャードは通常、それが配置されているコンピューターのIPアドレスまたはDNSアドレスです。
実際には、一般的なケースではキーとサーバーの数の関数、つまり 私たちが持っているマシンの数、または一般的には多くのサーバーから。 また、サーバーの数が異なると動作が異なるため、適切なサーバーを作成する必要があります。
しかし、これについて話す前に、もっと楽しいこと、つまり、このパーティションを実行するための適切なキーを選択することについて話したいと思います。 ここでのストーリーは、一般にこれです:データを1回断片化するキーを選択し、それを一生、まあ、または長期間(数年)使用して、このビジネスのすべての長所と短所を取得します。
そしてその後、何かができなくなったとき(データが特定の方法で既に配布されているため、システムが既に機能しているため、ダウンタイムは不可能です)、どんな問題がありますか?
1つのストーリー-2001年、SpyLOGの若さから-シャーディングはそこにいるユーザーに基づいていました。 SpyLOGとは何ですか? 今ではOpenstatです。 訪問の統計、つまり これはそのようなトラッカー、カウンター、ページ上の小さなボタンです。
一般に、大規模および小規模のすべてのサイトは、その時点で40台のマシンに分散されていました。 そして、それに応じて、大きなサイトは小さなサイトと一緒に住んでいました。 シャーディングキーはサイトIDでした(たとえば、anecdote.ru、rambler.ru、Yandex.ruなど)。
1つのシャーディングキーによって生成された1つのトラフィックが複数のマシンで受け入れられるため、大規模なサイトが実際にマシンをスタックしていました。
したがって、データを分割する対象を選択するときは、システムを配置しないように十分に小さいオブジェクトを選択する必要があります。
Facebookの場合、ジャスティンビーバーのページがあり、ユーザーもデータを分割することにしたとします。 当然、Justin Bieberには、100万人のフォロワー、ライカー、各メッセージの再投稿などがあります。 したがって、おそらく、ジャスティンビーバーを破片の相手として選択するのは最良のアイデアではありません。
シャーディングが正規化に関するものではないことをシャーディングするときに留意すべき2番目のポイント、つまり データを見て、それをマシンにどのように配布するかを決定する標準的な方法があると思う場合、そうではありません。 つまり、データではなく、ユースケース、アプリケーション、ビジネスを見て、ビジネスのどのユースケースが最も重要であり、最も生産性が高いかを考える必要があります。 シャーディングには常にトレードオフがあるためです。 いくつかのクエリは迅速に、即座に機能し、一部のクエリはクラスター全体で実行する必要があります。 そして、どのキーでシャードを選択するかがこれを決定します。
Alexey Rybak: Justin Bieberについて。 実際、ほとんどのソーシャルネットワークでは、シャーディングキーとしてユーザーを選択するのが良い選択だと思います。 ただし、すべての投稿、コメントなどを同じシャードにパックする場合は、ある時点でデータの分散が非常に異なることになり、おそらく使用する必要があることに注意してくださいプロジェクトには2種類のシャーディングがあります。1つはユーザーによるオリジナルで、もう1つはコメントなどによる追加です。
