
開発者が見落としがちな重要なポイントは、プロジェクトの運用です。 データセンターの選択方法 脅威を予測する方法は? フロントエンドレベルで何が起こりますか? フロントエンドのバランスをとる方法は? 監視方法 ログを構成する方法は? どのようなメトリックが必要ですか?
結局のところ、これはフロントエンドにすぎませんが、バックエンドとデータベースもあります。 どこでも異なる法律と論理。 HighLoad ++ JuniorカンファレンスのNikolai Sivko( okmeter.io )によるレポートで、高負荷プロジェクトの運用について詳しく読んでください。
プロダクションのプロジェクトライフ:操作のヒント
ニコライ・シヴコ( okmeter.io )
操作についてお話ししたいと思います。 はい、HighLoadカンファレンスは、開発、高負荷への対処方法などに関するものです。 など-オーガナイザーは私にそのような入門的なものをくれましたが、フォールトトレランスについてお話したいと思います。私の意見では、これも重要だからです。
私たちは問題の声明-私たちが望むものの定義から始める必要があります。

ロケット科学はありません。特に極秘のレシピは提供しません。 私は、対象読者が初心者の搾取者であるという事実に基づいています。 したがって、これはフォールトトレランスを計画する方法の単なるセットになります。
入り口にはウェブサイトがあり、彼はお金を稼ぐと仮定します。 したがって、サイトがオフになっていて、ユーザーがアクセスできない場合、お金を稼ぐことはできません。これは問題です。 ここで解決します。 彼がどれだけお金を稼ぐかは問題ですが、巨額のお金ではないためにできる限りのことをしようとします。 予算が少ないため、フォールトトレランスに時間をかけることにしました。

あなたはすぐに欲望に自分自身を制限する必要があります、すなわち フォーナインを作る、ファイブナインはすぐに価値がありません。 データセンターが提供するすべてのものに依存します-彼らは異なるレベルの認証を持っています、データセンターの設計は認証されています、すなわち すべてがフォールトトレラントであり、TIER IIIよりも先にジャンプしようとは思わないでしょう。 1か月あたり8分のダウンタイムで、99〜98%のアップタイムが可能です。 つまり データセンターはまだ予約していません。

実際には、データセンターがTIER IIIよりもわずかに低いと認定された場合(または、その順序を覚えていません)、実際、現代世界のデータセンターは非常にうまく機能しています。 つまり モスクワでは、彼らが言うように、休みなく年ごとに安定したデータセンターを見つけることは難しくありません。 Googleで確認したり、レビューを依頼したりできます。 その結果、あなたはどこかに起きて鉄を入れました。 しかし、データセンター内で破損するのは、損害、つまり 鉄の破損、ソフトウェアの破損。 コミュニティが存在するため、作成しなかったソフトウェアの破損は少し少なくなります。フォールトトレランスを監視するベンダーが存在することがありますが、作成したソフトウェアは破損する可能性が高くなります。

どこかから始める必要があります。 月に2万ルーブルの専用サーバーがあると仮定すると、これから踊ります。 その上に、フロントエンド、バックエンド、ベース、いくつかの補助サービス、memcached、それらを作成して作成する非同期タスクとハンドラーを備えたキューなど、すべてがヒープにあります。 こっち? さらに、これを順番に処理します。

近似アルゴリズム-各サブシステムを取得し、大まかにどのように壊れるかを推定し、どのように修復できるかを考えます。
私はすぐに言わなければならない-すべてを修正することは非現実的です。 すべてを修正することが可能である場合、100%の稼働時間があり、これはすべて必要ではありません。 しかし、私たちができるすべてを試してみましょう、すぐに閉じます。
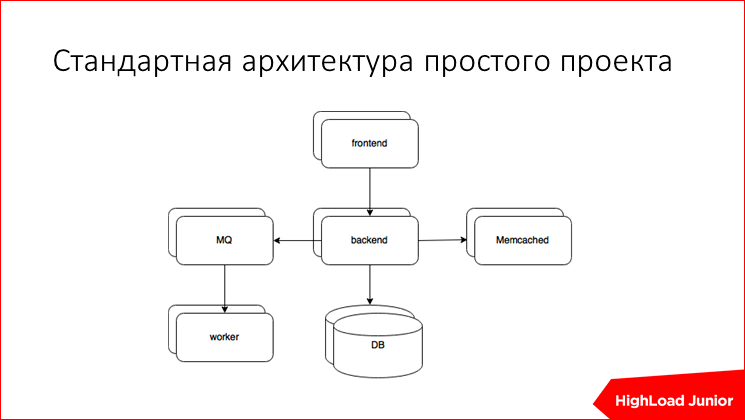
したがって、2000年以降の平均的なプロジェクトはどのように配置されていますか? バックエンドがあり、フロントエンドがあり、memcachedはよくありますが、メッセージキュー、ハンドラー、ベースは重要ではありません。 アルゴリズムをおおまかに理解して、カバーしていないものがある場合は、自分でそれを行うことができます。

