それでは、主題そのものに移りましょう。 5年前、トップエンドハードウェアでほとんど起動されなかったシングルスレッドプログラムを提供することはあまり「急増」できず、1〜2年でこの「プログラム」の部分(all意のごめん)が正常に動作することを知っていました。 今日、そのような「無料ランチ」は終わりました。
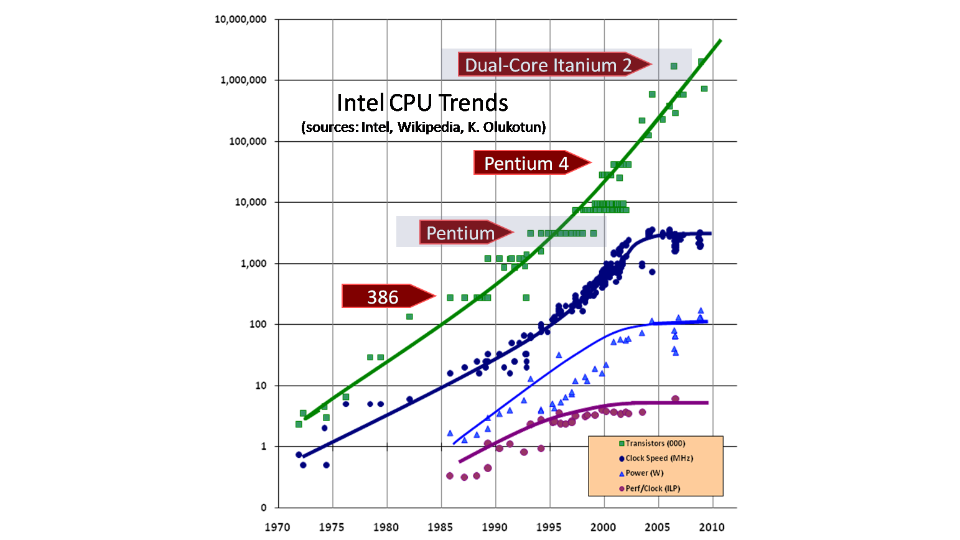
この図は、トランジスタの数がまだ増えていることを明確に示していますが、周波数に関しては、ほぼ上限に達しました。 1年でアイロンが2倍速く動作するという事実により、開発者の手の「曲率」を補正することはすでに困難です。 すべてがそれほど悲しいわけではありませんが、プロセッサはコア数の点でのみ成長しています。 その結果、湾曲した腕を持つオークによって書かれた「プログラム」が新しいハードウェア上で何らかの形で正常に機能するためには、マルチプロセッサ環境で正常に機能する必要があります。 そして、パフォーマンスは鉄のコアの数に直接関係していました。 それが実際に私たちが「マルチプロセッサ環境で正常に機能したもの」について話していることです。
2つの答えがあります。 まず、特定のハードウェア、Intel Xeon、God for ItaniumまたはElbrus向けに記述した場合、コードは完全に異なり、特定のハードウェアに合わせて調整されます。 このようなコードはすべてをハードウェアから絞り出しますが、非常にスケーラブルではありません。 これは、特定のハードウェア用に3Dゲームを作成する場合に適しています。たとえば、PS4などの今日のハードウェアからすべてを絞り出して、明日の神話を待つ必要はありません。 しかし、真空中の抽象的なプラットフォームの下でHeil Mirを非難し、VLIW CPUアーキテクチャとRISCの違いを理解していない普通のプログラマは何をすべきでしょうか? また、マルチスレッドプログラムを何らかの方法でプログラムして、今日のハードウェアで生産的に動作し、明日(新しいハードウェア)でさらに高速に動作するようにする必要もあります。 そして、シンガーのミシンで動作するプログラムのこの部分は、それでも「巧みな」実装の後、クラスターで起動することができました。
そうではないプログラマーになる方法? どのように問題を解決できますか? そう、新しいレベルの抽象化を追加することによって。 もちろん、この状況は例外ではありません。 抽象マシン(AM)はプログラマーの助けとなり、その下でほとんどのプログラマーが実際にコードを記述します。 実際、AMは、ポニーが生活し、虹と特定の本物の鉄の実装でうんちをする最も単純化された高レベルの概念(hi FP)を使用し、知識を減らしたいというエンジニアの欲求の間のトレードオフです。 彼女(AM)は、これからプログラマーは特定のハードウェア用に書くのではなく、抽象マシン用に書く(すべて抽象マシン用に書く)と言います。これは抽象メモリを持ち、このメモリは記述されたメモリモデルに従って動作します。 