これは当然、データが(一定の確率で)矛盾するという事実につながり、1つの要求ではなく2つの要求を行う必要があります。 これは恐ろしいことではありません。同時に、何らかの形で成長する機会が得られるからです。
そして、すべてを1つのシャードに詰めると、すべてが非常に不均衡になり、ユーザーのソフトウェアとサービスの品質が非常に低くなる可能性があります。 したがって、プログラミングをより複雑にすることは怖くありませんが、すべてが十分に高速になります。 つまり、これは非常に合理的なトレードオフです。
コンスタンティン・オシポフ:もう一つお話ししたい点があります。 シャーディングキーが常に保存されるわけではありません。 たとえば、セッションをmail.ruに保存します。 ID mail.ruがあるとします。kostea.mail.ruまたはそのようなものがあります。 セッションは、ログインしたデバイスを識別するオブジェクトです。 したがって、1つのログインには多くのセッションがあります。 Mail.ruは、1人のシャードに1人のユーザーのすべてのセッションを保存します。 シャーディングキーはログインです。 しかし、セッション自体、つまり オブジェクト識別子-主キー-これはシャーディングキーではありません。 つまり、オブジェクトの識別子がシャーディングキーであるとは限りません。 すべてが1つのシャードに保存されるため、これは便利です。 たとえば、パスワードがハッキングされた疑いがある場合など、1人のユーザーをどこでも切断できます。 これは簡単に管理できます。
良い断片鍵と悪い断片鍵の例を次に示します。

Alexey Rybak:この例に何度も戻ってくるので、続けます。
シャーディングに直面している場合、おそらく私たちのレポートを聞いていなかったときに起こりました。 インターネットで検索しようとしたところ、特別なものは見つかりませんでした。 過去、おそらく10年にわたって、多くのチームが自転車を発明するための同じ方法を行ってきました。 したがって、シャーディングを整理するパターンまたは方法の検討を、最も一般的で最悪の方法ではないものから始めます。
最初の2つとして、次を選択できます。
原則として、それはすべて単一のサーバーから始まり、システム管理を含む「システム管理者ヨーグルト」のためのそのような完全に簡単な方法があります。 「ヨーグルト」-それは軽くて健康的だからです。
この方法に移る前に、1つまたは2つのサーバーで開始するという事実にもかかわらず、大規模なシステムを作成する場合、成長する際の最も重要なことはサポートのコストです-比較的言えば、操作上の問題の数このすべての経済が発生します。 したがって、システム管理者の利便性は、このようなシステムを設計するときにおそらく最初に来る値です。
そのため、1台のサーバーがあり、レプリカを作成し、その上にデータをレプリケートしました。しばらくしてから、記録などによって負荷を分散し、次に何をすべきかを考えます。 そして、さらに2台のサーバーを購入します。各サーバーには独自のレプリカがあります。 なぜレプリカなのか? システム管理の観点から見ると、非常に簡単です-レプリカを設定してからしばらくの間禁止エントリがあったので、この図に示すように、アメーバのように共有するだけです。
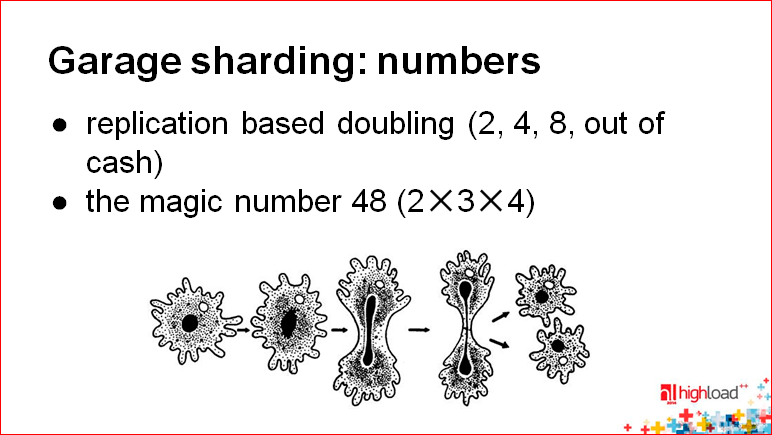