フロントエンド。 それは何のためですか? すべての着信要求を受け入れ、低速クライアントのサービスに従事し、何らかの形でより太いバックエンドの負荷を最適化し、ディスクから独自に静的情報を提供し、この場合、https、プロキシに関するサイトのトランスポート層セキュリティのサービスに従事しますバックエンドのリクエスト、バックエンド間のバランス、時には組み込みキャッシュがあります。

何が起こるでしょうか? Nginxまたは別のフロントエンドサーバーを持っている鉄片は、愚かに壊れる可能性があります。 Nginx自体またはこのマシン上の何かは、さまざまな理由で死ぬ可能性があります。 たとえば、リソースにぶつかったり、ディスクにぶつかったりなど、すべてが鈍くなることがあります。 その結果、すべてが遅くなります。 それを解決し始めましょう。

原則として、フロントエンド自体には条件はありません。 そうでない場合は、早急に修正することをお勧めします。 ステートレスの場合、つまり 彼はデータを保存せず、クライアントは自分だけに彼のリクエストを送信する義務はありません。これらのグランドのいくつかを配置し、実際にそれらの間のバランスを調整することができます。
難点は何ですか? 原則として、上記のすべては私たちの責任の範囲ではありません。私たちはそこで何も微調整することはできません。私たちのサーバーで立ち往生したレースを提供してくれたプロバイダーが既に存在します。

これについて何かする方法もあります。 スキルなしで実行できる最初の最も基本的なことは、DNSラウンドロビンです。 ドメインに複数のIP、1つのフロントエンドの1つのIP、もう1つのフロントエンドの別のIPを指定するだけで、すべてが機能します。
ここでの問題は、登録したサーバーが機能しているかどうかをDNSが認識しないことです。 壊れたIPを返さないようにDNSを教える場合でも、DNSキャッシュはまだあり、さまざまなプロバイダーからの曲がったキャッシュなどがあります。 一般に、DNSをすばやく変更するという事実に依存しないでください。 現実には、登録されているDNSのTTLが低い場合でも、クライアントは依然としてデッドIPに侵入します。
DNSに登録する複数のサーバー間で単一のIPアドレスが共有される場合、一般に共有IPと呼ばれるテクノロジーがあります。 VRRP、CARPなどのプロトコルの実装 ただそれを行う方法をグーグル、それは明確になります。
ここで問題は何ですか? プロバイダーのサービス提供者は、両方のサーバーが同じイーサネットセグメントに属していることを確認して、サービスハートビートなどを交換できるようにする必要があります。
そしてまだ-これは負荷分散を提供しません、すなわち バックアップサーバーは常にアイドル状態になります。 ソリューションは簡単です-2つのサーバー、2つのIP、1つのマスターを1つ、もう1つのマスターをもう1つ使用します。 そして、彼らはお互いを保証します。 そして、私たちはDNSで両方を規定しており、すべてが順調です。

これらのサーバーの前にルーティングを行うことができる何らかの種類のルーターまたはその他のネットワークハードウェアがある場合、Ciscoにそのような単純なヒント、たとえば同等のルートを記述し、次の場合に何らかの方法でこれらのルートがハードウェアから削除されることを確認できますサーバーがダウンしています。 ジュニパーの場合、これはBFDdを使用して実行できます。 しかし、一般的に、これらの単語はグーグルで習得できます。
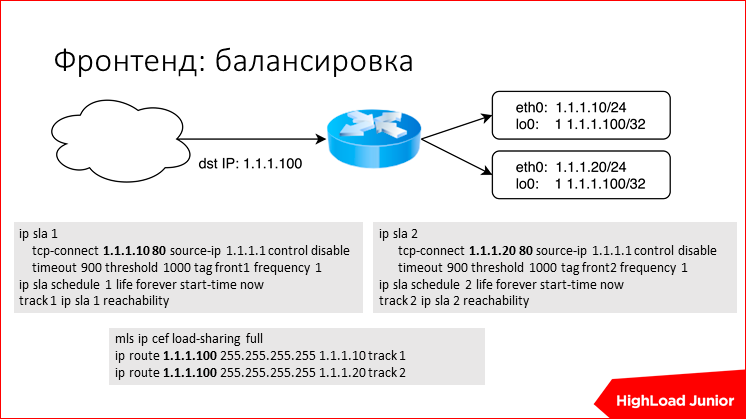
これは、シスコを通じてどのように機能するかです。 これらは設定の一部です。 1つのIPアドレスをアナウンスし、1つのサーバーと別のサーバーを通る2つのルートがあります。 ローバックインターフェイスの各フロントエンドでターゲットIPがハングしますか? どういうわけか、チェックをチェックするロジックが提供されます。 シスコ自体は、ルータのステータスを確認できます。たとえば、NginxポートのCB接続などを確認したり、単にpingを実行したりできます。 ここではすべてが簡単です。小さなプロジェクトの誰かが自分のルーターを持っている可能性は低いです。

