インデックスは、リレーショナルデータベースサーバーの最も強力で重要な機能の1つであることは誰もが知っています。 値をすばやく見つける方法 インデックスを作成します。 2つのテーブルを組み合わせるときに覚えておく必要があることは何ですか? インデックスを作成します。 動作が遅くなったSQLクエリを高速化する方法は? インデックスを作成します。

しかし、これらのインデックスは何ですか? また、 どのようにデータベース検索を高速化しますか? 調べるために、CでPostgreSQLデータベースサーバーのソースコードを読み、プレーンテキスト値のインデックスをどのように探すかを確認することにしました。 複雑なアルゴリズムと効率的なデータ構造を見つけることが期待されていました。 そして、私はそれらを見つけました。 今日は、Postgres内でインデックスがどのように見えるかを示し、それらがどのように機能するかを説明します。
私が見つけることを期待していなかったのは、Postgresのソースコードを読んでいたときに最初に発見したことです。それは、コンピュータサイエンスの理論の中心にあります。 Postgresのソースコードを読むことは、学校に戻り、若い頃に十分な時間がなかった科目を勉強することになりました。 Postgres内のCに関するコメントは、彼が行うことだけでなく、その理由も説明しています。
順次スキャン:マインドレス検索
Nautilusチームを去ったとき、彼らは使い果たされ、ほとんど気絶していました。Postgresの順次スキャンアルゴリズムは、ユーザーテーブル内のすべてのエントリを軽率にループしました。 Captain Nemoを見つけるためにこの簡単なSQLクエリを実行した以前の投稿を思い出してください。