問題は、常に倍増する必要があり、非常に高価になることです。 したがって、他の何かを使用する必要があります。
マジックナンバーに基づいたいくつかの組み合わせがあります。 ここに48を書いたが、実際これは単なるアイデアの一例に過ぎない。 なぜ48番が便利なのですか? 12、6、4、3に分割されます。同じサーバー上に48の回路または48のテーブルを保持し、最初はそのような数でカットするという事実から始めることができます。 次に、システム管理者の簡単な操作、ダンプ、データの一部を他のサーバーに転送できます。 もちろんこの場合、どこかで調整ロジックを用意する必要があります。調整ロジックについては後で説明します。 この方法-分割しやすい特別な数字を使用すると、たとえば最大48〜50台のサーバーなど、非常に簡単に成長できます。
Konstantin Osipov:一般的に、シャーディングについて考えるとき、まず対象領域、つまり 保存したデータの種類。
大量のデータは存在できません。 たとえ地球上のすべての人々について話しても、たった70億から80億です。 これはそれほどではありません。 いくつかのavitoのすべての広告について話している場合、これらも数百万ですが、これらは並外れた価値ではありません。 つまり 天井があります。 どのシステムも成長しますが、成長するにつれて成長は遅くなります。 したがって、可能な限りすべてをスケーリングするために、最も複雑な決定を下す必要は必ずしもありません。 最大10台のサーバーがあることがわかっている場合は、おそらく簡単なソリューションが必要です。
また、シャーディング式の選択(スライド上では、この式-半分に分割するだけです)は常にリシャーディングに関連していることに注意してください。
Alexey Rybak:キー間でデータをどのように分配しますか? サーバー間でいくつかのスキームを転送するという話をしていました。 その後、疑問が生じます。一般に、どのようにデータを分散させるのでしょうか? サーバー上に散在する重要なデータを選択しました。 最大の方法は2つあります。
最初の方法は、ハッシュのようなものです。 一貫している必要はありません。つまり、大まかに言って、新しいサーバーを追加すると、非常にシャッフルできる多くのキーがあります(これは、次に説明するポイントです)。 とにかく、何をしているの? これが数字キーの場合、サーバーの数で単純に除算し、除算の残りを取得できます-これがサーバー番号になります。 これが文字列キー(電子メールなど)の場合、数値ハッシュを取得して同じことを実行できます。
ログインの最初の文字を選択するなど、より多くの「ガレージ」方法がありますが、文字でログインの分布を決定しないため、最初に言語での文字の分布を考慮する必要がありますが、これも非常に困難です。 さらに、1つのサーバーに1つの文字を配置し、1つのサーバーに1つの文字が収まらない場合、この文字を後で分散させるために構成を大きく変更する必要があります。 非常に悪い考えです。 アンチパターンだと思います。
私たちは、ハッシュに関する場所がある問題を1つだけ概説します。 これは、新しいサーバーの追加です。 サポートの観点からリシャーディングを行うとどうなりますか? ノードが飛び出します。この部分のレプリカからマスターノードを選択し、できるだけ早く実行する必要があります。 第二に、負荷が増加したため、新しいサーバーを購入して、できるだけ早く運用する必要があります。 したがって、リシャーディングは重要な問題です。