私たちが行うことはすべて、監視とともにカバーする必要があります。なぜなら、それ自体が予約されているという事実にもかかわらず、システムで何が起こっているのかを理解する必要があるからです。
フロントエンドの場合、ログ監視は非常にうまく機能します。 モニタリングはログを読み取り、ヒストグラムを作成し、ユーザーに与えるエラーの数とサイトの動作速度を確認し始めます。
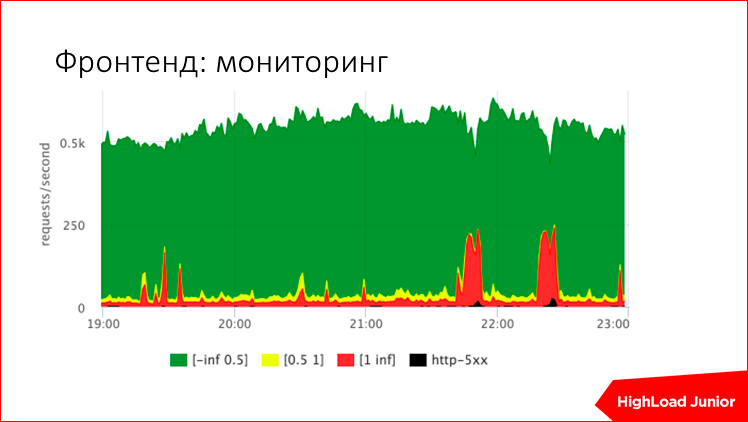
この写真については非常に示唆的です。 サイトへの1秒あたりyリクエストが表示されます。 この場合、1秒あたり約500件の要求が来ています。 通常の状況では、低速の要求(赤でマークされている)があります。これらは処理に1秒以上かかる要求です。 緑色のものは500ミリ秒よりも高速なものであり、黄色のものは中間のものであり、黒色のものはエラーです。 つまり すぐにあなたのサイトがどのように機能するかを見ることができます-5分前かどうかのように。 ここには2つの赤いバーストがあります-これらは単なる問題です。 これにより、サイトの速度が低下し、ユーザーリクエストの30〜40%が鈍くなっていました。

合計すると、これらのメトリックに従って、サイトの動作-良いか悪いかを明確に示すアラートを構成できます。 たとえば、このようなしきい値は次のとおりです。 つまり 1秒あたり200のリクエストがあるサイトで1秒あたり10を超えるリクエストがある場合、これは重大なアラートです。 1秒を超える、5を超える遅い要求の割合が許容される場合、これも重要なアラートです。
そのため、サイト全体を監視でカバーしました。 さて、サイト全体ではなく、原則として、サイトの状態であり、一般的には先に進むことができます。

全体として、このレイヤーでは、フロントエンドとその上のサービスが動作しているかどうかを確認する方法に沿って、フロントエンドを予約することで、何らかの形で2つの問題を解決しました。 2つの問題を解決しましたが、3番目の問題は解決できません。これは、意思決定の際にメトリックに依存する必要があるため、難しいためです。 私たちはそれを監視するだけです。問題がある場合は、私たちの手で理解します。 これは何もないよりも10倍優れています。

どうぞ バックエンド。 バックエンドは何ですか? 原則として、いくつかのリポジトリ、データベースからデータを収集、受信し、何らかの方法でそれらを変換し、ユーザーに応答します。 したがって、誰かを待っているときにリクエストの一部があります。 何かを計算するとき、たとえばテンプレートをレンダリングし、ユーザーに答えを返すだけの部分があります。

私たちはリスクを書き留めます:ハードウェアの一部が壊れ、サーバー自体が死に、バックエンドがデータを取得するサービスに問題があります。 私たち自身が十分なリソースを持っていないという事実のために、データベースは馬鹿げており、何か他のものは馬鹿げています。 書きましたが、すべてではないかもしれませんが、おおよそのアルゴリズムを示します。