Postgresはリクエストを処理、分析、および計画しました。 次に、順次スキャンプランノード(SEQSCAN)を実行するPostgres内のC関数であるExecSeqScanが 、Captain Nemoをすぐに見つけました。
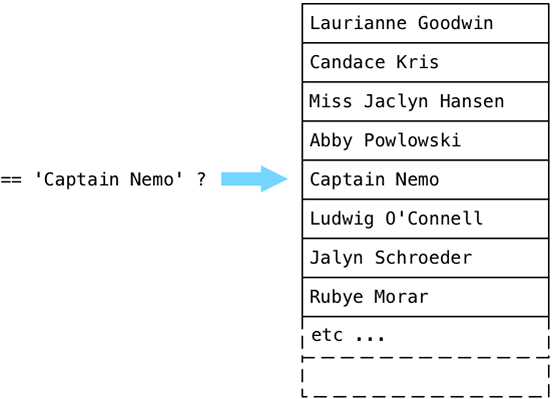
しかし、Postgresは不可解にもユーザーテーブル全体を循環し続け、各名前を「Captain Nemo」と比較しました。
テーブルに何百万ものレコードがある場合、プロセスには非常に長い時間がかかると想像してください。 もちろん、ソートを削除し、見つかった最初の名前のみが受け入れられるようにクエリを書き換えることでこれを回避できますが、より深い問題は、Postgresがターゲット文字列を検索する方法の非効率性です。 順次スキャンを使用してユーザーテーブルの各値を「Captain Nemo」と比較するのは遅く、非効率的で、テーブルに名前が表示されるランダムな順序に依存します。 私たちは何を間違っていますか? もっと良い方法があるはずです!
答えは簡単です。インデックスを作成するのを忘れていました。 さあ、やってみましょう。
インデックス作成
インデックスの作成は非常に簡単です-このコマンドを実行するだけです:
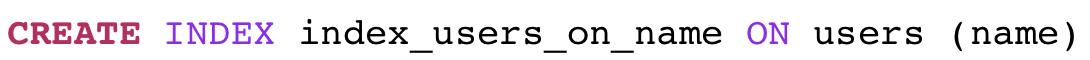
もちろん、Ruby開発者として、代わりにActiveRecord add_index移行を使用します。これにより、「内部で」同じCREATE INDEXコマンドが実行されます。 選択クエリを再度実行すると、Postgresは通常どおりプランツリーを作成しますが、今回は少し異なります。
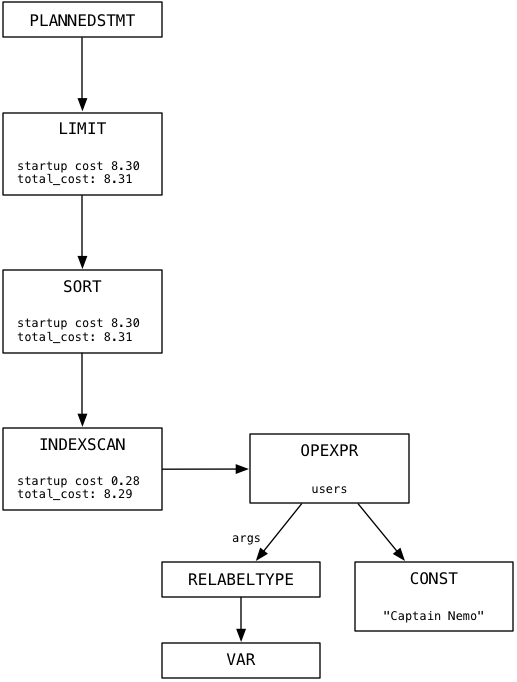
下部では、PostgresがSEQSCANの代わりにINDEXSCANを使用することに注意してください。 SEQSCANとは異なり、INDEXSCANはユーザーテーブル全体をスキャンしません。 代わりに、作成したばかりのインデックスを使用して、Captain Nemoレコードをすばやく効率的に検索して返します。
インデックスを作成することでパフォーマンスの問題は解決しましたが、多くの興味深い未回答の質問が残りました。
- Postgresのインデックスとは正確には何ですか?
- Postgresデータベースにアクセスしてインデックスをよりよく見ることができたら、 どのように見えるでしょうか?
- インデックスはどのように検索を高速化しますか?
Postgresのソースコードを調べて、これらの質問に答えてみましょう。
Postgresのインデックスとは何ですか?
まず、CREATE INDEXチームのドキュメントをご覧ください。
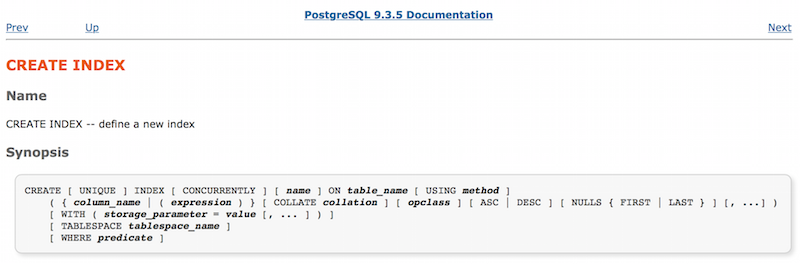
ここに、インデックスの作成に使用できるすべてのオプション(UNIQUEやCONCURRENTLYなど)が表示されます。 USINGメソッドなどのオプションがあることに注意してください。 彼はPostgresにどのインデックスが必要かを伝えます。 同じページの下に、USINGキーワードのメソッド引数に関する情報があります。

Postgresは4種類のインデックスを実装していることがわかります[約。 trans .:さらに、この記事はBRINや他の新しいインデックスバリエーションが登場する前に書かれました。 さまざまなタイプのデータに、さまざまな状況で使用できます。 USINGを指定しなかったため、index_users_on_nameインデックスはデフォルトタイプである「btree」(またはBツリー)インデックスです。
これが最初の手がかりです。PostgresインデックスはBツリーです。 しかし、Bツリーとは何ですか? どこで彼を見つけることができますか? もちろん、Postgresの内部です! 「btree:」を含むPostgres Cファイルのソースコードを検索しましょう
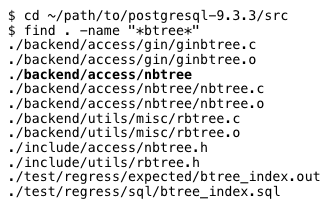
重要な結果は太字で示されています。「./ backend / access / nbtree」。このディレクトリ内にREADMEファイルがあります。 それを読みましょう:

驚いたことに、このREADMEファイルは詳細な12ページのドキュメントであることが判明しました。 Postgresのソースコードには、Cコードに関する有用で興味深いコメントだけでなく、データベースサーバーの理論と実装に関するドキュメントも含まれています。 オープンソースプロジェクトのコードを読んで理解することはしばしば困難で恐ろしいですが、PostgreSQLではそうではありません。 Postgresの開発者は、あなたと私が彼らの仕事を理解できるように多大な努力をしました。
READMEドキュメントのタイトル-「Btree Indexing」-ディレクトリに、PostgresでBツリーインデックスを実装するCコードが含まれていることを確認します。 しかし、最初の文はさらに興味深い:これは、Bツリーとは何か、postgresインデックスがどのように機能するかを説明する科学論文への参照です:LehmanとYaoによって作成されたBツリーの同時操作の効率的なロック )
この科学的研究の助けを借りて、B-Treeとは何かを理解しようとします。
Bツリーインデックスはどのように見えますか?
リーマンとヤオの研究は、1981年にBツリーアルゴリズムに加えられた革新的な変更について説明しています。 これについては少し後で話しましょう。 しかし、彼らはBツリーのデータ構造の簡単な紹介から始めます。これは1972年に9年前に発明されました。 それらの図の1つは、単純なBツリーの例を示しています。

Bツリーという用語は、英語の「balanced tree」-「balanced tree」の略語です。 このアルゴリズムにより、検索が簡単かつ高速になります。 たとえば、この例で値53を検索する場合、値40を含むルートノードから開始します。

検索値53とツリーノードで見つかった値を比較します。 53-40を超えていますか? 53は40より大きいため、ポインターを右下に移動します。 29を探していたら、左に行きます。 右側のポインターはより大きな値につながり、左側のポインターはより小さな値につながります。
ツリーの次の子ノードへのポインターをたどると、2つの値を含むノードが見つかります。

今回は、53を47および62とすぐに比較し、47 <53 <62であることがわかります。ツリーノードの値はソートされているため、これは簡単です。 今、私たちはセンターサインをたどります。
ここには、すでに3つの値を持つ別のツリーノードがあります。
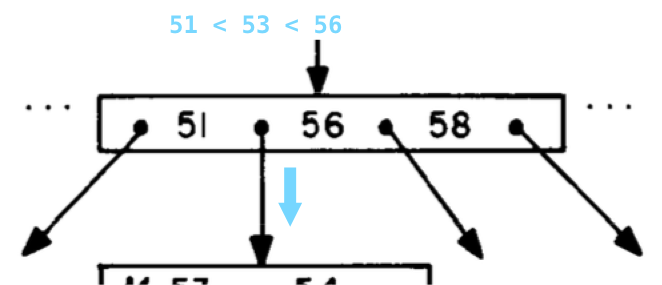
ソートされた数字のリストを確認した後、51 <53 <56を見つけ、4つのポインターの2番目に従います。
最後に、ツリーの葉ノードに到達します。
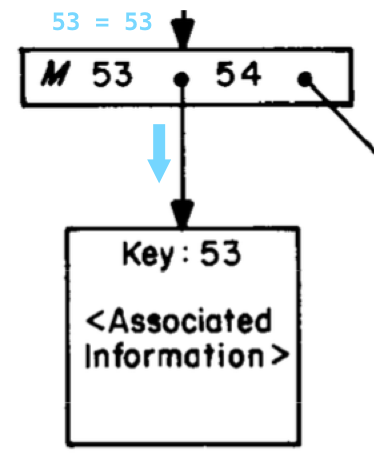
そして、ここに私たちの求めていた価値53があります!
Bツリーアルゴリズムは、次の理由で検索を高速化します。
- 各ノード内の値(キーと呼ばれる)をソートします。
- バランスが取れています。キーはノード間で均等に分散され、あるノードから別のノードへの遷移の数が最小限に抑えられます。 各ポインターは、後続の各子ノードとほぼ同じ数のキーを含む子ノードにつながります。
Postgresインデックスはどのように見えますか?
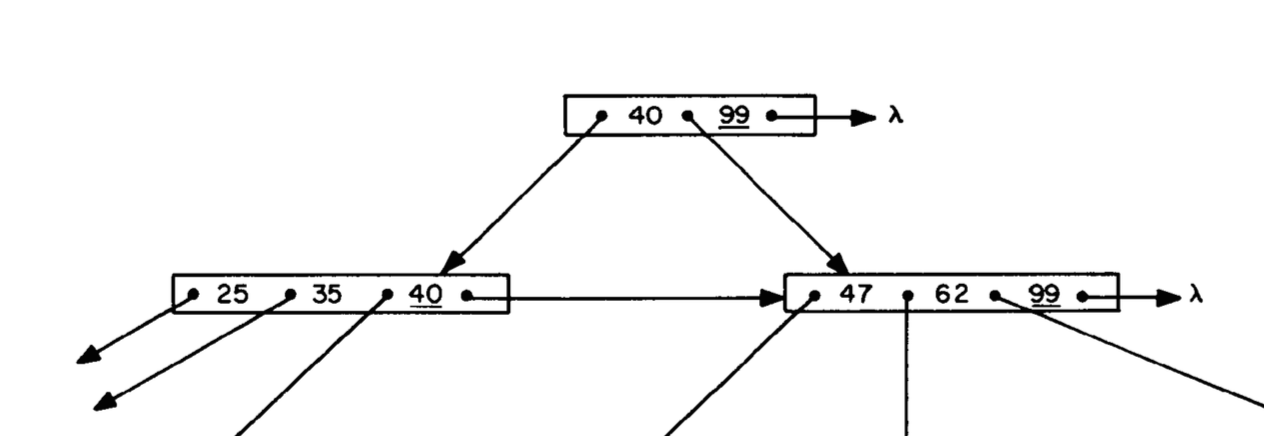
リーマンとヤオは30年以上前にこの図を描きました。 今日のPostgresの動作とは何の関係がありますか? 驚くべきことに、前に作成したindex_users_on_nameインデックスは、科学論文のこのまさに図に非常に似ています。2014年に、1981年の図とまったく同じようなインデックスを作成しました。
CREATE INDEXコマンドを実行すると、PostgresはBツリーのユーザーテーブルからすべての名前を保存しました。 それらは木の鍵になりました。 PostgresのBツリーインデックス内のノードは次のようになります。