残りの部門だけを使用すると、より多くのサーバーが表示され、すべてのハッシュが「再スミア」され、すべてのキー、すべてのデータを移動する必要があります。 これは非常に難しく、悪い操作です。 すべてを念頭に置いて機能します。
たとえば、Badooにmemcachedクラスターがあります。 残りの部門ですべてを配布し、新しいサーバーを追加し(これはそれほど頻繁には発生しません)、5〜10分後にすべてのデータが再ソートされました。 ネットワークを介してデータを移動し、別のマシンのメモリに保存することはゴミであるため、これはすべて問題なく迅速に行われます。
ユーザーデータがディスク上にある場合(たとえば、何らかの通信など)、これははるかに複雑なものです。
Konstantin Osipov: 「成人向け」のシャーディングがあります。 そして、これはレポートの2番目の部分です。

これは何ですか 遅かれ早かれ、一般的にクラウドがあり、データベースを回復力のあるスケールにしたいという考えがあります。 シャーディングスキームは、これらすべての詳細を考慮する必要がないようなものでなければなりません。 これは非常に魅力的です。
これが可能かどうかを確認します。 どのように機能するかを分析し、独自の結論を導き出します。
Alexey Rybak: 2つの非常に基本的なポイント、2つの方法があります。 そのうちの1つ、表関数を検討します。
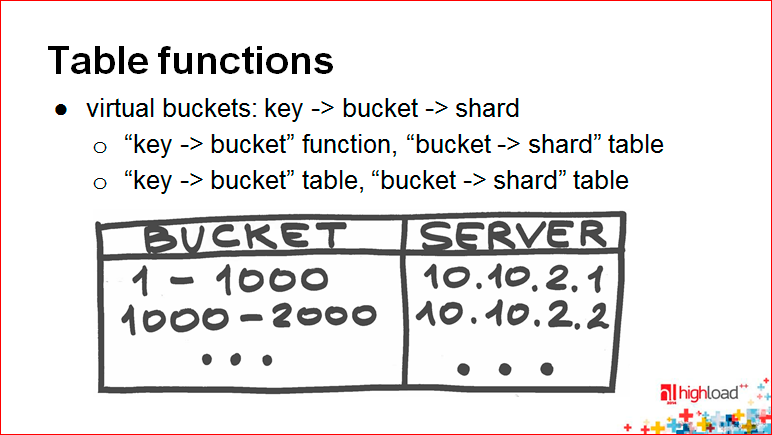
これは単なる表関数です。
このレポートの重要なタスクの1つは、特に条件に同意することです。 たとえば、これを示すために他の単語を使用していました。 メソッドを決定論的な方法に分割しました。 特定の数式があり、非決定的である場合、このキーまたはそのキーがマップされる場所を自由に構成できる場合。
概して、これは表関数であり、一貫したハッシュです。
表関数-これは、ある種の構成を持っているときです。 シャーディングに対するテーブル関数アプローチの使用は、仮想バケットなどの概念と非常に密接に結びついています。
キーをシャードにマップする機能があることを忘れないでください。 真ん中にある種の中間ディスプレイ、つまり このマッピングは2つになります。 まず、キーを仮想バケットにマッピングし、次に仮想バケットをクラスターの空間内の対応する座標にマッピングします。
これをすべて行う方法は多くありません。 また、最も重要なことは、システム管理者に自由と利便性を与えることであることも覚えています。
原則として、仮想バケットは十分に多く選択されます。 なぜ仮想的なのですか? 実際には、実際の物理サーバーを反映していないためです。 また、いくつかの方法を使用して、キーをシャードに直接マップします。
1つの方法は、「キーからバケットへ」関数の最初の部分が、ある種のハッシュまたは一貫したハッシュである場合です。 数式によって決定される一部と、シャードに直接移動するバケットがconfigを通じて表示されます。
2番目はもっと複雑です-configで両方を表示するとき。 比較的言えば、各キーについて、それがどこにあるかを覚えておく必要があるためです。 任意のキーをどこにでも移動できるようになりますが、一方で、「バケツから破片」に小さな設定があり、キーからバケツを決定し、適切な場所に移動するのに十分な速さで、チャンスを簡単かつ迅速に失います。