私たちは考え始め、閉じます。
バックエンドは、ステートレスを実行し、ユーザーセッションをディスクなどに保存することをお勧めします。 したがって、バランシングタスク、つまり 次のユーザーリクエストの送信先を心配することはできません。 鉄片をいくつか入れて、フロントエンドでバランスを取ることができます。

各バックエンドに対する多数のリクエストから身を守るには、バックエンドのパフォーマンス制限とは何かを理解し、その制限を設定する必要があります。 設定可能なapacheに制限があると仮定します。たとえば、「私は200の同時リクエストのみを取得し、それ以上は取得しません。 さらに来た場合は、「503」を指定します。これは、リクエストを処理できなくなったという明確なステータスです。 したがって、リクエストを別のサーバーに送信できることを、バランサーまたはフロントエンドの場合に示します。 したがって、過負荷に悩まされることはありません-システムが完全に過負荷になっている場合、ユーザーに「503」を与える-「おい、できません」のような明確なエラー これは、すべてのクエリが退屈でハングアップするのではなく、顧客は何が起こっているのかまったく理解していませんでした。
また、誰もが忘れる瞬間。 急速に開発されているプロジェクトでは、すべてのタイムアウトのチェックを忘れています。 タイムアウトを設定します。 バックエンドの入力がmemcachedデータベースの外部のどこかに行く場合、答えを待つ量を制限する必要があります。 永遠に待つことはできません。 あなたは、例えば、postgressの応答を期待して、それに接続し、いくつかのリソースを使用し、時間内に落ちなければなりません:「それで、もう待つことができません」と言って、2階でエラーを出します。 したがって、すべての操作が進行中であり、何が起こっているのか理解できないため、すべてが愚かでログに何もない状況を除外します。 タイムアウトを制限し、それらに非常に敏感である必要があります。そうすれば、より管理しやすいシステムになります。

バランス。 この場合、簡単です。 フロントエンドにNginxがある場合は、単にいくつかのアップストリームを規定します。 タイムアウトについても-LAN接続の場合、タイムアウトは秒ではなく、数十ミリ秒、またはそれ以下である必要があります。状況を確認する必要があります。 どのような場合に近隣サーバーへのリクエストを繰り返すかを言ってください。 嵐が発生しないように、再試行の回数を制限します。 大きな問題は、データ変更要求、投稿などを取得するかどうかです。 ここで、Nginxの最新バージョンでは、デフォルトでPOSTなどのリクエストを再試行しません。 べき等の要求ではありません。 そして、これは原理的には良いことです。誰もがこのペンを長い間待っていて、ついに登場しました。 投稿を追跡する場合は、他の動作を設定できます。

バックエンドについて-同時に監視でカバーしようとしています。 プロセスが生きているかどうか、リッスンソケットが開いているかどうか、サービスがサービスするのを待っているかどうか、ステータスを確認する特別なハンドルに応答するかどうか、サービスがリソースを消費する量、CPUをどれだけ使用するか、どのくらい使用するかを理解したい彼は、スワップにどれだけ座っているか、開いた記述子ファイルの数、ディスクでの入出力操作の数、断片、トラフィックなどにメモリを割り当てて、より多くを消費するか通常どおりに消費するかを理解しました。 これを理解することは非常に重要であり、前の期間と比較するために時間内に理解することが重要です。
Javaの特定のランタイムメトリックは、ヒープ状態、メモリプールの使用、ガベージコレクション、断片化された数、占有秒数、1秒あたりの数などです。
Pythonには独自のものがあり、GO'shkiには独自のものがあり、ランタイムに関連するすべてのものには独自の別個のメトリックがあります。

