
各GoTo学校内では、多くの活動が行われ、多くの成功したプロジェクトやあまり成功していないプロジェクトが学童によって実施されています。 残念ながら、各プロジェクトやインシデントについて話すことはできませんが、個々の成功を共有する価値はあります。 そのため、学校での成功とプロジェクトに関する一連の記事を生徒から始めます。
今年の夏、パートナーの1つであるE-Contenta社は、TVチャンネルの1つのニュースポータル用の推奨システムを作成するタスクを提案しました。 会社の人たちはデータ分析と機械学習の分野で教えていましたが、タスクは誰にとっても非常に興味深いものでした-そのような開発の真の必要性に加えて、タスクも非常にユニークでした-ニュースを推薦する方法は、例えば映画を推薦する方法とほとんど異なります。
6月学校の2人の生徒が決定を引き受けました。モスクワの16歳のアンドレイ・トヴォロフコフと、ボトキンスクの14歳のフセヴォロド・ジドコフです。 また、問題の簡単な説明とその解決策を用意しました。これについては、この記事で公開します。
タスクの説明
レコメンダーシステムは、現在の状態に関するデータをすでに持っている、最も興味深いオブジェクト(書籍、映画、記事など)を予測できるプログラムです。 状態は、ユーザーがすでに気に入っているオブジェクトや、クライアントについて知っているデータ(音楽の好みなど)である場合があります。 このようなデータは、サイトでのユーザーアクションを記録するか、ユーザーまたはオブジェクトに関する外部情報を収集することで簡単に取得できます。
推奨システムが解決する主なタスクは、エンドユーザーに対する製品の使いやすさを向上させることです。 ユーザーがそれを好む可能性が高いことを予測する必要があります。そうすれば、ユーザーは自分でそれを探す必要がなくなり、ユーザーをリソース上に保持できます。 Netflix、Spotify、および他の多くのスタートアップなどのデジタル大手企業は、高品質の推奨システムのおかげで成長しています。
推奨システムには、3つの主なタイプがあります:協調フィルタリング、コンテット、およびハイブリッド。
協調フィルタリングは、おそらくオブジェクトを推奨するための最も一般的なモデルです。 その主なアイデアは、オブジェクトがほぼ同一のユーザーによって表示される場合、これらのオブジェクトをこれらのユーザーに推奨することです。