Konstantin Osipov:なぜこれらのオプションが一般的に発生するのですか? 次に、ルーティングとリシャーディングについて説明します。 ここのすべては、原則として、美しく、便利で、完全に制御可能ですが、特定の条件があります。 この状態をどこかに保存する必要があり、変更する必要があります。 サーバーの数が増えたため、テーブルを変更する必要があります。 2つのアプローチがあります。1つ目-状態があるという事実を確認し、この状態を管理しようとします。 2番目のアプローチ-数式を可能な限り数学化して、状態を特定せずに可能な限り多くの経路を決定します。
シャーディングスキームを何らかの形で機能的に説明できる1つのアプローチを次に示します。 これは一貫したハッシュアプローチです。
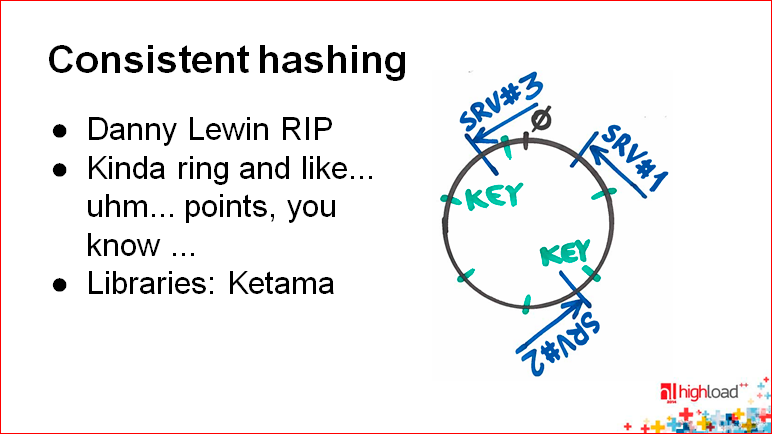
まず、その仕組みを説明します。 ハッシュ関数の全範囲が0〜2 32 (約40億)の直線ではなく、リング上に表示されると想像します。 つまり およそ0の場所に40億があります。
ハッシュ関数を使用するだけの場合、新しいノードを追加するときにこれをすべて再ハッシュする必要があります。 ノードの数で割った残りを使用することがわかります。
そして、ここでは、ノード数による除算の残りを使用しません。 これを行います-ハッシュ関数(おそらく別の関数)があり、それをサーバー識別子に適用し、サーバーをこのリングに配置します。 したがって、各サーバーはリング上で特定の範囲のキーを担当していることがわかります。 したがって、新しいサーバーを追加すると、その前後の範囲、つまり 彼は範囲を部分的に分割します。 シャッフルはまったく必要ありません。
Alexei Rybak:ずっと前にこれを初めて聞いたとき、私はまだ何も理解していませんでした。 何も理解していなくても怖くない。
ここでの考え方は次のとおりです。一貫したハッシュでは、新しいノードを追加するときに、キーのごく一部のみをシャッフルします。 そしてそれだけです。
これがどのように行われるか、関連するキーワードを見ることができます。
Konstantin Osipov:このハッシングストーリーの欠点についてもう少し説明します。 結局のところ、これはいくつかのランダム変数についてです。 ハッシュ関数は一種のランダマイザーであり、自然な意味を持ち、これに応じてランダムな値を提供します。 すべてが誤ってリングのどこかに落ちます。 そして、単純な場合、これは理想的な分布を提供しません。 サーバー3がサーバー1の隣にあり、サーバー2とサーバー3の間でこのような大きなハーフリングがデータのほぼ半分になっていることがあります(写真を参照)。
一貫したハッシュが正しく機能するためには、仮想バケット、マッピングテーブルの形でいくつかの状態を追加する必要があります。 また、仮想バケットはどこかに保存する必要があります。 仮想バケットとサーバー間のマッピング。 つまり あなたには条件があります。 これは純粋な数学ではありません。
キーワードGuava / Sumburを使用した別の興味深いスライドがあります。
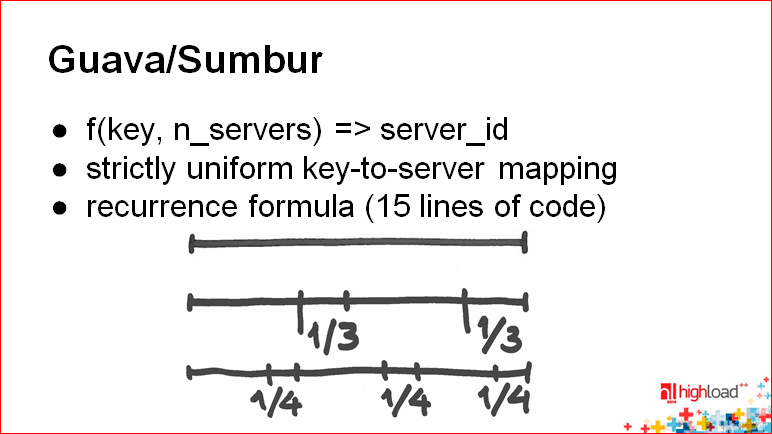
グアバの考え方は、一般的にあなたの状態が消えることです。 基本的に、これはキーとサーバーの数を取得し、server_idを提供する関数です。 , , - — — server_id.