バックエンドが何をしていたか、受信したリクエストの数を理解する必要があります。 ログでそれを撃つことができ、statsdでそれを撃つことができ、各リクエストのタイミング、特定のリクエストに費やされた時間、エラーの数を理解する必要があります。 これらのメトリックスの一部は、バックエンドのクライアントとして機能するため、原則としてフロントエンドを参照し、ミスがあったか通常の回答があったかを確認します。 彼は、答えをどれだけ待っていたかを見ています。 外部にあるすべてのサービスを待機していたバックエンドの数、つまり これはベース、memcached、nosqlであり、キューで動作する場合、タスクをキューに入れるのにどれくらい時間がかかりましたか。 また、たとえば、テンプレートのレンダリングなど、CPUのいくつかの有形部分にかかる時間。 つまり 「このようなテンプレートをレンダリングしますが、3ミリ秒かかりました」というログに書き込みます。それだけです。 つまり これらのメトリックを確認して比較できます。
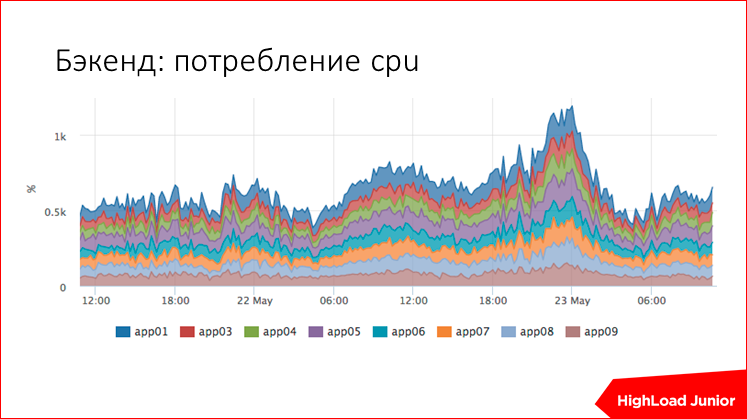
これは、プロジェクトの1つでCPU使用率rubyを測定する方法の例です。 これはすべてのホストの概要チャートです。ここには9つのバックエンドがあります。 ここでリソースが異常に消費されているかどうかはすぐにわかります。
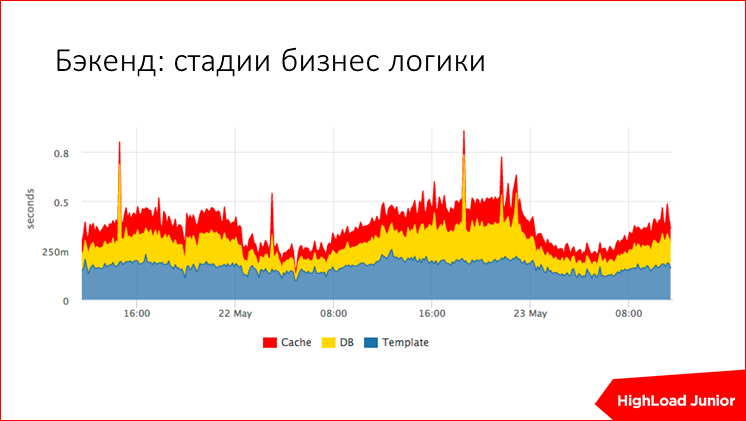
または、リクエスト処理段階としましょう。 ここでは、標準化のために時間の3分の1が費やされ、測定されました。 残りは約3分の1で、ベースとキャッシュを待機しています。 爆発したかどうかはすぐにわかります。 ここで、中央に外れ値があり、キャッシュが鈍くなったとき、別のバーストではベースが鈍った、たとえば黄色です。 誰が責任を負うかはすぐに明らかになり、長い間何かを探す必要はありません。

合計、バランサーがこのホストでバランスをとるのをやめ、問題がないため、鉄の故障でケースを閉じ、サービスが終了するようにケースを閉じました。 データベースやその他のリソースが愚かであるケースを監視しました。なぜなら、測定し、エラーの数を測定したからです。 リソースの消費を測定し、たとえば、レンダリングが遅い場合、CPUプロセスがどれだけ増えたか、そこ、ルビー、またはその他のものになっていることを確認します。 これも監視しています。 原則として、すべてが管理されています。 リクエストの数が増えたため、制限や制限により閉鎖されたため、ここでは原則としてすべてが悪くはありません。

データベースによると。 彼女の仕事は何ですか? データを保存します。つまり、原則として、データストレージの中心点はベースです。 nosqlかもしれませんが、まだ考慮に入れていません。 ユーザーからのリアルタイムリクエストに応答します。 バックエンドからユーザーが待っているページまで、ユーザーは何らかのリクエストの分析処理、つまり どこかであなたの冠が夜に働く、あなたがそこで働いた量などを計算します。

ベースはどうなりますか? いつものように-鉄片が壊れた、どこにも鉄片が壊れた。 ちなみに、すべての予備品などがあるにもかかわらず、あなたのハードウェアが永久に動作することを当てにすることはできないという統計によると、常にこのリスクを許容する必要があります。
腺によるデータの損失、単一のコピーにデータがあり、ガジェットが死んだとき、私たちは皆失われました...ガジェットが生きていて、いくつかの削除が来たか、データが何らかの形でクラッシュしました-これは完全に別のリスクです。
サービスは消滅しました。postgressはoom killerまたはmysqlに打ち負かされました-これが起こっていることを何らかの形で理解する必要もあります。
原則として、CPUやディスクなどに対応できないほど多くのリクエストをデータベースに送信した場合のリソース不足によるブレーキ。
たとえば、推定よりも10倍多くのリクエストを送信したという事実のために、たとえば、一部のトラフィックがそこに送信された、など。
クエリ曲線によるブレーキ-インデックスを使用しない場合、またはデータが何らかの形で間違っている場合、ブレーキもかかります。