インデックス内の各エントリは、IndexTupleDataと呼ばれるC構造で構成され、その後にビットマップと値が続きます。 Postgresはビットマップを使用して、キーのインデックス属性がNULLであるかどうかを記録してスペースを節約します。 実際の値は、ビットマップの後のインデックスにあります。
IndexTupleDataの構造を詳しく見てみましょう。

上の図は、各IndexTupleData構造に以下が含まれていることを示しています。
- t_tid:これは、別のインデックスタプルまたはデータベース内のレコードへのポインタです。 これはCの物理メモリへのポインタではないことに注意してください。代わりに、メモリのページで目的の値を見つけるためにPostgresが使用できる数値が含まれています。
- t_info:インデックスの要素に関する情報が含まれます。たとえば、その中にある値の数や、nullかどうかなどです。
これをよりよく理解するために、index_users_on_nameインデックスからいくつかのエントリを表示しましょう。
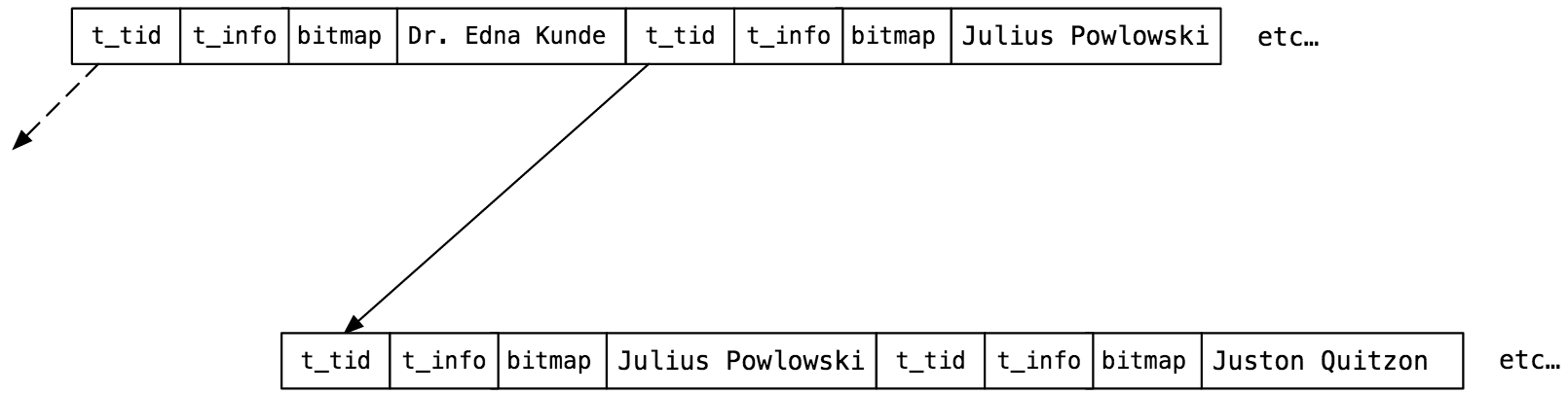
値をユーザーテーブルの一部の名前に置き換えました。 ツリーの最上位ノードには、キー「Dr. エドナ・クンデ」と「ジュリアス・パウロウスキー」、そして下-「ジュリアス・パウロウスキー」と「ジャストン・キッツン」。 リーマンおよびヤオ図とは異なり、Postgresは各子ノードで親キーを繰り返します。 ここでは、「Julius Powlowski」が最上位ノードと子ノードのキーです。 上位ノードのt_tidポインターは、下位ノードの同じJulius名を参照します。
Postgresがキー値をBツリーノードに保存する方法の詳細については、itup.hヘッダーファイルを参照してください。