. , — , , , .
— , . , , .. , . , , .
, , — , , , .. , .
: , , .
, .

, — :
- « »;
- ;
«».
« » — .
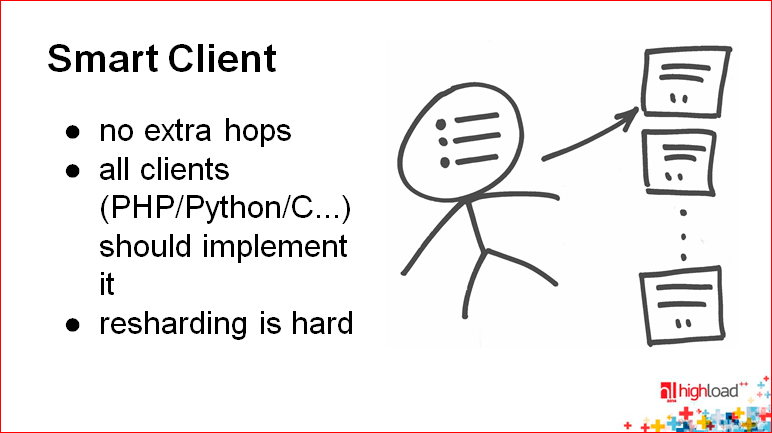
, , bucket. - , - . config, , , 1000 , 1000 , 1000 -. , - . , , , .
, , . — , , - - , , , — -. -, - , maintenance subwindow, , — , . - , - , - .. , , .
— .
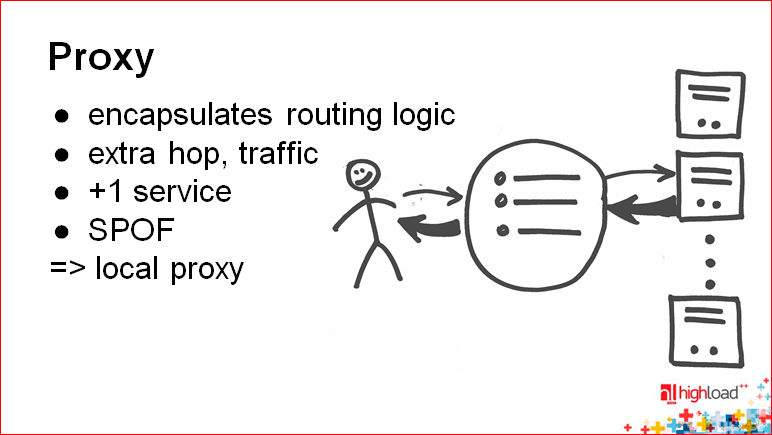
— .
: , ? , - , : «, ! ».
: , highload- ( ), , « — , , . , . , API, , , - … ».
, . , , : «, , ».
, , . .
, : , , , , , .
- , , , , , . , , , , , - , , .
, . , , . — , , . — .
, — .
: . . , . , ? load balancing-, , , .. , failover . つまり .
, , .
— , .. , . , — — .
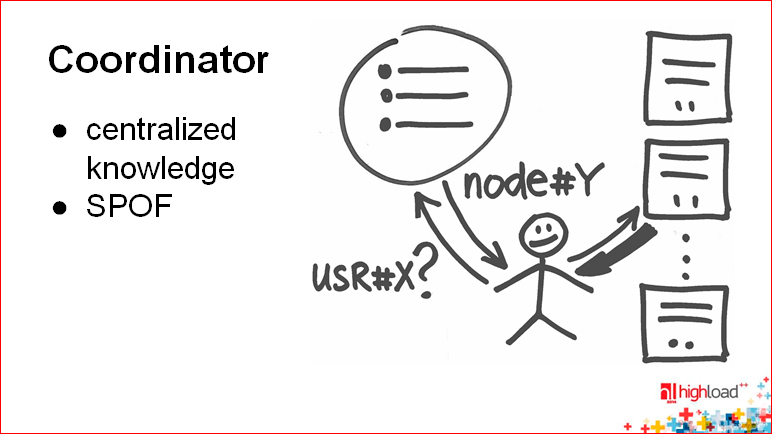
: — , (.. , - , ), . — , « ?». , .. , , -. , .