これで何かを試してみましょう。
レプリケーション。 レプリケーションは常に必要です。 レプリケーションを省くことができるケースは実際にはありません。 それを取得し、マスタースレーブモードの別のサーバーで設定するだけで、他に発明する必要はありません。
ほとんどのプロジェクトの主な負担は読書です。 原則として、サイトの安定した安定した運用のみを確実に読み取れば、上司またはあなたは非常に幸せになります。 これはすでに、落下するよりも何もないより100,500倍優れています。

レプリケーションラグの影響を受けないすべてのSELECTをすぐにレプリカにロードできます。 これは何ですか データはすぐにはレプリカに届きませんが、さまざまな理由に応じて、チャネルの帯域幅から始まり、そこでブロックされるレプリカの量で終わる一定の遅延があります。 匿名ユーザーが要求する要求、状態、たとえばディレクトリは、レプリケーションラグの影響を受けません。 データが遅れ、ユーザーが古くなった場合、何も悪いことは起こりません。 そして、ユーザーがプロファイルに記入し、フォームで送信を押し、まだ変更されていないデータを見せたら、それをレプリカから取得したとしましょう。これは問題です。 この場合、ウィザードでSELECTを実行する必要があります。 とにかく、ほとんどの負荷はキューに送られます。 また、レプリカがあること、遅れていることをアプリケーションに教える必要がありますが、フォールトトレランスに加えて、読み取り操作の負荷に対するスケーリングの問題を解決します。
レプリカにアクセスするために、たくさんのレプリカを置くことができ、梨を砲撃するのと同じくらい簡単です。 これらのレプリカへの着信要求のバランスをとるか、アプリケーションに10個のレプリカがあることを知らせることができます。 これは非常に複雑であり、私が理解しているように、標準ツールとあらゆる種類のフレームワークはこれを行う方法を知らないので、少しプログラミングする必要があります。 しかし、あなたはバランスを取る機会を得て、後戻りをします。 ユーザーリクエストを行い、たとえばレプリカがバランサーの背後にある場合、エラーまたはタイムアウトが発生します。同じデッドサーバーに到達する可能性があるため、試すことはできません。 したがって、バックエンドに約10個のレプリカを知ってもらうことができます。レプリカの1つが嘘をついている場合、もう1つを試して、もし生きている場合はエラーなしでユーザーに答えてください。 これは、このような小さな問題を一掃することです。 アップタイムでも動作します。
マスターが死んでいて、レプリカがある場合の対処方法を理解する必要があります。 最初に、切り替えることを決定する必要があります。

あなたのサーバーが死んで、パニックがあり、3年ごとに死んでいるとしましょう。 その後、彼を募集し、彼が昇るまで待って、切り替えでこのゴミをすべて開始しないことが、より便利です。なぜなら、無料ではなく、時間がかかり、非常に危険です。
それでも切り替えることに決めた場合は、バックエンドをレプリカに再構成します。 レコード全体をレプリカの1つに送信します。 これが通常のデータベース(postgress)の場合、レプリカモードでは、すべての変更要求、挿入、更新などにエラーを返します。 そして、それは重要ではありません。 次に、必要に応じて、マスターからレプリカまですべてが終了するまで待ちます。 彼が生きていれば。 彼が無生物のようであれば、待つことは何もない。
マスターが生きていれば、常にマスターを獲得します。 つまり 誰かが無効になった古いマスターに書き込みを行い、データを失わないような事件が発生しないように、それを終了することをお勧めします。 したがって、スレーブをマスターにアップグレードします。 これは、データベース管理システムのソリューションごとに異なる方法で実行されますが、合理化された手順があります。
まだレプリカがある場合は、それらを新しいマスターに切り替える必要があり、古いサーバーをどこかに接続する場合は、レプリカとしてオンにします。