そして、コンパイラ、JIT、インタプリタ、または神は、抽象マシン用に作成されたコード/バイトコード/などを特定の実装にマッピングする責任を誰が負うかをすでに知っています。 つまり、たとえば、C ++コードで抽象的なマシンの下で書いています(少なくともC ++ 11の仕様ではメモリモデルが非常に調和して明確に記述されているため、C ++に言及しました)コンパイラのタスクは、これを特定のハードウェア、たとえばInantium(VLIWアーキテクチャ)またはCISCプロセッサ上で動作するマシンコードに変換することです。 プログラムの異なる部分が、異なるプラットフォームで同時に異なるパフォーマンスを示すことは明らかです。
もちろん、コードから最大限のパフォーマンスを引き出したい場合は、何らかの方法でこれらの抽象化レベルからすべての地獄を捨て、特定の時点で可能な限りハードウェアに近いものにすべてを書き直す必要があります。 もちろん、問題がハードウェアに近いレベルにある場合、これは機能します。遅いアルゴリズムを使用している場合、低レベルで書き直して複雑さを追加しても状況を救う可能性は低いためです。 しかし、そのような「レムメタル」が必要なのは問題だけではありません。 まだ「抽象的なプログラマ」についてです。 抽象化に戻ると、問題は、抽象マシンで正確にMMを選択する理由と、なぜ近年それが突然関連性を持つようになったのかということです。 抽象マシンを長い間説明することは可能であり、これらのトピックに関する作業は実行されましたが、それを必要とした人はほとんどいませんでした。 事実、以前は、シングルスレッド環境の普及により、すべてのプログラムが何らかの形で決定されていました。 Shipilevが言ったように、実用的なプログラマーの場合、MMは1つの質問に答えるだけです。ストリーム内の変数Aを読み取った場合、最後のレコードの結果(複数のレコードがあった場合)を確認できますか?
確定的なシングルスレッドプログラムでは、これはすべて、作成している言語のMMを知らなくても簡単に決定できます。 プログラムはマルチコアアーキテクチャのために完全に壊れる可能性がありますが、ヤードが90年代に厳しい場合や、複数のプロセッサを搭載したマシンがスーパーコンピューターである場合は誰が気にしますか? さらに、P4HTプログラムを並列化する最初の機会が現れたとき、彼らは独自の見解と並列化のビジョンを示したため、先駆者は原則として、2-3の抽象的なフローではなく、それ自体はスケーラブルではないP4HTでコードを記述しました。
体に近づきましょう。 私たちが記憶から何を読むことができるかについての質問に答えるつもりなら、私たちの多くが想像するように、私たちは素朴なMMを見るでしょう。
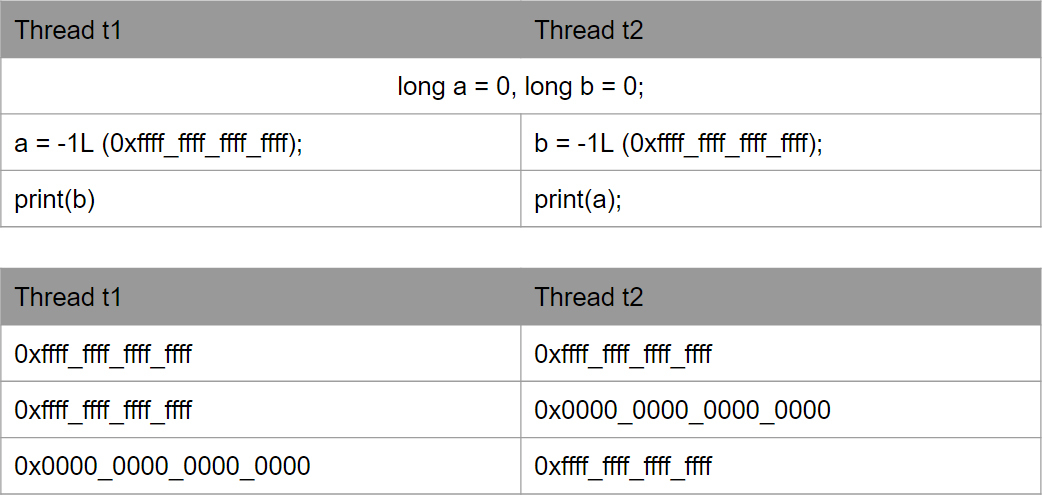
このシステムでは、光の広がり方を考慮していません! 光は十分に速いといつも教えられてきたにもかかわらず、いくつかの条件があります。 彼はそれほど速くありません、そして、我々が真空の理想的な状態について話していなければ...
