
機械学習問題の要件をどのように定式化し、精度/完全性曲線上のポイントを選択したかの実際的な例についてお話します。 自動コンテンツモデレーション用のシステムを開発する際、精度と完全性の間の妥協点を選択するという問題に直面し、査定者の収集とその一貫性の計算においてシンプルだが非常に有用な実験の助けを借りて解決しました。
HeadHunterでは、機械学習を使用してカスタムサービスを作成しています。 MLは「ファッショナブルでスタイリッシュ、若者...」ですが、最終的にはビジネス上の問題を解決するための可能なツールの1つにすぎず、このツールを正しく使用する必要があります。
問題の声明
極端に単純化すると、サービスの開発は会社のお金の投資になります。 また、開発されたサービスは有益である必要があります(たとえば、間接的に-たとえば、ユーザーの忠誠心を高める) 機械学習モデルの開発者は、ご理解のとおり、作業の品質をわずかに異なる用語(精度、ROC-AUCなど)で評価します。 したがって、ビジネスの要件を何らかの方法で、たとえばモデルの品質の要件に変換する必要があります。 これにより、とりわけ、「不要」なモデルの改善に夢中になることがなくなります。 つまり、会計の観点から-投資するのが少なく、製品開発の観点から-ユーザーにとって本当に役立つことをするということです。 具体的なタスクの1つとして、モデルの品質要件をかなり単純な方法で設定する方法について説明します。
私たちのビジネスの一部の1つは、電子申請書を作成するための一連のサービスをユーザーと申請者に提供し、これらの履歴書を使用する便利な(主に有料の)方法をユーザーと雇用者に提供することです。 この点で、人事マネージャーによる認識の観点から高品質の履歴書ベースを正確に確保することは非常に重要です。 たとえば、データベースにはスパムが含まれるだけでなく、常に最後の作業場所を示す必要があります。 そのため、各履歴書の品質をチェックする特別なモデレーターがいます。 新しい履歴書の数は絶えず増加しています(それ自体、私たちは非常に満足しています)が、同時に、モデレーターの負荷は増加しています。 簡単なアイデアを思いつきました。履歴データが蓄積されているので、公開が許可されている履歴書と、確定が必要な履歴書を区別できるモデルをトレーニングしましょう。 念のため、履歴書に「改善が必要」な場合、ユーザーはこの履歴書を使用する可能性が限られているため、その理由を理解し、すべてを修正できることを説明します。
ここでは、ソースデータを収集してモデルを構築する魅力的なプロセスについては説明しません。 おそらく、これを行った同僚が遅かれ早かれ経験を共有するでしょう。 とにかく、最終的にこの品質のモデルが得られました。
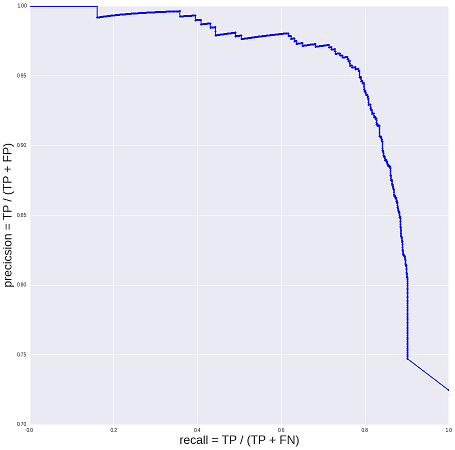
垂直軸は精度、またはモデルが正しく受け入れた履歴書の割合を表します。 水平軸-対応する完全性(リコール)、またはモデルによって受け入れられた割合は、「公開対象」再開の総数から再開します。 モデルに受け入れられないものはすべて、人々に受け入れられます。 ビジネスには2つの反対の目標があります:良いベース(「十分ではない」履歴書の最小割合)とモデレーションコスト(できるだけ多くの履歴書を自動的に受け入れ、開発コストが低いほど良い)。
良いモデルか悪いモデルを手に入れましたか? 改善する必要がありますか? そうでない場合、どのしきい値(しきい値)、つまり曲線上のどのポイントを選択するか:精度と完全性の間のトレードオフはビジネスに適していますか? 最初は、「98%の精度と40%の充足度が必要なように思えます」という精神で、漠然とした構成でこの質問に答えました。 もちろん、このような「製品要件」の正当化は存在しましたが、あまりにも不安定であったため、公開する価値はありませんでした。 そして、モデルの最初のバージョンがこの形式で出てきました。
評価者による実験
誰もが幸福であり、それから疑問が生じます。自動システムがさらに多くの履歴書を受け入れましょう! 明らかに、これは2つの方法で実現できます。モデルを改善するか、たとえば、上記の曲線上の別のポイントを選択する(完全性のために精度を下げる)。 製品要件をより意識的な方法で策定するために何をしましたか?