IndexTupleData
postgresql.orgで表示
Captain Nemoを含むBツリーノードを検索する
元のSELECTクエリに戻りましょう。

Postgresはindex_users_on_nameインデックスで「Captain Nemo」をどのくらい正確に探しますか? 前の記事で調べたシーケンシャルスキャンよりも高速にインデックスを使用するのはなぜですか? 調べるために、少しズームアウトして、インデックスのユーザー名を見てみましょう。
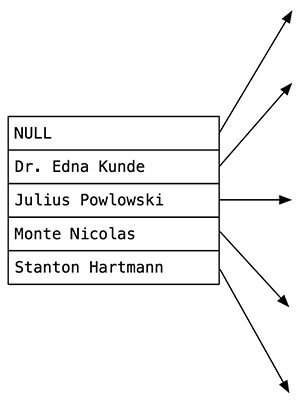
これは、Bツリーindex_users_on_nameのルートノードです。 名前が収まるように、木を横に置きます。 4つの名前と1つのNULL値が表示されます。 index_users_on_nameを作成したときに、Postgresがこのルートノードを作成しました。 インデックスの始まりを示す最初のNULL値に加えて、残りの4つの値はアルファベット順にほぼ均等に分布していることに注意してください。
Bツリーはバランスの取れたツリーであることを思い出させてください。 この例では、Bツリーに5つの子ノードがあります。
- 博士の前のアルファベット名 エドナ・クンデ;
- 博士の間にある名前 エドナ・クンデとジュリアス・ポウロウスキー。
- Julius PowlowskiとMonte Nicolasの間にある名前。
- など
Captain Nemoという名前を検索すると、Postgresは最初の右上矢印に従います。 これは、Nemo船長がアルファベット順にDr. エドナ・クンデ:
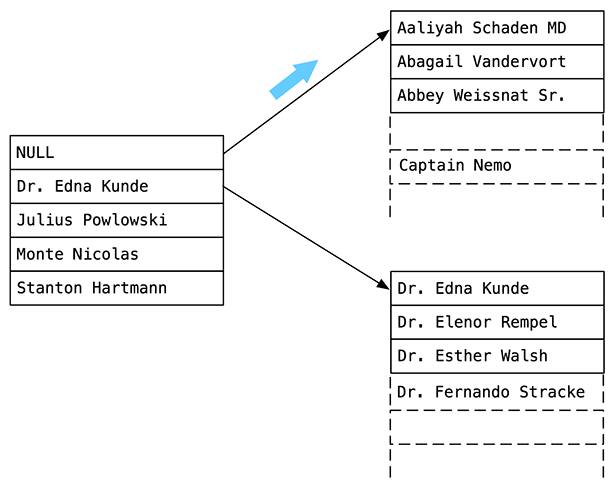
ご覧のとおり、右側のPostgresはCaptain Nemoを含むBツリーノードを見つけました。 私のテストでは、ユーザーテーブルに1000個の名前を追加しました。 この子Bツリーノードには、約200の名前(正確には240)が含まれています。 そのため、BツリーアルゴリズムはPostgresでの検索を大幅に絞り込みました。
PostgresがそのすべてのノードからターゲットBツリーノードを見つけるために使用する特定のアルゴリズムの詳細については、_bt_search関数を参照してください。
_bt_search
postgresql.orgで表示
特定のBツリーノード内でCaptain Nemoを検索する
Postgresは検索スペースを約200の名前を持つBツリーノードに絞り込んだので、その中からNemo船長を見つける必要があります。 彼はどうやってそれをしますか? この短縮リストに順次スキャンを適用しますか?