たとえば、ある特定のアリスがシリーズフレンズとビッグバンセオリーを好み、ブルックリン9-9とフレンズが好きな人がいない場合、ボブはブルックリン9-9をビッグバンセオリーに推薦できます。
協調フィルタリングでは、2つの主なアプローチが区別されます。
- 相関モデル-このようなモデルの主なアイデアは、ユーザー/オブジェクトのマトリックスの保存に基づいています。
- 潜在モデルとは、ユーザー/オブジェクトマトリックスを保持できないが、ユーザーとオブジェクトの「プロファイル」に基づいたモデルです。 プロファイルは、隠された特性のベクトルです。
レコメンダーモデルを作成する次の方法は、コンテットレコメンデーションです。 これは、モデルがオブジェクトの内容に依存することを意味します。 たとえば、ニューステキストの類似性を評価する(少し後でこれを行う方法について)か、映画「タイタニック」に他のキャメロン映画を推奨することができます。 このメソッドの主なアイデアは、推奨するオブジェクトについてできるだけ多くの情報を取得し、この情報を使用して同じオブジェクトを検索することです。その後、単純に類似のオブジェクトを推奨します。
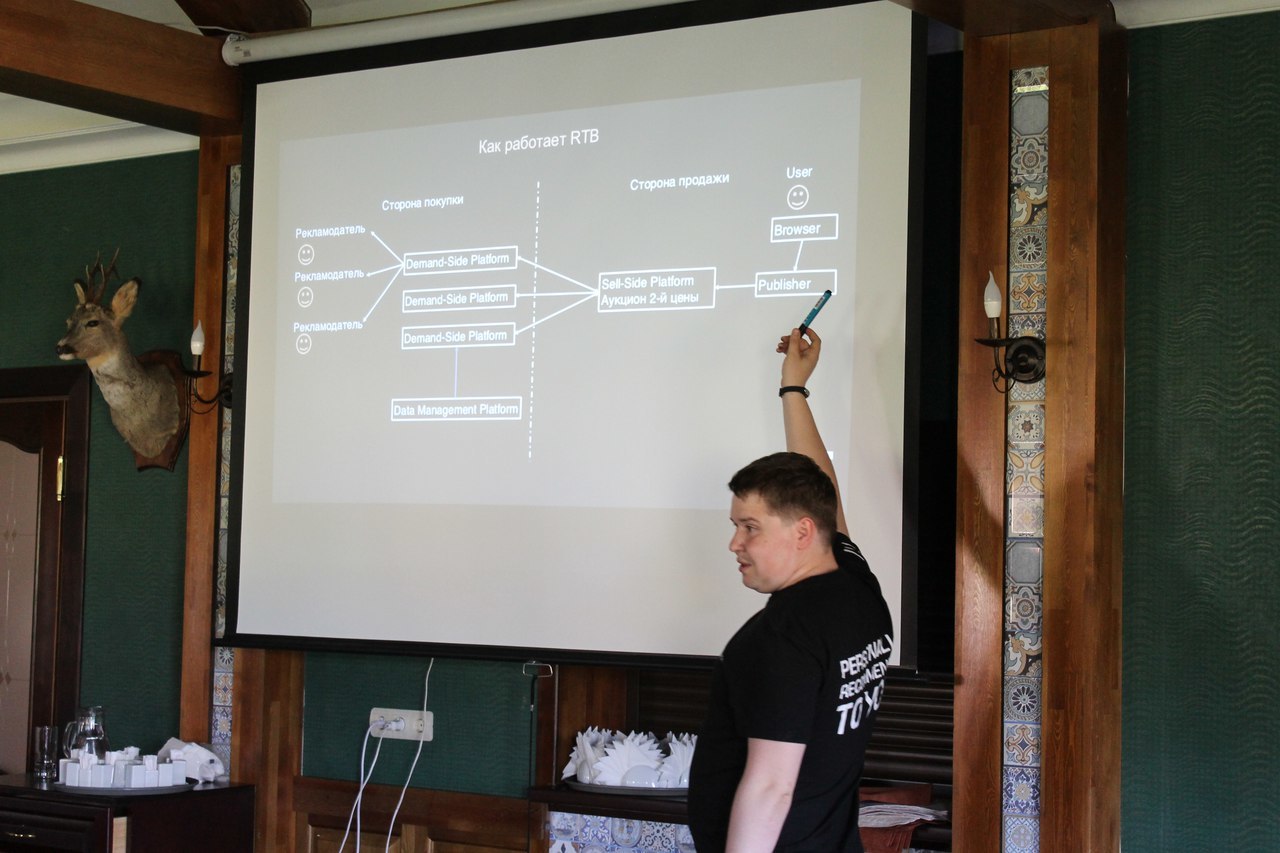
CTO E-Contentaによる夕食のRTB