実際、人(モデレーター)も間違っている可能性があると想定し、実験を行いました。 4人のランダムなモデレーターに、テストベンチで同じサンプルの履歴書を(互いに独立して)マークするように依頼しました。 同時に、作業プロセスは完全に再現されました(実験は通常の作業日と変わりませんでした)。 サンプリングでは、トリックがありました。 モデレーターごとに、すでに処理されたN個のランダムな履歴書を取りました(つまり、合計サンプルサイズは4Nでした)。
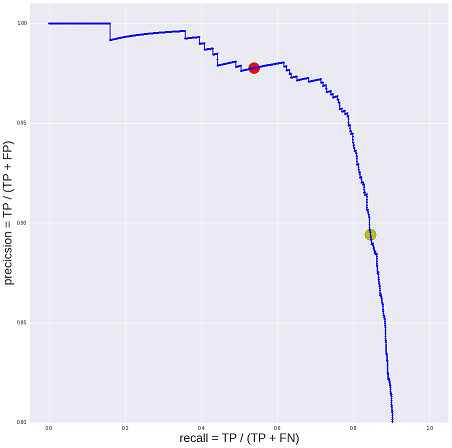
そのため、履歴書ごとに、モデレーターの4つの独立した決定(0または1)、モデルの解(0〜1の実数)、およびこれら4つのモデレーターの1つ(0または1)の初期解を収集しました。 最初にできることは、モデレーターの決定の平均「自己整合性」を計算することです(約90%でした)。 さらに、多数決方式などにより、履歴書の「品質」をより正確に評価できます(評価は「公開」または「公開しない」)。 仮定は次のとおりです。「モデレーターからの初期評価」と「ロボットからの初期評価」に加えて、独立モデレーターからの3つの評価があります。 3つの推定によると、常に多数意見があります(4つの格付けがあった場合、2:2の投票により、ソリューションがランダムに選択されます)。 その結果、「平均モデレーター」の精度を評価することができます-再び、約90%であることが判明しました。 曲線上に点を描き、モデルが80%を超える完全性で同じ予想精度を提供することを確認します(その結果、最小限のコストで2倍の履歴書を自動的に処理し始めました)。
結論とネタバレ
実際、自動調停システムの品質を受け入れるプロセスを構築する方法を考えていたときに、次に説明するいくつかの石に出会いました。 その間、かなり簡単な例を使用して、Yandex.Tolkiが手元になくても、アクセッサマークアップの利点とそのような実験の構築の簡単さを説明できたと思います。 この特定のケースでは、ビジネス上の問題を解決するには90%の精度で十分であることがわかりました。つまり、モデルを改善する前に、実際のビジネスプロセスの調査に時間をかける価値があります。
結論として、作業中の私たちのチームの助言に対して、Roman Poborchem p0b0rchyに感謝したいと思います。
読むべきもの:
- クラウドソーシング検索関連性評価の品質の確保:トレーニング質問の分布の影響 -同様の問題ステートメントの例
- Amazon Mechanical Turkのモデリング -Amazonのカスタムグレーディングシステム
- EMアルゴリズムを使用したオブザーバーのエラー率の最尤推定 -真の推定を予測するための反復アルゴリズム(特に、著者名アルゴリズム-Dawide-Skeneアルゴリズム)