全体として、私たちは何が起こっているのかを大まかに検討し、私の意見では、私たちが言ったのはかなり馬鹿げた操作であり、個人的にはマシンでそれをしたくありません。 リスクはありません。 より良いアイロンを切り替えて購入したりレンタルしたりする必要がある可能性を最小限に抑えることをお勧めします。 つまり マスターが死んでいる可能性を愚かに減らします。
ウィザードを段階的に切り替える方法に関する指示を必ず書いてください。 これは、ストレスの多い状況にある午前4時に眠っている人によって行われるべきであり、サイトに関連するビジネスを持っています。彼は自分が何をしているのかを考えるのに苦労する必要はありません。 もちろん、彼は働くためにバレンキを雇わず、脳を最小限に抑える必要があると考えなければなりません。 それはストレスの多い状況だからです。
この指示を必ずテストしてください。 テストされていない命令は命令ではありません。 したがって、命令をテストし、演習を手配します。 私たちは指示を書き、マスターを削減し、訓練します。指示に従ってすべてを厳密に行い、途中で何も発明しません。 うまくいかない場合は、すぐに指示に追加します。
途中で、時間を測定します。 30分または15分で同様の問題に対処できるようにするため、または人が到着してラップトップを開いてから押し出して運転した後、合計ダウンタイムが1.5分になるように時間を測定する必要があります。
次回、指示を変更した場合は、繰り返し練習する必要があります。 ダウンタイムであることが判明した時間に満足できない場合は、それを使用して、いくつかのステップを最適化して、どこかでファイルの並列コピーを提供するなどを試みることができます。 ステップを見るとき、各ステップにかかる量を測定し、ある種の最適化をかき立てます。

それとは別に、レプリケーションがバックアップではないというキャプテンのことは注目に値します。 データを強制終了するリクエストを受け取った場合、それもレプリカに送られ、すべてが失われます。 データをまったく保存する必要がある場合は、バックアップする必要があります。
バックアップも、データベースごとに異なる方法で実行されます。 完全バックアップがあり、通常は1秒ごとではありません。先書きログまたはbinログなどを使用して、毎日のダンプまたはデータファイルの毎日のコピーをキャッチできるバックアップの可能性があります。これらのbinログは慎重に側にコピーする必要があります。
繰り返しますが、これまでに一度も展開したことがなく、ベースを復元しなかったバックアップはバックアップではなく、一定の確率であなたを救うことができるが、事実ではないため、常にリカバリをテストする必要があります。 。
, , , , — . , . つまり , , , , . , , -, , ?

— , , , , , , / , , listen socket, .
, 5 . . - , - , postrgess , CPU, . - , , , , 500 , , , , ? - , , , . , , , , , , CPU, .
— . , — , — , . , -, 1 — . , , .. . , - , .
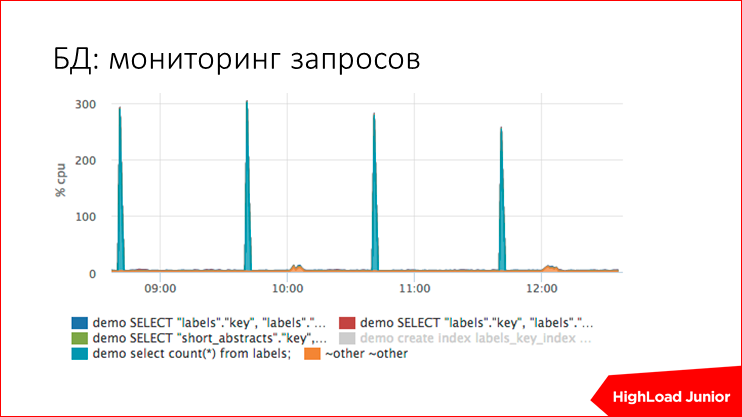
postgress . — - . , , , , ..
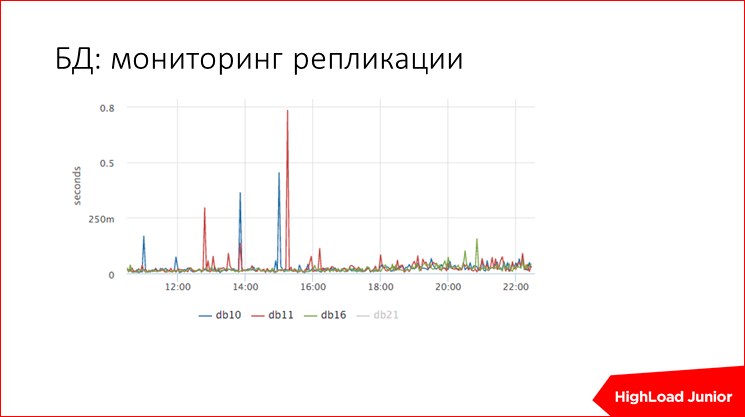
. つまり , , -, - , 800 , 50 .

.
- delete' — , , . , .
, , — , , read only .
- — . - . , . - .
, , 3 , , 5 , 8 . , . , , « 15 » — , , .

memcached, , , . memcached , .
, . つまり , , , 10 , .

, , , , memcached, - - - . .

emcached , , . - , . , -, , , , , . , , memcached , , , .
, , , , , , , , , , , , , , . , . , , , expire, , , - .

