無限にスクロールするページをスクレイピングする
専門家からのスクレイピーのヒントへようこそ! 今月は、Webスクレイピング作業を高速化するためのいくつかのトリックを紹介します。 主要なScrapyメンテナーとして、あなたが想像できるあらゆるハードルに直面しています。 だから心配しないでください-あなたは良い手にいます。 今後の記事の提案については、twitterまたはfacebookでお気軽にお問い合わせください。

1ページのアプリケーションと1ページの大量のAJAXリクエストの時代に、多くのWebサイトは、順方向/逆方向ナビゲーションボタンを派手なページ無限スクロールメカニズムに置き換えました。 このメカニズムを使用するWebサイトは、ユーザーが垂直にスクロールしながらページの最後に到達するたびに新しいエンティティを読み込みます(Twitter、Facebook、Google Imagesを思い出してください)。 UXの専門家は、無限スクロールメカニズムがユーザーに過剰な量のデータを提供すると主張していますが、結果の無限のリストを提供することに頼るWebページの数が増加していることがわかります。
Webスクレイパーを開発するときに最初に行うことの1つは、結果の次のページへのリンクを含むサイト上のユーザーインターフェイスコンポーネントを探すことです。 残念ながら、そのようなリンクは無限スクロールのページには表示されません。
このシナリオは、SplashやSeleniumなどのJavaScriptフレームワークの古典的なケースのように思えるかもしれませんが、実装は本当に簡単です。 これらのフレームワークのいずれかを介したユーザーインタラクションをシミュレートする代わりに行う必要があるのは、ページをスクロールしながらブラウザーのAJAXリクエストを調べ、Scrapyのスパイダーでこれらのリクエストを再作成することです。
例としてSpidy Quotesを使用して、ページにリストされているすべての要素を受け取るスパイダーを作成しましょう。
ページ検査
まず、ページ上の無限スクロールの仕組みを理解する必要があります。 そして、ブラウザの開発者ツールのネットワークパネルを使用してこれを行うことができます。 パネルを開き、ページをスクロールして、ブラウザから送信されたリクエストを確認します。
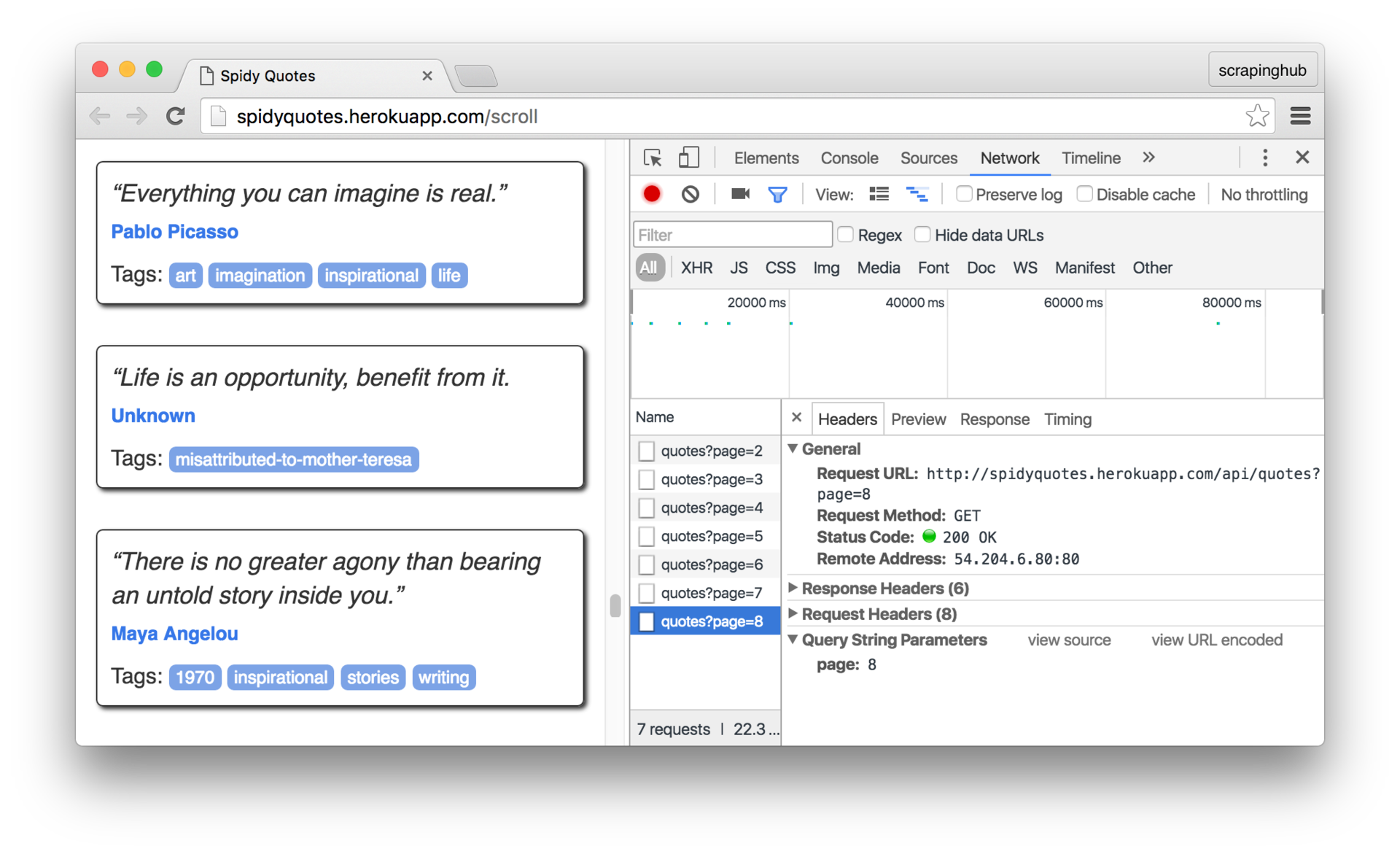
リクエストをクリックして、詳細を検討してください。 ご覧のとおり、ブラウザは/api/quotes?page=x
リクエストを送信し、レスポンスで次のようなJSONオブジェクトを受信します。
{ "has_next":true, "page":8, "quotes":[ { "author":{ "goodreads_link":"/author/show/1244.Mark_Twain", "name":"Mark Twain" }, "tags":["individuality", "majority", "minority", "wisdom"], "text":"Whenever you find yourself on the side of the ..." }, { "author":{ "goodreads_link":"/author/show/1244.Mark_Twain", "name":"Mark Twain" }, "tags":["books", "contentment", "friends"], "text":"Good friends, good books, and a sleepy ..." } ], "tag":null, "top_ten_tags":[["love", 49], ["inspirational", 43], ...] }
これは、クモに必要な情報です。 そのために必要なことは、 /api/quotes?page=x
リクエストを生成することだけ/api/quotes?page=x
has_next
フィールドのhas_next
がfalse
なるまで/api/quotes?page=x
増やしfalse
。 これの素晴らしい点は、必要なデータを取得するためにHTMLコンテンツを廃棄する必要さえないことです。 それはすべて、美しい機械可読JSON形式に含まれています。
ビルスパイダー
こちらがクモです。 サーバーからの応答で受信したJSON形式のコンテンツからターゲットデータを抽出します。 このアプローチは、ページのHTMLツリーを掘り下げるよりも単純で信頼性が高く、レイアウトを変更してもスパイダーが壊れないことを望んでいます。
import json import scrapy class SpidyQuotesSpider(scrapy.Spider): name = 'spidyquotes' quotes_base_url = 'http://spidyquotes.herokuapp.com/api/quotes?page=%s' start_urls = [quotes_base_url % 1] download_delay = 1.5 def parse(self, response): data = json.loads(response.body) for item in data.get('quotes', []): yield { 'text': item.get('text'), 'author': item.get('author', {}).get('name'), 'tags': item.get('tags'), } if data['has_next']: next_page = data['page'] + 1 yield scrapy.Request(self.quotes_base_url % next_page)
獲得した知識を使用して何か他のことをしたい場合は、無限のスクロールを使用して古い投稿をロードするため、ブログのスパイダーの作成を試すことができます
おわりに
無限のスクロールでWebサイトをスクレイピングする可能性について少しがっかりした場合は、今より自信を持っていただければ幸いです。 次回、ユーザーアクションの結果としてのAJAXリクエストへの呼び出しに基づいてページを処理する場合、ブラウザが行うリクエストを確認し、スパイダーでそれを再生します。 要求に対する応答は通常JSON形式であるため、スパイダーがはるかに簡単になります。