3 GHzプロセッサの1クロックサイクルで、真空中の光は10 cm通過します!
ローマン・エリザロフ
3 GHzプロセッサを使用している場合、光は1クロックサイクルで10 cm移動しますが、導体の場合はさらに少なくなります。 その結果、プロセッサーは物理的に変数を変更できず、これらの変更に関する情報を残りのプロセッサーに提供できません。 実際には、次のオプションを取得できます(これには以前のオプションはありませんが、これらも有効です)。 最も一般的に紛らわしいオプションは0x0です。
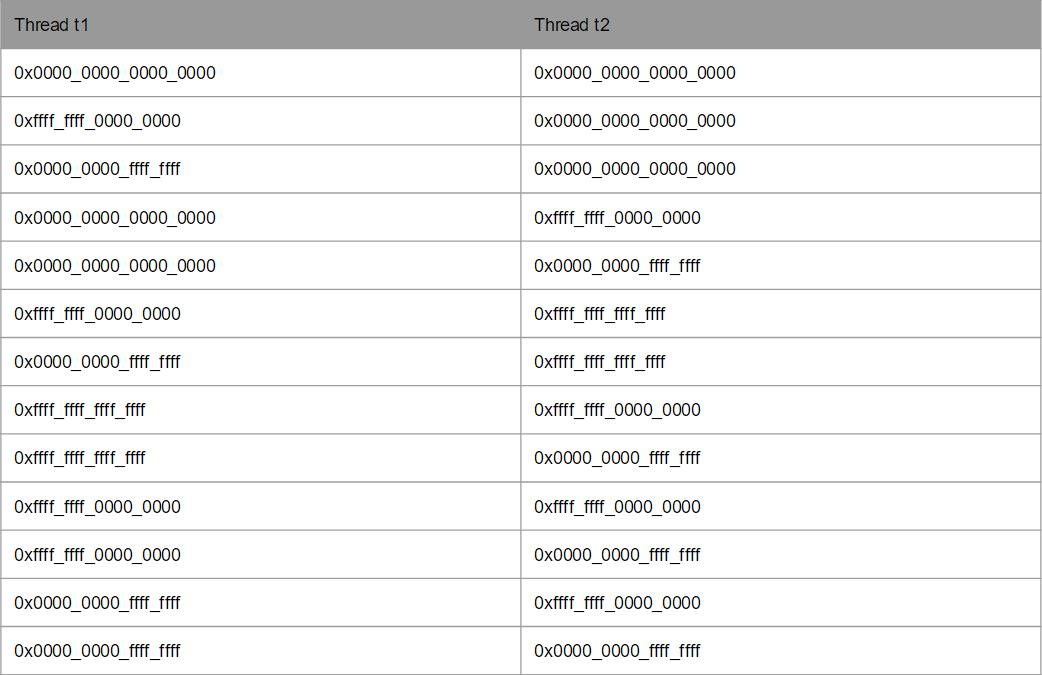
実際、高速での時間の歪みの影響を洗練された形で観察するため、これは非常に面白いです。 もちろん、プロセッサコアが互いにデータを同期する方法が原因で、奇妙な結果が表示されます。 しかし、プログラマーが、相対論的な物理学を思わせる独自のプロセスを持っていることに気付くのはどれほどクールなのでしょうか?)2つのCPUがあり、それらは互いに独立しており、内部のデータの物理的な交換があり、制限が異なるためです互いに異なった見方をします。現在と見なされるもの(変数「a」はゼロ、2番目のCPUは過去と見なされます。この変数は既に-1であるため)。 もちろん、非同期化はそれほど速くない速度によって引き起こされますが、プロセッサの複雑さのために同様の問題が発生しました。 実際、こちら側から考えると、これらのすべてのパラドックスをわずかに変更した例で視覚化するのは非常に簡単です。

