
Sparkにはいくつかの神話があります。
- Spark'y need Hadoop:not need!
- SparkにはScalaが必要です:必要ありません!
なんで? カットの下を見てください。
きっとあなたはスパークについて聞いたことがあるでしょう、そしておそらくあなたはそれが何で、何と一緒に食べられているかも知っているでしょう。 もう1つは、このフレームワークを専門的に使用していない場合、頭の中にいくつかの典型的なステレオタイプがあり、彼をよく知ることができなくなるリスクがあるということです。
神話1. SparkはHadoopなしでは機能しません
Hadoopとは何ですか? 大まかに言うと、これは分散ファイルシステムであり、このデータを処理するためのAPIセットを備えたデータウェアハウスです。 そして、奇妙なことに、HadoopにはSparkが必要であり、その逆は不要だと言う方が正しいでしょう!
実際、標準のHadoopツールキットでは、既存のデータを高速で処理することはできず、Sparkでも可能です。 問題は、SparkにHadoopが必要かどうかということです。 Sparkとは何かを見てみましょう。
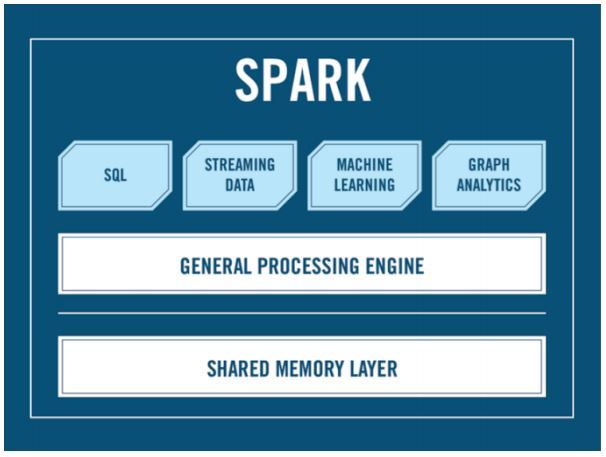
ご覧のとおり、ここにはHadoopはありません。API、SQL、ストリーミングなどがあります。 Hadoopはオプションです。 そして、クラスターマネージャー、あなたは尋ねますか? Sparkをクラスターで実行するのは誰ですか? アレクサンダー・セルゲヴィッチ? 神話の脚が伸びるのはまさにこの質問からです。ほとんどの場合、YARNはHadoopの下でクラスターのスパークのジョブを分散するために使用されますが、代替手段もあります。 Hadoop。
神話2. SparkはScalaで記述されているため、Scalaで記述する必要もあります。
JavaとScalaの両方でSparkを使用できますが、2番目のオプションはいくつかの理由で最良であると多くの人が考えています。
- Scalaはクールです!
- より多くのランチャーとより便利な構文。
- Spark APIはScalaによって強化され、Java APIよりも早く登場します。
Scalaのクールさとファッションについての最初のポイントから始めましょう。 反論は簡単で、1行に収まります。驚くかもしれませんが、 ほとんどのJava開発者は... Javaを知っています ! そして、それは多くの費用がかかります-崖のほうを向いている先輩のチームは、StackOverflow-Drivenの後輩に変わります!

構文は別の話です-JavaとHolivarを読む場合 Scala、これらの例のようなものに出くわします(ご覧のように、コードは単に行の長さを合計するだけです):
スカラ
val lines = sc.textFile("data.txt") val lineLengths = lines.map(_.length) val totalLength = lineLengths.reduce(_+_)
Java
JavaRDD<String> lines = sc.textFile ("data.txt"); JavaRDD<Integer> lineLengths = lines.map (new Function() { @Override public Integer call (String lines) throws Exception { return lines.length (); } }); Integer totalLength = lineLengths.reduce (new Function2() { @Override public Integer call(Integer a, Integer b) throws Exception { return a + b; } });
1年前、Sparkのドキュメントでさえ、例はまさにそのように見えました。 ただし、Java 8コードを見てみましょう。
Java 8
JavaRDD<String> lines = sc.textFile ("data.txt"); JavaRDD<Integer> lineLengths = lines.map (String::length); int totalLength = lineLengths.reduce ((a, b) -> a + b);
よさそうですね。 いずれにしても、Javaは私たちにとって馴染みのある世界であるということも理解する必要があります。それは、Spring、デザインパターン、コンセプトなどです。 Scalaでは、ジャビスタは完全に異なる世界に直面する必要があります。ここで、あなたまたはあなたの顧客がそのようなリスクに対して準備ができているかどうかを検討する価値があります。
すべての例は、JPoint 2016で作成されたSparkに関するEvgeny EvgenyBorisov Borisovのレポートから取られており、ちなみに会議の最高のレポートとなっています。 継続したい:RDD、テスト、例、ライブコーディング? ビデオを見る:
Gods BigDataへのより多くの火花
そして、ユージーンのレポートを見て、実存的なカタルシスを経験し、Sparkをより詳しく知る必要があることに気づいた場合、1か月後にユージーンと一緒に生きることができます。
大規模な2 日間のスパークウェルカムトレーニングが10月12〜13日にサンクトペテルブルクで開催されます。
未経験のSpark開発者が最初に遭遇する問題と解決策について説明しましょう。 構文とあらゆる種類のトリックを扱いますが、最も重要なことは、Inversion of Control、デザインパターン、Springフレームワーク、Maven / Gradle、Junitなどのフレームワーク、ツール、概念を使用してJavaでSparkを記述する方法を確認することです。 それらはすべて、Sparkアプリケーションをよりエレガントで読みやすく親しみやすくするのに役立ちます。
多くのタスク、ライブコーディングがあり、最終的には、慣れ親しんだJavaの世界でSpark-eの独立した作業を開始するのに十分な知識をこのトレーニングに残します。
ここに詳細なプログラムをアップロードすることはあまり意味がありません。それを望む人は誰でもトレーニングページで見つけることができます 。
ユージンボリソフ
Nayaテクノロジー

Evgeny Borisovは2001年からJavaで開発を続けており、多数のエンタープライズプロジェクトに参加しています。 単純なプログラマーから建築家になり、ルーチンにうんざりして、彼は無料のアーティストになりました。 今日、彼はさまざまな聴衆向けにコース、セミナー、マスタークラスを作成および実施しています。イスラエル軍の将校向けのJ2EEのライブコースです。 春-ルーマニア人向けのWebEx経由、カナダ人向けのGoToMeeting経由の休止状態、ウクライナ人向けのトラブルシューティングとデザインパターン。
PSプログラマーの日にこの機会に皆さんを祝福します!