集合的な創造性

強度試験

困難を克服する

ゲームFingersの例での現実との衝突

最強の生き残り

最後に、書き込みバグ
解決策
このタスクでは、ニュースの推奨に従って、ハイブリッドモデルを使用することにしました。 以前のオプションの結果を組み合わせて、加重結果を返します。
オブジェクトとユーザーに対して取得した属性に基づくハイブリッドモデルは、ユーザーがこの記事を読む(クリックする)確率を返します。 いくつかのテストの後、ランダムフォレストを機械学習アルゴリズムとして使用することにしましたが、これはそれほど重要ではありません。
機械学習のすべての問題では、データの分布を見て、モデルのトレーニングに役立つ依存関係を構築することが重要です。この良い結果が得られない場合。 たとえば、この問題では、モデルを作成する前に、次のようなグラフを作成しました。
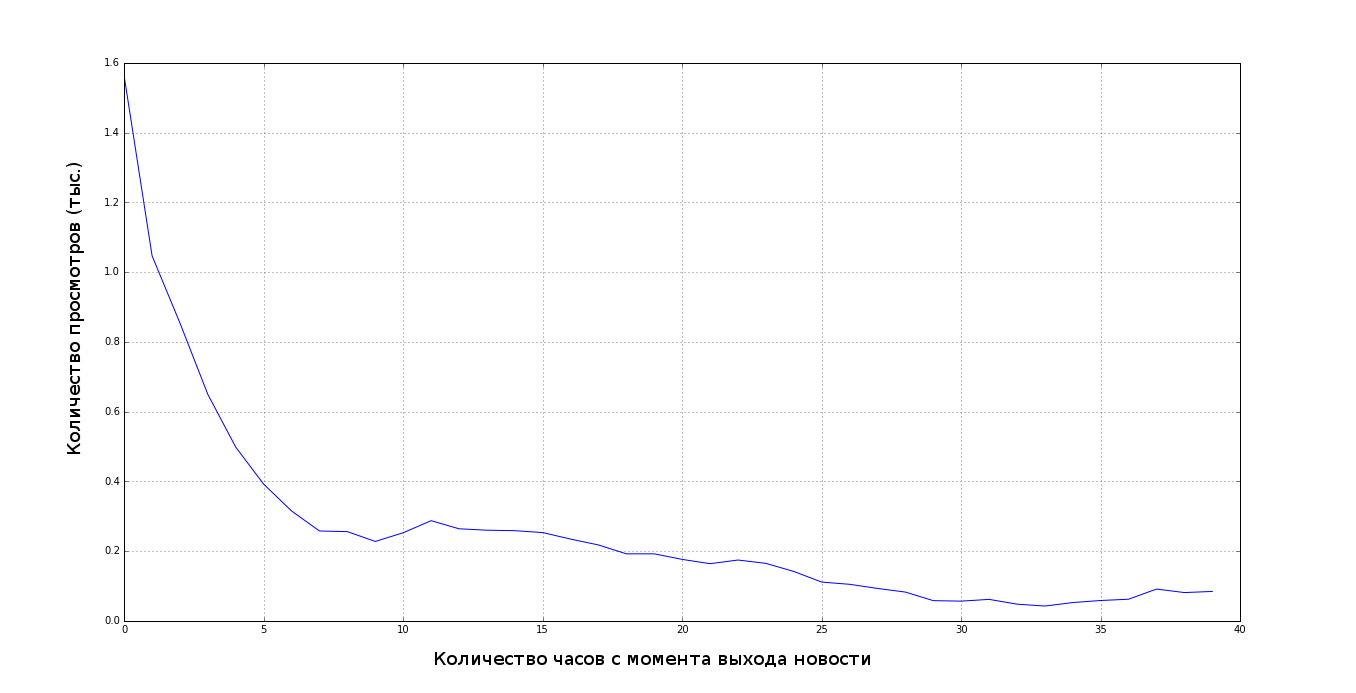
ハイブリッドモデルの本質は、機能として、協調フィルタリングを使用して取得した値とコンテンツモデルを使用して取得した値を提供することです。
協調フィルタリングから始めましょう。 この記事を見たユーザーによるニュースの類似性を計算しましょう。 このために、コサイン尺度がよく使用されます-2つのベクトル間の角度のコサイン、この場合はユーザービュー。

1つのニュース項目だけでなく推奨事項も考慮に入れるため、最後の3つの記事と1つの可能な記事(推定する切り替えの確率)を取得し、その後、読み取られた各ニュースから可能な記事へのコサイン類似度を計算します。 したがって、3つの機能を取得します。
今やもっと難しい仕事があります-コンテンツのニュースの類似性を評価することです。 キーワードを検索したり、効率が低いために交差点をカウントしたりするなど、最も単純なオプションは無視しました。
コンテンツモデルを構築する分野では、テーマモデリングは独立しており、教師なしでドキュメントをトピックに分割する方法です。 これにはいくつかのアルゴリズムがあり、システムではNMF(非負行列の分解)を使用しました。LDA(潜在ディリクレ配置)よりも優れていることが証明されました。 NMFを使用する前に、TF-IDFを使用して、マトリックスを作成する必要があります。
TF-IDFは2つの部分で構成されています。
TF(期間頻度)は、ドキュメント内の特定の単語の数と特定のドキュメント内の単語の数の比率です。 用語頻度を使用して、文書内の単語の重要性を評価できます。 いわゆるストップワード(接続詞および関連語、代名詞、前置詞、助詞など)の頻度は他の頻度よりも多いため、すべてのニュースをクリアしたことに注意してください。

IDF(逆文書頻度)は、コレクション文書で特定の単語が出現する頻度の逆です。 IDFの助けを借りて、ストップワードだけでなく、頻繁に使用される名詞の重要性を下げることもできます。