ストリーム2がストリーム1を見る方法を見ると、何でも見ることができます。 ストリーム2のユニバースでは、ストリーム1は、たとえば、aのみを書き込むことができます。 書き込みbがまったく発生しない場合があります。 書き込みbのみが表示され、書き込みaはまったく発生しない場合があります。 write a write bを見ることができますが、それらのシーケンスは完全に異なる場合があり、ストリーム1の内部とは異なります。
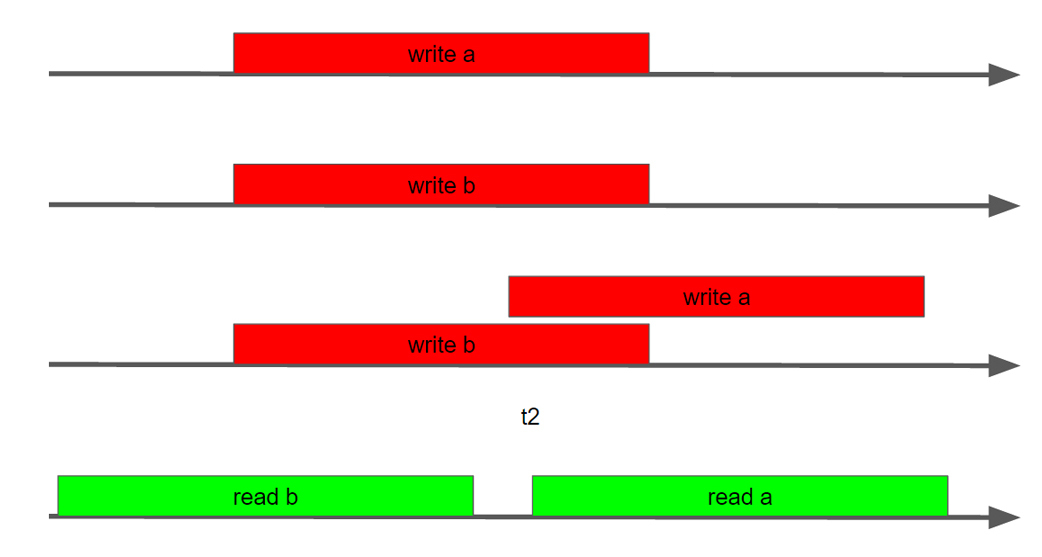
推測するのは難しくないので、結果は完全に予測不可能です。

Javaの以前のバージョンには、「バグ」と呼ばれるものが非常に多くありました。 実際、MMの制限を完全に理解していない素朴なレミングの群衆は、実際には永続的なサイクルに入るコードを書きました。 実際、Javaは開発者が自分が書いていることを知っていると単純に考えたため、単純に多くの最適化を適用しました。
優れたプログラムを作成し、x86_64でテストしてから、32ビットARM(またはPowerPC)で実行し、驚きの状況に陥りました。 それは、Vasya Pupkinがテスト対象の特定のハードウェアについて書いたからです。実際、Abstract Machineで書いた理解なしに、仕様は彼がコードを書いた特定のマシン以外の保証(より弱い)を与えます。 。 もちろん、彼が知っておくべき仕様である抽象マシンのために彼が書いた認識は、そのような故障の後に来ますが、コードが突然クライアントのマシンで動作しなくなると非常に遅くなります。