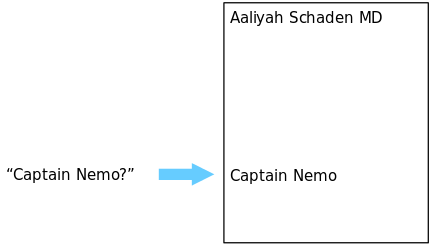
いや ツリーノード内のキー値を検索するために、Postgresはバイナリ検索アルゴリズムの使用に切り替えます。 ツリーノードの50%の位置にあるキーと「Captain Nemo」の比較を開始します。

Captain Nemoはアルファベット順でBreana Wittingに従うため、Postgresは75%にジャンプし、別の比較を行います。

今回、キャプテンネモはカーティスウルフに行くので、Postgresは少し戻ってきます。 さらに数回のイテレーションの後(Postgresは私の例でCaptain Nemoを見つけるために8回比較しました)、Postgresは最終的に私たちが探していたものを見つけました。
Postgresが特定のBツリーノードで値を検索する方法の詳細については、_bt_binsrch関数を参照してください。
_bt_binsrch
postgresql.orgで表示
多くのことを学ぶ必要があります
この投稿では、Bツリー、データベースインデックス、Postgres内部に関するすべてのエキサイティングな詳細について話すのに十分なスペースがありません...多分、顕微鏡でPostgresの本を書く必要があります。 Bツリーでの同時操作の効率的なロック、またはBツリーが参照する別の科学論文で読むことができます。
- Bツリーの挿入:Bツリーアルゴリズムの最も美しい部分は、ツリーに新しいキーを追加することです。 それらは適切なツリーノードにソートされた順序で追加されますが、新しいキーの余地がない場合はどうなりますか? この場合、Postgresはノードを2つに分割し、それらの1つに新しいキーを挿入し、新しい子ノードへのポインターとともに、キーを分割ノードから親ノードに追加します。 もちろん、新しいキーを追加するために親ノードも分割する必要があり、複雑な再帰操作につながる可能性があります。
- Bツリーからの削除:逆演算も興味深いものです。 キーがノードから削除されると、可能であれば、Postgresは親ノードからキーを削除することで兄弟ノードを結合します。 この操作は再帰的にもできます。
- B-Link-Tree:LehmanとYaoの研究では、複数のスレッドが同じB-Treeを使用する場合の同時実行性とブロッキングに関して調査した革新について説明しています。 多くのクライアントが同じインデックスを同時に検索および変更できるため、Postgresのコードとアルゴリズムはマルチスレッドである必要があります。 各Bツリーノードから次の子ノード(いわゆる「右矢印」)に別のポインターを追加すると、2番目のスレッドがインデックス全体をブロックせずにノードを分割する場合でも、1つのスレッドがツリーを検索できます。
氷山の見えない部分を探検することを恐れないでください
アロナックス教授は、人生とキャリアを危険にさらして、とらえどころのないノーチラスを見つけ、キャプテンネモと一緒に素晴らしい水中アドベンチャーの長いシリーズに参加しました。 私たちも同じことをする必要があります。水の下に飛び込むことを恐れないでください-毎日使用するツール、言語、およびテクノロジーの奥深くに。 Postgresについて多くを知ることができますが、内部からどのように機能するか知っていますか? 中を見てみると、自分が水中の冒険に出たときに振り返る時間がありません。
私たちのアプリケーションの背後にある情報学を職場で学ぶことは、単なる娯楽ではなく、開発者の開発プロセスの重要な要素です。 ソフトウェア開発用のツールは毎年改良されており、Webサイトやモバイルアプリケーションの作成は簡素化されていますが、依存している基本的なコンピューターサイエンスを見失うことはありません。 私たちは皆、リーマンやヤオのような巨人、そして彼らの理論を使用してPostgresを作成したオープンソース開発者の肩の上に立っています。 日常的に使用するツールを当たり前のように受け取らないでください。デバイスを調べてください。 開発者として賢くなり、気付かなかったアイデアや知識を見つけます。