« ». - , . . - in-memory .
— , — , , .
. , . , — -, -.
: , , - , , , .. .
: , ( ) , , . .
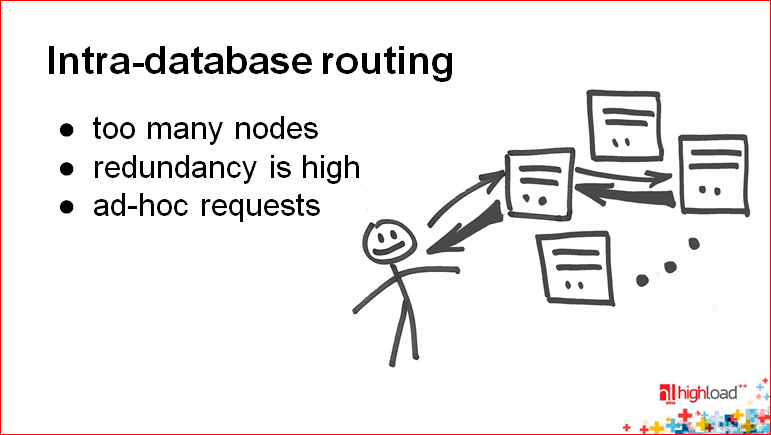
: . , , , , . — . つまり , . , . , .
— - , , , . つまり , , , . , , . , , . , .
, 100 , .
, , Redis. , .
, , , , .. . .
.

? , . , . .
: , . - , . , , . — — , - . .
: -. , , , . つまり - , , , , , . , , . — - , , — , « ».
: , , , , , .. , .
: . , , , , , , , . , . , , .
, - , , , , , , , .

: , , — . , ?
: — , - , .. , , . .
— «update is a move». — , - , . , — , , timestamp. , timestamp, . - . つまり , .
., , e-mail-. , e-mail ( ), -. , .. , timestamp.
, , , . . , .
, , , .
: , , , , - … - .
: — «data expiration».
memcached Badoo. , , — .
, . - . .
: — . , , - , , , , (, twitter )…
: , twitter . , , , … - , , — . .
: , , , .
. Badoo, , , . .
— , .. Badoo - — - , - . , 10 , «». 何してるの? «», , ( ) . , - , - . , ( , , , ) .
« ». , , .
: , — . - schema-less, , .
: — , ? , ..
, . — , . , , , . , .
, , .
: timestamp- . — ? つまり - , , ? ?
: Timestamp , . , . , .. , . , , .
: , . .
: . : ? , - . . , . これは別のトピックです。
— . .
— «», , , .
: Timestamp ?
: , .
: Newdata — . sharding function?
: sharding function . Badoo. . , . , -, , , Badoo , , y.
sharding function , . , , , , .
, Badoo. , -. bucket, bucket config-. config , - bucket- . , bucket-, , . - .
- , , -, . .
: , .. , , … - , ?
: .
-, - , . , .. « », - — , — Redis, Mongo — , , . , . 動作します。 Cassandra, Hadoop, Mongo, Redis Cluster. Tarantool- .
, — . , , , , — . - , , . つまり , , .
, , , — .
: , , . , , . , - - , - . : « ? ». , , « », , — , - .
, . , , , .
連絡先
kostja
fisher
Mail.ru
Badooブログ
— HighLoad++ . 2016 — HighLoad++ , 7 8 .
— HighLoad++. , — :)
- HighLoad.Guide — , , , . 30 . !