MMは、この混乱と混乱にどのように対処するのに役立ちますか? MMの最も基本的な概念の1つは、1978年にランポートによって導入されたHappensBeforeの概念です。 彼は簡単な方法で、はい、おridge、不法行為、自慰行為がありますが、この混乱と動揺の間で整理されるいくつかの操作を選びましょう。 つまり、スレッド間に2つの操作があり、その下で、2番目のスレッドの2番目の操作で1つの操作が厳密に順序付けられていることを確認できます。 この操作を明確にするために、偽の例に戻ることができます。
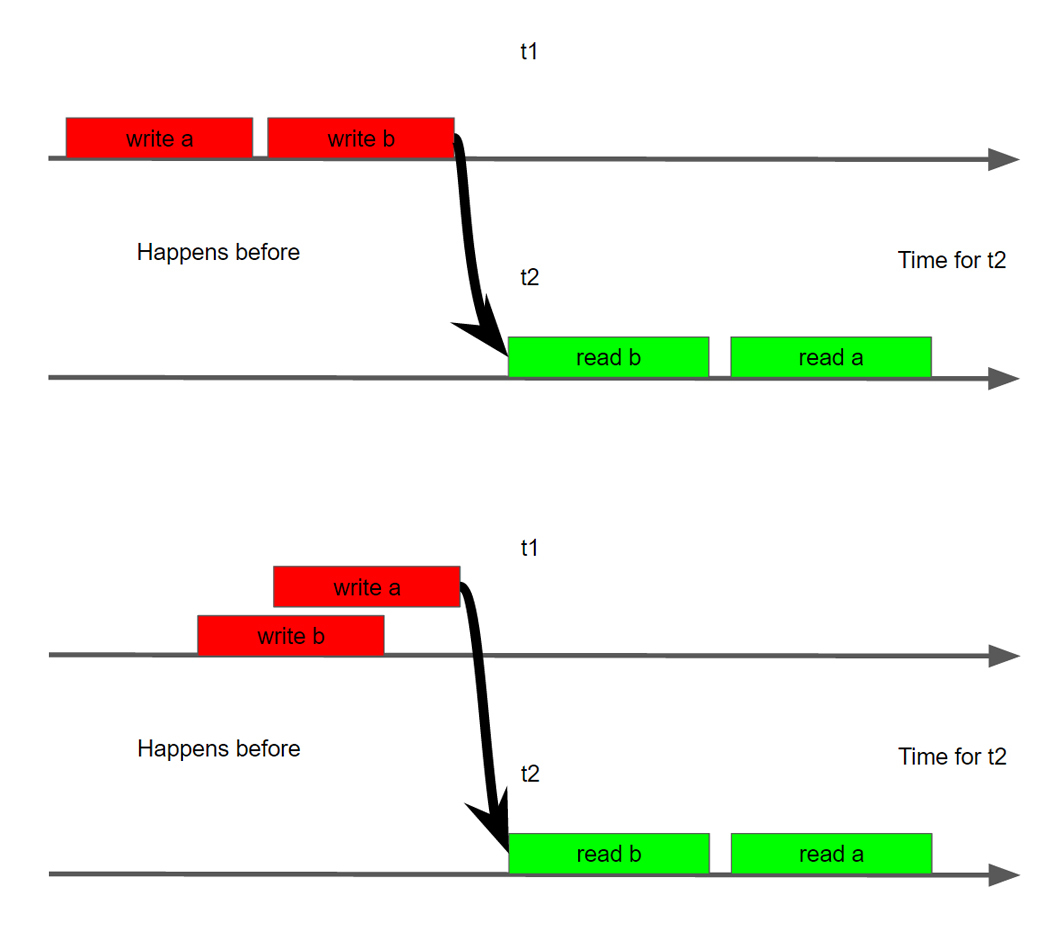
そして最後に、そのような例がどのくらいの頻度でどのプラットフォームで発生するかをより明確に理解するために、あなたが書いているのではないという理由だけで、あなたが地元のタイプライターで作業し、すべてが機能するときに私が話した状況を明確に見る抽象マシン、および特定のアイロンについては、Gleb Smirnovのレポート「フードの下のマルチスレッド」を参照することをお勧めします。 その前に、ローマ・エリザロフともちろんシプリエフの一般的な理論報告書を見てください。 すべてのレポートを簡単に表示できるように、これらのすべてのレポートをプレイリストで慎重に収集しました。 レポートをソートしました。