テキスト内の単語の重要性と一意性を知ることが重要であるため、TF-IDFを乗算して次のようになります。

TF-IDFを使用して、TF-IDFから取得した値を配置するドキュメントと単語の交差点で、単語のドキュメントのマトリックスを作成します。
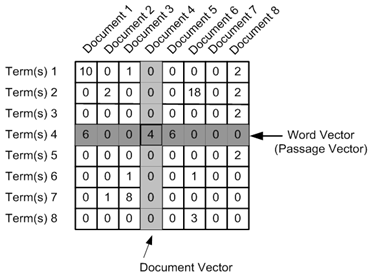
用語ドキュメントマトリックスを受け取ったら、NMFを使用して特異値に従って分解します。 マトリックスが分解された後、任意のドキュメントと用語を空間内のベクトルとして表すことができます。用語の組み合わせやドキュメント間の近接性は、ベクトルのスカラー積を使用して簡単に計算できます。 このすべての後、Savchenkoに関する記事が1つのクラスターになり、State Dumaが別のクラスターで提案する法律に関する法律など、非常に意味のあるトピックが得られました。
勾配降下法を使用して、データに最適なクラスター数を見つけました。40です。変換後、各ニュースは40次元空間のポイントと見なすことができます。各次元は特定のクラスターに属している度合いです。
また、機能として、4つのニュースのそれぞれに40個の値を使用できます。 さらに、機能エンジニアリングを実行し、読んだ各記事と可能な記事の違いを追加することもできますが、できませんでした。
その結果、予測が適切なモデルが得られました。 たとえば、私たちは、推薦システムが候補者の特定の名前の記事を私たちに提供した直後に、大統領顧問のポストに誰かが任命される可能性についてのいくつかのニュースを読みました。
品質指標
それにも関わらず、記事は非常に論理的に推奨されることがわかりましたが、推奨の品質メトリックを計算する必要がありました。 最も一般的なメトリックはMAP @ Kです 。ここで、Kは推奨事項の数です。 このタスクでは、ユーザーは一度に10個の記事を推奨されます。したがって、K = 10です。このメトリックにより、ユーザーが望むものをどれだけ早く提供したか、この場合、ユーザーが実際に読んだ記事をどれだけ早く推奨したかを知ることができます。
その結果、MAP @ 10は最終モデルで0.75、最初のモデルで0.05でした。 私たちの結果は非常に適切であることが判明しました。これは、メトリックおよびアイテストによって示されました。
推奨システムの作成が完了したら、Webアプリケーションを作成し、そのアプリケーションを使用して自分で作業を評価できます。 そのソースはGithubで入手できます。
プロジェクトの作業中に、このような推奨システムの重要な機能に気付きました:同じトピックに関する記事のtrapにユーザーを誘導することが非常に多いため、ユーザーが興味を持っている他のトピックを見つけるためにランダムな記事を含めることは価値があります。
結果は何ですか?
結果は教師に高く評価され、E-Contentaが顧客のプロジェクトのさらなる作業に使用しました。そして、彼らは新しい問題を解決するためにインターンシップに招待されました。
また、多くの企業が教育プロセスに参加し、学校の参加者の目標を設定していることを非常に喜んでいます。
今後の活動
この秋、Jetbrains、CROC、Intel、Institute of Bioinformatics、BIOCAD、Parseq Lab、Odnoklassnikiなどが参加して、イングリアビジネスインキュベーターで高校と中学校が開催されます。
これはサンクトペテルブルクでの最初の学校です。 参加者は、データ分析とバイオインフォマティクスだけでなく、モバイルアプリケーション、チャットボット、およびWebサービスの開発に伴うインターネットにも参加します。 10月22日までGoTo Challengeコンテストに参加することで、 Webページの ゲノムアセンブリまたはテーマ分類子を実装することで、誰もがバイオインフォマティクスとデータ分析の分野での無料トレーニングの助成金を獲得することができます 。
私たちは専門家をメンターと教師の役割に参加するように招待します。特に、みんなと仕事を分かち合うことをいとわないスタートアップは特に幸せです。
また、 2番目のGoToHackデータ分析ハッカソンについても説明しますが、今回は教育とHR専用です。 Stepik.orgプラットフォームのオンラインコースを修了した学生に関する実際のデータに基づいて、Kaggleの課題を含むオンラインステージが既に開始されていることに注意してください。