, , . , , , memcached , ? , , , , , , n , . , , , memcached? , , , , . , . つまり , , — , , ?
, . つまり - , , , , , , ? , , .
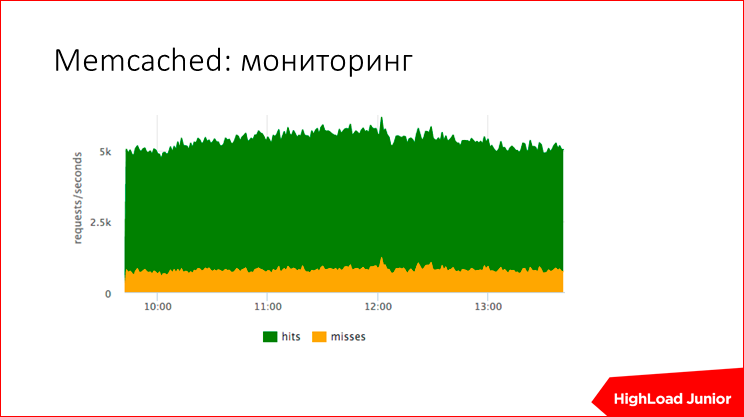
memcached , .. , - , , - . , , 98% , .

. , , memcached, latency … , -, , . , - — , . . . memcached , , , - .
— . , .

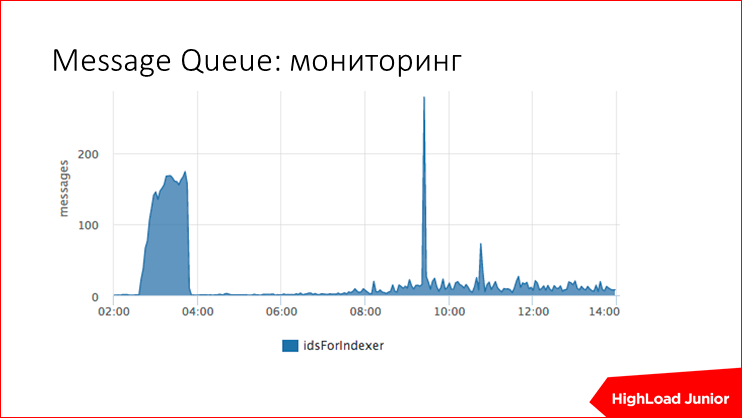
. ? - , , - , . , Message Queue. publisher — , , consumer — , - ..

.
. «», , -, .
, , 2 . — , .
— , .
, publisher , , , - , , , , , , .
- .

, , .. — , — . , , , , , . . , . -, , , , , , , , - .
, , , , , 3 , , , -.

, , , . , 10 . . ? . つまり , , , . , , , , , , , . , , , - , , , . , , .
, ?

, , , — , ? , .. , , , , , - , -.
— , .. , , .

— , .. . , , , ..

まとめると。 , . , , - , - , , , .

20 . . 月あたり。 , , , - — , .. uptime . , , , — , , .

. — . , , , , , . Load Balancing, . , — . , 5 , - SLA .
, . , , CPU, , — , . , — , , , , , -, , , , , . , , , , .

それにもかかわらず、データセンターのクラッシュから身を守りたい場合、ここではすべてがまったく同じです-バックアップグランドを別のデータセンターに置き、そこに複製を構成し、そこに新しいコードを展開する必要があります。バックエンドについて話している場合は、そこに静的ファイルをアップロードする必要があります。まあ、いくつかのDCのサーバーで作業するだけです。データセンターが停止している場合は手動DNSを切り替えるか、既にルーティング、BGP、およびアドレスブロックを使用して、フォールトトレラントなトラフィックを作成できます。

今日お話ししたすべてをまとめます。
最も重要なことは、リスクを理解することです。 リスクを書き出すだけで、今は何もできませんが、リストがあれば、これはすでに非常に良いことです。 リスクが非常に単純で非常に簡単であるため、今すぐ5分以内に閉じると、リストが縮小され、覚えておく必要のある問題が少なくなります。 シナリオが複雑な場合は、このリスクが発生する可能性を減らしてみてください。できない場合は、この問題の一部を閉じて、それが絶対に馬鹿げている場合は、手動介入に任せ、手動介入を自動化する場合は、その後、指示を書き、演習を行います。
したがって、計画がある場合は、フォールトトレランスに既に飽きています。 残りはすべて最適化とダウンタイムの削減です。

連絡先
ニコライ・シヴコ、 nsv @ okmeter.io Habréのokmeter.io 会社のブログ 。
追加情報
情報が足りませんか? それとも、ニコラスのこれらのヒントやその他のヒントをどの時点でつなぐかが明確ではありませんか? これらすべては、9月6日にローマイヴリエフのマスタークラスで詳細に分析します。